【pwn入门】基础知识
声明
本文是B站你想有多PWN和星盟安全学习的笔记,包含一些视频外的扩展知识。
工具和命令
常见的工具
- pwntools安装
- checksec安装
- pwndbg的安装和gdb使用
- ubuntu没有使用全部磁盘空间
sudo lvextend -l +100%FREE /dev/mapper/ubuntu--vg-ubuntu--lv
sudo resize2fs /dev/mapper/ubuntu--vg-ubuntu--lv
- one_gadget 下载 安装 与使用
- LibcSearcher-ng
- ubuntu 64上的GCC如何编译32位程序
sudo apt-get install build-essential module-assistant
sudo apt-get install gcc-multilib g++-multilib
gcc -m32 hello.c -o hello
- 关闭安全编译选项
gcc -m32 overflow.c -o overflow -z execstack -z norelro -fno-pie -no-pie -fno-stack-protector
常见命令
file
1.功能:查看文件的类型信息
2.案例:
![]()
3. 详细教程
ldd
1.功能:用于打印程序或者库文件所依赖的共享库列表
2.案例

3.详细教程
nm
1.功能:该命令用来列出指定文件中的符号
2.案例

3.详细教程
hexdump
1.功能:hexdump是Linux下的一个二进制文件查看工具,它可以将二进制文件转换为ASCII、八进制、十进制、十六进制格式进行查看。
2.案例

3.详细教程
readelf
1.功能:用于显示 elf 格式文件的信息
2.案例

3.详细教程
objdump
1.功能:对二进制进行反汇编
2.案例:
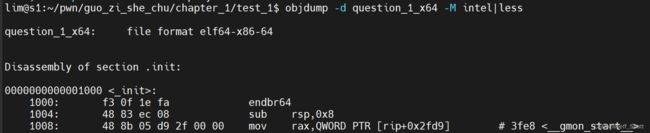
3.详细教程
gcc
1.功能:对源码进行编译
2.案例
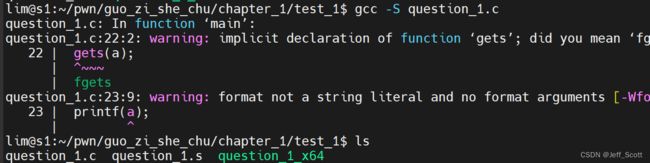
3.详细教程
寄存器
通用寄存器
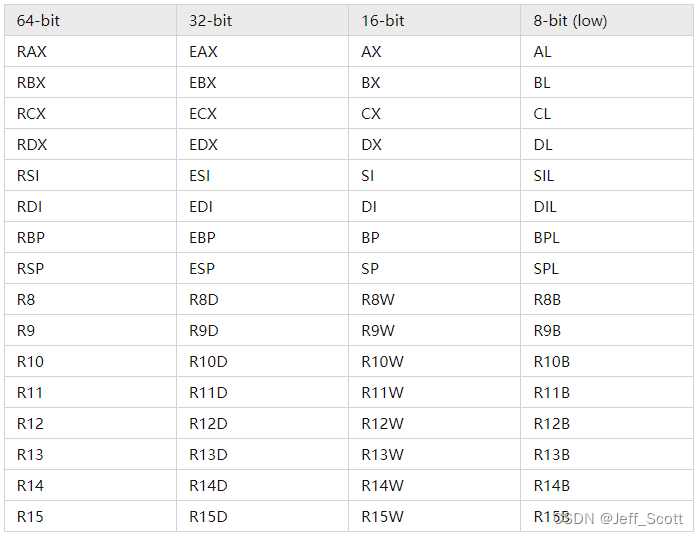
32位寄存器
eax:通常用来执行加法,函数调用的返回值一般也放在这里面
ebx:数据存取
ecx:通常用作计数器,比如for循环
edx:暂不清楚
esp:栈顶指针,指向栈的顶部
ebp:栈底指针,指向栈的底部,通常用ebp+偏移量的形式来定位函数存放在栈中的局部变量
edi:字符串操作时,用于存放数据源的地址
esi:字符串操作时,用于存放目的地址的,和edi两个经常搭配一起使用,执行字符串的复制等操作
64位寄存器
rax:通常用于存储函数调用返回值
rsp:栈顶指针,指向栈的顶部
rdi:第一个入参
rsi:第二个入参
rdx:第三个入参
rcx:第四个入参
r8:第五个入参
r9:第六个入参
rbx:数据存储,遵循Callee Save原则
rbp:存放当前栈帧的栈底地址
r12~r15:数据存储,遵循Callee Save原则
r10~r11:数据存储,遵循Caller Save原则
特殊寄存器
指针寄存器(instruction pointer, RIP)
在64位模式下,指令指针是RIP寄存器。 这个寄存器保持着下一条要执行的指令的64位地址偏移量
X86-64的RIP可以切分成32位的EIP 和 16位IP,CPU是几位模式下就只能使用对应的指针寄存器。
状态寄存器(status register, RFLAGS)
RFLAGS也有32位和16位版本,分别是EFLAGS 和 FLAGS。但是EFLAGS 和 FLAGS可以同时使用。
段寄存器 (Segment registers)X86-64一共有6个段寄存器: CS, SS, DS, ES, FS, and GS。
除了长模式以外的所有CPU运行模式里,都有一个段选择器 selector, 表示当前使用GDT 还是 LDT。 同时,还需要一个段描述符descriptor, 提供了段的基址和范围。(Linux中基本不使用分段)
长模式中,除了 FS 和 GS 之外的所有内容都被视为在一个具有零基地址和64位范围的平面地址空间中。 FS 和 GS 作为特殊情况保留,但不再使用段描述符表,取而代之的是,访问保存在 FSBASE 和 GSBASE 中的MSR寄存器中的基地址。
参考资料
汇编基础
常见的汇编指令
数据传输指令
- MOV
MOV DEST, SRC // 把源操作数传送给目标
MOV EAX,1234H // 执行结果(EAX) = 1234H
MOV EBX, EAX
MOV EAX, [00404011H] // [ ] 表示取地址内的值
MOV EAX, [ESI]
- PUSH
PUSH VALUE // 把目标值压栈,同时SP指针-1字长
PUSH 1234H
PUSH EAX
- POP
POP DEST // 将栈顶的值弹出至目的存储位置,同时SP指针+1字长
POP EAX
算术运算指令
- ADD
- SUB
- LEA
LEA REG, SRC // 把源操作数的有效地址送给指定的寄存器
LEA EBX, ASC // 取 ASC 的地址存放至 EBX 寄存器中
LEA EAX, 6[ESI] // 把 ESI+6 单元的32位地址送给 EAX
逻辑运算指令
-
NOT 取反运算指令 NOT dest 把操作数dest按位取反
-
AND 与运算指令 AND dest, src 把dest和src进行与运算之后送回dest
-
OR 或运算指令 OR dest, src 把dest和src进行或运算之后送回dest
-
XOR 异或运算 XOR dest, src 把dest和src进行异或运算之后送回dest
转移指令
- CMP
比较整数
CMP destination,source
- JMP
无条件转移指令 JMP lable 无条件地转移到标号为label的位置 - J[Condition] JCC
有条件转移指令 - CALL
过程调用指令 CALL labal 直接调用label - LEAVE
在函数返回时,恢复父函数栈帧的指令,等效于:
MOV ESP, EBP
POP EBP
- RET
在函数返回时,控制程序执行流返回父函数的指令,等效于:
POP RIP // 这条指令实际是不存在的,不能直接向RIP寄存器传送数据
参考资料
从C源代码到可执行文件的生成过程
编译:由C语言代码生成汇编代码
汇编:由汇编代码生成机器码
链接:将多个机器码的目标文件链接成一个可执行文件

两种汇编格式

GDB调试
常见的命令
gdb program // 启动进程,不带参数
run[r] // 运行程序。可搭配参数使用
start // 运行程序,停在第一条执行语句。可搭配参数使用
list[l] // 查看程序源码
break[b] // 设置断点。可指定文件名、函数名和行号等参数来设置断点
delete // 删除断点等。可用于删除断点、监视点、display 等
continue[c] // 继续执行程序。让程序继续执行,到下一个断点或程序结束
next[n] // 单步执行程序,跳过函数调用
step[s] // 单步执行程序,进入函数调用
finish // 结束当前函数。返回到函数调用点
参考资料
字节序
小端序
低地址存放数据低位、高地址存放数据高位,我们所主要关注的格式。(助记:小跟班守规矩,低放低,高放高)

大端序
低地址存放数据高位、高地址存放数据低位。(助记:大领导不守规矩,高低错位)

程序结构
磁盘中的文件
ELF文件头表(ELF header)
记录了ELF文件的组织结构
程序头表/段表(Program header table)
告诉系统如何创建进程
生成进程的可执行文件必须拥有此结构
重定位文件不一定需要
节头表(Section header table)
记录了ELF文件的节区信息
用于链接的目标文件必须拥有此结构
其它类型目标文件不一定需要
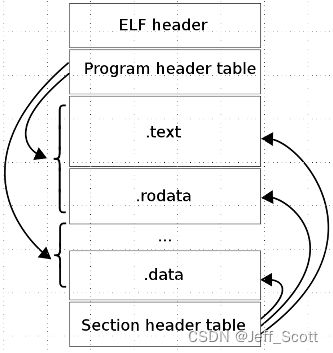
内存中进程
Kernel Space:内核空间
Stack:栈 ,存储局部、临时变量,函数调用时,存储函数的返回指针,用于控制函数的调用和返回。在程序块开始时自动分配内存,结束时自动释放内存,其操作方式类似于数据结构中的栈。
Heap:堆,存储动态内存分配,需要程序员手工分配,手工释放.注意它与数据结构中的堆是两回事,分配方式类似于链表。
BSS Segment:未初始化过的数据,在程序运行初未对变量进行初始化的数据。
Data Segment:初始化过的数据,在程序运行初已经对变量进行初始化的数据。
Text Segment:程序段,程序代码在内存中的映射,存放函数体的二进制代码。

栈
进程地址空间中最顶部的段是栈,大多数编程语言将之用于存储函数参数和局部变量。调用一个方法或函数会将一个新的栈帧(stack frame)压入到栈中,这个栈帧会在函数返回时被清理掉。由于栈中数据严格的遵守FIFO的顺序,这个简单的设计意味着不必使用复杂的数据结构来追踪栈中的内容,只需要一个简单的指针指向栈的顶端即可,因此压栈(pushing)和退栈(popping)过程非常迅速、准确。进程中的每一个线程都有属于自己的栈。
堆
与栈一样,堆用于运行时内存分配;但不同的是,堆用于存储那些生存期与函数调用无关的数据。大部分语言都提供了堆管理功能。在C语言中,堆分配的接口是malloc()函数。如果堆中有足够的空间来满足内存请求,它就可以被语言运行时库处理而不需要内核参与,否则,堆会被扩大,通过brk()系统调用来分配请求所需的内存块。堆管理是很复杂的,需要精细的算法来应付我们程序中杂乱的分配模式,优化速度和内存使用效率。处理一个堆请求所需的时间会大幅度的变动。实时系统通过特殊目的分配器来解决这个问题。

参考资料
磁盘和内存的映射
一个段(segment)包含多个节(section),段视图用于进程的内存区域的 rwx权限划分,节视图用于ELF文件编译链接时与在磁盘上存储时 的文件结构的组织。
代码段(Text segment)包含了代码与只读数据
.text 节
.rodata 节
.hash 节
.dynsym 节
.dynstr 节
.plt 节
.rel.got 节
……
数据段(Data segment)包含了可读可写数据
.data 节
.dynamic 节
.got 节
.got.plt 节
.bss 节
……
栈段(Stack segment)


程序数据是如何在内存中组织的
