c++ 后台服务器开发面试题目总结
文章目录
-
- 1 C++ 中include头文件时尖括号与双引号的区别
-
- 1.1 区别
- 1.2 总结
- 2 c++的封装 继承 多态
- 3 计算机网络的OSI七层模型,每一层的作用是啥
- 4 红黑树的基本问题
- 5 set怎么保证插入不重复的性质
- 6 一次网页的访问从URL开始,说一下整个访问的过程
- 7 TCP和UDP协议的区别
- 7.1 TCP粘包问题
- 8 、三次握手协议的具体过程 断开连接是四次挥手的情况
-
- 8.1 Tcp的四次挥手 timewait怎么解释(详细一点)
- 8.2 三次握手之后,双方怎么知道后续不会丢包
- 9 数据库的事务隔离级别
-
- 9.1 第三个级别怎么解决的 不可重复读的问题的
- 10 HTTP协议和HTTPS协议的区别(HTTP是应用层的协议)
- 11 c++内存的五个存储器以及各自的作用
- 12 一个表,name,subject,score,找出来所有科目都及格的学生名字
- 13 数据库的索引 聚集索引和非聚集索引,聚簇索引 稀疏索引 稠密索引
- 14 list和vector的区别
-
- vector数据结构
- list数据结构
- 15 内存对齐
-
- 之所以要内存对齐,有两方面的原因:
- 16 c++之中的map的种类
- 17 namespace介绍一下:命名空间
- 18 C++内存溢出和内存泄漏?
- 19 B类地址 子网掩码 255.255.255.248 有多少台主机
- 20 进程调度算法(作业调度算法)
- 21 vector的和数组一样连续存储,vector的扩容机制
- 22 c++中 const 和define 的区别的
- 23 引用和指针的区别
- 24 static_cast以及 c++之中的类型转换
- 25 STL的map和set的区别 低层用啥实现的
- 26 STL的理解,STL的优势
- 27 c++智能指针
- 28 虚函数和纯虚函数
- 29 哈希表,哈希冲突 解决办法。
- 30 线程的生命周期(开始 就绪 结束。。。。。)
- 31 构造函数和析构函数的子类基类调用顺序
- 32 Mysql的底层引擎是什么了解吗 innodb索引的b+树
- 33 进程间的通信方式
- 34 线程的同步方式
-
- 34.1 线程同步锁的种类
- 34.2 线程创建的基本方式
- 34.3 线程安全问题
- 35 进程和线程的区别,多进程和多线程编程概念
-
- 35.1 什么是线程安全的
- 36 用户态和内核态
- 37 大数据之中数据的数目是n 选择第k大的数据 (堆排序),时间复杂度是啥?(n-k)O(logk)?
- 38 int (*s[10])(int) s是一个什么数据类型
- 39 写一个函数指针 类似(void)func(这里应该怎么写的)
- 40 SQL语句之中的 delete和 drop的不同
- 41 操作系统中的虚拟内存 :硬盘一部分
- 42 操作系统条件变量
- 42.1 操作系统:写一个生产者,消费者的循环队列 P V原语句
- 43 TCP拥塞控制怎么进行
- 44 linux的内存管理(段页方式)
- 45 关系型数据库和非关系型数据库额区别
- 46 c++几组比较
-
- 46.1 c++之中define vs const
- 46.2 private 和 protect:
- 46.3 struct vs union
- 46.4 友元函数,运算符重载
- 47 vector的扩容机制 以及 vector中push_back操作时间复杂度分析
- 48 B树(B-)、B+树,B*树的简单介绍
- 49 memcpy和strcpy的区别
- 50 经典面试题之new和malloc的区别
- 51 面向对象的特征并简述
- 52 如何避免死锁
- 53 c++类的加载过程
- 54 MySQL 添加列,修改列,删除列
- 55 C语言和c++的区别
-
- C语言中struct和union的区别是什么?
- C和C++中struct的区别是什么?
- C++中的 struct与class的区别是什么?
- 56 C++中基类的析构函数不是虚函数,会带来什么问题
- 57 头文件中的ifndef/define/endif有什么作用
- 58 面试题:char * strcpy(char * strDest,const char * strSrc);
- 59 循环队列的存储空间为 Q(1:50) ,初始状态为 front=rear=50 。经过一系列正常的入队与退队操作后, front=rear=25 ,此后又插入一个元素,则循环队列中的元素个数为( )
- 60 乐观锁与悲观锁的区别
- 61 static
- 62 map的插入的返回值是啥
- 64 io复用问题
- 65 动态链接和静态链接
- 66 map低层红黑树的实现
- 67自定义 结构体作为 map的key 需要注意什么呢
- 68 SQL语句之中的内连接,外连接
- 69 线程池的介绍
1 C++ 中include头文件时尖括号与双引号的区别
1.1 区别
系统自带的头文件用尖括号括起来,表示编译器先在用户的工作目录下搜索头文件,如果搜索不到则到系统默认目录下去寻找,所以双引号一般用于包含用户自己编写的头文件。如:#include “student.h” , #include “XXXX.h” 。
用户自定义的文件用双引号括起来,编译器首先会在用户目录下查找,然后在到C++安装目录(比如VC中可以指定和修改库文件查找路径,Unix和Linux中可以通过环境变量来设定)中查找。所以一般尖括号用于包含标准库文件,如:#include
1.2 总结
- 使用 “xxx.h”,告诉编译器,从当前工作目录开始查找。
- 使用
,告诉编译器,从系统默认目录中去查找; - 当不确定的时候,就使用双引号,系统会从当前工作目录找完成后,然后再去系统默认目录中查找。若 #include “” 查找成功,则遮蔽 #include <> 所能找到的同名文件;否则再按照 #include <> 的方式查找文件。另外标准库头文件都放在 #include <> 所查找的位置。
2 c++的封装 继承 多态
https://blog.csdn.net/ruyue_ruyue/article/details/8211809
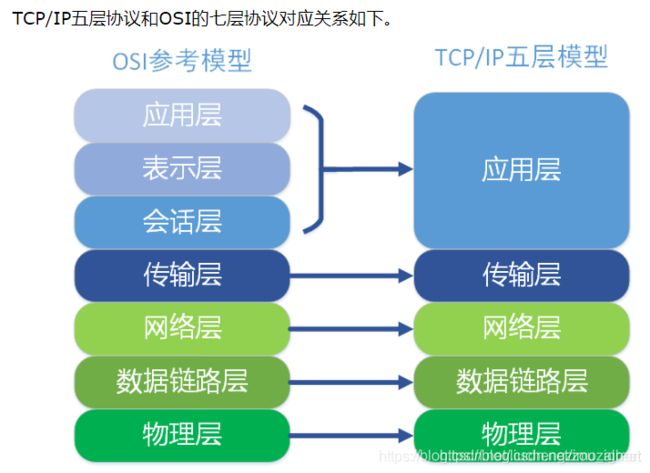
3 计算机网络的OSI七层模型,每一层的作用是啥
https://blog.csdn.net/weixin_34179762/article/details/88729259
计算机网络——五层与七层模型
https://www.cnblogs.com/qishui/p/5428938.html
4 红黑树的基本问题
https://www.jianshu.com/p/e136ec79235c
红黑树是一种含有红黑结点并能自平衡的二叉查找树。它必须满足下面性质:
性质1:每个节点要么是黑色,要么是红色。
性质2:根节点是黑色。
性质3:每个叶子节点(NIL)是黑色。
性质4:每个红色结点的两个子结点一定都是黑色。
性质5:任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
5 set怎么保证插入不重复的性质
https://zhuanlan.zhihu.com/p/83567235
提供迭代器访问元素,但是无法使用迭代器改变元素值,因为 key就是 value,set的元素必须独一无二,因此 insert 用的是 rb_tree 的 insert_unique() 函数。multiset 元素的 key 可以重复。因此 insert 用的是 rb_tree 的insert_equal() 函数。
6 一次网页的访问从URL开始,说一下整个访问的过程
客户端获取URL - > DNS解析 - > TCP连接 - >发送HTTP请求 - >服务器处理请求 - >返回报文 - >浏览器解析渲染页面 - > TCP断开连接
访问一个URL经历了哪些过程
7 TCP和UDP协议的区别
两者最大的不同就是 TCP 提供可靠的传输,而 UDP 提供的是不可靠传输
UDP能够进行广播
https://blog.csdn.net/zhang6223284/article/details/81414149
TCP 和 UDP 的区别
- TCP 是面向连接的,UDP 是面向无连接的
- UDP程序结构较简单
- TCP 是面向字节流的,UDP 是基于数据报的
- TCP 保证数据正确性,UDP 可能丢包
- TCP 保证数据顺序,UDP 不保证
TCP 的顺序问题,丢包问题,流量控制都是通过滑动窗口来解决的,拥塞控制时通过拥塞窗口来解决的
什么是面向连接,什么是面向无连接
在互通之前,面向连接的协议会先建立连接,如 TCP 有三次握手,而 UDP 不会
TCP 为什么是可靠连接
- 通过 TCP 连接传输的数据无差错,不丢失,不重复,且按顺序到达。
- TCP 报文头里面的序号能使 TCP 的数据按序到达
- 报文头里面的确认序号能保证不丢包,累计确认及超时重传机制
- TCP 拥有流量控制及拥塞控制的机制
7.1 TCP粘包问题
https://my.oschina.net/u/4269462/blog/3195211
https://www.cnblogs.com/findumars/p/7486665.html
github的文章 和这个题目无关的
8 、三次握手协议的具体过程 断开连接是四次挥手的情况
8.1 Tcp的四次挥手 timewait怎么解释(详细一点)
https://blog.csdn.net/chrise_/article/details/80449028
https://blog.csdn.net/qq_38950316/article/details/81087809
8.2 三次握手之后,双方怎么知道后续不会丢包
滑动窗口协议
9 数据库的事务隔离级别
9.1 第三个级别怎么解决的 不可重复读的问题的
解决可重复读的方法
有两个策略可以防止这个问题的发生:
(1) 推迟事务2的执行,直至事务1提交或者回退。这种策略在使用锁时应用。
(2) 而在多版本并行控制中,事务2可以被先提交。而事务1,继续执行在旧版本的数据上。当事务1终于尝试提交时,数据库会检验它的结果是否和事务1、事务2顺序执行时一样。如果是,则事务1提交成功。如果不是,事务1会被回退。
参考链接:https://www.cnblogs.com/balfish/p/8298296.html
数据库中的事务,事务的隔离级别
10 HTTP协议和HTTPS协议的区别(HTTP是应用层的协议)
https://www.cnblogs.com/sueyyyy/p/12012570.html
https://blog.csdn.net/xiaoming100001/article/details/81109617
HTTPS和HTTP的区别主要如下:
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
11 c++内存的五个存储器以及各自的作用
https://blog.csdn.net/zou_albert/article/details/107914264
在C++中,内存分成5个区,他们分别是堆、栈、自由存储区、全局/静态存储区和常量存储区。
- 栈:就是那些由编译器 在需要的时候分配,在不需要的时候自动清除变量 的存储区。里面的变量通常是局部变量、函数参数等。
- 堆:就是那些由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete。如果程序员没有释放掉, 那么在程序结束后,操作系统会自动回收。 程序员需要自动释放堆的内存。
- 自由存储区:就是那些由malloc等分配的内存块,他和堆是十分相似的, 不过它是用free来结束自己的生命的。
- 全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量又分为初始化的和未初始化的(初始化的全局变量和静态变量在一块区域,未初始化的全局变量与静态变量在相邻的另一块区域,同时未被初始化的对象存储区可以通过void*来访问和操纵,程序结束后由系统自行释放),在C++里面没有这个区分了,他们共同占用同一块内存区。
- 常量存储区:这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改(当然,你要通过非正当手段也可以修改)
12 一个表,name,subject,score,找出来所有科目都及格的学生名字
SELECT DISTINCT A.name FROM Student A
WHERE A.name not in(
SELECT Distinct S.name FROM Student S WHERE S.score <80)
13 数据库的索引 聚集索引和非聚集索引,聚簇索引 稀疏索引 稠密索引
MySQL (8) 聚集索引 非聚集索引 聚簇索引 稀疏索引 稠密索引
14 list和vector的区别
vector数据结构
vector和数组类似,拥有一段连续的内存空间,并且起始地址不变。
因此能高效的进行随机存取,时间复杂度为o(1);
但因为内存空间是连续的,所以在进行插入和删除操作时,会造成内存块的拷贝,时间复杂度为o(n)。
另外,当数组中内存空间不够时,会重新申请一块内存空间并进行内存拷贝。
list数据结构
list是由双向链表实现的,因此内存空间是不连续的。
只能通过指针访问数据,所以list的随机存取非常没有效率,时间复杂度为o(n);
但由于链表的特点,能高效地进行插入和删除。
与其他序列式容器相比,list和forward_list最大的缺陷是不支持任意位置的随机访问,比如:要访问list 的第6个元素,必须从已知的位置(比如头部或者尾部)迭代到该位置。
deque是一个double-ended queue,它的具体实现不太清楚,但知道它具有以下两个特点:
它支持[]操作符,也就是支持随即存取,并且和vector的效率相差无几,它支持在两端的操作:push_back,push_front,pop_back,pop_front等,并且在两端操作上与list的效率也差不多。
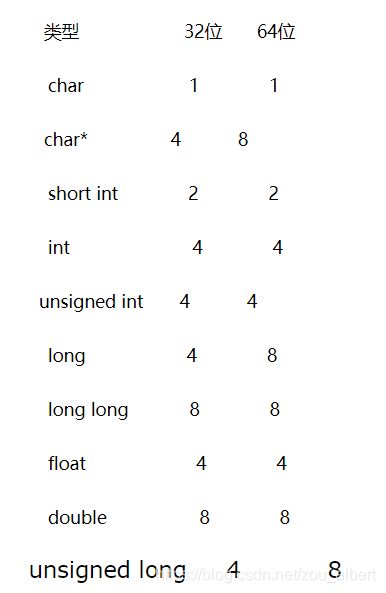
15 内存对齐
之所以要内存对齐,有两方面的原因:
-
平台原因:各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。————- 比如,有些架构的CPU在访问 一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐。
-
性能原因:内存对齐可以提高存取效率。————- 比如,有些平台每次读都是从偶地址开始,如果一个int型(假设为32位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这32bit,而如果存放在奇地址开始的地方,就需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该32bit数据。
https://songlee24.github.io/2014/09/20/memory-alignment/
struct Q{
char c;
int num1;
double num2;
};
struct
{
int i; // 4个字节
char c1; // 1个字节
char c2; // 1个字节
}x1;
struct
{
char c1; // 1个字节
int i; // 4个字节
char c2; // 1个字节
}x2;
struct
{
char c1; // 1个字节
char c2; // 1个字节
int i; // 4个字节
}x3;
int main()
{
printf("%d\n",sizeof(x1)); // 输出8
printf("%d\n",sizeof(x2)); // 输出12
printf("%d\n",sizeof(x3)); // 输出8
return 0;
}
问上述代码中sizeof(Q)为多少? 16 实际上这是考察struct结构地址对齐的问题
struct的对其系数和以下几个关系有关
- 元素大小
- 元素顺序
- #pargma pack参数
https://www.cnblogs.com/zhao-zongsheng/p/9099603.html

对齐规则
- struct中成员在内存中按顺序排列,在没有#pargma pack(n)的情况下,各个成员的对齐系数为自己的长度
- 在有#pargma pack(n)的情况下,各个成员的对齐系数为min(自己的长度,n)
struct整体的对齐系数为对齐系数中最大的 - 依次排列时要满足地址对对齐系数取模为0
16 c++之中的map的种类
- map是一类关联式容器,不允许重复的键值。它的特点是增加和删除节点对迭代器的影响很小,除了操作节点,对其他的节点都没有什么影响。对于迭代器来说,不可以修改键值,只能修改其对应的实值 低层使用红黑树实现的,
- unorder_map与map不同:map的KEY值是有序的,而unorder_map则是无序的,unordered_map的底层是一个防冗余的哈希表(开链法避免地址冲突)
- multimap 和 map 的唯一差别是:元素可以重复,也就是 multimap 允许其元素拥有相同的 key。
- hash_map 和unorder_map类似,前者的空间复杂度最低。
17 namespace介绍一下:命名空间
https://blog.csdn.net/liitdar/article/details/80337871
最典型的例子就是std命名空间,C++标准库中所有标识符都包含在该命名空间中
https://blog.csdn.net/lx_392754/article/details/52220676
18 C++内存溢出和内存泄漏?
1、内存溢出
内存溢出是指程序在申请内存时没有足够的内存空间供其使用。原因可能如下:
(1)内存中加载的数据过于庞大;
(2)代码中存在死循环;
(3)递归调用太深,导致堆栈溢出等;
(4)内存泄漏最终导致内存溢出;
2、内存泄漏
内存泄漏是指使用new申请内存, 但是使用完后没有使用delete释放内存,导致占用了有效内存。
https://www.cnblogs.com/outs/p/8964941.html
https://blog.csdn.net/invisible_sky/article/details/78205461
添加链接描述C++面试常见题目4_内存管理,内存泄露
内存泄漏的几种情况
19 B类地址 子网掩码 255.255.255.248 有多少台主机
根据子网掩码计算最大主机数,广播地址
计算机网络——子网划分(内含习题讲解)
20 进程调度算法(作业调度算法)
常用的操作系统进程(作业)调度算法
21 vector的和数组一样连续存储,vector的扩容机制
22 c++中 const 和define 的区别的
const 与 #define 区别
- 定义常量角度: const 定义的常数是变量也带类型, #define 定义的只是个常数 不带类型。
- 就起作用的阶段而言:define是在编译的预处理阶段起作用,而const是在编译、运行的时候起作用。
- 就起作用的方式而言: define只是简单的字符串替换,没有类型检查。而const有对应的数据类型,是要进行判断的,可以避免一些低级的错误,例如:正因为define只是简单的字符串替换会导致边界效应,具体举例可以参考下面代码:
#define N 2+3 //我们预想的N值是5,我们这样使用N
double a = N/2; //我们预想的a的值是2.5,可实际上a的值是3.5
- 占用空间而言:
#define PI 3.14 //预处理后 占用代码段空间
const float PI=3.14; //本质上还是一个 float,占用数据段空间
- 从是否可以再定义的角度而言: const不足的地方,是与生俱来的,const不能重定义,而#define可以通过#undef取消某个符号的定义,再重新定义。
- 从代码调试的方便程度而言: const常量可以进行调试的,define是不能进行调试的,因为在预编译阶段就已经替换掉了。
- 是否可以做函数参数:宏定义不能作为参数传递给函数,const常量可以在函数的参数列表中出现
23 引用和指针的区别
空初大小多变const
- 空:指针有自己的一块空间,而引用只是一个别名;
- 初:指针可以被初始化为NULL,而引用必须被初始化且必须是一个已有对象 的引用;
- 大小:使用sizeof看一个指针的大小是4,而引用则是被引用对象的大小;
- 多:指针可以有多级指针(p),而引用至多一级;
- 变:指针在使用中可以指向其它对象,但是引用只能是一个对象的引用,不能 被改变;
- 可以有const指针,但是没有const引用;
https://blog.csdn.net/will130/article/details/48730725
24 static_cast以及 c++之中的类型转换
C++中四种类型转换是:static_cast, dynamic_cast, const_cast, reinterpret_cast
1、const_cast
用于将const变量转为非const
2、static_cast
用于各种隐式转换,比如非const转const,void*转指针等, static_cast能用于多态向上转化,如果向下转能成功但是不安全,结果未知;
3、dynamic_cast
用于动态类型转换。只能用于含有虚函数的类,用于类层次间的向上和向下转化。只能转指针或引用。向下转化时,如果是非法的对于指针返回NULL,对于引用抛异常。要深入了解内部转换的原理。
向上转换:指的是子类向基类的转换
向下转换:指的是基类向子类的转换
它通过判断在执行到该语句的时候变量的运行时类型和要转换的类型是否相同来判断是否能够进行向下转换。
4、reinterpret_cast
几乎什么都可以转,比如将int转指针,可能会出问题,尽量少用;
5、为什么不使用C的强制转换?
C的强制转换表面上看起来功能强大什么都能转,但是转化不够明确,不能进行错误检查,容易出错。
https://www.jianshu.com/p/1a2310f1b58e
25 STL的map和set的区别 低层用啥实现的
26 STL的理解,STL的优势
STL的优点:
1.实现数据结构和算法的分离,使得STL非常通用。
2.STL具有高可重用性,高性能,高移植性,夸平台的优点。
-
高可重用性:STL中几乎所有的代码都采用了模板类和模板函数的方式实现,代码重用性高。
-
高性能:如map,采用红黑数的变体实现,效率高。
-
高移植性:STL模块很容易移植。
27 c++智能指针
C++里面的四个智能指针: auto_ptr, shared_ptr, weak_ptr, unique_ptr 其中后三个是c++11支持,并且第一个已经被11弃用。
为什么要使用智能指针:
智能指针的作用是管理一个指针,因为存在以下这种情况:申请的空间在函数结束时忘记释放,造成内存泄漏。使用智能指针可以很大程度上的避免这个问题,因为智能指针就是一个类,当超出了类的作用域是,类会自动调用析构函数,析构函数会自动释放资源。所以智能指针的作用原理就是在函数结束时自动释放内存空间,不需要手动释放内存空间。
- auto_ptr(c++98的方案,cpp11已经抛弃)
采用所有权模式。
auto_ptr< string> p1 (new string ("I reigned lonely as a cloud.”));
auto_ptr p2;
p2 = p1; //auto_ptr不会报错.
此时不会报错,p2剥夺了p1的所有权,但是当程序运行时访问p1将会报错。所以auto_ptr的缺点是:存在潜在的内存崩溃问题!
- unique_ptr(替换auto_ptr)
unique_ptr实现独占式拥有或严格拥有概念,保证同一时间内只有一个智能指针可以指向该对象。它对于避免资源泄露(例如“以new创建对象后因为发生异常而忘记调用delete”)特别有用。
采用所有权模式,还是上面那个例子
复制代码
1
2
3
unique_ptr p3 (new string (“auto”)); //#4
unique_ptr p4; //#5
p4 = p3;//此时会报错!!
编译器认为p4=p3非法,避免了p3不再指向有效数据的问题。因此,unique_ptr比auto_ptr更安全。
另外unique_ptr还有更聪明的地方:当程序试图将一个 unique_ptr 赋值给另一个时,如果源 unique_ptr 是个临时右值,编译器允许这么做;如果源 unique_ptr 将存在一段时间,编译器将禁止这么做,比如:
unique_ptr pu1(new string (“hello world”));
unique_ptr pu2;
pu2 = pu1; // #1 not allowed
unique_ptr pu3;
pu3 = unique_ptr(new string (“You”)); // #2 allowed
其中#1留下悬挂的unique_ptr(pu1),这可能导致危害。而#2不会留下悬挂的unique_ptr,因为它调用 unique_ptr 的构造函数,该构造函数创建的临时对象在其所有权让给 pu3 后就会被销毁。这种随情况而已的行为表明,unique_ptr 优于允许两种赋值的auto_ptr 。
注:如果确实想执行类似与#1的操作,要安全的重用这种指针,可给它赋新值。C++有一个标准库函数std::move(),让你能够将一个unique_ptr赋给另一个。例如:
unique_ptr ps1, ps2;
ps1 = demo(“hello”);
ps2 = move(ps1);
ps1 = demo(“alexia”);
cout << *ps2 << *ps1 << endl;
- shared_ptr
shared_ptr实现共享式拥有概念。多个智能指针可以指向相同对象,该对象和其相关资源会在“最后一个引用被销毁”时候释放。从名字share就可以看出了资源可以被多个指针共享,它使用计数机制来表明资源被几个指针共享。可以通过成员函数use_count()来查看资源的所有者个数。除了可以通过new来构造,还可以通过传入auto_ptr, unique_ptr,weak_ptr来构造。当我们调用release()时,当前指针会释放资源所有权,计数减一。当计数等于0时,资源会被释放。
shared_ptr 是为了解决 auto_ptr 在对象所有权上的局限性(auto_ptr 是独占的), 在使用引用计数的机制上提供了可以共享所有权的智能指针。
成员函数:
use_count 返回引用计数的个数
unique 返回是否是独占所有权( use_count 为 1)
swap 交换两个 shared_ptr 对象(即交换所拥有的对象)
reset 放弃内部对象的所有权或拥有对象的变更, 会引起原有对象的引用计数的减少
get 返回内部对象(指针), 由于已经重载了()方法, 因此和直接使用对象是一样的.如 shared_ptr sp(new int(1)); sp 与 sp.get()是等价的
- weak_ptr
weak_ptr 是一种不控制对象生命周期的智能指针, 它指向一个 shared_ptr 管理的对象. 进行该对象的内存管理的是那个强引用的 shared_ptr. weak_ptr只是提供了对管理对象的一个访问手段。weak_ptr 设计的目的是为配合 shared_ptr 而引入的一种智能指针来协助 shared_ptr 工作, 它只可以从一个 shared_ptr 或另一个 weak_ptr 对象构造, 它的构造和析构不会引起引用记数的增加或减少。weak_ptr是用来解决shared_ptr相互引用时的死锁问题,如果说两个shared_ptr相互引用,那么这两个指针的引用计数永远不可能下降为0,资源永远不会释放。它是对对象的一种弱引用,不会增加对象的引用计数,和shared_ptr之间可以相互转化,shared_ptr可以直接赋值给它,它可以通过调用lock函数来获得shared_ptr。
class B;
class A
{
public:
shared_ptr pb_;
~A()
{
cout<<“A delete\n”;
}
};
class B
{
public:
shared_ptr pa_;
~B()
{
cout<<“B delete\n”;
}
};
void fun()
{
shared_ptr pb(new B());
shared_ptr pa(new A());
pb->pa_ = pa;
pa->pb_ = pb;
cout<
int main()
{
fun();
return 0;
}
可以看到fun函数中pa ,pb之间互相引用,两个资源的引用计数为2,当要跳出函数时,智能指针pa,pb析构时两个资源引用计数会减一,但是两者引用计数还是为1,导致跳出函数时资源没有被释放(A B的析构函数没有被调用),如果把其中一个改为weak_ptr就可以了,我们把类A里面的shared_ptr pb_; 改为weak_ptr pb_; 运行结果如下,这样的话,资源B的引用开始就只有1,当pb析构时,B的计数变为0,B得到释放,B释放的同时也会使A的计数减一,同时pa析构时使A的计数减一,那么A的计数为0,A得到释放。
注意的是我们不能通过weak_ptr直接访问对象的方法,比如B对象中有一个方法print(),我们不能这样访问,pa->pb_->print(); 英文pb_是一个weak_ptr,应该先把它转化为shared_ptr,如:shared_ptr p = pa->pb_.lock(); p->print();
https://www.nowcoder.com/tutorial/93/a34ed23d58b84da3a707c70371f59c21
智能指针的举例子
28 虚函数和纯虚函数
https://www.cnblogs.com/inception6-lxc/p/8597326.html
https://blog.csdn.net/zxxkkkk/article/details/109363441
29 哈希表,哈希冲突 解决办法。
https://blog.csdn.net/u011109881/article/details/80379505
https://blog.csdn.net/z_ryan/article/details/78760944?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.edu_weight&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.edu_weight
30 线程的生命周期(开始 就绪 结束。。。。。)
31 构造函数和析构函数的子类基类调用顺序

32 Mysql的底层引擎是什么了解吗 innodb索引的b+树
MySQL中四种常用存储引擎的介绍
1>.InnoDB支持事物,而MyISAM不支持事物
2>.InnoDB支持行级锁,而MyISAM支持表级锁
3>.InnoDB支持MVCC, 而MyISAM不支持
4>.InnoDB支持外键,而MyISAM不支持
5>.InnoDB不支持全文索引,而MyISAM支持。(X)
33 进程间的通信方式
进程通信:
每个进程各自有不同的用户地址空间,任何一个进程的全局变量在另一个进程中都看不到,所以进程之间要交换数据必须通过内核,在内核中开辟一块缓冲区,进程A把数据从用户空间拷到内核缓冲区,进程B再从内核缓冲区把数据读走,内核提供的这种机制称为进程间通信。
IPC的方式通常有管道(包括无名管道和命名管道)、消息队列、信号量、共享存储、Socket、Streams等。其中 Socket和Streams支持不同主机上的两个进程IPC。
进程间的八种通讯方式
1.管道:速度慢,容量有限,只有父子进程能通讯。
2.消息队列:容量受到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题。
3.信号量:不能传递复杂消息,只能用来同步
4.共享内存区:能够很容易控制容量,速度快,但要保持同步,比如一个进程在写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全,当然,共享内存区同样可以用作线程间通讯,不过没这个必要,线程间本来就已经共享了同一进程内的一块内存。
5.套接字: 可用于不同机器间的进程通信。
那种最快:
几种方式的比较:
管道:速度慢,容量有限
消息队列:容量受到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题。
信号量:不能传递复杂消息,只能用来同步
共享内存区:能够很容易控制容量,速度快,但要保持同步,比如一个进程在写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全,当然,共享内存区同样可以用作线程间通讯,不过没这个必要,线程间本来就已经共享了一块内存的。
34 线程的同步方式
- 临界区(Critical Section)、互斥对象(Mutex):主要用于互斥控制;都具有拥有权的控制方法,只有拥有该对象的线程才能执行任务,所以拥有,执行完任务后一定要释放该对象。
- 信号量(Semaphore)、事件对象(Event):事件对象是以通知的方式进行控制,主要用于同步控制
https://blog.csdn.net/s_lisheng/article/details/74278765
https://www.notown.club/?p=463
34.1 线程同步锁的种类
https://blog.csdn.net/guoxiang3538/article/details/79376191
34.2 线程创建的基本方式
- C++ 11新特性中,已经可以使用std::thread来创建线程了,
- Windows系统为我们提供了相关API,我们可以使用他们来进行多线程编程。
https://www.cnblogs.com/codingmengmeng/p/5913068.html
34.3 线程安全问题
35 进程和线程的区别,多进程和多线程编程概念
35.1 什么是线程安全的
如果多线程的程序运行结果是可预期的,而且与单线程的程序运行结果一样,那么说明是“线程安全”的。
36 用户态和内核态
虽然用户态下和内核态下工作的程序有很多差别,但最重要的差别就在于特权级的不同,即权力的不同。运行在用户态下的程序不能直接访问操作系统内核数据结构和程序,
当我们在系统中执行一个程序时,大部分时间是运行在用户态下的,在其需要操作系统帮助完成某些它没有权力和能力完成的工作时就会切换到内核态,
37 大数据之中数据的数目是n 选择第k大的数据 (堆排序),时间复杂度是啥?(n-k)O(logk)?
选择第k大的数据
38 int (*s[10])(int) s是一个什么数据类型
39 写一个函数指针 类似(void)func(这里应该怎么写的)
提示:函数的值是int 并且函数的返回值也是int
40 SQL语句之中的 delete和 drop的不同
41 操作系统中的虚拟内存 :硬盘一部分
https://www.cnblogs.com/Benjious/p/11611431.html
虚拟内存
42 操作系统条件变量
42.1 操作系统:写一个生产者,消费者的循环队列 P V原语句
https://www.cnblogs.com/lustar/p/7689059.html
43 TCP拥塞控制怎么进行
44 linux的内存管理(段页方式)
45 关系型数据库和非关系型数据库额区别
https://blog.csdn.net/oChangWen/article/details/5342330
46 c++几组比较
46.1 c++之中define vs const
C语言之const与define区别
修饰变量,使其不能被修改
- 修饰函数参数,表明输入的参数在参数内不能被修改
修饰指针
- 常量指针,指向的内容不能被修改,即指向“常量”的指针 , const int *p
- 指针常量,指针的指向不能改变,即指针类型的常量,int * const p
- 修饰类的成员函数,表明其是常函数,即不能修改类的成员变量,const成员函数斌调用非const成员函数,因为非const成员函数可能会修改成员变量
46.2 private 和 protect:
46.3 struct vs union
46.4 友元函数,运算符重载
47 vector的扩容机制 以及 vector中push_back操作时间复杂度分析
http://blog.sina.com.cn/s/blog_a2a6dd380102w73e.html
48 B树(B-)、B+树,B*树的简单介绍
B树、B-树、B+树、B*树之间的关系
B树和B+树区别:
关键字数量不同:B+树分支结点M个关键字,叶子节点也有M个;B树分支结点则存在 k-1 个关键码
数据存储位置不同:B+树数据存储在叶子结点上;B树存储在每个结点上;
查询不同:B+树是从根节点到叶子节点的路径;B树是只需要找到数据就可以
分支节点存储信息不同:B+树存索引信息;B树存的是数据关键字
49 memcpy和strcpy的区别
strcpy针对字符串
memcpy可以是数组、对象、字符串等,需要指定长度
50 经典面试题之new和malloc的区别
重点在构造函数不同
- 属性:
new/delete是C++关键字,需要编译器支持。malloc/free是库函数,需要头文件支持。 - 参数:
使用new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算。而malloc则需要显式地指出所需内存的尺寸。 - 返回类型
new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无须进行类型转换,故new是符合类型安全性的操作符。而malloc内存分配成功则是返回void * ,需要通过强制类型转换将void*指针转换成我们需要的类型。 - 分配失败
new内存分配失败时,会抛出bac_alloc异常。malloc分配内存失败时返回NULL。 - 自定义类型
- new会先调用operator new函数,申请足够的内存(通常底层使用malloc实现)。然后调用类型的构造函数,初始化成员变量,最后返回自定义类型指针。delete先调用析构函数,然后调用operator delete函数释放内存(通常底层使用free实现)。
- malloc/free是库函数,只能动态的申请和释放内存,无法强制要求其做自定义类型对象构造和析构工作。
-
重载
C++允许重载new/delete操作符,特别的,布局new的就不需要为对象分配内存,而是指定了一个地址作为内存起始区域,new在这段内存上为对象调用构造函数完成初始化工作,并返回此地址。而malloc不允许重载。 -
内存区域
new操作符从自由存储区(free store)上为对象动态分配内存空间,而malloc函数从堆上动态分配内存。自由存储区是C++基于new操作符的一个抽象概念,凡是通过new操作符进行内存申请,该内存即为自由存储区。而堆是操作系统中的术语,是操作系统所维护的一块特殊内存,用于程序的内存动态分配,C语言使用malloc从堆上分配内存,使用free释放已分配的对应内存。自由存储区不等于堆,如上所述,布局new就可以不位于堆中。
https://blog.csdn.net/nie19940803/article/details/76358673
51 面向对象的特征并简述
包括四大基本特征和五大基本原则。
特征:抽象、继承、多态、封装
原则:单一职责原则、开放封闭原则、替换原则、依赖原则、接口分离原则
面向对象的特征并简述
52 如何避免死锁
产生死锁的四个必要条件:
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求和保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不可抢占条件:进程已获得的资源,在末使用完之前,不能强行剥夺,只能在进程使用完时由自己释放。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
https://blog.csdn.net/weixin_41969690/article/details/107617634
53 c++类的加载过程
https://my.oschina.net/alphajay/blog/5029
- 分配空间(Allocation)
- 初始化(Initialization) ( 对象的初始化是通过初始化列表来完成,而对象的赋值则才是通过构造函数,或者更准确的说应该是构造函数的实现体。)
54 MySQL 添加列,修改列,删除列
ALTER TABLE:添加,修改,删除表的列,约束等表的定义。
查看列:desc 表名;
修改表名:alter table t_book rename to bbb;
添加列:alter table 表名 add column 列名 varchar(30);
删除列:alter table 表名 drop column 列名;
修改列名MySQL: alter table bbb change nnnnn hh int;
修改列名SQLServer:exec sp_rename’t_student.name’,‘nn’,‘column’;
修改列名Oracle:lter table bbb rename column nnnnn to hh int;
修改列属性:alter table t_book modify name varchar(22);
55 C语言和c++的区别
C与C++的最大区别:在于它们的用于解决问题的思想方法不一样。之所以说C++比C更先进,是因为“ 设计这个概念已经被融入到C++之中
- 设计思想上:
C++是面向对象的语言,而C是面向过程的结构化编程语言
面向过程的语言:
优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源;比如单片机、嵌入式开发、 Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
缺点:没有面向对象易维护、易复用、易扩展
面向对象的语言:
优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统 更加灵活、更加易于维护
缺点:性能比面向过程低
-
语法上:
C++具有封装、继承和多态三种特性
C++相比C,增加多许多类型安全的功能,比如强制类型转换、
C++支持范式编程,比如模板类、函数模板等
C语言和c++的区别
C语言中struct和union的区别是什么?
C和C++中struct的区别是什么?
C语言中的struct与C++中的struct的区别表现在以下3个方面:
(1) C语言的struct不能有函数成员,而C++的struct可以有。
(2) C语言的struct中数据成员没有private、public和protected访问权限的设定,而C++ 的struct的成员有访问权限设定。
(3) C语言的struct是没有继承关系的,而C++的struct却有丰富的继承关系。
C语言中的struct是用户自定义数据类型,它是没有权限设置的,它只能是一些变量的集合体,虽然可以封装数据却不可以隐藏数据,而且成员不可以是函数。为 了和C语言兼容,C++中就引入了 struct关键字。C++语言中的struct是抽象数据类型 (ADT),它支持成员函数的定义,同时它增加了访问权限,它的成员函数默认访问权限为 public。
C++中的 struct与class的区别是什么?
具体而言,在C++中,class和struct做类型定义时只有两点区别:
(1) 默认继承权限不同。class继承默认是private继承,而struct继承默认是public继承;
(2) class还用于定义模板参数,就像typename,但关键字struct不用于定义模板参数。
56 C++中基类的析构函数不是虚函数,会带来什么问题
C++中基类的析构函数不是虚函数,会带来什么问题
57 头文件中的ifndef/define/endif有什么作用
https://blog.csdn.net/wangdd_199326/article/details/81324804
58 面试题:char * strcpy(char * strDest,const char * strSrc);
面试题:char * strcpy(char * strDest,const char * strSrc);
59 循环队列的存储空间为 Q(1:50) ,初始状态为 front=rear=50 。经过一系列正常的入队与退队操作后, front=rear=25 ,此后又插入一个元素,则循环队列中的元素个数为( )
https://www.nowcoder.com/questionTerminal/8da86fee838348af931e2b86a2c160bc
60 乐观锁与悲观锁的区别
61 static
修饰全局变量
修饰全局变量,不初始化默认初始为0,存储在静态存储区,从声明到程序结束一直存在
修饰局部变量
也存储在静态存储区,作用域是局部作用域,当定义他的函数或者语句块结束时,作用域结束,但该变量并没有被销毁,只不过我们不能访问,直到该函数再次被调用
修饰类的数据成员
不属于类的对象,类内声明,类外初始化,类的静态成员变量被所有对象共享,保证了共享性,又具备安全性
修饰类的成员函数
静态成员函数只能访问静态成员变量,不能访问非静态成员函数,原因是静态成员函数不与任何对象绑定,因此不包含this指针,在静态成员函数内部不能直接使用this指针,因此不能访问类的非静态成员变量
修饰函数
即静态函数,仅在声明它的cpp文件中使用,其他文件不可使用
面试例子
static关键字的作用,修饰函数有什么用?
加粗样式static修饰的函数叫静态函数,包括两种
静态函数出现在类里,则它是一个静态成员函数。静态成员函数不与任何对象绑定,因此不包含this指针,在静态成员函数内部不能直接使用this指针,即不能直接访问普通成员函数;静态成员函数属于类本身,在类加载时就会分配内存,可以通过类名直接去访问;虽然静态成员函数不属于类对象,但是可以通过类对象访问静态成员函数。
普通的全局的静态函数。限定在本源码文件中,不能在其他文件调用(普通函数的定义和声明默认情况下都是extern的,即可被其他文件调用)。故好处在于:1)其他文件中可以定义相同名字的函数。
62 map的插入的返回值是啥
64 io复用问题
IO多路复用(IO Multiplexing)
65 动态链接和静态链接
66 map低层红黑树的实现
67自定义 结构体作为 map的key 需要注意什么呢
68 SQL语句之中的内连接,外连接
left join (左连接):返回包括左表中的所有记录和右表中连接字段相等的记录。
right join (右连接):返回包括右表中的所有记录和左表中连接字段相等的记录。
inner join (等值连接或者叫内连接):只返回两个表中连接字段相等的行。
full join (全外连接):返回左右表中所有的记录和左右表中连接字段相等的记录。
左连接 ,右连接,内连接和全外连接的4者区别
69 线程池的介绍
C++11并发学习之六:线程池的实现
线程池的原理及C++线程池的封装实现