机器学习预测CPU占有率
现在有一组数据,64台主机在过去三周的cpu使用率时序数据,时序间隔300秒。一共366735条数据,部分数据如下图:


现在需要预测下一周的CPU占有率,我们选择训练集的最后3000条数据做预测,使用四个模型去运行,发现准确率可以达到100%。
模型一:线性回归模型
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 从CSV文件读取训练数据,从第二行开始
train_data = pd.read_csv('cpu_train.csv', skiprows=1, header=None, names=['time', 'vmid', 'mean'])
# 使用独热编码来处理 'vmid' 列
vmid_encoded = pd.get_dummies(train_data['vmid'], prefix='vmid')
X_train = pd.concat([train_data['time'], vmid_encoded], axis=1)
# 目标变量是mean
y_train = train_data['mean']
# 使用最后3000条数据作为测试集
X_test = X_train.iloc[-3000:]
y_test = y_train.iloc[-3000:]
# 初始化线性回归模型
model = LinearRegression()
# 在训练集上训练模型
model.fit(X_train, y_train)
# 进行mean值预测
predicted_means = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, predicted_means)
accuracy = model.score(X_test, y_test)
# 输出预测结果和真实值
for i, (index, row) in enumerate(X_test.iterrows()):
time = row['time']
true_mean = y_test.iloc[i]
predicted_mean = predicted_means[i]
print(f"Time: {time}, True Mean: {true_mean}, Predicted Mean: {predicted_mean}")
print(f"L Mean Squared Error: {mse}")
print(f"L Accuracy: {accuracy}")
# # 创建一个DataFrame来存储预测结果
# result_df = pd.DataFrame({'Time': X_test['time'], 'True Mean': y_test, 'Predicted Mean': predicted_means})
#
# # 将结果保存到CSV文件
# result_df.to_csv('LinearRegression_Predictions.csv', index=False)
#
# print("Predicted results saved to LinearRegression_Predictions.csv")
运行结果:

模型二:XGBoost回归模型
import pandas as pd
import xgboost as xgb
from sklearn.metrics import mean_squared_error
# 从CSV文件读取训练数据,从第二行开始
train_data = pd.read_csv('cpu_train.csv', skiprows=1, header=None, names=['time', 'vmid', 'mean'])
# 使用独热编码来处理 'vmid' 列
vmid_encoded = pd.get_dummies(train_data['vmid'], prefix='vmid')
X_train = pd.concat([train_data['time'], vmid_encoded], axis=1)
# 目标变量是mean
y_train = train_data['mean']
# 使用最后3000条数据作为测试集
X_test = X_train.iloc[-3000:]
y_test = y_train.iloc[-3000:]
# 初始化XGBoost回归模型
model = xgb.XGBRegressor()
# 在训练集上训练模型
model.fit(X_train, y_train)
# 进行mean值预测
predicted_means = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, predicted_means)
# XGBoost模型没有score方法,这里可以直接计算R^2作为"Accuracy"
r2 = model.score(X_test, y_test)
# 输出预测结果和真实值
for i, (index, row) in enumerate(X_test.iterrows()):
time = row['time']
true_mean = y_test.iloc[i]
predicted_mean = predicted_means[i]
print(f"Time: {time}, True Mean: {true_mean}, Predicted Mean: {predicted_mean}")
print(f"X Mean Squared Error: {mse}")
print(f"X R^2 (Accuracy): {r2}")
# # 创建一个DataFrame来存储预测结果
# result_df = pd.DataFrame({'Time': X_test['time'], 'True Mean': y_test, 'Predicted Mean': predicted_means})
#
# # 将结果保存到CSV文件
# result_df.to_csv('XGBoost_Predictions.csv', index=False)
#
# print("Predicted results saved to XGBoost_Predictions.csv")
运行结果:
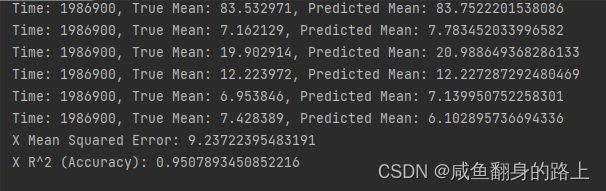
模型三: 随机森林回归模型
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# 从CSV文件读取训练数据,从第二行开始
train_data = pd.read_csv('cpu_train.csv', skiprows=1, header=None, names=['time', 'vmid', 'mean'])
# 使用独热编码来处理 'vmid' 列
vmid_encoded = pd.get_dummies(train_data['vmid'], prefix='vmid')
X_train = pd.concat([train_data['time'], vmid_encoded], axis=1)
# 目标变量是mean
y_train = train_data['mean']
# 使用最后3000条数据作为测试集
X_test = X_train.iloc[-3000:]
y_test = y_train.iloc[-3000:]
# 初始化随机森林回归模型
model = RandomForestRegressor()
# 在训练集上训练模型
model.fit(X_train, y_train)
# 进行mean值预测
predicted_means = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, predicted_means)
# 随机森林模型没有score方法,这里可以直接计算R^2作为"Accuracy"
r2 = model.score(X_test, y_test)
# 输出预测结果和真实值
for i, (index, row) in enumerate(X_test.iterrows()):
time = row['time']
true_mean = y_test.iloc[i]
predicted_mean = predicted_means[i]
print(f"Time: {time}, True Mean: {true_mean}, Predicted Mean: {predicted_mean}")
print(f"R Mean Squared Error: {mse}")
print(f"R R^2 (Accuracy): {r2}")
# # 创建一个DataFrame来存储预测结果
# result_df = pd.DataFrame({'Time': X_test['time'], 'True Mean': y_test, 'Predicted Mean': predicted_means})
#
# # 将结果保存到CSV文件
# result_df.to_csv('RandomForest_Predictions.csv', index=False)
#
# print("Predicted results saved to RandomForest_Predictions.csv")
运行结果:

模型四:决策树回归模型
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error
# 从CSV文件读取训练数据,从第二行开始
train_data = pd.read_csv('cpu_train.csv', skiprows=1, header=None, names=['time', 'vmid', 'mean'])
# 使用独热编码来处理 'vmid' 列
vmid_encoded = pd.get_dummies(train_data['vmid'], prefix='vmid')
X_train = pd.concat([train_data['time'], vmid_encoded], axis=1)
# 目标变量是mean
y_train = train_data['mean']
# 使用最后3000条数据作为测试集
X_test = X_train.iloc[-3000:]
y_test = y_train.iloc[-3000:]
# 初始化决策树回归模型
model = DecisionTreeRegressor()
# 在训练集上训练模型
model.fit(X_train, y_train)
# 进行mean值预测
predicted_means = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, predicted_means)
# 决策树模型没有score方法,这里可以直接计算R^2作为"Accuracy"
r2 = model.score(X_test, y_test)
# 输出预测结果和真实值
for i, (index, row) in enumerate(X_test.iterrows()):
time = row['time']
true_mean = y_test.iloc[i]
predicted_mean = predicted_means[i]
print(f"Time: {time}, True Mean: {true_mean}, Predicted Mean: {predicted_mean}")
print(f"D Mean Squared Error: {mse}")
print(f"D R^2 (Accuracy): {r2}")
# # 创建一个DataFrame来存储预测结果
# result_df = pd.DataFrame({'Time': X_test['time'], 'True Mean': y_test, 'Predicted Mean': predicted_means})
#
# # 将结果保存到CSV文件
# result_df.to_csv('DecisionTree_Predictions.csv', index=False)
#
# print("Predicted results saved to DecisionTree_Predictions.csv")
运行结果:
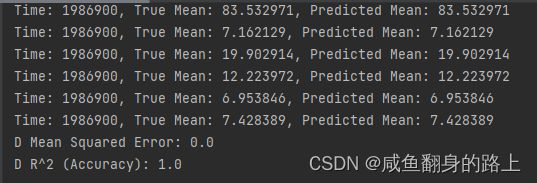
下面我将用自己的测试集去预测的代码放在下面:
模型一:线性回归
import pandas as pd
from sklearn.linear_model import LinearRegression
# 从CSV文件读取训练数据,从第二行开始
train_data = pd.read_csv('your_train_data.csv', skiprows=1, header=None, names=['time', 'vmid', 'mean'])
# 使用独热编码来处理 'vmid' 列
vmid_encoded = pd.get_dummies(train_data['vmid'], prefix='vmid')
X_train = pd.concat([train_data['time'], vmid_encoded], axis=1)
# 目标变量是mean
y_train = train_data['mean']
# 初始化线性回归模型
model = LinearRegression()
# 在训练集上训练模型
model.fit(X_train, y_train)
# 从CSV文件读取测试数据,从第二行开始
test_data = pd.read_csv('your_teat_data.csv', skiprows=1, header=None, names=['time', 'vmid'])
# 使用独热编码来处理 'vmid' 列
vmid_encoded_test = pd.get_dummies(test_data['vmid'], prefix='vmid')
X_test = pd.concat([test_data['time'], vmid_encoded_test], axis=1)
# 进行mean值预测
predicted_means = model.predict(X_test)
# 输出预测结果
for i, row in test_data.iterrows():
vmid = row['vmid']
time = row['time']
mean = predicted_means[i]
print(f"Time: {time}, vmid: {vmid}, Predicted mean: {mean}")
# 创建一个DataFrame来存储预测结果
result_df = pd.DataFrame({'Time': test_data['time'], 'vmid': test_data['vmid'], 'Predicted Mean': predicted_means})
# 将结果保存到CSV文件
result_df.to_csv('LinearRegression.csv', index=False)
print("Predicted results saved to LinearRegression.csv")模型二:XGBoost回归模型
import pandas as pd
import xgboost as xgb
from tqdm import tqdm
# 从CSV文件读取训练数据,从第二行开始
train_data = pd.read_csv('your_train_data.csv', skiprows=1, header=None, names=['time', 'vmid', 'mean'])
# 使用独热编码来处理 'vmid' 列
vmid_encoded = pd.get_dummies(train_data['vmid'], prefix='vmid')
X_train = pd.concat([train_data['time'], vmid_encoded], axis=1)
# 目标变量是mean
y_train = train_data['mean']
# 初始化XGBoost回归模型,并设置参数为使用GPU加速
model = xgb.XGBRegressor(n_estimators=100, random_state=0, tree_method='gpu_hist')
# 在训练集上训练模型,添加进度条
with tqdm(total=len(X_train)) as pbar:
model.fit(X_train, y_train)
pbar.update(len(X_train))
# 从CSV文件读取测试数据,从第二行开始
test_data = pd.read_csv('your_test_data.csv', skiprows=1, header=None, names=['time', 'vmid'])
# 使用独热编码来处理 'vmid' 列
vmid_encoded_test = pd.get_dummies(test_data['vmid'], prefix='vmid')
X_test = pd.concat([test_data['time'], vmid_encoded_test], axis=1)
# 进行mean值预测
predicted_means = model.predict(X_test)
# 输出预测结果
for i, row in test_data.iterrows():
vmid = row['vmid']
time = row['time']
mean = predicted_means[i]
print(f"Time: {time}, vmid: {vmid}, Predicted mean: {mean}")
# 创建一个DataFrame来存储预测结果
result_df = pd.DataFrame({'Time': test_data['time'], 'vmid': test_data['vmid'], 'Predicted Mean': predicted_means})
# 将结果保存到CSV文件
result_df.to_csv('xgboost.csv', index=False)
print("Predicted results saved to xgboost.csv")
模型三:随机森林模型
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from tqdm import tqdm
from sklearn.preprocessing import OneHotEncoder
# 从CSV文件读取训练数据,从第二行开始
train_data = pd.read_csv('your_train_data.csv', skiprows=1, header=None, names=['time', 'vmid', 'mean'])
# 使用独热编码来处理 'vmid' 列
encoder = OneHotEncoder(sparse_output=False)
vmid_encoded = encoder.fit_transform(train_data[['vmid']])
X_train = pd.concat([train_data['time'], pd.DataFrame(vmid_encoded, columns=encoder.get_feature_names_out(['vmid']))], axis=1)
# 目标变量是mean
y_train = train_data['mean']
# 初始化随机森林回归模型
model = RandomForestRegressor()
# 在训练集上训练模型,添加进度条
with tqdm(total=len(X_train)) as pbar:
model.fit(X_train, y_train)
pbar.update(len(X_train))
# 从CSV文件读取测试数据,从第二行开始
test_data = pd.read_csv('your_test_data.csv', skiprows=1, header=None, names=['time', 'vmid'])
# 使用独热编码来处理 'vmid' 列
vmid_encoded_test = encoder.transform(test_data[['vmid']])
X_test = pd.concat([test_data['time'], pd.DataFrame(vmid_encoded_test, columns=encoder.get_feature_names_out(['vmid']))], axis=1)
# 进行mean值预测
predicted_means = model.predict(X_test)
# 输出预测结果
for i, row in test_data.iterrows():
vmid = row['vmid']
time = row['time']
mean = predicted_means[i]
print(f"Time: {time}, vmid: {vmid}, Predicted mean: {mean}")
# 创建一个DataFrame来存储预测结果
result_df = pd.DataFrame({'Time': test_data['time'], 'vmid': test_data['vmid'], 'Predicted Mean': predicted_means})
# 将结果保存到CSV文件
result_df.to_csv('RandomForestRegressor.csv', index=False)
print("Predicted results saved to RandomForestRegressor.csv")
模型四:决策树回归
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from tqdm import tqdm
from sklearn.preprocessing import OneHotEncoder
# 从CSV文件读取训练数据,从第二行开始
train_data = pd.read_csv('your_train_data.csv', skiprows=1, header=None, names=['time', 'vmid', 'mean'])
# 使用独热编码来处理 'vmid' 列
encoder = OneHotEncoder(sparse_output=False)
vmid_encoded = encoder.fit_transform(train_data[['vmid']])
X_train = pd.concat([train_data['time'], pd.DataFrame(vmid_encoded, columns=encoder.get_feature_names_out(['vmid']))], axis=1)
# 目标变量是mean
y_train = train_data['mean']
# 初始化决策树回归模型
model = DecisionTreeRegressor()
# 在训练集上训练模型,添加进度条
with tqdm(total=len(X_train)) as pbar:
model.fit(X_train, y_train)
pbar.update(len(X_train))
# 从CSV文件读取测试数据,从第二行开始
test_data = pd.read_csv('your_test_data.csv', skiprows=1, header=None, names=['time', 'vmid'])
# 使用独热编码来处理 'vmid' 列
vmid_encoded_test = encoder.transform(test_data[['vmid']])
X_test = pd.concat([test_data['time'], pd.DataFrame(vmid_encoded_test, columns=encoder.get_feature_names_out(['vmid']))], axis=1)
# 进行mean值预测
predicted_means = model.predict(X_test)
# 输出预测结果
for i, row in test_data.iterrows():
vmid = row['vmid']
time = row['time']
mean = predicted_means[i]
print(f"Time: {time}, vmid: {vmid}, Predicted mean: {mean}")
# 创建一个DataFrame来存储预测结果
result_df = pd.DataFrame({'Time': test_data['time'], 'vmid': test_data['vmid'], 'Predicted Mean': predicted_means})
# 将结果保存到CSV文件
result_df.to_csv('decision_tree.csv', index=False)
print("Predicted results saved to decision_tree.csv")