经典匹配算法: KMP、Sunday与ShiftAnd
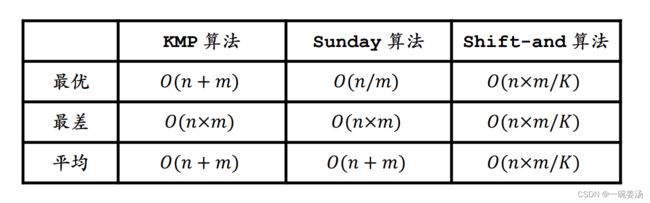
本次介绍的三种算法的时间复杂度:
基础概念:
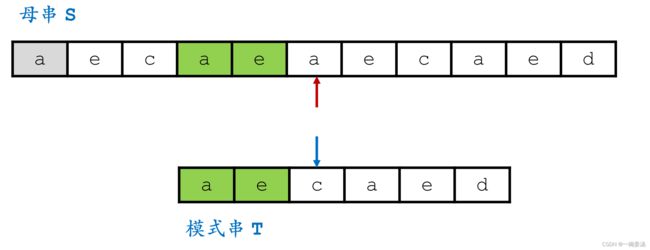 图3
图3
 图1
图1
单模匹配问题:单个模式串,比如我们要在一个长串(母串S)中查找一个短串(模式串T)是否出现过。
暴力匹配算法:
算法思想:用模式串去对齐母串的每一位,普通人能想到。
暴力匹配算法的作用是:让我们清楚地知道,这个世界上存在一种,虽然非常笨,但是能够正确地处理单模匹配问题的算法。所谓正确,其实意味着我们在匹配过程中,能够不重(不会重复地和母串某一位进行匹配对齐)不漏(不会漏掉任何一次有可能找到模式串的匹配机会)地去处理每一次匹配操作。为什么暴力匹配算法重要?因为我们应当意识到,不管我们对算法如何进行各种优化,我们优化以后的算法都要向暴力匹配算法一样,最起码做到两点:不重、不漏。即不管你怎么优化,在算法中都不能放弃任何一次有可能找到模式串的机会。
代码实现:
#include
using namespace std;
// 暴力匹配算法
int brute_force(const char *text, const char *pattern) { // 返回母串中模式串出现的起始位置
for (int i = 0; text[i]; ++i) {
int flag = 1;
for (int j = 0; pattern[j]; ++j) {
if (text[i + j] == pattern[j]) continue;
flag = 0;
break;
}
if (flag == 1) return i; // 找到模式串,直接返回
}
return -1; // 遍历完了每一个位置,都没有找到。
}
#define TEST(func, s1, s2) { \
printf("%s(\"%s\", \"%s\") = %d\n", #func, s1, s2, func(s1, s2)); \
}
int main() {
char s1[100], s2[100];
while (cin >> s1 >> s2) {
TEST(brute_force, s1, s2);
}
return 0;
} KMP算法:
在暴力匹配算法的基础上,我们要进行优化,首先得观察出来,暴力匹配算法究竟哪里比较浪费时间:
可以看到暴力匹配的时候,每次匹配失败都会往下一位进行对齐,但其实没有必要,下一次真正要对齐的是:模式串中,截止到我当前匹配成功的位置,最长的,前缀和后缀匹配的位置。
注意!这一点很关键:kmp将问题由从母串找信息,转变为到模式串里找信息。
 图2
图2
下一次就从这个匹配成功的后缀的起始位置开始就行了,跳过了中间那些注定会失败的部分:
假设我们用 ![]() 表示模式串中
表示模式串中 ![]() 位的前缀,
位的前缀,![]() 表示模式串中
表示模式串中 ![]() 位的后缀,那么以上过程可以看作对于图1中模式串中绿色部分,有如下的依次对比过程:
位的后缀,那么以上过程可以看作对于图1中模式串中绿色部分,有如下的依次对比过程:
- 是否从第2位对齐,pre_4=last_4
- 是否从第3位对齐,pre_3=last_3
- 是否从第4位对齐,pre_2=last_2
最终发现只有从第4位开始对齐的时候,pre_2=last_2等式成立。于是下一次对齐的地方就是第四位,而且,前两位默认匹配成功,没必要再匹配了。
KMP算法的一般过程如下图所示,黄色是第一次匹配失败的位置,蓝色是最长前缀后缀匹配:


往下就只需要继续比较黄色区域部分,如果匹配不成功,就开始新一轮的KMP加速:Ta就变成新一轮的“绿色部分”,重复上面的过程,形成一个递归:

所以,所谓的优化方向其实就是,跳过一些,绝对不会产生答案的匹配位置。KMP做的就是这样一个加速。
代码实现:
#include
#include
using namespace std;
// 提取kmp关键信息
void GetNext(const char *pattern, int *next) {
next[0] = -1; // 如果文本串和模式串第一位就匹配失败,这个时候我应该向前跳到-1位。
for (int i = 1, j = -1; pattern[i]; ++i) { // i指向的是第一个起冲突的位置,j指向的就是i的前一个,也就是模式串和母串匹配成功的位置
while (j != -1 && pattern[j + 1] - pattern[i]) j = next[j]; // 黄色部分匹配失败,j指向下一个绿色部分中可能匹配成功的位置
if (pattern[j + 1] == pattern[i]) j += 1; // 如果匹配成功, j就向后移动一位,绿色部分扩大一位
if (next[i] == j) next[i] = next[j]; // 修正的next数组
else next[i] = j;
}
return ;
}
int kmp(const char *text, const char *pattern) {
int n = strlen(pattern);
int *next = (int *)malloc(sizeof(int) * n); // 当前位置匹配不成功的时候,模式串要向前跳到第几位
GetNext(pattern, next); // 根据模式串的信息,预处理出KMP加速信息
for (int i = 0, j = -1; text[i]; i++) { // i指向当前匹配的每一位,j指向当前匹配位置之前匹配成功的那一位。
while (j != -1 && text[i] - pattern[j + 1]) j = next[j];
if (text[i] == pattern[j + 1]) j += 1;
if (pattern[j + 1] == 0) return i - j; // 匹配成功了模式串的最后一位,返回母串中的起始位置
}
return -1; // 匹配失败
}
#define TEST(func, s1, s2) { \
printf("%s(\"%s\", \"%s\") = %d\n", #func, s1, s2, func(s1, s2)); \
}
int main() {
char s1[100], s2[100];
while (cin >> s1 >> s2) {
TEST(kmp, s1, s2);
}
return 0;
} 算法思想升华:上面的过程可以抽象化成这样一个过程:给一个字符,j 变一下,状态变一下,这本质上就是状态机。是在做状态之间的转换。
因为kmp算法每一次只需要拿到文本串的一个字符,那么kmp算法就可以处理基于流数据的单模匹配问题。因为kmp一开始没有必要存储文本串的全量信息。
想象一种问题场景:两台计算机之间的信息通讯,A机器每次会给B机器传输一个字符,假设B机器就是用来过滤敏感词的。但是A机器发给B机器的文章到底有多长,不知道,究竟什么时候结束也不知道。类似这种场景就是流数据。我们需要在通讯的过程中过滤出来敏感词,敏感词就是模式串。
Sunday算法:
黄金对齐点位:

当模式串失配的情况发生了,模式串整体向后平移一位,此时最后一位d对应到e,可知这个e一定会出现在模式串中,于是从后向前查找,找到e最后出现的位置。将模式串在e这个位置和母串对齐,对齐之后,再重头开始比较:

此时发现第一位又失配了,于是模式串再整体向后移动一位,最后一位对应到a,可知a一定出现在模式串当中,于是从后向前找到最后一个a出现的位置,并与母串对齐,再重头进行匹配。

此时,发现能匹配完全,算法结束。
sunday算法要求我们预处理的信息:每一种字符在模式串中最后出现的位置。
如果文本串中,出现了模式串中根本没出现过的字符,那么模式串应该向后移动整个模式串的长度。
sunday算法适合处理在一篇文章中,查找一个单词。如果每次都向后这样子跳啊,sunday算法的时间复杂度最好能到达O(n/m),m是单词的长度,n是文章的长度。
所以sunday算法在实际场景中是远优于kmp,远优于暴力匹配的。
代码实现:
#include
#include
using namespace std;
#define TEST(func, s1, s2) { \
printf("%s(\"%s\", \"%s\") = %d\n", #func, s1, s2, func(s1, s2)); \
}
int sunday(const char *text, const char *pattern) {
#define BASE 256
int n = strlen(text), m, last_pos[BASE];
for (int i = 0; i < 256; i++) last_pos[i] = -1;
for (m = 0; pattern[m]; ++m) last_pos[pattern[m]] = m; // 当前字符出现在第n位
for (int i = 0; i + m <= n; i += (m - last_pos[text[i + m]])) {
int flag = 1;
for (int j = 0; pattern[j]; ++j) {
if (text[i + j] == pattern[j]) continue;
flag = 0;
break;
}
if (flag) return i;
}
return -1;
}
int main() {
char s1[100], s2[100];
while (cin >> s1 >> s2) {
TEST(sunday, s1, s2);
}
return 0;
} shift-and算法:
首先,将模式串处理成类似下边的二进制数据:

怎么解释这段信息呢?以第一个a字符为例:a字符出现在0和3两个位置。那么d[a]转换成二进制以后,左边是低位,右边是高位,就等于十进制数 9。
同理可以算得d[c] = 4、d[d] = 32、d[e] = 18
第二步:设定一个P值,表示以文本串当前位置为最后一个字符,能够匹配成功模式串的前几位。
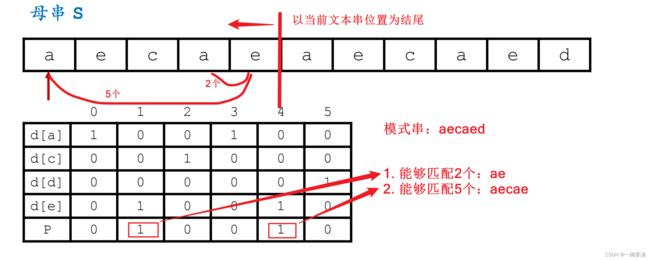
P值的转移:当新输入一个字符s[i]的时候,加入P原来表示能够匹配第1位和第4位,那么P<<1就表示,能够匹配第2位和第5位,当然新进来这个字符也有可能匹配成功前1位,所以要或上1。
当然最后是否能够匹配成功还是要&上d[s[i]]
代码实现:
#include
#include
using namespace std;
#define TEST(func, s1, s2) { \
printf("%s(\"%s\", \"%s\") = %d\n", #func, s1, s2, func(s1, s2)); \
}
int shift_and(const char *text, const char *pattern) {
int code[256] = {0};
int n = 0;
for (n = 0; pattern[n]; ++n) code[pattern[n]] |= (1 << n);
int p = 0;
for (int i = 0; text[i]; i++) {
p = (p << 1 | 1) & code[text[i]]; // p状态转移
if (p & (1 << (n - 1))) return i - n + 1;
}
return -1;
}
int main() {
char s1[100], s2[100];
while (cin >> s1 >> s2) {
TEST(shift_and, s1, s2);
}
return 0;
} 时间复杂度为O(n)
shift-and算法适用于下面这个问题场景:

每个位置允许出现多个字符,可以由表中的信息体现出来。
并且shift-and算法也能诠释自动机的思想:每进来一个字符,P的状态就转变一下。所以shift-and算法也能处理流数据单模匹配问题,并且实际中比kmp更加高效。
int GetNextP(char ch, int *code, int p) {
return (p << 1 | 1) & code[ch]; // p状态转移
}
int shift_and(const char *text, const char *pattern) {
int code[256] = {0};
int n = 0;
for (n = 0; pattern[n]; ++n) code[pattern[n]] |= (1 << n);
int p = 0;
for (int i = 0; text[i]; i++) {
p = GetNextP(text[i], code, p);
if (p & (1 << (n - 1))) return i - n + 1;
}
return -1;
}自动机的思想对于算法思维的培养是至关重要的,是一大类的算法思维,因为自动机的本质,就是图灵机,图灵机的本质,就是当代计算机的运行原理。故自动机囊括了所有程序运行的本质原理,这意味着自动机的思想对于我们写程序来说,它的意义远高于我们对于排序算法的学习,远高于对于搜索算法的学习,远高于我们对于任何一种其他算法的学习,这就是自动机思想对于专业的编程人员、对于编码思维锻炼的重要意义所在。