零基础入门NLP之新闻文本分类挑战赛——基于深度学习的文本分类3
此章,我们继续进一步学习基于深度学习的文本分类,了解Transformer的原理和基于Bert的词表示。
一、Transformer
Google于2017年6月发布在arxiv上的一篇文章《Attention is all you need》,提出解决sequence to sequence问题的transformer模型,用全attention的结构代替了lstm,抛弃了之前传统的encoder-decoder模型必须结合cnn或者rnn的固有模式,只用attention,可谓大道至简。文章的主要目的是在减少计算量和提高并行效率的同时不损害最终的实验结果( GLUE 上效果排名第一https://gluebenchmark.com/leaderboard),创新之处在于提出了两个新的Attention机制,分别叫做 Scaled Dot-Product Attention 和 Multi-Head Attention。Transformer作者已经发布其在TensorFlow的tensor2tensor库中。
考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
时间片 t 的计算依赖 t-1 时刻的计算结果,这样限制了模型的并行能力;
顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
1、Transformer模型结构
Transformer的实验室基于机器翻译的,其本质上是一个Encoder-Decoder的结构,编码器由6个编码block组成(encoder每个block由self-attention,FFNN组成),同样解码器是6个解码block组成(decoder每个block由self-attention,encoder-decoder attention以及FFNN组成),与所有的生成模型相同的是,编码器的输出会作为解码器的输入。Transformer可概括为:
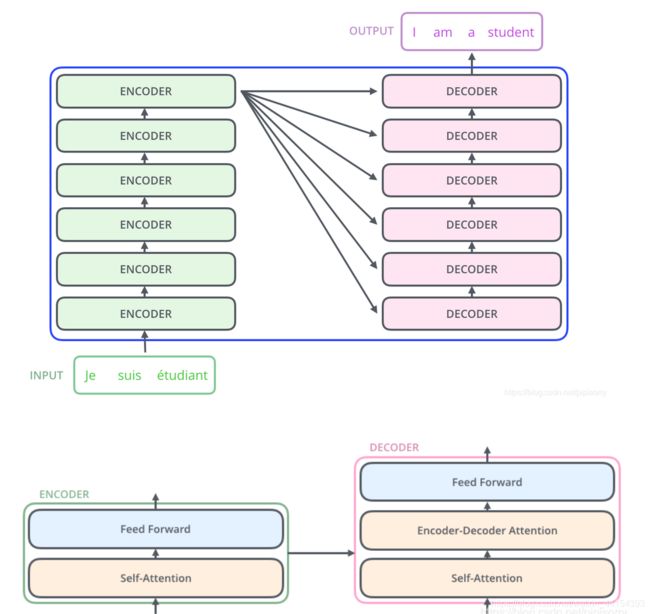
具体模型结构如下图:
Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution。和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。
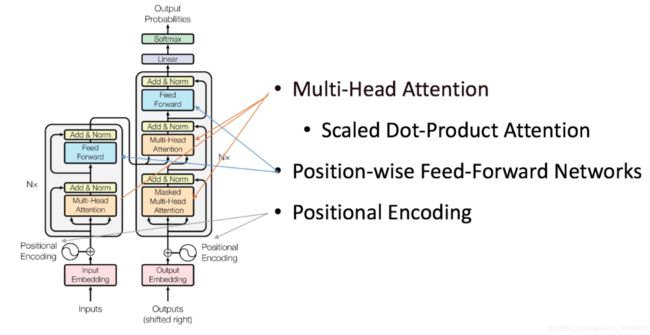
2、Transformer Encoder
Encoder由Nx个相同的layer组成,layer指的就是上图左侧的单元,最左边有个“Nx”(论文中是6x个)。每个Layer由两个sub-layer组成,分别是multi-head self-attention mechanism和fully connected feed-forward network。其中每个sub-layer都加了residual connection和normalisation,即在两个子层中会使用一个残差连接,接着进行层标准化(layer normalization)。因此可以将sub-layer的输出表示为:
sub_layer_output = LayerNorm(x+(SubLayer(x))) \
multi-head self-attention mechanism和fully connected feed-forward network两个sub-layer的解释。
3、Multi-head self-attention
多头注意力机制——点乘注意力的升级版本。attention可由以下形式表示[深度学习:注意力模型Attention Model:Attention机制]:

Multi-head attention:multi-head attention则是通过h个不同的线性变换对Q,K,V进行投影,最后将不同的attention结果拼接起来(很像cnn的思想):

Transformer会在三个地方使用multi-head attention:
-
encoder-decoder attention:输入为encoder的输出和decoder的self-attention输出,其中encoder的self-attention作为 key and value,decoder的self-attention作为query。
-
encoder self-attention:输入的Q、K、V都是encoder的input embedding and positional embedding。
-
decoder self-attention:在decoder的self-attention层中,deocder 都能够访问当前位置前面的位置,输入的Q、K、V都是decoder的input embedding and positional embedding。
Note: 在一般的attention模型中,Q就是decoder的隐层,K就是encoder的隐层,V也是encoder的隐层。所谓的self-attention就是取Q,K,V相同,均为encoder或者decoder的input embedding and positional embedding,更具体为“网络输入是三个相同的向量q, k和v,是word embedding和position embedding相加得到的结果"。
Scaled dot-product attention:不同的attention线性变换的计算采用了scaled dot-product attention,即:

参考资料:
https://blog.csdn.net/qq_41664845/article/details/84969266
二、Bert
1、Bert是什么?
BERT(Bidirectional Encoder Representations from Transformers)于2018年末发布,是我们将在本教程中使用的模型,为读者更好地理解和指导在NLP中使用迁移学习模型提供了实用的指导。BERT是一种预训练语言表示的方法,用于创建NLP从业人员可以免费下载和使用的模型。你可以使用这些模型从文本数据中提取高质量的语言特征,也可以使用你自己的数据对这些模型进行微调,以完成特定的任务(分类、实体识别、问题回答等),从而生成最先进的预测。
2、为什么要使用Bert的嵌入?
首先,这些嵌入对于关键字/搜索扩展、语义搜索和信息检索非常有用。例如,如果你希望将客户的问题或搜索与已经回答的问题或文档化的搜索相匹配,这些表示将帮助准确的检索匹配客户意图和上下文含义的结果,即使没有关键字或短语重叠。
其次,或许更重要的是,这些向量被用作下游模型的高质量特征输入。NLP模型(如LSTMs或CNNs)需要以数字向量的形式输入,这通常意味着需要将词汇表和部分语音等特征转换为数字表示。在过去,单词被表示为惟一索引值(one-hot编码),或者更有用的是作为神经单词嵌入,其中词汇与固定长度的特征嵌入进行匹配,这些特征嵌入是由Word2Vec或Fasttext等模型产生的。与Word2Vec之类的模型相比,BERT提供了一个优势,因为尽管Word2Vec下的每个单词都有一个固定的表示,而与单词出现的上下文无关,BERT生成的单词表示是由单词周围的单词动态通知的。例如,给定两句话:
“The man was accused of robbing a bank.” “The man went fishing by the bank of the river.”
Word2Vec将在两个句子中为单词“bank”生成相同的单词嵌入,而在BERT中为“bank”生成不同的单词嵌入。除了捕获一词多义之类的明显差异外,上下文相关的单词embeddings还捕获其他形式的信息,这些信息可以产生更精确的特征表示,从而提高模型性能。
3、特征
(1)通过联合调节所有层中的左右上下文来预训练深度双向表示
(2)the first fine-tuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outperforming many systems with task-specific architectures
(3)所需计算量非常大。Jacob 说:「OpenAI 的 Transformer 有 12 层、768 个隐藏单元,他们使用 8 块 P100 在 8 亿词量的数据集上训练 40 个 Epoch 需要一个月,而 BERT-Large 模型有 24 层、2014 个隐藏单元,它们在有 33 亿词量的数据集上需要训练 40 个 Epoch,因此在 8 块 P100 上可能需要 1 年?16 Cloud TPU 已经是非常大的计算力了。
(4)预训练的BERT表示可以通过一个额外的输出层进行微调,适用于广泛任务的state-of-the-art模型的构建,比如问答任务和语言推理,无需针对具体任务做大幅架构修改。
(5)一词多义问题
4、训练
不使用传统的从左到右或从右到左的语言模型来预训练BERT。 相反,使用两个新的无监督预测任务预训练BERT,分别是MLM和next sentence prediction。训练所用语料库为the concatenation of BooksCorpus (800M words) and English Wikipedia (2,500M words)
(1)MLM(Cloze task)
A.原理
MLM从输入中随机地掩盖一些token,并且目标是仅基于其上下文来预测被掩盖的单词的原始词汇id。与从左到右的语言模型预训练不同,MLM 目标允许表征融合左右两侧的上下文,从而预训练一个深度双向 Transformer。与masked token对应的最终隐藏向量被输入到词汇表上的输出softmax中。
B.缺点
a.预训练和fine-tuning之间不匹配,因为在fine-tuning期间从未看到[MASK]token。
为了解决这个问题,团队并不总是用实际的[MASK]token替换被“masked”的词汇。相反,训练数据生成器随机选择15%的token。例如在这个句子“my dog is hairy”中,它选择的token是“hairy”。不是总是将选择的token替换为 [MASK], 数据生成器会执行以下过程:
80%的时间:用[MASK]标记替换单词,例如,my dog is hairy → my dog is [MASK]
10%的时间:用一个随机的单词替换该单词,例如,my dog is hairy → my dog is apple
10%的时间:保持单词不变,例如,my dog is hairy → my dog is hairy. 这样做的目的是将表示偏向于实际观察到的单词。
Transformer encoder不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入token的分布式上下文表示。此外,因为随机替换只发生在所有token的1.5%(即15%的10%),这似乎不会损害模型的语言理解能力。
b.每个batch只预测了15%的token,这表明模型可能需要更多的预训练步骤才能收敛。
团队证明MLM的收敛速度略慢于 left-to-right的模型(预测每个token),但MLM在实验上获得的提升远远超过增加的训练成本。
(2)next sentence prediction
许多重要的下游任务,如问答(QA)和自然语言推理(NLI)都是基于理解两个句子之间的关系,这并没有通过语言建模直接获得。为了训练一个理解句子的模型关系,BERT预先训练了一个二进制化的下一句测任务,这一任务可从任何单语语料库( monolingual corpus)中生成。具体地说,当选择句子A和B作为预训练样本时,B有50%的可能是A的下一个句子,也有50%的可能是来自语料库的随机句子。
5、fine-tuning
For fine-tuning, most model hyperparameters are the same as in pre-training, with the exception of the batch size, learning rate, and number of training epochs.
Large data sets (e.g.,100k+ labeled training examples) were far less sensitive to hyperparameter choice than small datasets.
Fine-tuning is typically very fast, so it is reasonable to simply run an exhaustive search over the above parameters and choose the model that performs best on the development set
参考资料:
https://blog.csdn.net/zhiman_zhong/article/details/84392679