ClickHouse从入门到精通(二)
文章目录
- ClickHouse从入门到精通(二)
-
- ClickHouse 进阶篇
-
- SQL操作
-
- 1. Insert
- 2. Update 和 Delete
- 3. 查询操作
- 4. Alter 操作
- 5. 导出数据
- 副本
-
- 1. 副本写入流程
- 2. 配置步骤
- 3. 案例演示
- 集群
-
- 1. 集群配置
- 2. 配置一个默认集群
- 分片集群
-
- 1. 分片写入流程(3分片2副本共6个节点)
- 2. 集群读取流程(3分片2副本共6个节点)
- 3. 3分片2副本集群配置
- 4. 配置三节点集群及副本
ClickHouse从入门到精通(二)
ClickHouse 进阶篇
SQL操作
- 基本上相对于传统关系型数据库(以 MySQL 为例) 的 SQL 语句,ClickHouse 基本都支持,这里需要重点关注下 ClickHouse 与标准 SQL 不一致的地方。
1. Insert
- 基本与标准 SQL(MySQL)基本一致。
-- 标准
INSERT INTO [database_name].table_name[(c1, c2, ...)] values(v11, v12, ...), (v21, v22, ...), ...;
-- 从表到表插入
INSERT INTO [database_name].table_name[(c1, c2, ...)] SELECT ...
2. Update 和 Delete
- ClickHouse 提供了 Delete 和 Update 的能力,这类操作被称为 Mutation 查询,可以看作是 Alter 的一种。
- 虽然可以实现修改和删除,但是和一般的 OLTP 数据库不一样,Mutation 语句是一种很“重”的操作,而且不支持事务。
- “重”的原因主要是每次修改或者删除都会导致放弃目标数据的原有分区,重建新分区。所以尽量做批量的变更,不要进行频繁小数据的操作。
-- 删除操作
ALTER TABLE t_order_smt DELETE WHERE sku_id = 'sku_001';
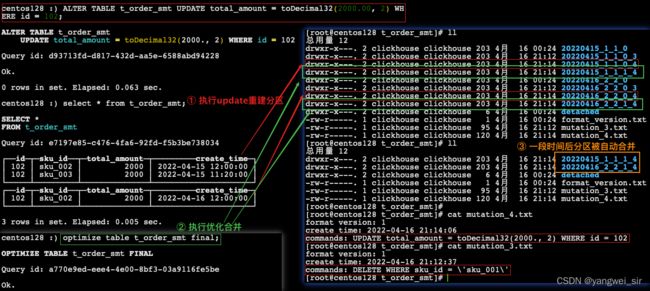
-- 更新操作
ALTER TABLE t_order_smt UPDATE total_amount = toDecimal32(2000.00, 2) WHERE id = 102;
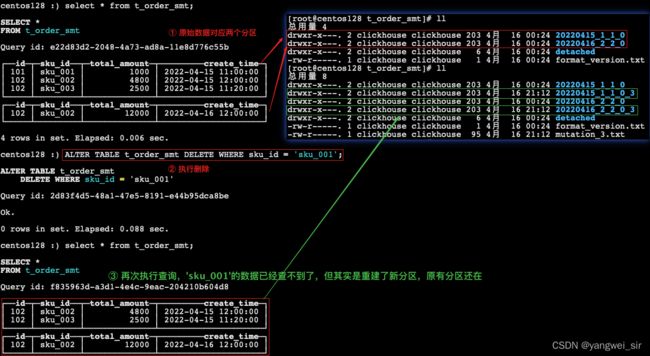
- 由于操作比较“重”,所以 Mutation 语句分两步执行,同步执行的部分其实只是进行新增数据新增分区和并把旧分区打上逻辑上的失效标记。直到触发分区合并的时候,才会删除旧数据释放磁盘空间,一般不会开放这样的功能给用户,由管理员完成。
3. 查询操作
- 支持子查询;
- 支持 CTE(Common Table Expression 公用表达式 with 子句);
- 支持各种 JOIN,但是 JOIN 操作无法使用缓存,所以即使是两次相同的 JOIN 语句,ClickHouse 也会视为两条新的 SQL;
- 窗口函数:目前最新版本已经支持;
- 暂不支持自定义函数;
- GROUP BY 操作增加了 with rollup、with cube、with total 用于按不同维度统计。
-- 先清空表 t_order_mt
create table t_order_mt (
id UInt32,
sku_id String,
total_amount Decimal(16, 2),
create_time Datetime
) engine = MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
-- 插入数据
insert into t_order_mt values
(101, 'sku_001', 1000.00, '2022-04-15 09:00:00'),
(102, 'sku_002', 1500.00, '2022-04-15 10:30:00'),
(102, 'sku_003', 2500.00, '2022-04-15 12:30:00'),
(103, 'sku_004', 1500.00, '2022-04-15 13:00:00'),
(104, 'sku_001', 10000.00, '2022-04-15 13:00:00'),
(105, 'sku_002', 800.00, '2022-04-15 12:00:00'),
(106, 'sku_002', 1500.00, '2022-04-15 10:30:00'),
(107, 'sku_003', 2500.00, '2022-04-15 12:30:00'),
(108, 'sku_004', 1500.00, '2022-04-15 13:00:00'),
(109, 'sku_002', 10000.00, '2022-04-15 13:00:00'),
(110, 'sku_003', 800.00, '2022-04-15 12:00:00');
- with rollup(上卷):从右至左去掉维度进行小计
select id, sku_id, sum(total_amount) from t_order_mt group by id, sku_id with rollup;

- with cube:从右至左去掉维度进行小计,再从左至右去掉维度进行小计
select id, sku_id, sum(total_amount) from t_order_mt group by id, sku_id with cube;
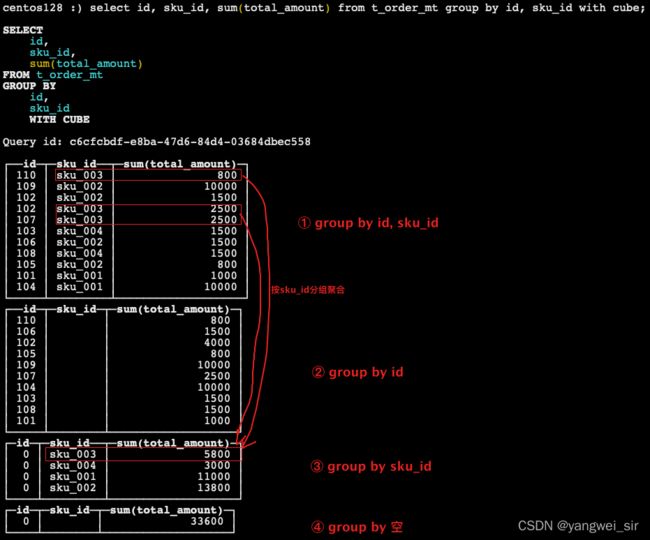
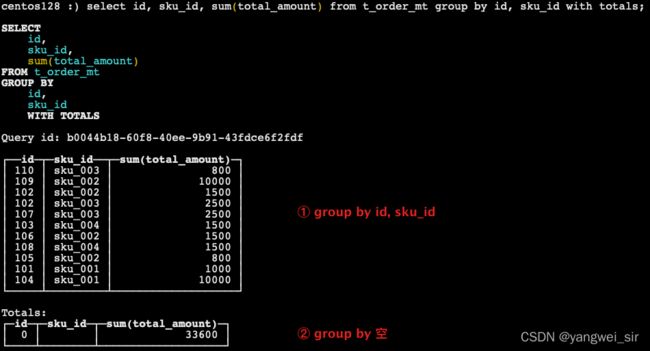
- with totals:只计算合计
select id, sku_id, sum(total_amount) from t_order_mt group by id, sku_id with totals;
4. Alter 操作
-- 新增字段
ALTER TABLE [database_name].table_name ADD COLUMN ${new_col_name} ${col_type} after ${old_col_name};
-- 修改字段类型
ALTER TABLE [database_name].table_name MODIFY COLUMN ${new_col_name} ${col_type};
-- 删除字段
ALTER TABLE [database_name].table_name DROP ${col_name};
5. 导出数据
clickhouse-client --query "select * from test.t_order_mt where create_time='2022-04-15 12:00:00'" --format CSVWithNames > /bigdata/data/rs.csv --password

- 更多支持格式:https://clickhouse.com/docs/en/interfaces/formats/
副本
- 副本的目的主要是保障数据的高可用性,即使一台 ClickHouse 节点宕机,那么也可以从其他服务器获得相同的数据。
- 参考资料:https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/replication/
1. 副本写入流程
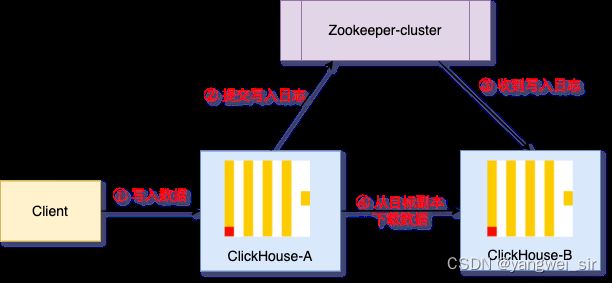
2. 配置步骤
- 启动 ZooKeeper 集群
- 在 node01 的 /etc/clickhouse-server/config.d 目录下创建一个名为 metrika.xml 的配置文件,内容如下:
<yandex>
<zookeeper-servers>
<node index="1">
<host>node01host>
<port>2181port>
node>
<node index="2">
<host>node02host>
<port>2181port>
node>
<node index="3">
<host>node03host>
<port>2181port>
node>
zookeeper-servers>
yandex>
- 也可以不创建外部文件,直接在 config.xml 中指定
,修改配置文件的用户组
chown clickhouse:clickhouse metrika.xml
- 修改 /etc/clickhouse-server/config.xml 配置文件:
<interserver_http_port>9009interserver_http_port>
<interserver_http_host>192.168.x.xinterserver_http_host>
<zookeeper incl="zookeeper-servers" optional="true" />
<include_from>/etc/clickhouse-server/config.d/metrika.xmlinclude_from>

- 将配置文件同步到 node02、node03 节点上,并重启服务
sudo clickhouse restart
3. 案例演示
- 建表语句:
CREATE TABLE table_name ( ... ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/{table_name}', '{replica}') ...
- Replicated*MergeTree 参数:
- 第一个参数:是分片的 ZK_PATH,一般按照==/clickhouse/tables/{layer}-{shard}/{table_name}== 的格式写。
/clickhouse/tables/是公共前缀,推荐使用这个;{layer}-{shard}是分片标识部分,大多数情况来说,只需保留 {shard} 占位符即可;table_name是该表在 ZooKeeper 中的名称,使其与 ClickHouse 中的表名相同比较好。 这里它被明确定义,跟 ClickHouse 表名不一样,并不会被 RENAME 语句修改。可以在前面添加一个数据库名称table_name也是,例如:db_name.table_name
- 第二个参数:是副本名称,
{replica}占位符- 用于标识同一个表分片的不同副本,可以使用服务器名称;
- 相同的分片副本名称不能相同。
- 这些参数可以包含宏替换的占位符,即大括号的部分,会被替换为配置文件里 macros 那部分配置的值。
<macros> <shard>01shard> <replica>node01replica> macros>- config.xml 配置文件中添加:
<macros incl="macros" optional="true" /> - 第一个参数:是分片的 ZK_PATH,一般按照==/clickhouse/tables/{layer}-{shard}/{table_name}== 的格式写。
- 副本只能同步数据,不能同步表结构,所以我们需要在每台机器上自己手动创建表。
-- 分别在 node01、node02 和 node03 两台机器上执行
create table t_order_rep(
id UInt32,
sku_id String,
total_amount Decimal(16, 2),
create_time Datetime
) engine = ReplicatedMergeTree('/clickhouse/tables/{shard}/t_order_rep', '{replica}')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
-- 在 node01 上插入数据
insert into t_order_rep values
(101, 'sku_001', 1000.00, '2022-04-15 09:00:00'),
(102, 'sku_002', 1500.00, '2022-04-15 10:30:00'),
(103, 'sku_004', 1500.00, '2022-04-15 13:00:00'),
(104, 'sku_001', 10000.00, '2022-04-15 13:00:00'),
(105, 'sku_002', 800.00, '2022-04-15 12:00:00');
- node02 和 node03 两节点上也能查到数据,副本数据同步成功!!!
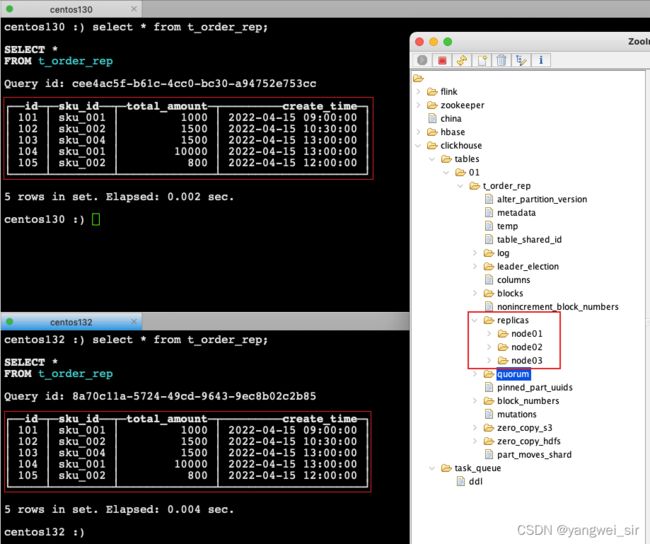
- 同样的方式,你可以将clickhouse中的数据复制到更多的集群中。在这个过程中,你基本不需要担心zookeeper的性能问题。一个Zookeeper集群能给整个clickhouse集群支撑协调每秒几百个INSERT,数据的吞吐量可以跟不用复制的数据一样高。官方给出的Yandex.Metrica集群,大约有300台服务器,依然一个zookeeper搞定了。
集群
1. 集群配置
- 集群是通过服务器配置文件来配置的,在 config.xml 中找到
标签,进行集群配置,ClickHouse 默认已经配置了一些集群

- 举个例子:
<remote_servers>
<logs>
<shard>
<weight>1weight>
<internal_replication>falseinternal_replication>
<replica>
<priority>1priority>
<host>example01-01-1host>
<port>9000port>
replica>
<replica>
<host>example01-01-2host>
<port>9000port>
replica>
shard>
<shard>
<weight>2weight>
<internal_replication>falseinternal_replication>
<replica>
<host>example01-02-1host>
<port>9000port>
replica>
<replica>
<host>example01-02-2host>
<secure>1secure>
<port>9440port>
replica>
shard>
logs>
remote_servers>
- 集群名称不能包含点号,每个服务器需要指定
host、port,和可选的user、password、secure、compression的参数:host– 远程服务器地址。可以域名、IPv4或IPv6。如果指定域名,则服务在启动时发起一个 DNS 请求,并且请求结果会在服务器运行期间一直被记录。如果 DNS 请求失败,则服务不会启动。如果你修改了 DNS 记录,则需要重启服务。port– 消息传递的 TCP 端口(「tcp_port」配置通常设为 9000)。不要跟 http_port 混淆。user– 用于连接远程服务器的用户名。默认值:default。该用户必须有权限访问该远程服务器。访问权限配置在 users.xml 文件中。更多信息,请查看«访问权限»部分。password– 用于连接远程服务器的密码。默认值:空字符串。secure– 是否使用ssl进行连接,设为true时,通常也应该设置port= 9440。服务器也要监听9440 compression- 是否使用数据压缩。默认值:true。
2. 配置一个默认集群
- 删掉 config.xml 中配置的集群,在外部配置文件 metrika.xml 中添加如下配置:
<remote_servers>
<default>
<shard>
<internal_replication>trueinternal_replication>
<replica>
<host>node01host>
<port>9000port>
replica>
<replica>
<host>node02host>
<port>9000port>
replica>
<replica>
<host>node03host>
<port>9000port>
replica>
shard>
default>
remote_servers>
- node01、node02、node03都需要配置,然后重启 ClickHouse。
- 在 node01 上执行建表语句:使用 ReplicatedMergeTree 引擎,可以不用配置ZK路径(默认/clickhouse/tables/{shard}/{UUID})和副本名称(默认用使用宏替换),但是要加上 on cluster {cluster_name}
create table t_order_cluster on cluster default(
id UInt32,
sku_id String,
total_amount Decimal(16, 2),
create_time Datetime
) engine = ReplicatedMergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
- 此时,在 node02、node03 也同样创建了和 node01 相同的表

分片集群
- 副本虽然能够提高数据的可用性,降低丢失风险,但是每台服务器实际上必须容纳全量数据,对数据的横向扩容没有解决。
- 要解决数据水平切分的问题,需要引入分片的概念。通过分片把一份完整的数据进行切分,不同的分片分布到不同的节点上,再通过 Distributed 表引擎把数据拼接起来一同使用。
- Distributed 表引擎本身不存储数据,有点类似于 MyCat 之于 MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据。
- 注意:ClickHouse 的集群是表级别的,实际企业中,大部分做了高可用,但是没有用分片,避免降低查询性能以及操作集群的复杂性。
1. 分片写入流程(3分片2副本共6个节点)
向集群写数据的方法有两种:
- 一、自已指定要将哪些数据写入哪些服务器,并直接在每个分片上执行写入。换句话说,在分布式表上«查询»,在数据表上 INSERT。 这是最灵活的解决方案 – 你可以使用任何分片方案,对于复杂业务特性的需求,这可能是非常重要的。 这也是最佳解决方案,因为数据可以完全独立地写入不同的分片。
- 二、在分布式表上执行 INSERT。在这种情况下,分布式表会跨服务器分发插入数据。 为了写入分布式表,必须要配置分片键(最后一个参数)。当然,如果只有一个分片,则写操作在没有分片键的情况下也能工作,因为这种情况下分片键没有意义。

- 每个分片都可以在配置文件中定义权重。默认情况下,权重等于1。数据依据分片权重按比例分发到分片上。例如,如果有两个分片,第一个分片的权重是9,而第二个分片的权重是10,则发送 9 / 19 的行到第一个分片, 10 / 19 的行到第二个分片。
- 分片可在配置文件中定义 internal_replication 参数:
- true:写操作只选一个正常的副本写入数据。如果分布式表的子表是复制表(*ReplicaMergeTree),请使用此方案。换句话说,这其实是**把数据的复制工作交给实际需要写入数据的表本身而不是分布式表。**生产环境上推荐使用。
- false:写操作会将数据写入所有副本。实质上,这意味着要分布式表本身来复制数据。这种方式不如使用复制表的好,因为不会检查副本的一致性,并且随着时间的推移,副本数据可能会有些不一样。
2. 集群读取流程(3分片2副本共6个节点)

- 查询数据时,如果一个分片shard有多个副本repIica,那么Distributed表引擎就需要面对副本选择的问题,选择查询究竟在哪个副本上执行。ck的负载均衡优先选择 errors_count 最小的那个,如果多个 errors_count 相同,则有以下四种策略:
- random:随机,默认的负载均衡算法;
- nearest_hostname:选择集群配置中host名称和当前host名称最相似的那个,相似比较的规则是与当前host的名称,按字节进行逐位对比,找到不同字节最少的那个。
- in_order:按照集群配置顺序选择。
- first_or_random:按照集群配置顺序选择第一个,如果第一个不可用,则随意选择一个其他的。
3. 3分片2副本集群配置
<remote_servers>
<shard_cluster>
<shard>
<internal_replication>trueinternal_replication>
<replica>
<host>node01host>
<port>9000port>
replica>
<replica>
<host>node02host>
<port>9000port>
replica>
shard>
<shard>
<internal_replication>trueinternal_replication>
<replica>
<host>node03host>
<port>9000port>
replica>
<replica>
<host>node04host>
<port>9000port>
replica>
shard>
<shard>
<internal_replication>trueinternal_replication>
<replica>
<host>node05host>
<port>9000port>
replica>
<replica>
<host>node06host>
<port>9000port>
replica>
shard>
shard_cluster>
remote_servers>
4. 配置三节点集群及副本
- 集群及副本规划:2分片,只有第一个分片有副本
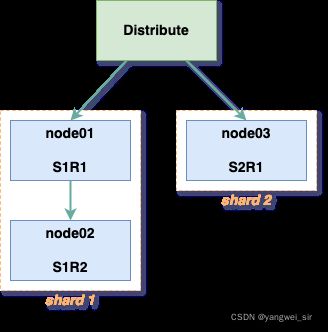
| node01 | node02 | node03 |
|---|---|---|
- 在 node01、node02、node03 三台机器上创建 metrika-shard.xml 配置文件,内容如下:
<yandex>
<remote_servers>
<shard_cluster>
<shard>
<internal_replication>trueinternal_replication>
<replica>
<host>node01host>
<port>9000port>
replica>
<replica>
<host>node02host>
<port>9000port>
replica>
shard>
<shard>
<internal_replication>trueinternal_replication>
<replica>
<host>node03host>
<port>9000port>
replica>
shard>
shard_cluster>
remote_servers>
<zookeeper-servers>
<node index="1">
<host>node01host>
<port>2181port>
node>
<node index="2">
<host>node02host>
<port>2181port>
node>
<node index="3">
<host>node03host>
<port>2181port>
node>
zookeeper-servers>
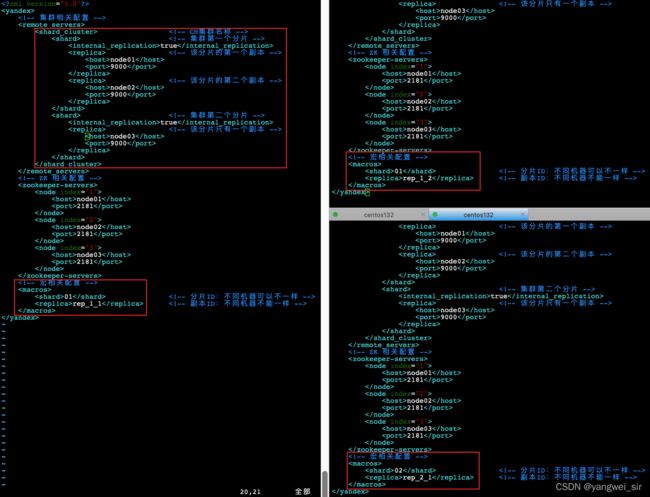
<macros>
<shard>01shard>
<replica>rep_1_1replica>
macros>
yandex>
- 每台机器上的宏相关配置不一样
- 修改配置文件的用户组:
chown clickhouse:clickhouse metrika-shard.xml
- 修改 /etc/clickhouse-server/config.xml
<include_from>/etc/clickhouse-server/config.d/metrika-shard.xmlinclude_from>
- 重启 node01、node02、node03 上的 clickhouse
- 在 node01 上执行建表语句:会自动同步到 node02、node03
create table t_order_sc on cluster shard_cluster (
id UInt32,
sku_id String,
total_amount Decimal(16, 2),
create_time Datetime
) engine = ReplicatedMergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);

- 在 node01 上创建 Distribute 分布式表
create table t_order_sc_all on cluster shard_cluster (
id UInt32,
sku_id String,
total_amount Decimal(16, 2),
create_time Datetime
) engine = Distributed(shard_cluster, test, t_order_sc, hiveHash(sku_id));
- Distributed(shard_cluster, test, t_order_sc, hiveHash(sku_id)):
- Distributed(集群名称, 库名, 本地表名, 分片键);
- 分片键必须是整型数字,所以用 hiveHash 函数转换,也可以 rand()。
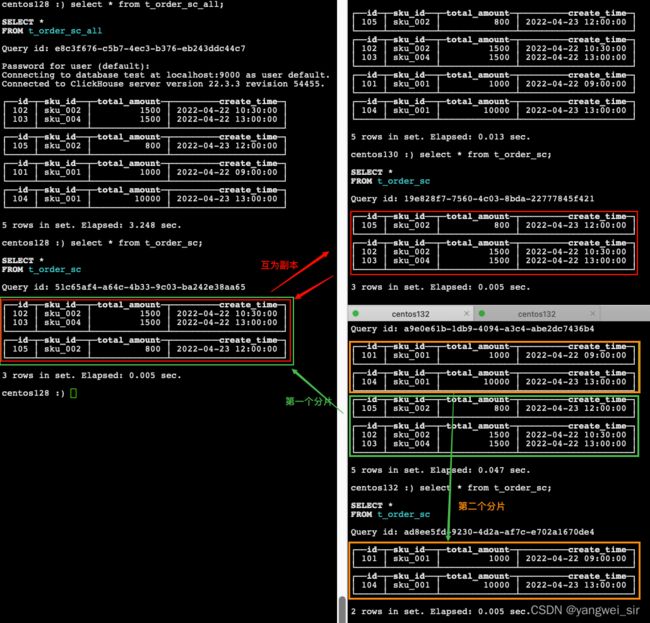
- 在 node01 上插入测试数据:
insert into t_order_sc_all values
(101, 'sku_001', 1000.00, '2022-04-22 09:00:00'),
(102, 'sku_002', 1500.00, '2022-04-22 10:30:00'),
(103, 'sku_004', 1500.00, '2022-04-22 13:00:00'),
(104, 'sku_001', 10000.00, '2022-04-23 13:00:00'),
(105, 'sku_002', 800.00, '2022-04-23 12:00:00');
- 分别通过分布式表和本地表查询,对比输出结果
select * from t_order_sc_all;
select * from t_order_sc;
遇到问题:eceived exception from server (version 22.3.3):
Code: 516. DB::Exception: Received from localhost:9000. DB::Exception: Received from node03:9000. DB::Exception: default: Authentication failed: password is incorrect or there is no user with such name. (AUTHENTICATION_FAILED)
需要修改配置:

- 对比数据分布: