一、网络虚拟化——QEMU虚拟网卡
写在前面
网络虚拟化曾经只是内核虚拟化功能开发者才会关注的技术。但随着云计算模式和云原生概念的推广,云上业务的部署形态都已转向了虚拟机和容器,而两者都依赖网络虚拟化技术提供高性能网络功能,因此虚拟网络已经是云环境下的主流网络形态。而云上的虚拟机和容器对网络虚拟化技术的易用性、功能和性能都提出了更高的要求。
本文介绍最经典的网络虚拟化技术——QEMU虚拟网卡。
什么是KVM
KVM(Kernel-based Virtual Machine)是一个基于Linux内核的虚拟化技术,它允许在一个物理主机上运行多个虚拟机,并为每个虚拟机提供独立的操作系统和资源。KVM是一种硬件虚拟化技术,它利用处理器的虚拟化扩展来提供高性能的虚拟化解决方案。
以下是KVM的一些关键特点和工作原理:
硬件虚拟化: KVM利用支持虚拟化的处理器特性,如Intel的VT-x和AMD的AMD-V,以实现硬件虚拟化。这允许虚拟机直接访问物理硬件,从而提供接近原生性能的虚拟化。
Linux内核模块: KVM是一个Linux内核模块,它将虚拟化功能添加到Linux内核中。这意味着KVM虚拟机可以在Linux主机上运行,而且与Linux内核紧密集成,提供了更好的性能和管理能力。
虚拟机管理: KVM可以与各种虚拟机管理工具结合使用,最常见的是libvirt,它提供了一个统一的接口来管理KVM虚拟机的创建、配置和监控。管理员可以使用这些工具轻松地管理多个虚拟机实例。
多操作系统支持: KVM支持多种不同的操作系统,包括Linux、Windows、BSD等。这使得它成为一种通用的虚拟化解决方案,可以满足各种应用场景的需求。
性能: 由于KVM是硬件虚拟化技术,因此它通常提供了接近原生性能的虚拟化。这使得它适用于需要高性能的应用程序和工作负载。
问题
1.1 使用QEMU虚拟网卡时,guest系统中是如何使用网卡和网络的?是否感知虚拟化设备的存在,是否需要和运行在物理机上时使用不同的配置?是否需要修改内核?
1.2在guest系统中如何感知和加载网卡?QEMU是如何实现来支持这种功能的?
1.3在guest系统中如何通过网卡收发报文?QEMU是如何实现来支持这种功能的?
1.4guest系统收发的报文,在QEMU和host系统中是如何流转的?通过哪些环节实现guest和host、guest和外部网络间的交互?
1.5用QEMU虚拟网卡方式支持虚拟机网络功能有哪些优点和不足?
QEMU
QEMU是LINUX平台上广泛应用的虚拟机管理器(VMM),它能够模拟多种硬件架构和设备,支持模拟运行多种不同的操作系统。其中,QEMU就支持了对特定网卡设备(例如e1000)的全虚拟化,使得guest操作系统和内核不需要做任何修改就能使用原有的网卡驱动完成网络操作。
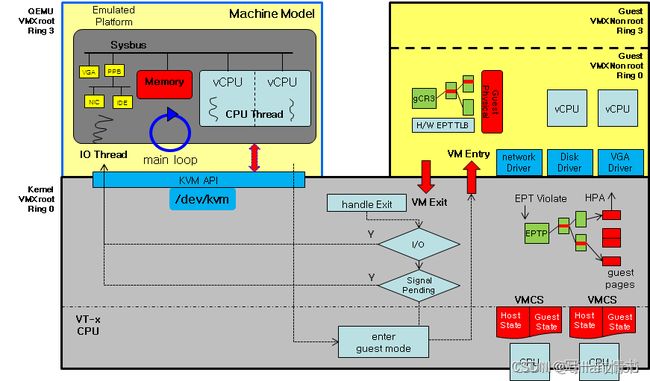
QEMU-KVM架构图(来自wiki.qemu.org)
QEMU模拟IO设备的原理,可以参考了解 QEMU 设备和High-level introduction to virtualization’s low-level。大体上,通过指令翻译或者基于KVM和CPU硬件虚拟化,QEMU可以在guest操作设备,也就是执行访问设备地址空间或寄存器的指令时,中断guest的执行流并模拟出guest操作对设备的影响,之后再恢复guest的执行。
QEMU虚拟网卡
网卡作为一种网络IO设备,在QEMU中的模拟实现和其他IO设备是一样的。通过QEMU的模拟,guest系统中使用虚拟网卡时的使用方法和感受和在物理机上是完全相同的(除了性能之外),不需要修改内核驱动或配置。
guest系统对网卡的感知和加载的模拟和其他设备的模拟也是一样的,对网卡的感知来自于QEMU对PCI/PCIE总线设备的模拟,对网卡的加载、收发包则是对网卡设备的模拟。
QEMU中实现了多种经典网卡设备的模拟,例如e1000、rtl8139、i82559c等。网卡设备和驱动的逻辑都是类似的,这里就以e1000的网络报文收发为例,分析一下guest中网络rx/tx操作的实现逻辑步骤。由于主流的x86架构CPU都已经支持了CPU硬件虚拟化,例如Intel的VT-x和AMD的AMD-V,因此这里只讨论QEMU-KVM场景。
TX:
guest内核将tx报文内容写入skb
guest内核将tx报文信息(例如数据的dma地址、长度等)写入descriptor ring
guest内核修改网卡的tx队列寄存器,通知网卡处理tx报文
触发VM Exit,KVM处理VM Exit事件
KVM发现是IO操作,返回用户态QEMU进程(qemu进程从ioctl中返回)
QEMU处理IO操作,根据descriptor内容将报文转发
QEMU更新虚拟网卡的状态和DMA内存
QEMU重新通过KVM接口恢复guest执行(VM Entry)
RX:
QEMU收到rx报文
QEMU将rx报文内容写入guest指定的DMA地址空间
QEMU将rx报文信息写入descriptor ring
QEMU更新rx队列寄存器(虚拟)
QEMU向guest注入中断
guest处理中断,更新descriptor ring和寄存器,这里又会陷入QEMU
上面只是一个简化的流程,guest处理报文的逻辑和物理机是一样的,可以参考Linux系统下网络数据包的处理流程。中断注入原理可以参考High-level introduction to virtualization’s low-level。
通过上述流程,guest发送的报文就能够被QEMU转发到host内核或网络上,而从host或网络上发给guest的报文也可以被QEMU转发到guest虚拟网卡上。
QEMU虚拟网络
前面已经介绍了QEMU如何模拟guest的网卡行为,但仍然有一个问题,就是报文在QEMU到host内核/网卡之间是如何流转的?毕竟,guest需要通信的对象并不是QEMU本身。这部分功能称为虚拟网络的后端。
QEMU支持的网络后端模式实现主要有两种:SLIRP(user)和TAP。
SLIRP模式是一种在用户态实现的后端。在这种模式下,QEMU在用户态解析guest收发的网络报文,并向其他guest和host转发。同时SLIRP还支持NAT地址转换。这就要求在SLIRP模式下实现一套TCP/IP协议栈。SLIRP的实现笔者没有看过,也没有找到详细介绍其原理的文章。据找到的个别资料介绍,SLIRP在和host或外部网络通信时,并不是通过raw socket转发报文的形式实现的,而是通过将guest报文的行为翻译成普通socket操作来实现的,例如guest发送了一个SYN包,SLIRP就调用一个到目标地址的connect syscall。这个实现听起来有些不可思议,但SLIRP本身来自于很古老的协议模拟软件,因此也是可以理解的。但这种实现功能必然有限,如果guest发送一些不太标准的报文或SLIRP协议栈不能理解或处理的报文,那么网络功能必然不能正常运行。
TAP模式就比较好理解了。这种模式下QEMU为每个guest创建一个tap设备,直接向这个tap设备收发报文。tap设备可以连接到一个bridge上实现更复杂的路由功能。
其实guest报文到了QEMU用户态逻辑之后,后端的实现方式可以有很多种,例如OVS或OVS-DPDK。这部分的功能与虚拟化其实已经没有太多的关系,更多是网络报文处理转发能力的实现。后续将不再重点讨论这部分技术。
小结
本文分析了QEMU的经典网络虚拟化实现:物理网卡虚拟,以及QEMU的经典后端实现方式:SLIRP和TAP。通过本文的分析,应该已经可以回答文章开头提出的4个问题:
-
使用QEMU虚拟网卡时,guest系统中是如何使用网卡和网络的?是否感知虚拟化设备的存在,是否需要和运行在物理机上时使用不同的配置?是否需要修改内核?
答案是不需要,guest完全不用感知或修改网络使用方式。 -
在guest系统中如何感知和加载网卡?QEMU是如何实现来支持这种功能的?
通过拦截和模拟实现guest的PCI和网卡设备访问操作,让guest获得和在物理机上相同的操作结果。 -
在guest系统中如何通过网卡收发报文?QEMU是如何实现来支持这种功能的?
同样通过拦截和模拟实现guest的网卡操作,并将外部发给guest的报文也通过模拟的方式交给虚拟机处理并注入中断。 -
guest系统收发的报文,在QEMU和host系统中是如何流转的?通过哪些环节实现guest和host、guest和外部网络间的交互?
通过SLIRP或TAP模式将报文转发到host或外部网络。 -
用QEMU虚拟网卡方式支持虚拟机网络功能有哪些优点和不足?
QEMU虚拟网卡方式实现网络功能的优点是对guest系统透明,不需要guest系统做任何修改,使用物理网卡驱动就能操作虚拟网卡完成网络通信。
这种实现方式的主要缺点有两个。一是需要用软件去模拟各种真实物理硬件网卡的功能,由于硬件网卡功能复杂而缺乏标准,因此QEMU模拟网卡的代码也复杂多变,而且可能存在软件模拟的网卡行为和硬件不一致,导致guest系统中的网络行为和host上出现差异。
另一个更明显的缺点是性能。根据前面的分析,每次读写网卡寄存器或IO地址时都会导致guest应用到QEMU进程的来回切换,而一次网络读写操作可能会产生多次网卡IO操作,这就导致使用QEMU虚拟网卡时虚拟机的网络性能受限于上下文和guest/host切换的速度,必然远低于物理机的性能水平。
原文链接:https://blog.csdn.net/dillanzhou/article/details/120169734