InfluxDB时序数据库安装和使用
安装
下载
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.4.0-linux-amd64.tar.gz
安装(没有/opt/module/目录的话先创建)
tar -zxvf influxdb2-2.4.0-linux-amd64.tar.gz -C /opt/module/
运行
cd /opt/module/influxdb2_linux_amd64/
./influxd
访问页面
http://192.168.233.128:8086/
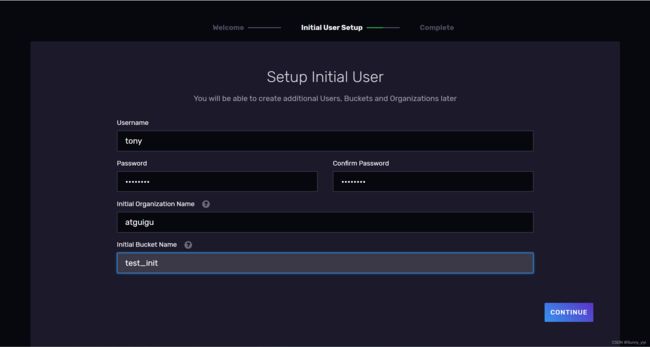
看到下面页面表示influxdb启动成功~

初始化 设置用户密码 组织结构 存储桶

Load Data( 数据来源 )
行协议

使用telegraf获取数据来源
1、新建存储桶example02

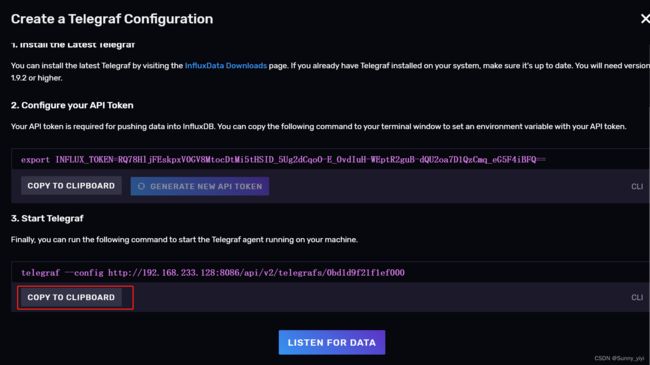
2、创建一个配置

3、下载安装telegraf
wget https://dl.influxdata.com/telegraf/releases/telegraf-1.23.4_linux_amd64.tar.gz
tar -zxvf telegraf-1.23.4_linux_amd64.tar.gz -C /opt/module/
cd /opt/module/telegraf-1.23.4/usr/bin
复制API Token 到/opt/module/telegraf-1.23.4/usr/bin目录下粘贴,按回车


env命令就能看到这个环境变量
启动telegraf
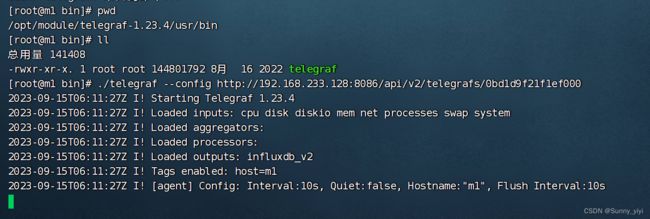
然后在控制Data Explorer面板就能看到从telegraf发送到InfluxDB的数据

使用Scrapers获取数据来源
1、下载安装启动 普罗米修斯
wget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gz
tar -zxvf node_exporter-1.6.1.linux-amd64.tar.gz -C /opt/module/
cd /opt/module/node_exporter-1.6.1.linux-amd64
./node_exporter
访问:http://192.168.233.128:9100/metrics
就能看到监控系统情况数据指标

2、创建新的存储桶example03

3、创建新的Scraper


Java操作InfluxDB
controller
package cn.tedu.springboot_quick.controller;
import cn.tedu.springboot_quick.InfluxDB.InfluxDbMapper;
import cn.tedu.springboot_quick.InfluxDB.MeasurementCpu;
import cn.tedu.springboot_quick.common.CommonResult;
import cn.tedu.springboot_quick.common.utils.ResultUtil;
import cn.tedu.springboot_quick.entity.Menus;
import cn.tedu.springboot_quick.service.MenusService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import org.influxdb.dto.BatchPoints;
import org.influxdb.dto.Point;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/**
*
* 前端控制器
*
*
* @author zhushagnlin
* @since 2021-07-12
*/
@Api(tags = "InfluxDB")
@RestController
@RequestMapping("/influx")
public class InfluxDBController {
@Autowired
InfluxDbMapper influxDbMapper;
@ApiOperation(value = "InfluxDB插入",tags = "InfluxDB")
@GetMapping("/insertInfluxDB")
public CommonResult insertInfluxDB(){
// 创建点数据
Point point1 = Point.measurement("cpu")
.time(System.currentTimeMillis()+ 8 * 60 * 60 * 1000L, TimeUnit.MILLISECONDS)
.tag("tag1","tag111")
.tag("tag2","tag222")
.addField("value", 80)
.addField("host", "server1")
.build();
Point point2 = Point.measurement("cpu")
.time(System.currentTimeMillis()+2000+ 8 * 60 * 60 * 1000L, TimeUnit.MILLISECONDS)
.tag("tag1","tag111")
.tag("tag2","tag222")
.addField("value", 65)
.addField("host", "server2")
.build();
// 批量写入点数据
BatchPoints batchPoints = BatchPoints.database("test1")
.points(point1,point2)
.build();
influxDbMapper.writeBatch(batchPoints);
return ResultUtil.result();
}
@ApiOperation(value = "InfluxDB查询",tags = "InfluxDB")
@GetMapping("/selectInfluxDB")
public CommonResult selectInfluxDB(){
//编写select查询语句
String queryCmd = "SELECT * FROM cpu";
List<MeasurementCpu> result = influxDbMapper.query(queryCmd, MeasurementCpu.class);
return ResultUtil.list(result);
}
}
InfluxDbMapper
package cn.tedu.springboot_quick.InfluxDB;
import cn.tedu.springboot_quick.config.InfluxConfig;
import org.influxdb.InfluxDB;
import org.influxdb.InfluxDBFactory;
import org.influxdb.dto.BatchPoints;
import org.influxdb.dto.Point;
import org.influxdb.dto.Query;
import org.influxdb.dto.QueryResult;
import org.springframework.beans.BeanWrapperImpl;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import org.springframework.util.ObjectUtils;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
@Component
public class InfluxDbMapper {
private final InfluxConfig influxConfig;
private InfluxDB influxDB;
@Autowired
public InfluxDbMapper(InfluxConfig influxConfig) {
this.influxConfig = influxConfig;
getInfluxDB();
}
/**
* 获取 influxdb 连接
*/
public void getInfluxDB() {
if (influxDB == null) {
influxDB = InfluxDBFactory.connect(influxConfig.getUrl(),
influxConfig.getUsername(),
influxConfig.getPassword());
//设置使用数据库 保证库存在
influxDB.setDatabase(influxConfig.getDatabase());
//设置数据库保留策略 保证策略存在
if (!ObjectUtils.isEmpty(influxConfig.getRetention())) {
influxDB.setRetentionPolicy(influxConfig.getRetention());
}
//配置 写入策略
if(!ObjectUtils.isEmpty(influxConfig.getEnableBatchTime()) &&
!ObjectUtils.isEmpty(influxConfig.getEnableBatchCount())){
influxDB.enableGzip().enableBatch(influxConfig.getEnableBatchCount(),
influxConfig.getEnableBatchTime(),TimeUnit.MILLISECONDS);
}
}
}
/**
* 关闭连接
*/
public void close() {
if (influxDB != null) {
influxDB.close();
}
}
/**
* 指定时间插入
*
* @param measurement 表
* @param tags 标签
* @param fields 字段
* @param time 时间
* @param unit 单位
*/
public void write(String measurement, Map<String, String> tags, Map<String, Object> fields, long time, TimeUnit unit) {
Point point = Point.measurement(measurement).tag(tags).fields(fields).time(time, unit).build();
influxDB.write(point);
close();
}
/**
* 插入数据-自动生成时间
*
* @param measurement 表
* @param tags 标签
* @param fields 字段
*/
public void write(String measurement, Map<String, String> tags, Map<String, Object> fields) {
write(measurement, tags, fields, System.currentTimeMillis() + 8 * 60 * 60 * 1000L, TimeUnit.MILLISECONDS);
}
/**
* 批量插入
*
* @param points 批量记录 推荐 1000 条作为一个批
*/
public void writeBatch(BatchPoints points) {
influxDB.write(points);
close();
}
public void writeBatch(List<String> list) {
influxDB.write(list);
close();
}
/**
* 用来执行相关操作
*
* @param command 执行命令
* @return 返回结果
*/
public QueryResult query(String command) {
return influxDB.query(new Query(command));
}
/**
* 创建数据库
*
* @param name 库名
*/
public void createDataBase(String name) {
query("create database " + name);
}
/**
* 删除数据库
*
* @param name 库名
*/
public void dropDataBase(String name) {
query("drop database " + name);
}
/**
* select 查询封装
*
* @param queryResult 查询返回结果
* @param clazz 封装对象类型
* @param 泛型
* @return 返回处理回收结果
*/
public <T> List<T> handleQueryResult(QueryResult queryResult, Class<T> clazz) {
//0.定义保存结果集合
List<T> lists = new ArrayList<>();
//1.获取结果
List<QueryResult.Result> results = queryResult.getResults();
//2.遍历结果
results.forEach(result -> {
//3.获取 series
List<QueryResult.Series> seriesList = result.getSeries();
if (!CollectionUtils.isEmpty(seriesList)) {
//4.遍历 series
seriesList.forEach(series -> {
//5.获取的所有列
List<String> columns = series.getColumns();
//6.获取所有值
List<List<Object>> values = series.getValues();
//7.遍历数据 获取结果
for (int i = 0; i < values.size(); i++) {
try {
//8.根据 clazz 进行封装
T instance = clazz.newInstance();
//9.通过 spring 框架提供反射类进行处理
BeanWrapperImpl beanWrapper = new BeanWrapperImpl(instance);
HashMap<String, Object> fields = new HashMap<>();
for (int j = 0; j < columns.size(); j++) {
String column = columns.get(j);
Object val = values.get(i).get(j);
if ("time".equals(column)) {
//beanWrapper.setPropertyValue("time", Timestamp.from(ZonedDateTime.parse(String.valueOf(val)).toInstant()).getTime());
beanWrapper.setPropertyValue("time", String.valueOf(val));
} else {
//保存当前列和值到 field map 中 //注意: 返回结果无须在知道是 tags 还是 fields 认为就是字段和值 可以将所有字段作为 field 进行返回
fields.put(column, val);
}
}
//10.通过反射完成 fields 赋值操作
beanWrapper.setPropertyValue("fields", fields);
lists.add(instance);
} catch (InstantiationException | IllegalAccessException e) {
throw new RuntimeException(e);
}
}
});
}
});
return lists;
}
/**
* 查询返回指定对象
*
* @param selectCommand select 语句
* @param clazz 类型
* @param 泛型
* @return 结果
*/
public <T> List<T> query(String selectCommand, Class<T> clazz) {
return handleQueryResult(query(selectCommand), clazz);
}
}
MeasurementCpu
package cn.tedu.springboot_quick.InfluxDB;
import lombok.Data;
import org.influxdb.annotation.Column;
import org.influxdb.annotation.Measurement;
import java.util.HashMap;
@Data
@Measurement(name = "cpu")
public class MeasurementCpu {
private HashMap<String, Object> fields;
@Column(name = "time")
private String time;
}
2.4版本插入和查询
DemoPOJO
package cn.tedu.springboot_quick.InfluxDB.V24;
import com.influxdb.annotations.Column;
import com.influxdb.annotations.Measurement;
import java.time.Instant;
/**
* @author: tony
* @date: 2022/9/23 21:53
* @description: 这是一个POJO类,对应将POJO类写入InfluxDB
*/
@Measurement(name="temperature")
public class DemoPOJO {
/** 注意类上的@Measurement注解,我们既可以使用Measurement注解来指定一个POJO类的测量名称
* 但是使用@Measurement注解会将测量名称直接写死在代码里
* 当测量名称会在运行时发生改变时,我们可以使用@Column(menasurement=true)注解
* 这样会将POJO类中被注解的值作为测量名称。
* **/
//@Column(measurement = true)
//String measurementName;
/** 相当于InfluxDB行协议中的标签集,此处标签的名称将会是location **/
@Column(tag = true)
String location;
/** 相当于InfluxDB行协议中的字段集,此处字段的名称将会是value **/
@Column
Double value;
/** 相当于InfluxDB行协议中的时间戳 **/
@Column(timestamp = true)
Instant timestamp;
/** 全参构造器,方便调用者创建对象 **/
public DemoPOJO(String location, Double value, Instant timestamp) {
this.location = location;
this.value = value;
this.timestamp = timestamp;
}
}
Write1
package cn.tedu.springboot_quick.InfluxDB.V24;
import com.influxdb.client.InfluxDBClient;
import com.influxdb.client.InfluxDBClientFactory;
import com.influxdb.client.WriteApiBlocking;
import com.influxdb.client.domain.WritePrecision;
import java.time.Instant;
/**
* @author: tony
* @date: 2022/9/23 3:23
* @description: 这里是使用同步方式向InfluxDB写入数据的示例代码
*
*/
public class Write1 {
/** tony 操作时需要换成自己的 **/
private static char[] token = "JGk2wps3dHXbxKnME8JKB6pyT05iw3vjshSjd3TaB967v6w2HTXRqWdUhNuPyDtJOFTvUWb6fuhb8VwfZ9uW3g==".toCharArray();
/** 组织名称 操作时需要换成自己的 **/
private static String org = "hit";
/** 存储桶名称 **/
private static String bucket = "example_java";
/** InfluxDB服务的url **/
private static String url = "http://localhost:8086/";
public static void main(String[] args) {
InfluxDBClient influxDBClient = InfluxDBClientFactory.create(url, token, org, bucket);
WriteApiBlocking writeApiBlocking = influxDBClient.getWriteApiBlocking();
// 0. 使用InflxuDB行协议写入
// writeApiBlocking.writeRecord(WritePrecision.MS,"temperature,location=north value=50");
// 1. 使用Point写入
// Point point = Point.measurement("temperature")
// .addTag("location", "west")
// .addField("value", 38.0)
// .time(Instant.now(),WritePrecision.NS)
// ;
// writeApiBlocking.writePoint(point);
// 2. 使用POJO类写入
DemoPOJO demoPOJO = new DemoPOJO("east", 22.2, Instant.now());
writeApiBlocking.writeMeasurement(WritePrecision.MS,demoPOJO);
// 3. 调用close方法会关闭并释放一些比如守护线程之类的对象。
influxDBClient.close();
}
}
AsyncWrite
package cn.tedu.springboot_quick.InfluxDB.V24;
import com.influxdb.client.InfluxDBClient;
import com.influxdb.client.InfluxDBClientFactory;
import com.influxdb.client.WriteApi;
import com.influxdb.client.WriteOptions;
import com.influxdb.client.domain.WritePrecision;
import java.time.Instant;
/**
* @author: tony
* @date: 2022/9/23 22:46
* @description: 通过异步的方式向InfluxDB写入数据
*/
public class AsyncWrite {
/** token 操作时需要换成自己的 **/
private static final char[] token = "JGk2wps3dHXbxKnME8JKB6pyT05iw3vjshSjd3TaB967v6w2HTXRqWdUhNuPyDtJOFTvUWb6fuhb8VwfZ9uW3g==".toCharArray();
/** 组织名称 操作时需要换成自己的 **/
private static String org = "hit";
/** 存储桶名称 **/
private static String bucket = "example_java";
/** InfluxDB服务的url **/
private static String url = "http://localhost:8086/";
public static void main(String[] args) {
// 0.创建InfluxDB的客户端
InfluxDBClient influxDBClient = InfluxDBClientFactory.create(url, token, org, bucket);
// 1.异步写入会创建一个守护线程,所以在makWriteApi时可以传递一些配置项,也就是WriteOptions对象
WriteOptions options = WriteOptions.builder()
.batchSize(999)
.flushInterval(10000)
.build();
// 2.使用makeWriteApi创建的
WriteApi writeApi = influxDBClient.makeWriteApi(options);
for (int i = 0; i < 999; i++) {
DemoPOJO demoPOJO = new DemoPOJO("south", 33.3, Instant.now());
writeApi.writeMeasurement(WritePrecision.MS,demoPOJO);
}
// 3.关闭连接,此方法会触发一次刷写,将缓冲区中剩下的数据向InfluxDB写入一次。
influxDBClient.close();
}
}
Query
package cn.tedu.springboot_quick.InfluxDB.V24;
import com.influxdb.client.InfluxDBClient;
import com.influxdb.client.InfluxDBClientFactory;
import com.influxdb.client.QueryApi;
import com.influxdb.query.FluxRecord;
import com.influxdb.query.FluxTable;
import java.util.List;
import java.util.Map;
/**
* @author: tony
* @date: 2022/9/24 1:07
* @description: 这是关于从InfluxDB查询数据的代码
*/
public class Query {
/** token 操作时需要换成自己的 **/
private static char[] token = "JGk2wps3dHXbxKnME8JKB6pyT05iw3vjshSjd3TaB967v6w2HTXRqWdUhNuPyDtJOFTvUWb6fuhb8VwfZ9uW3g==".toCharArray();
/** 组织名称 **/
private static String org = "hit";
/** InfluxDB服务提供的url **/
private static String url = "http://localhost:8086/";
public static void main(String[] args) {
// 0.创建InfluxDB客户端对象
InfluxDBClient influxDBClient = InfluxDBClientFactory.create(url, token, org);
// 1.获取查询API对象
QueryApi queryApi = influxDBClient.getQueryApi();
// 2.这个flux脚本会查询test存储桶中的go_goroutines测量,这个测量下只有一个序列
String flux = "from(bucket: \"test\")\n" +
" |> range(start: -1h)\n" +
" |> filter(fn: (r) => r[\"_measurement\"] == \"go_goroutines\")\n" +
" |> aggregateWindow(every: 10s, fn: mean, createEmpty: false)\n" +
" |> yield(name: \"mean\")";
// 3.这个flux脚本会查询example02存储桶中的cpu测量,指定字段名称为usage_user后,
String flux2 = "from(bucket: \"test02\")\n" +
" |> range(start: -1h)\n" +
" |> filter(fn: (r) => r[\"_measurement\"] == \"cpu\")\n" +
" |> filter(fn: (r) => r[\"_field\"] == \"usage_user\")\n" +
" |> aggregateWindow(every: 10s, fn: mean, createEmpty: false)\n" +
" |> yield(name: \"mean\")";
// 4.使用query方法将会得到一个List对象,其中每一个FluxTable都对应着一个序列
List<FluxTable> query = queryApi.query(flux);
// 5.下面这个for循环会把遍历每个序列,并将这个序列中对应的每一行数据打印出来。
for (FluxTable fluxTable : query) {
List<FluxRecord> records = fluxTable.getRecords();
for (FluxRecord record : records) {
Map<String, Object> one = record.getValues();
System.out.println(one);
}
}
// 6.下面的queryRaw方法将会得到一个字符串,字符串中是FLUX拓展的CSV格式的数据
String data = queryApi.queryRaw(flux2);
System.out.println(data);
}
}