中移物联在车联网场景中基于 TDengine 3.0 时序数据库的最佳实践
case
小T导读
在中移物联网的智慧出行场景中,需要存储车联网设备的轨迹点,还要支持对车辆轨迹进行查询。为了更好地进行数据处理,他们在 2021 年上线了 TDengine 2.0 版本的 5 节点 3 副本集群。3.0 发布后,它的众多特性吸引着中移物联网进行了大版本升级。本文详细分享了中移物联网在 3.0 项目的业务实践和全新体验,以此给大家作参考。
关于中移物联网
中移物联网有限公司是中国移动通信集团有限公司出资成立的全资子公司。公司按照中国移动整体战略布局,围绕“物联网业务服务的支撑者、专用模组和芯片的提供者、物联网专用产品的推动者”的战略定位,专业化运营物联网专用网络,设计生产物联网专用模组和芯片,打造智慧出行、智能家居、智能穿戴等特色产品,开发运营物联网连接管理平台 OneLink 和物联网开放平台 OneNET,推广物联网解决方案,形成了五大方向业务布局和物联网“云-网-边-端 ”全方位的体系架构。
从 2.0 到 3.0
智慧出行是中移物联网的一个非常典型的场景,我们需要存储车联网设备的轨迹点,还要支持对轨迹进行查询。最初我们使用的是 Oracle 小型机单表分区存储数据,运维复杂不便管理。2017 年,响应集团去 IOE 的要求,该项目开始使用 MySQL 集群。2019 年,产品提出了更高的数据存储需求,我们又开始调研国产数据库 TiDB,但由于其存储成本过高,不适合轨迹存储这种低价值的数据,而且不能解决行业客户轨迹数据存储周期定制化的需要,因此我们开始继续调研新的存储方案——国产开源时序数据库 (Time Series Database)TDengine 就是这个时候进入了我们的视野。
在调研中我们发现,智慧出行轨迹数据的特点天然适合 TDengine :
高频写入,每天写入约两亿条轨迹数据;
低频查询,通常是由用户触发,查询最近几天的轨迹;
企业用户有定制轨迹存储周期的需求;
不针对 OLAP 需求,数据价值密度低。
因此,在经历了严谨的选型测试后,我们最终确定选择 TDengine 作为新的数据存储引擎。具体选型过程和项目历史背景可以参考 2.x 版本的案例《存储空间降为原来的1/7,TDengine在中移物联网轨迹数据存储中的应用》。
改造后系统的整体架构如下图所示:
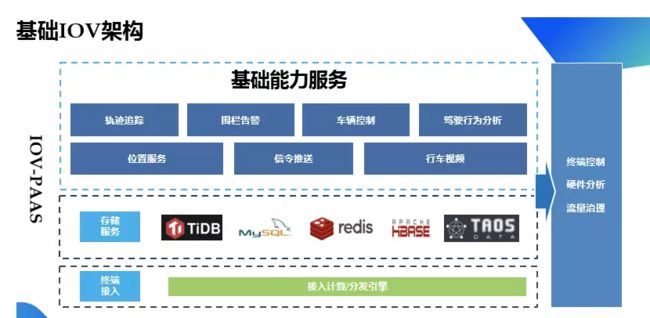
我们在 2021 年上线 TDengine 的 2.4.0.18 的 5 节点 3 副本集群稳定运行至今。今年 3.0 发布后,它的众多特性十分吸引我们,其中最典型的几个包括:
Raft 协议的引入使 TDengine 拥有了更标准的一致性算法
存储引擎的重构优化了 2.x 版本的设计
查询灵活度大幅提升,可实现的需求变得多元化
支持更强大的流式计算
因此,尽管 2 - 3 版本底层数据文件并不兼容,我们还是自己写了程序把数据迁移到了 3.0.2.5 版本,以至于后面官方正式发布了企业版迁移工具 taosX 的时候,我们早就先走一步了。
3.0 使用体验
TDengine 3.0 的安装部署上保留了和 2.0 一样的简单易用模式,升级操作只需要备份数据文件目录,覆盖安装即可,而且写入速度极高,接近硬盘的连续写入性能。TDengine 的高效压缩算法,可以节省大量存储空间,SQL 使用也非常简单。在此前对 MySQL 方案的替换中,我们的存储空间降为原来的 1/7,可以看到,在节省存储空间方面,TDengine 的优势极为明显。
目前我们共有 102 万张子表,已经累积的总数据量已经达到了 2000 亿行,3 副本,磁盘占用 3.1TB。在迁移到 TDengine 3.0 之后,各方面的表现依然非常不错:业务的写入峰值达到了 1.2-1.3w 行/s ,数据迁移的过程中可以达到 20w 行/s,这些情况下 TDengine 都可以轻松处理;存储大约只有 MySQL 的 1/7;读取数据性能也很突出,我们最常用的单设备单日查询,可以在 0.1s 内返回结果。
我们当前使用的是 3.0.2.5 版本,但是由于业务本身不允许停机,所以没办法做离线升级。因此,后续会由 TDengine 企业版团队协助我们在线升级至最新版本(当前最新版本为 3.0.5.1)。
3.0 建模设计
在库表设计上,我们运用了自动建表来写入数据,每个终端设备产生的轨迹点位数据在第一次入库的时候自动创建子表,这样只需要建一个 database 和业务需求的超级表就可以了,省掉了数据入库时的校验和建表操作。
值得一提的是,在 2.x 时代,元数据是在管理节点上集中存储的,因此在当时的版本中,自动建表的速度会受到单线程工作能力的制约,当时大概最高每秒只能创建 6000 个子表左右,不过当时我们也没有这么高的建表频率所以也没有受到太大影响。经过重构之后,3.0 的元数据已经完全做到了分布式存储,所有 vnode 都会独立存储自己表的元数据并处理写入操作,所以自动建表的写入效率已经大幅增加。
我们的超级表建表语句如下,可以给大家参考:
1.车辆历史状态、位置:
create stable device_statushis ( pos_time TIMESTAMP, sample_time TIMESTAMP, record_time TIMESTAMP, online_status SMALLINT, alarm_status SMALLINT, pos_method SMALLINT, pos_precision SMALLINT, pos_longitude DOUBLE, pos_latitude DOUBLE, pos_altitude DOUBLE, pos_speed FLOAT, pos_direction FLOAT, acc_forward FLOAT, acc_side FLOAT, acc_verticle FLOAT, rollover_level SMALLINT, power_voltage FLOAT, acc_status SMALLINT, satellite_num SMALLINT ) tags( device_id BINARY(32) ) ;2.车辆事件:四急( 急加速 急减速 急刹车 急转弯)
CREATE STABLE `emg_info` (`pos_time` TIMESTAMP, `sample_time` TIMESTAMP, `record_time` TIMESTAMP, `duration` SMALLINT, `mid_interval` SMALLINT, `mid_number` SMALLINT, `pre_number` SMALLINT, `pre_interval` SMALLINT, `start_time` TIMESTAMP, `end_time` TIMESTAMP, `start_lat` DOUBLE, `end_lat` DOUBLE, `start_lng` DOUBLE, `end_lng` DOUBLE, `event_type` SMALLINT, `sample_info` NCHAR(2048), `parameter_type` NCHAR(10)) TAGS (`device_id` VARCHAR(32), `app_code` NCHAR(32));3.GPS 信息:
CREATE STABLE `gps_info` (`pos_time` TIMESTAMP, `sample_time` TIMESTAMP, `record_time` TIMESTAMP, `online_status` SMALLINT, `alarm_status` SMALLINT, `pos_method` SMALLINT, `pos_precision` SMALLINT, `pos_longitude` DOUBLE, `pos_latitude` DOUBLE, `pos_altitude` DOUBLE, `pos_speed` FLOAT, `pos_direction` FLOAT, `acc_forward` FLOAT, `acc_side` FLOAT, `acc_verticle` FLOAT, `rollover_level` SMALLINT, `power_voltage` FLOAT, `acc_status` SMALLINT, `satellite_num` SMALLINT) TAGS (`device_id` VARCHAR(32), `app_code` NCHAR(32), `device_hash` INT);4. 汽车总线数据:
CREATE STABLE `can_info` (`pos_time` TIMESTAMP, `sample_time` TIMESTAMP, `record_time` TIMESTAMP, `gas_pedal_position` FLOAT, `spark_angle` FLOAT, `total_fuel_consumption` INT, `storage_battery_voltage` FLOAT, `latest_engine_runtime` INT, `fuel_pressure` INT, `distance_after_mil` INT, `long_term_fuel_trim` FLOAT, `engine_rpm` INT, `intake_manifold_pressure` SMALLINT, `distance_total` INT, `engine_inlet_port_temp` SMALLINT, `calcu_load` TINYINT, `vehicle_speed` SMALLINT, `fuel_type` NCHAR(30), `area_code` INT) TAGS (`device_id` VARCHAR(32), `app_code` NCHAR(32));在应用层,由于我们存储的数据是车辆轨迹数据,因此会做很多关于车辆轨迹数据的分析,比如:热点路线、轨迹段数据、停留点、行驶事件(急转弯、急加速、急减速、车辆其它信息),但由于 TDengine 一直以来都是时序数据库,并没有地理信息相关的计算函数,所以在这块我们自己写了很多函数,通过 Spark 的 RDD 来进行了计算分析,最后再把分析后的数据返回给客户端。
未来展望
目前 TDengine 能够很好地解决我们的需求,尤其是强大的存取能力是我们最满意的地方。但近期我从官方人员处得知,从即将于 7 月份发布的 3.0.6.0 版本开始,TDengine 将提供全新的数据类型 geometry 用于点线面等几何类型的存储,并且会逐步提供一套符合 OGC(Open Geospatial Consortium) 标准的 SQL 函数,包括几何输入输出、空间关系、几何测量、集合操作和几何处理等等。
其实通过我们观察,还是有很多车联网用户对于轨迹分析有使用需求,如果 TDengine 可以完整支持到空间数据的处理,这样我们的系统架构将会进一步简化,连 Spark 都可以不用了,这就可以说是完全意义上地使用了 All in one 的时序数据处理引擎。
可惜的是,目前由于我们历史数据的经纬度都是通过单独列来存储的,对于 Geometry 带来的全新数据类型,我们庞大的历史数据量和应用层是很难快速调整的,所以只能在测试环境应用,先逐渐试用起来。
最后,祝 TDengine 越来越好,最终成为时序数据库的事实标准。
作者介绍|PROFILE
薛超,中移物联网数据库运维高级工程师,10 年数据库运维经历,2017 年加入中移物联网,负责智能硬件产品部数据库相关工作,专注于数据库优化和推动架构演进;近年来主要研究国产新型数据库,目前所在部门全部业务已经去“O”,在此过程中,积累了大量新型数据库的运维经验。
往期推荐
☞ 十年回望,中国物联网平台消亡史
☞ IDC中国 IoT物联网平台评估报告
☞ IoT物联网平台趋势: 私有化
☞ 5个值得分享的物联网创业失败教训
☞ 国内 4 大 IoT物联网平台选型对比
☞ 云厂商的「IoT物联网平台」不香了吗?
