为什么不建议使用自定义Object作为HashMap的key
此前部门内的一个线上系统上线后内存一路飙高、一段时间后直接占满。协助开发人员去分析定位,发现内存中某个Object的量远远超出了预期的范围,很明显出现内存泄漏了。
结合代码分析发现,泄漏的这个对象,主要存在一个全局HashMap中,是作为HashMap的Key值。第一反应就是这里key对应类没有去覆写equals()和hashCode()方法,但对照代码仔细一看却发现其实已经按要求提供了自定义的equals和hashCode方法了。进一步走读业务实现逻辑,才发现了其中的玄机。
踩坑历程回顾
鉴于项目代码相对保密,这里举个简单的DEMO来辅助说明下。
场景:
内存中构建一个HashMap映射集,用于存储每个用户最近的发帖信息(只是个例子,实际工作中如果遇到这种用户发帖缓存的场景,一般都是用的集中缓存,而不是单机缓存)。
用户信息User类定义如下:
@Data
public class User {
// 用户名称
private String userName;
// 账号ID
private String accountId;
// 用户上次登录时间,每次登录的时候会自动更新DB对应时间
private long lastLoginTime;
// 其他字段,忽略
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return lastLoginTime == user.lastLoginTime &&
Objects.equals(userName, user.userName) &&
Objects.equals(accountId, user.accountId);
}
@Override
public int hashCode() {
return Objects.hash(userName, accountId, lastLoginTime);
}
}
}
实际使用的时候,用户发帖之后,会将这个帖子信息添加到用户对应的缓存中。
/**
* 将发帖信息加入到用户缓存中
*
* @param currentUser 当前用户
* @param postContent 帖子信息
*/
public void addCache(User currentUser, Post postContent) {
cache.computeIfAbsent(currentUser, k -> new ArrayList<>()).add(postContent);
}
当实际运行的时候,会发现问题就来了,Map中的记录越来越多,远超系统内实际的用户数量。为什么呢?仔细看下User类就可以知道了!
原来编码的时候直接用IDE工具自动生成的equals和hashCode方法,里面将lastLoginTime也纳入计算逻辑了。这样每次用户重新登录之后,对应hashCode值也就变了,这样发帖的时候判断用户是不存在Map中的,就会再往map中插入一条,随着时间的推移,内存中数据就会越来越多,导致内存泄漏。
这么一看,其实问题很简单。但是实际编码的时候,很多人往往又会忽略这些细节、或者当时可能没有这个场景,后面维护的人新增了点逻辑,就会出问题 —— 说白了,就是埋了个坑给后面的人踩上了。
hashCode覆写的讲究
hashCode,即一个Object的散列码。HashCode的作用:
- 对于List、数组等集合而言,HashCode用途不大;
- 对于HashMap\HashTable\HashSet等集合而言,HashCode有很重要的价值。
HashCode在上述HashMap等容器中主要是用于寻域,即寻找某个对象在集合中的区域位置,用于提升查询效率。
一个Object对象往往会存在多个属性字段,而选择什么属性来计算hashCode值,具有一定的考验:
- 如果选择的字段太多,而HashCode()在程序执行中调用的非常频繁,势必会影响计算性能;
- 如果选择的太少,计算出来的HashCode势必很容易就会出现重复了。
为什么hashCode和equals要同时覆写
这就与HashMap的底层实现逻辑有关系了。
对于JDK1.8+版本中,HashMap底层的数据结构形如下图所示,使用数组+链表或者红黑树的结构形式:
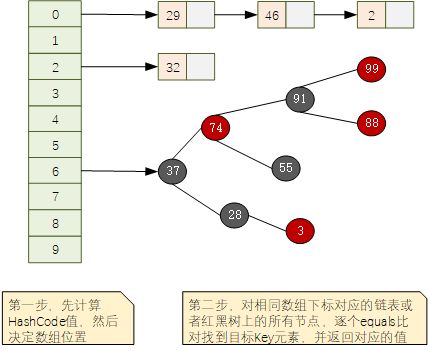
给定key进行查询的时候,分为2步:
- 调用key对象的hashCode()方法,获取hashCode值,然后换算为对应数组的下标,找到对应下标位置;
- 根据hashCode找到的数组下标可能会同时对应多个key(所谓的hash碰撞,不同元素产生了相同的hashCode值),这个时候使用key对象提供的equals()方法,进行逐个元素比对,直到找到相同的元素,返回其所对应的值。
根据上面的介绍,可以概括为:
- hashCode负责大概定位,先定位到对应片区
- equals负责在定位的片区内,精确找到预期的那一个
这里也就明白了为什么hashCode()和equals()需要同时覆写。
数据退出机制的兜底
其实,说到这里,全局Map出现内存泄漏,还有一点就是编码实现的时候缺少对数据退出机制的考虑。
参考下redis之类的依赖内存的缓存中间件,都有一个绕不开的兜底策略,即数据淘汰机制。
对于业务类编码实现的时候,如果使用Map等容器类来实现全局缓存的时候,应该要结合实际部署情况,确定内存中允许的最大数据条数,并提供超出指定容量时的处理策略。比如我们可以基于LinkedHashMap来定制一个基于LRU策略的缓存Map,来保证内存数据量不会无限制增长,这样即使代码出问题也只是这一个功能点出问题,不至于让整个进程宕机。
public class FixedLengthLinkedHashMap<K, V> extends LinkedHashMap<K, V> {
private static final long serialVersionUID = 1287190405215174569L;
private int maxEntries;
public FixedLengthLinkedHashMap(int maxEntries, boolean accessOrder) {
super(16, 0.75f, accessOrder);
this.maxEntries = maxEntries;
}
/**
* 自定义数据淘汰触发条件,在每次put操作的时候会调用此方法来判断下
*/
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxEntries;
}
}
总结
梳理下几个要点:
- 最好不要使用Object作为HashMap的Key
- 如果不得已必须要使用,除了要覆写equals和hashCode方法
- 覆写的equals和hashCode方法中一定不能有频繁易变更的字段
- 内存缓存使用的Map,最好对Map的数据记录条数做一个强制约束,提供下数据淘汰策略。
好啦,关于这个问题的分享就到这里咯,你是否有在工作中遇到此类相同或者相似的问题呢?欢迎一起分享讨论下哦~
我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点个关注,也可以关注下我的公众号【架构悟道】,获取更及时的更新。
期待与你一起探讨,一起成长为更好的自己。