Seata 源码篇之核心思想 - 01
Seata 源码篇之核心思想 - 01
- 引言
- 基础架构
- 数据源代理
- 分支事务提交和回滚
- 隔离级别
-
- 解决脏写
- 读未提交
- 读已提交
- 小结
笔者个人项目中使用到了seata来做分布式事务管理,面试过程中也经常被问到seata的原理,seata源码本身也不是很复杂,所以准备出一个Seata源码大白话解读系列。
本系列文章编撰过程主要参考Seata官网提供的相关源码解读文章,附加笔者个人理解,如有不正确,欢迎各位大佬在评论区指出。
参考资料:
- Seata官网提供的系列源码解析文章
对Seata框架不了解的可以先阅读一下下面这篇文章:
- Seata框架使用和基本原理
引言
分布式事务目前的解决方案主要分为侵入式和无侵入式的方案:
- 无侵入式方案主要是基于XA的二阶段提交协议,缺点就是资源锁定周期长,还存在单点故障等问题。
- 侵入式方案的典型有TCC,SAGA 和 基于消息队列事务消息实现的最终一致性
Seata同时支持无侵入式和侵入式两种实现方式,本系列前半部分主要聚焦于无侵入式的实现;
基础架构
Seata的设计思路就是将一个分布式事务理解成一个全局事务,下面挂了若干个分支事务,而每个分支事务又是一个满足ACID的本地事务,即每个分支事务的执行过程是原子性的,而全局事务需要确保所有分支事务执行过程的原子性;
与之相对的就是每个本地事务包含若干SQL语句,每个SQL语句执行过程是原子性的,本地事务需要确保其所包含的所有sql语句执行过程的原子性。
具体如下面所示:
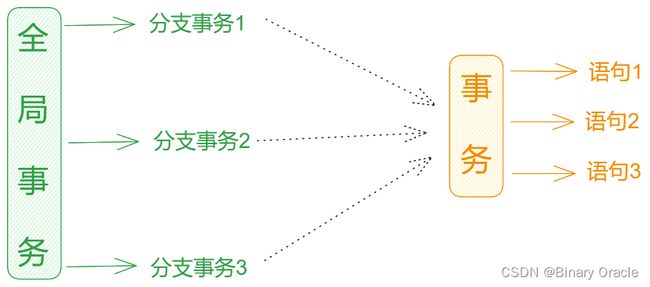
Seata 内部定义了3个模块来处理全局事务和分支事务的关系和处理过程 :
- Transaction Coordinator ( TC ) : 事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或者回滚。
- Transaction Manager ( TM ) : 控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决定。
- Resource Manager ( RM ):控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚。
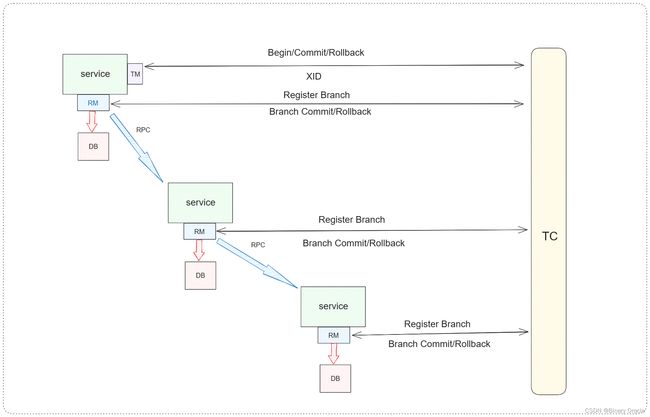
整个全局事务的执行分为以下几步:
- TM 向 TC 申请开启一个全局事务,TC 创建全局事务后返回全局唯一的 XID,XID 会在全局事务的上下文中传播;
- RM 向 TC 注册分支事务,该分支事务归属于拥有相同 XID 的全局事务;
- TM 向 TC 发起全局提交或回滚;
- TC 调度 XID 下的分支事务完成提交或者回滚。
数据源代理
传统的XA协议依赖的是数据库层面来保障事务的一致性,也就是说XA的各个分支事务是在数据库层面上驱动的,这会导致数据库与XA驱动耦合,同样也会导致各个分支事务资源锁定周期长,因此性能很低,一般不采用。
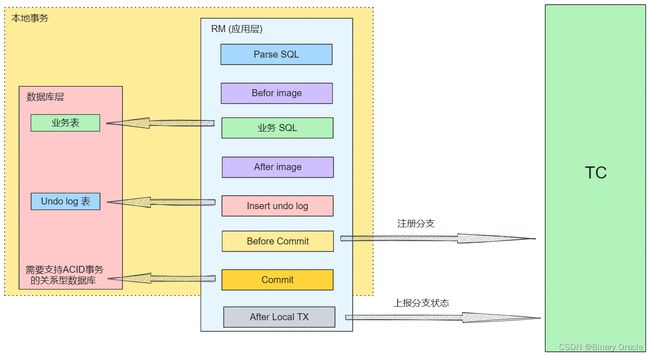
Seata 默认的AT模式则是基于业务层面实现的补偿机制,通过对RM进行改造,在应用层中添加一层对数据源的代理,如下图所示:
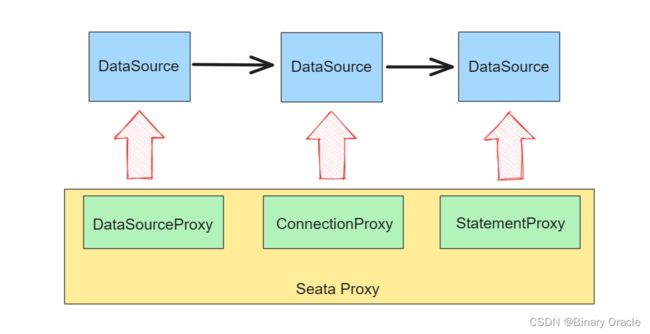
Seata 在数据源做了一层代理层,所以我们使用 Seata 时,我们使用的数据源实际上用的是 Seata 自带的数据源代理 DataSourceProxy,Seata 在这层代理中加入了很多逻辑,主要是解析 SQL,把业务数据在更新前后的数据镜像组织成回滚日志,并将 undo log 日志插入 undo_log 表中,保证每条更新数据的业务 sql 都有对应的回滚日志存在。
这样做的好处就是,本地事务执行完可以立即释放本地事务锁定的资源,然后向 TC 上报分支状态。当 TM 决议全局提交时,就不需要同步协调处理了,TC 会异步调度各个 RM 分支事务删除对应的 undo log 日志即可,这个步骤非常快速地可以完成;当 TM 决议全局回滚时,RM 收到 TC 发送的回滚请求,RM 通过 XID 找到对应的 undo log 回滚日志,然后执行回滚日志完成回滚操作。
传统的XA协议与Seata提供的AT模式实现区别如下图所示:
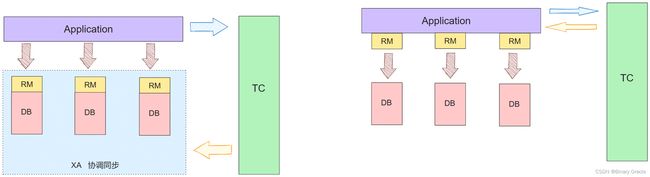
- XA 方案的 RM 是放在数据库层的,它依赖了数据库的 XA 驱动程序
- Seata 的 RM 实际上是已中间件的形式放在应用层,不用依赖数据库对协议的支持,完全剥离了分布式事务方案对数据库在协议支持上的要求
分支事务提交和回滚
分支事务提交和回滚分为三个阶段,如下所示:
- 第一阶段: 分支注册
分支事务利用 RM 模块 中对 JDBC 数据源的代理,加入了若干流程,对业务 SQL 进行解释,把业务数据在更新前后的数据镜像组织成回滚日志,并生成 undo log 日志,对全局事务锁的检查以及分支事务的注册等,利用本地事务 ACID 特性,将业务 SQL 和 undo log 写入同一个事物中一同提交到数据库中,保证业务 SQL 必定存在相应的回滚日志,最后对分支事务状态向 TC 进行上报。
- 第二阶段: TM决议全局提交
当 TM 决议提交时,就不需要同步协调处理了,TC 会异步调度各个 RM 分支事务删除对应的 undo log 日志即可,这个步骤非常快速地可以完成。这个机制对于性能提升非常关键,我们知道正常的业务运行过程中,事务执行的成功率是非常高的,因此可以直接在本地事务中提交,这步对于提升性能非常显著。

- 第三阶段: TM决议全局回滚
当 TM 决议回滚时,RM 收到 TC 发送的回滚请求,RM 通过 XID 找到对应的 undo log 回滚日志,然后利用本地事务 ACID 特性,执行回滚日志完成回滚操作并删除 undo log 日志,最后向 TC 进行回滚结果上报。

业务对以上所有的流程都无感知,业务完全不关心全局事务的具体提交和回滚,而且最重要的一点是 Seata 将两段式提交的同步协调分解到各个分支事务中了,分支事务与普通的本地事务无任何差异,这意味着我们使用 Seata 后,分布式事务就像使用本地事务一样,完全将数据库层的事务协调机制交给了中间件层 Seata 去做了,这样虽然事务协调搬到应用层了,但是依然可以做到对业务的零侵入,从而剥离了分布式事务方案对数据库在协议支持上的要求,且 Seata 在分支事务完成之后直接释放资源,极大减少了分支事务对资源的锁定时间,完美避免了 XA 协议需要同步协调导致资源锁定时间过长的问题。
隔离级别
Seata为我们提供一个全局事务,谈到事务就离不开事务隔离级别这个问题,Seata AT模式的事务隔离级别是建立在分支事务的本地隔离级别基础上的。在数据库本地隔离级别读已提交或以上的前提下,Seata 设计了由事务协调器维护的全局排它锁,来保证事务间的写隔离,同时,将全局事务默认定义在读未提交的隔离级别上。
在讲 Seata 事务隔离级之前,我们先来回顾一下数据库事务的隔离级别,目前数据库事务的隔离级别一共有 4 种,由低到高分别为:
- Read uncommitted:读未提交
- Read committed:读已提交
- Repeatable read:可重复读
- Serializable:序列化
数据库一般默认的隔离级别为读已提交,比如 Oracle,也有一些数据的默认隔离级别为可重复读,比如 Mysql,一般而言,数据库的读已提交能够满足业务绝大部分场景了。
我们知道 Seata 的事务是一个全局事务,它包含了若干个分支本地事务,在全局事务执行过程中(全局事务还没执行完),某个本地事务提交了,如果 Seata 没有采取任务措施,则会导致已提交的本地事务被读取,造成脏读;如果数据在全局事务提交前已提交的本地事务被修改,则会造成脏写。
由此可以看出,传统意义的脏读是读到了未提交的数据,Seata 脏读是读到了全局事务下未提交的数据,全局事务可能包含多个本地事务,某个本地事务提交了不代表全局事务提交了。
绝大部分应用在读已提交的隔离级别下工作是没有问题的,而实际上,这当中又有绝大多数的应用场景,实际上工作在读未提交的隔离级别下同样没有问题。
在极端场景下,应用如果需要达到全局的读已提交,Seata 也提供了全局锁机制实现全局事务读已提交。但是默认情况下,Seata 的全局事务是工作在读未提交隔离级别的,保证绝大多数场景的高效性。
Seata AT模式下写操作都必须加锁,但是读操作默认不加锁,因此可以读到还未提交的全局事务做出的修改,可以自行选择加锁,使其工作在读已提交隔离级别下。
解决脏写
假设按照我们目前已知流程运行,那么看看会遇到什么问题呢?
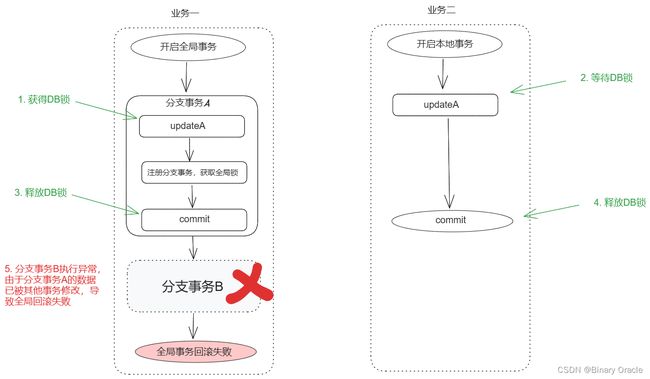
业务一开启全局事务,其中包含分支事务A(修改 A)和分支事务 B(修改 B),业务二修改 A,其中业务一执行分支事务 A 先获取本地锁,业务二则等待业务一执行完分支事务 A 之后,获得本地锁修改 A 并入库,业务一在执行分支事务时发生异常了,由于分支事务 A 的数据被业务二修改,导致业务一的全局事务无法回滚。
业务一回滚分支事务A的时候,会通过after-image判断当前自己自己更新过的数据,是否又被其他人修改了,如果是说明发生了脏写问题,这里会抛出异常。
Seata采用加互斥锁的方式来解决脏写问题:
1、业务二执行时加 @GlobalTransactional注解:

业务二在执行全局事务过程中,分支事务 A 提交前,注册分支事务获取全局锁时,发现业务一全局锁还没执行完,因此业务二提交不了,抛异常回滚,所以不会发生脏写。
这里其实是发生了死锁现象,但是由于两方都存在锁超时机制,最终会因为全局锁超时较早,抛出超时异常,提前打破死锁局面。
- 业务二执行时加 @GlobalLock注解:
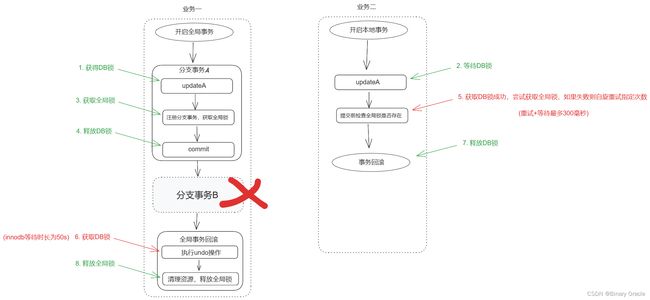
与 @GlobalTransactional注解效果类似,只不过不需要开启全局事务,只在本地事务提交前,检查全局锁是否存在。
- 业务二执行时加 @GlobalLock 注解 + select for update语句:

如果加了select for update语句,则会在 update 前检查全局锁是否存在,只有当全局锁释放之后,业务二才能开始执行 updateA 操作。
如果单单是 transactional,那么就有可能会出现脏写,根本原因是没有 Globallock 注解时,不会检查全局锁,这可能会导致另外一个全局事务回滚时,发现某个分支事务被脏写了。所以加 select for update 也有个好处,就是可以重试。
读未提交
Seata AT模式下,默认为读未提交隔离级别,即不会对select请求做任何拦截处理,如下图所示:

由于业务一最终进行了全局事务回滚,所以业务二读取到的值就变成了脏值,此时就产生了脏读问题。
读已提交
Seata AT 模式默认为读未提交隔离级别,该隔离级别下可能会产生脏读问题,这里是指在全局事务未提交前,被其它业务读到已提交的分支事务的数据,本质上是Seata默认的全局事务是读未提交。
可以把这里分支事务提交理解为执行完事务中一条sql更新语句。
那么怎么避免脏读现象呢?
- 业务二查询 A 时加 @GlobalLock 注解 + select for update语句:
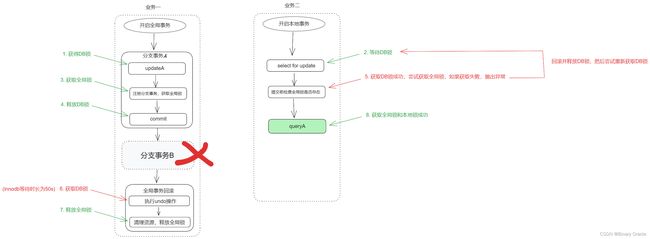
加select for update语句会在执行 SQL 前检查全局锁是否存在,只有当全局锁完成之后,才能继续执行 SQL,这样就防止了脏读。
小结
本文所讲的是Seata的AT模式,也是Seata默认情况下的启用的模式,其类似于XA的两阶段提交方案,同时对业务无侵入,但是这种模式依然需要依赖数据库本地事务的ACID特性。
对于不支持ACID特性的数据库而言,可以考虑Seata提供的TCC方案,其是一种对业务有入侵的方案,通过手工编码指定提交和回滚逻辑,在业务层面实现补偿逻辑,关于TCC部分源码解析将在本系列后半部分给出。