【计算机视觉】Vision Transformers算法介绍合集(一)
文章目录
-
- 一、Vision Transformer
- 二、Swin Transformer
- 三、Detection Transformer
- 四、Data-efficient Image Transformer
- 五、self-DIstillation with NO labels
- 六、Deformable DETR
- 七、Compact Convolutional Transformers
- 八、NesT
- 九、Pyramid Vision Transformer
- 十、Dense Prediction Transformer
- 十一、Convolutional Vision Transformer
- 十二、Tokens-To-Token Vision Transformer
- 十三、Multiscale Vision Transformer
- 十四、MoCo v3
- 十五、LV-ViT
Vision Transformers 是应用于视觉任务的类似 Transformer 的模型。 它们源于 ViT 的工作,直接将 Transformer 架构应用于非重叠的中型图像块上进行图像分类。 您可以在下面找到不断更新的视觉转换器列表。
ViT类型模型可以进一步分为均匀尺度ViT、多尺度ViT、带卷积的混合ViT和自监督ViT。 下面列出的方法全面概述了应用于一系列视觉任务的 ViT 模型。
一、Vision Transformer
Vision Transformer(ViT)是一种图像分类模型,它在图像块上采用类似 Transformer 的架构。 将图像分割成固定大小的块,然后将每个块线性嵌入,添加位置嵌入,并将所得向量序列馈送到标准 Transformer 编码器。 为了执行分类,使用了向序列添加额外的可学习“分类标记”的标准方法。
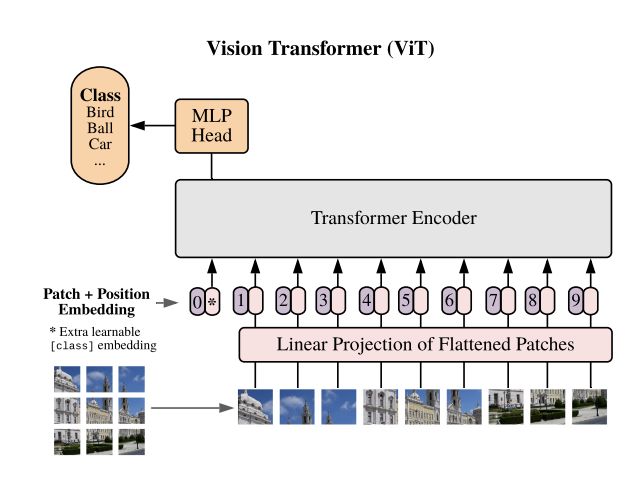
二、Swin Transformer
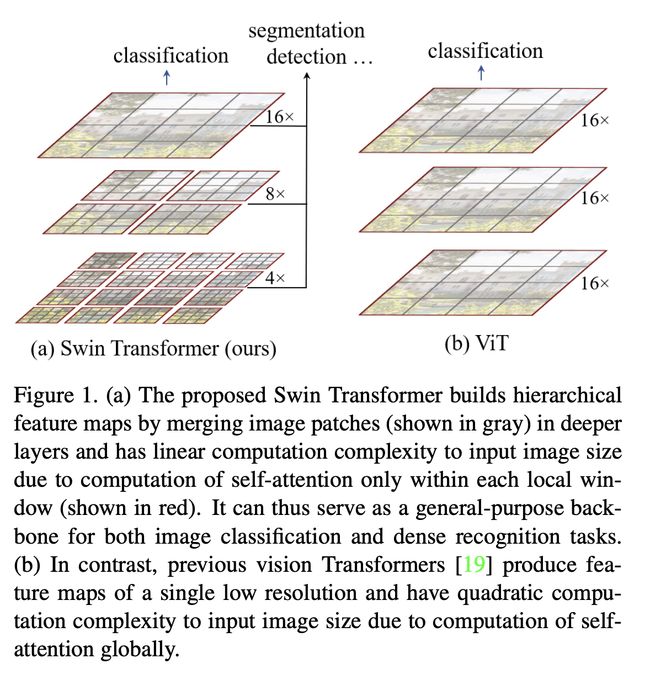
Swin Transformer 是视觉变压器的一种。 它通过合并更深层中的图像块(以灰色显示)来构建分层特征图,并且由于仅在每个局部窗口(以红色显示)内计算自注意力,因此具有输入图像大小的线性计算复杂性。 因此,它可以作为图像分类和密集识别任务的通用主干。 相比之下,以前的视觉 Transformer 会生成单个低分辨率的特征图,并且由于全局自注意力的计算,输入图像大小的计算复杂度是二次方的。
三、Detection Transformer
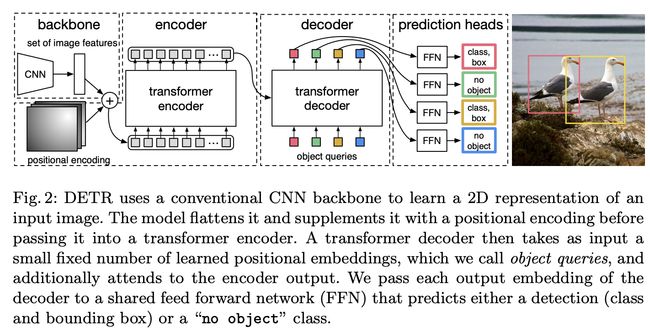
Detr(即检测变压器)是一种基于集合的目标检测器,在卷积主干之上使用变压器。 它使用传统的 CNN 主干来学习输入图像的 2D 表示。 该模型将其展平并用位置编码对其进行补充,然后将其传递到变压器编码器。 然后,变压器解码器将少量固定数量的学习位置嵌入(我们称之为对象查询)作为输入,并另外关注编码器输出。 我们将解码器的每个输出嵌入传递到共享前馈网络(FFN),该网络预测检测(类和边界框)或“无对象”类。
四、Data-efficient Image Transformer
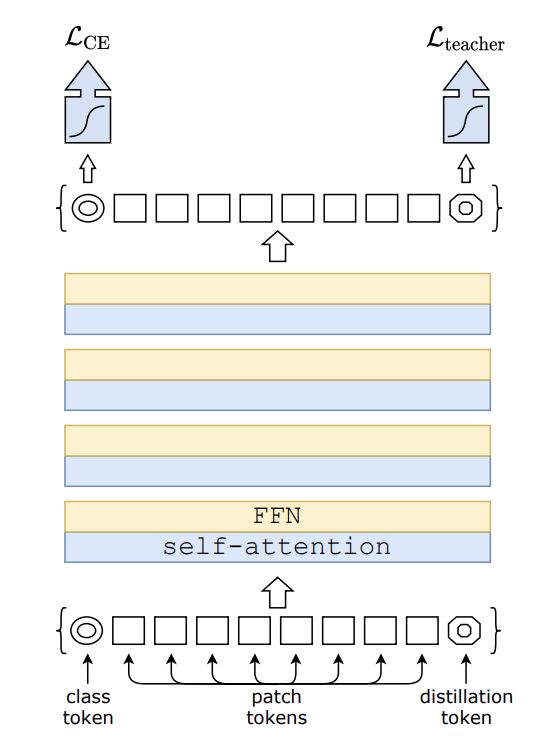
数据高效图像转换器是一种用于图像分类任务的视觉转换器。 该模型使用 Transformer 特有的师生策略进行训练。 它依赖于蒸馏令牌,确保学生通过注意力向老师学习。
五、self-DIstillation with NO labels
DINO(无标签自蒸馏)是一种自监督学习方法,它使用标准交叉熵损失直接预测由动量编码器构建的教师网络的输出。


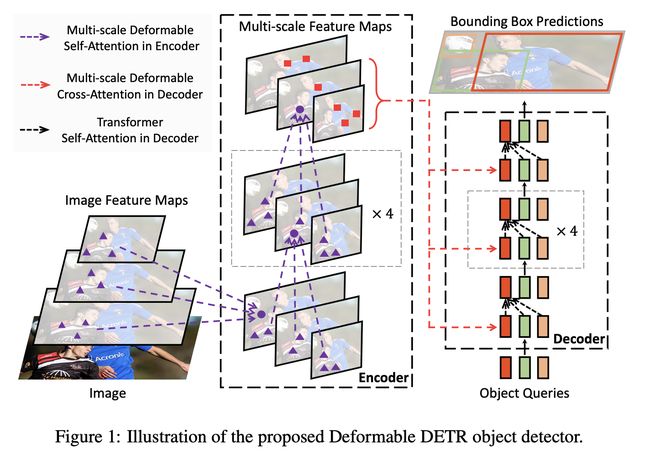
六、Deformable DETR
可变形 DETR 是一种目标检测方法,旨在缓解 DETR 收敛速度慢和复杂度高的问题。 它结合了可变形卷积的稀疏空间采样和 Transformers 的关系建模功能的最佳性能。 具体来说,它引入了一个可变形注意模块,该模块关注一小组采样位置,作为所有特征图像素中突出关键元素的预过滤器。 该模块可以自然地扩展到聚合多尺度特征,而无需借助 FPN。
七、Compact Convolutional Transformers
紧凑卷积变压器利用序列池并用卷积嵌入替换补丁嵌入,从而实现更好的归纳偏差并使位置嵌入成为可选。 CCT 比 ViT-Lite(较小的 ViT)实现了更好的精度,并增加了输入参数的灵活性。

八、NesT
NesT 堆叠规范的 Transformer 层,对每个图像块独立进行局部自注意力,然后分层“嵌套”它们。 空间相邻块之间的处理信息的耦合是通过每两个层次结构之间所提出的块聚合来实现的。 整体的层次结构可以由两个关键的超参数决定:


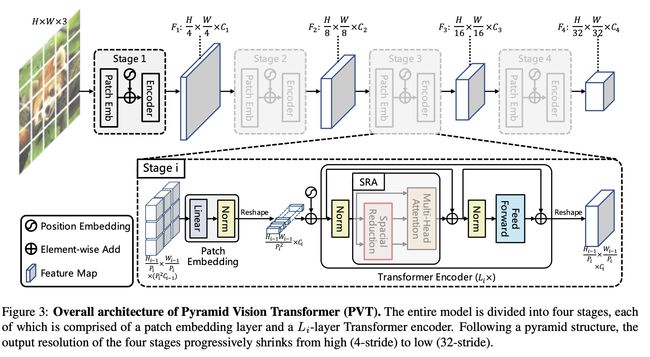
九、Pyramid Vision Transformer
PVT(金字塔视觉变压器)是一种视觉变压器,利用金字塔结构使其成为密集预测任务的有效骨干。 具体来说,它允许使用更细粒度的输入(每个补丁 4 x 4 像素),同时随着 Transformer 的加深而缩小其序列长度,从而降低计算成本。 此外,空间减少注意(SRA)层用于进一步减少学习高分辨率特征时的资源消耗。

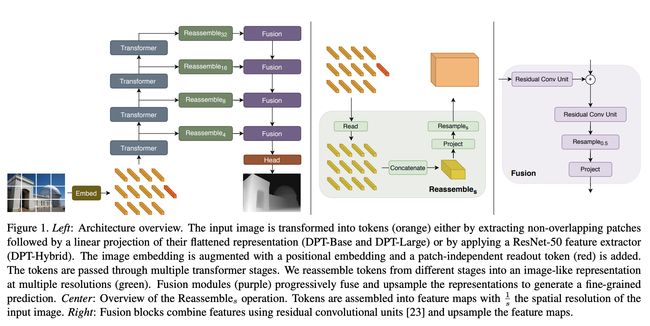
十、Dense Prediction Transformer
密集预测变压器(DPT)是一种用于密集预测任务的视觉变压器。
通过提取非重叠斑块,然后对其展平表示(DPT-Base 和 DPT-Large)进行线性投影,或者通过应用 ResNet-50 特征提取器(DPT-Hybrid),将输入图像转换为标记(橙色)。 图像嵌入通过位置嵌入得到增强,并添加了与补丁无关的读出标记(红色)。 令牌通过多个变压器阶段。 令牌从不同阶段重新组装成多种分辨率的类似图像的表示(绿色)。 融合模块(紫色)逐步融合和上采样表示以生成细粒度的预测。
十一、Convolutional Vision Transformer
卷积视觉 Transformer (CvT) 是一种将卷积合并到 Transformer 中的架构。 CvT 设计将卷积引入到 ViT 架构的两个核心部分。
首先,Transformers 被划分为多个阶段,形成 Transformers 的层次结构。 每个阶段的开始由一个卷积令牌嵌入组成,该嵌入在 2D 重塑令牌图上执行重叠卷积操作(即,将扁平令牌序列重塑回空间网格),然后进行层归一化。 这使得模型不仅可以捕获局部信息,还可以逐步减少序列长度,同时增加跨阶段标记特征的维度,实现空间下采样,同时增加特征图的数量,就像 CNN 中执行的那样。
其次,Transformer 模块中每个自注意力块之前的线性投影被替换为提出的卷积投影,该投影在 2D 重塑令牌图上采用 s × s 深度可分离卷积运算。 这使得模型能够进一步捕获局部空间上下文并减少注意机制中的语义歧义。 它还允许管理计算复杂性,因为卷积的步长可用于对键和值矩阵进行二次采样,以将效率提高 4 倍或更多,同时将性能下降降至最低。

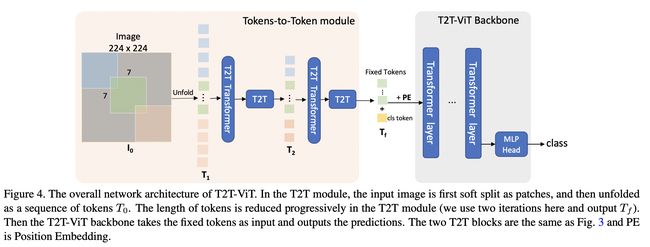
十二、Tokens-To-Token Vision Transformer
T2T-ViT(Tokens-To-Token Vision Transformer)是一种 Vision Transformer,它结合了 1)分层的 Tokens-to-Token (T2T) 转换,通过递归地将相邻的 Tokens 聚合成一个 Token(Tokens)来逐步将图像结构化为 tokens。 -to-Token),这样可以对周围令牌表示的局部结构进行建模,并可以减少令牌长度; 2)经过实证研究后,受 CNN 架构设计启发,为视觉变换器提供了具有深窄结构的高效主干。
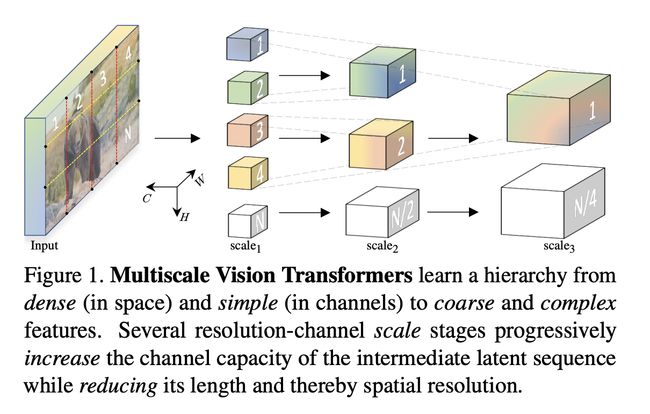
十三、Multiscale Vision Transformer
多尺度视觉变压器(MViT)是一种用于对图像和视频等视觉数据进行建模的变压器架构。 与在整个网络中保持恒定通道容量和分辨率的传统 Transformer 不同,多尺度 Transformer 具有多个通道分辨率缩放阶段。 从输入分辨率和小通道尺寸开始,各阶段分层扩展通道容量,同时降低空间分辨率。 这创建了一个多尺度的特征金字塔,早期层以高空间分辨率运行,以模拟简单的低级视觉信息,而更深的层则以空间粗糙但复杂的高维特征运行。
十四、MoCo v3


十五、LV-ViT
LV-ViT 是一种视觉转换器,使用标记标签作为训练目标。 与 ViT 的标准训练目标不同,ViT 的标准训练目标是在额外的可训练类标记上计算分类损失,标记标记利用所有图像补丁标记以密集的方式计算训练损失。 具体来说,标记标记将图像分类问题重新表述为多个标记级识别问题,并为每个补丁标记分配由机器注释器生成的单独位置特定的监督。
