怎么更好的训练一个会数学推理的LLM大模型呢?
前言
大模型如火如荼,最近越来越多的工作针对代码和数学两个技能点进行了单独训练,相继推出了math和code大模型。
今天我们就先来看看截止目前,一些已经针对数学优化的开源工作。一共涉及到四篇比较出色的paper。
在最后也进行了一点简单的总结,供大家参考,一起学习,共同进步。
RFT
论文:https://arxiv.org/pdf/2308.01825.pdf
本文首先给出了一个经验:那就是训练的数据集量级越大效果越好,尤其是当基座不是那么好的时候,更需要大量的SFT的数据集来增强最终的效果。

1/2代表用了总数据量的一半,ICL代表8-shot。大模型需要的数据量和参数量到底是怎样一个关系到目前为止也没有一个确切定量的关系,作者这里转而从loss来定量看这个问题,可以看到loss越小代表着模型越好,当模型比较好时,只需要少量的SFT数据集就可以到达较好的效果且继续增加SFT量级时带来的额外收益不大,当模型比较差时,则需要更多的SFT数据来训练模型以达到更好的效果。
用预训练loss这个指标来衡量基座模型好坏是具有一定参考价值的,并且虽然不同模型的loss由于训练数据等不同,loss不能完全可比,但是仍然具有一定规律,作者整理分析了一些模型如下:

红色是采用few-shot,蓝色是采用sft,可以看到最终效果和预训练loss是具有一定相关性的。
基于上面第一幅图的结论,增加训练集量级是可以带来最终收益的,所以目标就变成了训练集的数据增强,SFT训练集无法就是一个
作者首先研究了不同解题候选个数K的影响如下:

在进行了拒绝采样后,可能会有生成相同的解题思路,为此需要去重,而图中的no dedup就代表不进行去重,可以看到去不去重影响不大,且去重后更好一些,进一步证明收益主要来源于多解题思路而不是存粹的数量。同时也可以看到增加解题思路越大收益越大,但是随着越来越多,收益增加速度也放缓了,相比于第一幅图增加量级带来的收益曲线相比这个这里的增长曲线速度是变缓的,毕竟这里只是增加了解题思路,相比于直接增加题目效果还是差一些(这里其实从接下来要介绍的第二篇paperWizardMath也可以佐证,WizardMath是直接增加题目,效果很棒)。
同时作者进一步从不同的模型进行采样,进一步汇总各种解题思路,效果进一步提升。:

值得庆幸的是作者开源了数据集和代码,大家可以直接复现。
WizardMath
论文:https://arxiv.org/pdf/2308.09583.pdf


WizardMath是在llama2 基座上做的。
其最大的idea就是通过进化学习来生成了一批具有更大难度的数学问题(如第一幅图),其实这是一个系列,最早的一篇paper是WizardLM,后面顺势推出了WizardCode,这是第三篇WizardMath,效果都是出奇的好。
除了SFT,又使用了强化学习进行了优化,具体的就是有两个rm模型,一个是对进化后的Instruction进行打分(具体使用的是Wizard-E),另外就是对response每个步骤进行打分(具体使用的是chatgpt)。
目前在GSM8k榜单上,在开源模型中,WizardMath效果也是名列前茅的。


比较遗憾的是,WizardMath没有开源了进化的数据,也没有开源进化的指令;不过WizardLM开源了进化的指令,可以进行一波参考。
MAMMOTH
论文:https://arxiv.org/pdf/2309.05653.pdf
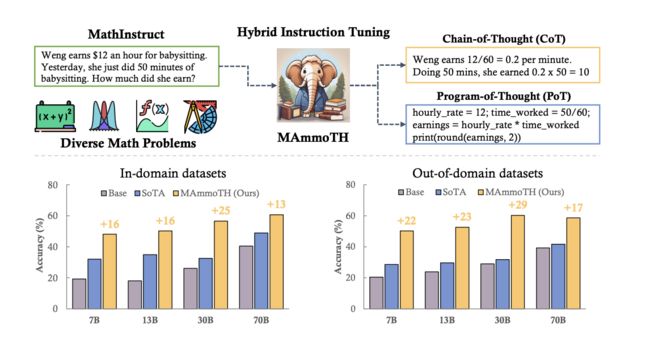
该篇paper的最大贡献有两个;第一就是除了常用的GSM8k和math两个数据集进一步收集了一些相关的其他数学训练集如下:

其次就是引入了Pot,之前解决数学问题都是采用Cot,Cot就是我们常理解的一步一步给出解题步骤,而Pot就是通过写程序来解决,一个形象化的case如下:

Pot相比于Cot来说,在得到结果的过程中还要借助一些编程API运行得到最终结果。
效果如下:

可以看到,整体上可以追平WizardMath,且在code llama上热启比llama2 会好一些,同时论文中强调MAMMOTH的泛化性更好即在和训练集不是同源的benchmark上效果更好:

不过这应该是得益于开头说的MAMMOTH训练集除了GSM8k和math还增加了一些其他的,而WizardMath其实只用了GSM8k和math。当然作者也对各个数据集增益做了消融:

可以看到新增加的几个训练集对GSM8k和math没有带来多少额外的大幅增益,主要是提高别的benchmark的泛化性。
另外需要说明一点的是,论文对GSM8k和math评测都是采用了pot,而对一些比如多选题的benchmark只能采用cot了,因为作者发现pot的效果好于cot:

其中SoTA (GSM + MATH CoT)就是WizardMath,可以看到采用cot相比于pot效果会差一些,但是混合pot和cot的数据后,效果会进一步提升。
值得庆幸的是MAMMOTH开源了它的SFT数据集,量级一共是260k,这一点比WizardMath好一些,更有利于复现,因为llama2和code llama都是开源的,大家可以完全试试,效果也是直逼WizardMath。
MathGLM
这篇paper主要关注的是语言大模型能不能解决算数问题?尤其是超过8位数的乘法运算,以及涉及小数和分数的运算?
论文:https://arxiv.org/pdf/2309.03241.pdf
作者首先对运算做了汇总:运算上分为加减乘除和指数运算,具体数值形式上又分为整数,分数,百分数,负数等等:

然后作者用python脚本去生成训练样本,和人类运算一样,对于复杂问题,需要一步一步运算给出整个答案

同时对于Tokenization的过程是将每个数字和运算单独编码如下:

效果当然是不错的了:
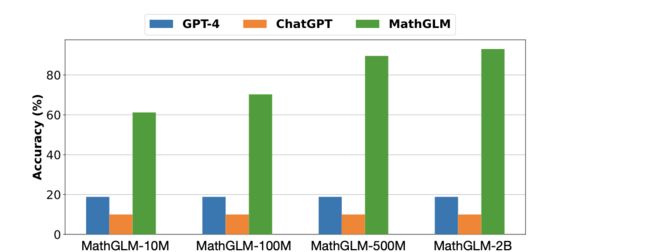
同时作者也开源了他们的数据集可以下载,复现一波。
总结
(1)扩量
在比较好的基座模型下,只需要少量的SFT数据即可达到很好的效果,如果基座较差,那么就需要更多的SFT数据(当然质量也得保证住)才可以追平。
基于这个经验,那么增大SFT数据量必然是没错的,因为我们无法很精确的衡量手头的基座模型到底有多好,也就很难确定到底需要多少SFT数据(也可能只猜个大概量级),可实际操作的时候还是不断加量,直到模型效果收敛,只能说当你的基座模型好时,可能很快就可以看到收敛(或者说加量带来的收益越来越微乎其微),当你的基座比较差时,需要很多数据且很多算力来探究到这个天花板。
那么能够维持不断加量来做实操实验的前提就是手头得有源源不断的数据,且是高质量的,这样才有机会来探究天花板,可实际情况是大多时候我们不可能有海量的数据,就比如今天我们探讨的训练数学能力所使用的GSM8K,他的总量级是一定的,当我们全部用上的时候,发现效果依然在上升怎么办呢?想继续加量,可是已经没有像GSM8K这样好的数据了。
当然最好的方法就是人工去收集,这样成本太高;于是我们就可以看到上面几篇paper思路其实都可以抽象为加量,有的是想办法加量prompt(WizardMath的进化prompt,MAMMOTH多找了一些开源数据集),有的是想办法在没有更好的prompt前提下加量resposne(RFT的一道题搞多个解题思路,MAMMOTH引入pot,其实也是一种更特殊的解题思路即用程序来解)。
我们可以结合一下:通过进化学习来扩充prompt,多解题思路来进一步扩散response,这样就可以快速得到源源不断的一批高质量SFT数据,然后就可以去探索当前自己使用基座的天花板啦!当然选的基座越好,越很快就能探索到啦
(2)逻辑和算数
另外就是对于数据题目,能够进行推理逻辑和算对数可以看成是两个能力,假设一道数学题是:“小红有五个苹果,又买了三个,现在一共多少个?”如果模型给出 5 + 3 = 8 5+3=8 5+3=8是最好的,如果给出 5 + 3 = 7 5+3=7 5+3=7,那起码说明它get到了逻辑,知道用加法而不是除法减法等等。学会逻辑很重要,至于数算对算不对也是个基础能力,比如MathGLM也对其的探索,甚至我们是不是可以借助计算器来解,不一定非的大模型来做算对数这件事,大模型如果能很好的学会逻辑,这个价值本身就很大了。
不过返回头来说“小红有五个苹果,又买了三个,现在一共多少个?”这个例子过于简单,如果一个稍微复杂一点的例子,是很难将逻辑和算数解藕开的,总不能先生成一点逻辑,遇到算数就停下用计算器算一下,然后接着模型推理吧,那么如何将算数这一能力挪出去且又能让模型重点做逻辑部分呢?MAMMOTH中的POT给了我们一个思路,那就是转化成编程,把算数挪出去给编程API跑得到最终结果。
还有没有更好的结合方式,以及大模型究竟适不适合做算数这一问题,它是不是只学会逻辑就好了呢?大家可以多多探索。
关注
欢迎关注,下期再见啦~
知乎,csdn,github,微信公众号