任务流调度工具AirFlow
知识点01:课程目标
-
AirFlow介绍【了解】
- 功能、特点
- 架构角色、安装部署
-
AirFlow使用【掌握】
- 核心:调度脚本【Python | Shell】
- 定时调度:Linux Crontab表达式
- 邮件告警:配置
-
回顾Spark核心概念
-
存储:安全性、高效性
-
计算:使用【API:类、方法】、原理【资源使用】
-
零碎:采集、调度、选举、可视化
-
Spark概念
- 分布式资源:Master | ResourceManager、Worker | NodeManager
- 分布式程序:Driver 、Executor、Task
- 原理性概念:Job、DAG、Stage
-
知识点02:任务流调度回顾
-
目标:回顾任务流调度的需求及常用工具
-
路径
- step1:需求
- step2:常用工具
-
实施
-
需求
-
相同的业务线,有不同的需求会有多个程序来实现,这多个程序共同完成的需求,组合在一起就是工作流或者叫做任务流
-
基于工作流来实现任务流的自动化运行
-

-
需求1:基于时间的任务运行
- job1和job2是每天0点以后自动运行
-
需求2:基于运行依赖关系的任务运行
- job3必须等待job1运行成功才能运行
- job5必须等待job3和job4都运行成功才能运行
-
调度类型
- 定时调度:基于某种时间的规律进行调度运行
- 调度工作流
- 依赖调度:基于某种依赖关系进行调度运行
- 工作流中的程序的依赖关系
- 定时调度:基于某种时间的规律进行调度运行
-
常用工具
-
Oozie:Cloudera公司研发,功能强大,依赖于MR实现分布式,集成Hue开发使用非常方便
-
传统开发:xml文件
<workflow> <start to="action1"> start> <action name='action1'> <shell> shell> <ok to='action2'> <kill to='killAction'> action> <action name='action2'> <shell> shell> <ok to='action3'> <kill to='killAction'> action> …… workflow> -
现在开发:Hue通过图形化界面自主编辑DAG
-
场景:CDH大数据平台
-
-
Azkaban:LinkedIn公司研发,界面友好、插件支持丰富、自主分布式,可以使用properties或者JSON开发
-
开发properties文件,压缩成zip压缩包
name='appname2' type=command dependencies=appname1 comman='sh xxxx.sh' -
上传到web界面中
-
场景:Apache平台
-
-
AirFlow:Airbnb公司研发,自主分布式、Python语言开发和交互,应用场景更加丰富
-
开发Python文件
# step1:导包 # step2:函数调用 -
提交运行
-
场景:整个数据平台全部基于Python开发
-
-
DolphinScheduler:易观公司研发,国产开源产品,高可靠高扩展、简单易用
-
-
-
小结
- 回顾任务流调度的需求及常用工具
知识点03:AirFlow的介绍
-
目标:了解AirFlow的功能特点及应用场景
-
路径
- step1:背景
- step2:设计
- step3:功能
- step4:特点
- step5:应用
-
实施
-
起源
- 2014年,Airbnb创造了一套工作流调度系统:Airflow,用来替他们完成业务中复杂的ETL处理。从清洗,到拼接,只用设置好一套Airflow的流程图。
- 2016年开源到了Apache基金会。
- 2019年成为了Apache基金会的顶级项目:http://airflow.apache.org/。
-
设计:利用Python的可移植性和通用性,快速的构建的任务流调度平台
-
功能:基于Python实现依赖调度、定时调度
-
特点
- 分布式任务调度:允许一个工作流的Task在多台worker上同时执行
- DAG任务依赖:以有向无环图的方式构建任务依赖关系
- Task原子性:工作流上每个task都是原子可重试的,一个工作流某个环节的task失败可自动或手动进行重试
- 自主定制性:可以基于代码构造任何你需要调度的任务或者处理工具
- 优点:灵活性好
- 缺点:开发复杂
-
应用
- 基于Python开发背景下的系统建议使用
-
小结
- 了解AirFlow的功能特点及应用场景
知识点04:AirFlow的部署启动
-
目标:了解AirFlow的工具部署及管理
-
路径
- step1:安装部署
- step2:启动测试
- step3:关闭
-
实施
-
安装部署
- 自行安装:《参考附录一》
- 放弃安装:请将虚拟机快照恢复到《AirFlow安装完成》
-
启动测试
-
删除记录:第二次启动再做
rm -f /root/airflow/airflow-* -
启动Redis:消息队列:
nohup /opt/redis-4.0.9/src/redis-server /opt/redis-4.0.9/src/redis.conf > output.log 2>&1 & ps -ef | grep redis
-
-

- 启动AirFlow
```shell
# 以后台进程方式,启动服务
airflow webserver -D
airflow scheduler -D
airflow celery flower -D
airflow celery worker -D
```
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vkTwgPaD-1672110712263)(Day1015_任务流调度工具AirFlow.assets/image-20211015102430125.png)]
- 测试网络端口
- Airflow Web UI:`node1:8085`
- 用户名密码:admin
- Celery Web UI:`node1:5555`
-
小结
- 了解AirFlow的工具部署及管理
知识点05:AirFlow的架构组件
-
目标:了解AirFlow的架构组件
-
路径
- step1:架构
- step2:组件
-
实施
- 架构

- Client:开发AirFlow调度的程序的客户端,用于开发AirFlow的Python程序
- Master:分布式架构中的主节点,负责运行WebServer和Scheduler
- Worker:负责运行Execution执行提交的工作流中的Task
- 组件

```
A scheduler, which handles both triggering scheduled workflows, and submitting Tasks to the executor to run.
An executor, which handles running tasks. In the default Airflow installation, this runs everything inside the scheduler, but most production-suitable executors actually push task execution out to workers.
A webserver, which presents a handy user interface to inspect, trigger and debug the behaviour of DAGs and tasks.
A folder of DAG files, read by the scheduler and executor (and any workers the executor has)
A metadata database, used by the scheduler, executor and webserver to store state.
```
- WebServer:提供交互界面和监控,让开发者调试和监控所有Task的运行
- Scheduler:负责解析和调度Task任务提交到Execution中运行
- Executor:执行组件,负责运行Scheduler分配的Task,运行在Worker中
- DAG Directory:DAG程序的目录,将自己开发的程序放入这个目录,AirFlow的WebServer和Scheduler会自动读取
- airflow将所有程序放在一个目录中
- 自动检测这个目录有么有新的程序
- MetaData DataBase:AirFlow的元数据存储数据库,记录所有DAG程序的信息
-
小结
- 了解AirFlow的架构组件
知识点06:AirFlow的开发规则
-
目标:掌握AirFlow的开发规则
-
路径
- step1:开发Python调度程序
- step2:提交Python调度程序
-
实施
-
官方文档
- 概念:http://airflow.apache.org/docs/apache-airflow/stable/concepts/index.html
-
示例:http://airflow.apache.org/docs/apache-airflow/stable/tutorial.html
-
开发Python调度程序
-
开发一个Python程序,程序文件中需要包含以下几个部分
-
注意:该文件的运行不支持utf8编码,不能写中文
-
step1:导包
# 必选:导入airflow的DAG工作流 from airflow import DAG # 必选:导入具体的TaskOperator类型 from airflow.operators.bash import BashOperator # 可选:导入定时工具的包 from airflow.utils.dates import days_ago
-

-
step2:定义DAG及配置
# 当前工作流的基础配置 default_args = { # 当前工作流的所有者 'owner': 'airflow', # 当前工作流的邮件接受者邮箱 'email': ['[email protected]'], # 工作流失败是否发送邮件告警 'email_on_failure': True, # 工作流重试是否发送邮件告警 'email_on_retry': True, # 重试次数 'retries': 2, # 重试间隔时间 'retry_delay': timedelta(minutes=1), } # 定义当前工作流的DAG对象 dagName = DAG( # 当前工作流的名称,唯一id 'airflow_name', # 使用的参数配置 default_args=default_args, # 当前工作流的描述 description='first airflow task DAG', # 当前工作流的调度周期:定时调度【可选】 schedule_interval=timedelta(days=1), # 工作流开始调度的时间 start_date=days_ago(1), # 当前工作流属于哪个组 tags=['itcast_bash'], )- 构建一个DAG工作流的实例和配置
-
step3:定义Tasks
-
Task类型:http://airflow.apache.org/docs/apache-airflow/stable/concepts/operators.html
-
常用
BashOperator- executes a bash command- 执行Linux命令
PythonOperator- calls an arbitrary Python function- 执行Python代码
EmailOperator- sends an email- 发送邮件的
-
其他
MySqlOperatorPostgresOperatorMsSqlOperatorOracleOperatorJdbcOperatorDockerOperatorHiveOperatorPrestoToMySqlOperator- ……
-
BashOperator:定义一个Shell命令的Task
# 导入BashOperator from airflow.operators.bash import BashOperator # 定义一个Task的对象 t1 = BashOperator( # 指定唯一的Task的名称 task_id='first_bashoperator_task', # 指定具体要执行的Linux命令 bash_command='echo "hello airflow"', # 指定属于哪个DAG对象 dag=dagName ) -
PythonOperator:定义一个Python代码的Task
# 导入PythonOperator from airflow.operators.python import PythonOperator # 定义需要执行的代码逻辑 def sayHello(): print("this is a programe") #定义一个Task对象 t2 = PythonOperator( # 指定唯一的Task的名称 task_id='first_pyoperator_task', # 指定调用哪个Python函数 python_callable=sayHello, # 指定属于哪个DAG对象 dag=dagName )
-
-
step4:运行Task并指定依赖关系
-
定义Task
Task1:runme_0 Task2:runme_1 Task3:runme_2 Task4:run_after_loop Task5:also_run_this Task6:this_will_skip Task7:run_this_last -
需求
- Task1、Task2、Task3并行运行,结束以后运行Task4
- Task4、Task5、Task6并行运行,结束以后运行Task7
-
-
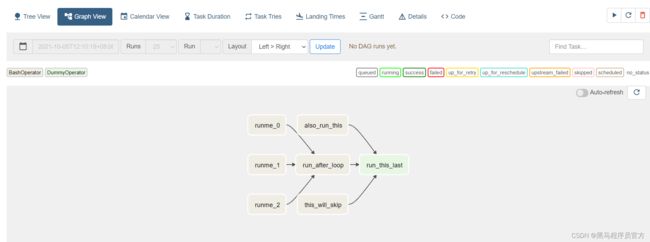
- 代码
```python
task1 >> task4
task2 >> task4
task3 >> task4
task4 >> task7
task5 >> task7
task6 >> task7
```
- 如果只有一个Task,只要直接写上Task对象名称即可
```
task1
```
-
提交Python调度程序
-
哪种提交都需要等待一段时间
-
自动提交:需要等待自动检测
- 将开发好的程序放入AirFlow的DAG Directory目录中
- 默认路径为:/root/airflow/dags
-
手动提交:手动运行文件让airflow监听加载
python xxxx.py -
调度状态
-
No status (scheduler created empty task instance):调度任务已创建,还未产生任务实例
-
Scheduled (scheduler determined task instance needs to run):调度任务已生成任务实例,待运行
-
Queued (scheduler sent task to executor to run on the queue):调度任务开始在executor执行前,在队列中
-
Running (worker picked up a task and is now running it):任务在worker节点上执行中
-
Success (task completed):任务执行成功完成
-
-
-
小结
- 掌握AirFlow的开发规则
知识点07:Shell调度测试
-
目标:实现Shell命令的调度测试
-
实施
-
需求:使用BashOperator调度执行一条Linux命令
-
代码
-
创建
# 默认的Airflow自动检测工作流程序的文件的目录 mkdir -p /root/airflow/dags cd /root/airflow/dags vim first_bash_operator.py -
开发
# import from airflow import DAG from airflow.operators.bash import BashOperator from airflow.utils.dates import days_ago from datetime import timedelta # define args default_args = { 'owner': 'airflow', 'email': ['[email protected]'], 'email_on_failure': True, 'email_on_retry': True, 'retries': 1, 'retry_delay': timedelta(minutes=1), } # define dag dag = DAG( 'first_airflow_dag', default_args=default_args, description='first airflow task DAG', schedule_interval=timedelta(days=1), start_date=days_ago(1), tags=['itcast_bash'], ) # define task1 run_bash_task = BashOperator( task_id='first_bashoperator_task', bash_command='echo "hello airflow"', dag=dag, ) # run the task run_bash_task-
工作中使用bashOperator
bash_command='sh xxxx.sh' -
xxxx.sh:根据需求
- Linux命令
- hive -f
- spark-sql -f
- spark-submit python | jar
-
-
-
提交
python first_bash_operator.py -
查看
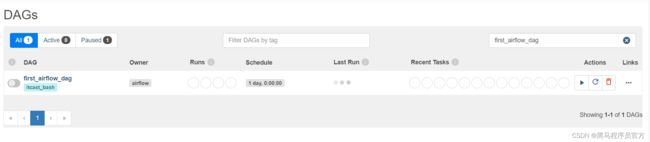
-
执行
-
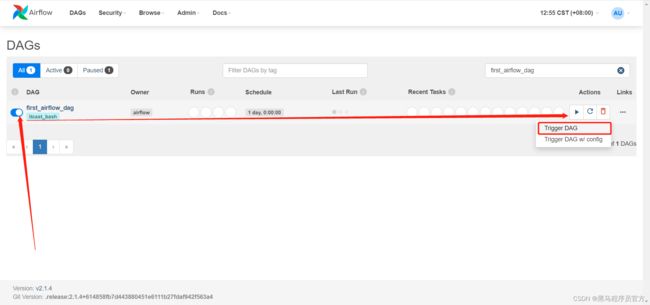
-
小结
- 实现Shell命令的调度测试
知识点08:依赖调度测试
-
目标:实现AirFlow的依赖调度测试
-
实施
-
需求:使用BashOperator调度执行多个Task,并构建依赖关系
-
代码
-
创建
cd /root/airflow/dags vim second_bash_operator.py -
开发
# import from datetime import timedelta from airflow import DAG from airflow.operators.bash import BashOperator from airflow.utils.dates import days_ago # define args default_args = { 'owner': 'airflow', 'email': ['[email protected]'], 'email_on_failure': True, 'email_on_retry': True, 'retries': 1, 'retry_delay': timedelta(minutes=1), } # define dag dag = DAG( 'second_airflow_dag', default_args=default_args, description='first airflow task DAG', schedule_interval=timedelta(days=1), start_date=days_ago(1), tags=['itcast_bash'], ) # define task1 say_hello_task = BashOperator( task_id='say_hello_task', bash_command='echo "start task"', dag=dag, ) # define task2 print_date_format_task2 = BashOperator( task_id='print_date_format_task2', bash_command='date +"%F %T"', dag=dag, ) # define task3 print_date_format_task3 = BashOperator( task_id='print_date_format_task3', bash_command='date +"%F %T"', dag=dag, ) # define task4 end_task4 = BashOperator( task_id='end_task', bash_command='echo "end task"', dag=dag, ) say_hello_task >> [print_date_format_task2,print_date_format_task3] >> end_task4
-
-
提交
python second_bash_operator.py -
查看
-

-
小结
- 实现AirFlow的依赖调度测试
知识点09:Python调度测试
-
目标:实现Python代码的调度测试
-
实施
-
需求:调度Python代码Task的运行
-
代码
-
创建
cd /root/airflow/dags vim python_etl_airflow.py -
开发
# import package from airflow import DAG from airflow.operators.python import PythonOperator from airflow.utils.dates import days_ago import json # define args default_args = { 'owner': 'airflow', } # define the dag with DAG( 'python_etl_dag', default_args=default_args, description='DATA ETL DAG', schedule_interval=None, start_date=days_ago(2), tags=['itcast'], ) as dag: # function1 def extract(**kwargs): ti = kwargs['ti'] data_string = '{"1001": 301.27, "1002": 433.21, "1003": 502.22, "1004": 606.65, "1005": 777.03}' ti.xcom_push('order_data', data_string) # function2 def transform(**kwargs): ti = kwargs['ti'] extract_data_string = ti.xcom_pull(task_ids='extract', key='order_data') order_data = json.loads(extract_data_string) total_order_value = 0 for value in order_data.values(): total_order_value += value total_value = {"total_order_value": total_order_value} total_value_json_string = json.dumps(total_value) ti.xcom_push('total_order_value', total_value_json_string) # function3 def load(**kwargs): ti = kwargs['ti'] total_value_string = ti.xcom_pull(task_ids='transform', key='total_order_value') total_order_value = json.loads(total_value_string) print(total_order_value) # task1 extract_task = PythonOperator( task_id='extract', python_callable=extract, ) extract_task.doc_md = """\ #### Extract task A simple Extract task to get data ready for the rest of the data pipeline. In this case, getting data is simulated by reading from a hardcoded JSON string. This data is then put into xcom, so that it can be processed by the next task. """ # task2 transform_task = PythonOperator( task_id='transform', python_callable=transform, ) transform_task.doc_md = """\ #### Transform task A simple Transform task which takes in the collection of order data from xcom and computes the total order value. This computed value is then put into xcom, so that it can be processed by the next task. """ # task3 load_task = PythonOperator( task_id='load', python_callable=load, ) load_task.doc_md = """\ #### Load task A simple Load task which takes in the result of the Transform task, by reading it from xcom and instead of saving it to end user review, just prints it out. """ # run extract_task >> transform_task >> load_task
-
-
提交
python python_etl_airflow.py -
查看
-
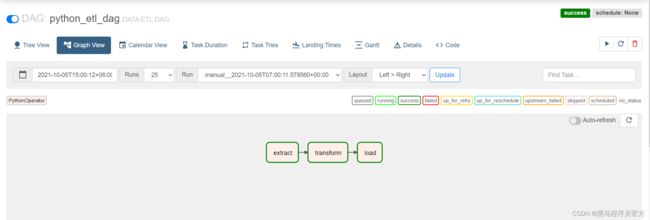
-
小结
- 实现Python代码的调度测试
知识点10:Oracle与MySQL调度方法
-
目标:了解Oracle与MySQL的调度方法
-
实施
-
Oracle调度:参考《oracle任务调度详细操作文档.md》
-
step1:本地安装Oracle客户端
-
step2:安装AirFlow集成Oracle库
-
step3:创建Oracle连接
-
step4:开发测试
query_oracle_task = OracleOperator( task_id = 'oracle_operator_task', sql = 'select * from ciss4.ciss_base_areas', oracle_conn_id = 'oracle-airflow-connection', autocommit = True, dag=dag )
-
-
MySQL调度:《MySQL任务调度详细操作文档.md》
-
step1:本地安装MySQL客户端
-
step2:安装AirFlow集成MySQL库
-
step3:创建MySQL连接
-
step4:开发测试
-
方式一:指定SQL语句
query_table_mysql_task = MySqlOperator( task_id='query_table_mysql', mysql_conn_id='mysql_airflow_connection', sql=r"""select * from test.test_airflow_mysql_task;""", dag=dag ) -
方式二:指定SQL文件
query_table_mysql_task = MySqlOperator( task_id='query_table_mysql_second', mysql_conn_id='mysql-airflow-connection', sql='test_airflow_mysql_task.sql', dag=dag ) -
方式三:指定变量
insert_sql = r""" INSERT INTO `test`.`test_airflow_mysql_task`(`task_name`) VALUES ( 'test airflow mysql task3'); INSERT INTO `test`.`test_airflow_mysql_task`(`task_name`) VALUES ( 'test airflow mysql task4'); INSERT INTO `test`.`test_airflow_mysql_task`(`task_name`) VALUES ( 'test airflow mysql task5'); """ insert_table_mysql_task = MySqlOperator( task_id='mysql_operator_insert_task', mysql_conn_id='mysql-airflow-connection', sql=insert_sql, dag=dag )
-
-
-
-
小结
- 了解Oracle与MySQL的调度方法
知识点11:大数据组件调度方法
-
目标:了解大数据组件调度方法
-
实施
-
AirFlow支持的类型
- HiveOperator
- PrestoOperator
- SparkSqlOperator
-
需求:Sqoop、MR、Hive、Spark、Flink
-
解决:统一使用BashOperator或者PythonOperator,将对应程序封装在脚本中
-
Sqoop
run_sqoop_task = BashOperator( task_id='sqoop_task', bash_command='sqoop --options-file xxxx.sqoop', dag=dag, ) -
Hive
run_hive_task = BashOperator( task_id='hive_task', bash_command='hive -f xxxx.sql', dag=dag, ) -
Spark
run_spark_task = BashOperator( task_id='spark_task', bash_command='spark-sql -f xxxx.sql', dag=dag, ) -
Flink
run_flink_task = BashOperator( task_id='flink_task', bash_command='flink run /opt/flink-1.12.2/examples/batch/WordCount.jar', dag=dag, )
-
-
-
小结
- 了解大数据组件调度方法
知识点12:定时调度使用
-
目标:掌握定时调度的使用方式
-
实施
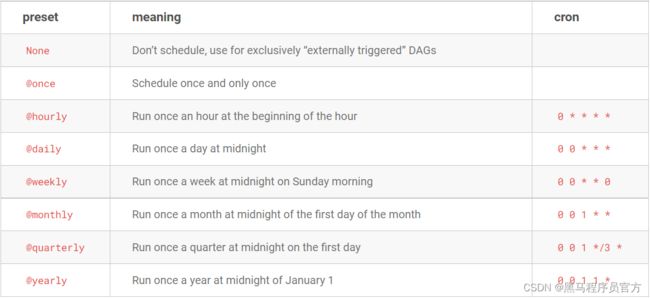
- http://airflow.apache.org/docs/apache-airflow/stable/dag-run.html
-
方式一:内置
with DAG( dag_id='example_branch_operator', default_args=args, start_date=days_ago(2), schedule_interval="@daily", tags=['example', 'example2'], ) as dag: -
方式二:datetime.timedelta对象
timedelta(minutes=1) timedelta(hours=3) timedelta(days=1)with DAG( dag_id='latest_only', schedule_interval=dt.timedelta(hours=4), start_date=days_ago(2), tags=['example2', 'example3'], ) as dag: -
方式三:Crontab表达式
-
与Linux Crontab用法一致
with DAG( dag_id='example_branch_dop_operator_v3', schedule_interval='*/1 * * * *', start_date=days_ago(2), default_args=args, tags=['example'], ) as dag:分钟 小时 日 月 周 00 00 * * * 05 12 1 * * 30 8 * * 4
-
-
小结
- 掌握定时调度的使用方式
知识点13:Airflow常用命令
-
目标:了解AirFlow的常用命令
-
实施
-
列举当前所有的dag
airflow dags list -
暂停某个DAG
airflow dags pause dag_name -
启动某个DAG
airflow dags unpause dag_name -
删除某个DAG
airflow dags delete dag_name -
执行某个DAG
airflow dags trigger dag_name -
查看某个DAG的状态
airflow dags state dag_name -
列举某个DAG的所有Task
airflow tasks list dag_name
-
-
小结
- 了解AirFlow的常用命令
知识点14:邮件告警使用
-
目标:了解AirFlow中如何实现邮件告警
-
路径
- step1:AirFlow配置
- step2:DAG配置
-
实施
-
原理:自动发送邮件的原理:邮件第三方服务
-
发送方账号:配置文件中配置
smtp_user = [email protected] # 秘钥id:需要自己在第三方后台生成 smtp_password = 自己生成的秘钥 # 端口 smtp_port = 25 # 发送邮件的邮箱 smtp_mail_from = [email protected] -
接收方账号:程序中配置
default_args = { 'owner': 'airflow', 'email': ['[email protected]'], 'email_on_failure': True, 'email_on_retry': True, 'retries': 1, 'retry_delay': timedelta(minutes=1), }
-
-
AirFlow配置:airflow.cfg
# 发送邮件的代理服务器地址及认证:每个公司都不一样 smtp_host = smtp.163.com smtp_starttls = True smtp_ssl = False # 发送邮件的账号 smtp_user = [email protected] # 秘钥id:需要自己在第三方后台生成 smtp_password = 自己生成的秘钥 # 端口 smtp_port = 25 # 发送邮件的邮箱 smtp_mail_from = [email protected] # 超时时间 smtp_timeout = 30 # 重试次数 smtp_retry_limit = 5 -
关闭Airflow
# 统一杀掉airflow的相关服务进程命令 ps -ef|egrep 'scheduler|flower|worker|airflow-webserver'|grep -v grep|awk '{print $2}'|xargs kill -9 # 下一次启动之前 rm -f /root/airflow/airflow-* -
程序配置
default_args = { 'email': ['[email protected]'], 'email_on_failure': True, 'email_on_retry': True } -
启动Airflow
airflow webserver -D airflow scheduler -D airflow celery flower -D airflow celery worker -D -
模拟错误
-

-
小结
- 了解AirFlow中如何实现邮件告警
知识点15:一站制造中的调度
-
目标:了解一站制造中调度的实现
-
实施
- ODS层 / DWD层:定时调度:每天00:05开始运行
- dws(11)
- dws耗时1小时
- 从凌晨1点30分开始执行
- dwb(16)
- dwb耗时1.5小时
- 从凌晨3点开始执行
- st(10)
- st耗时1小时
- 从凌晨4点30分开始执行
- dm(1)
- dm耗时0.5小时
- 从凌晨5点30分开始执行
-
小结
- 了解一站制造中调度的实现
知识点16:回顾:Spark核心概念

-
什么是分布式计算?
- 分布式程序:MapReduce、Spark、Flink程序
- 多进程:一个程序由多个进程来共同实现,不同进程可以运行在不同机器上
- 每个进程所负责计算的数据是不一样,都是整体数据的某一个部分
- 自己基于MapReduce或者Spark的API开发的程序:数据处理的逻辑
- 分逻辑
- MR
- ·MapTask进程:分片规则:基于处理的数据做计算
- 判断:文件大小 / 128M > 1.1
- 大于:按照每128M分
- 小于:整体作为1个分片
- 大文件:每128M作为一个分片
- 一个分片就对应一个MapTask
- 判断:文件大小 / 128M > 1.1
- ReduceTask进程:指定
- ·MapTask进程:分片规则:基于处理的数据做计算
- Spark
- Executor:指定
- 分布式资源:YARN、Standalone资源容器
- 将多台机器的物理资源:CPU、内存、磁盘从逻辑上合并为一个整体
- YARN:ResourceManager、NodeManager【8core8GB】
- 每个NM管理每台机器的资源
- RM管理所有的NM
- Standalone:Master、Worker
- 实现统一的硬件资源管理:MR、Flink、Spark on YARN
- 分布式程序:MapReduce、Spark、Flink程序
-
Spark程序的组成结构?
- Application:程序
- 进程:一个Driver、多个Executor
- 运行:多个Job、多个Stage、多个Task
-
什么是Standalone?
- Spark自带的集群资源管理平台
-
为什么要用Spark on YARN?
- 为了实现资源统一化的管理,将所有程序都提交到YARN运行
-
Master和Worker是什么?
- 分布式主从架构:Hadoop、Hbase、Kafka、Spark……
- 主:管理节点:Master
- 接客
- 管理从节点
- 管理所有资源
- 从:计算节点:Worker
- 负责执行主节点分配的任务
- 主:管理节点:Master
- 分布式主从架构:Hadoop、Hbase、Kafka、Spark……
-
Driver和Executer是什么?
-
step1:启动了分布式资源平台
-
step2:开发一个分布式计算程序
sc = SparkContext(conf) # step1:读取数据 inputRdd = sc.textFile(hdfs_path) #step2:转换数据 wcRdd = inputRdd.filter.map.flatMap.reduceByKey #step3:保存结果 wcRdd.foreach sc.stop -
step3:提交分布式程序到分布式资源集群运行
spark-submit xxx.py executor个数和资源 driver资源配置 -
先启动Driver进程
- 申请资源:启动Executor计算进程
- Driver开始解析代码,判断每一句代码是否产生job
-
再启动Executor进程:根据资源配置运行在Worker节点上
- 所有Executor向Driver反向注册,等待Driver分配Task
-
-
Job是怎么产生的?
- 当用到RDD中的数据时候就会触发Job的产生:所有会用到RDD数据的函数称为触发算子
- DAGScheduler组件根据代码为当前的job构建DAG图
-
DAG是怎么生成的?
- 算法:回溯算法:倒推
- DAG构建过程中,将每个算子放入Stage中,如果遇到宽依赖的算子,就构建一个新的Stage
- Stage划分:宽依赖
- 运行Stage:按照Stage编号小的开始运行
- 将每个Stage转换为一个TaskSet:Task集合
-
Task的个数怎么决定?
- 一核CPU = 一个Task = 一个分区
- 一个Stage转换成的TaskSet中有几个Task:由Stage中RDD的最大分区数来决定
-
Spark的算子分为几类?
- 转换:Transformation
- 返回值:RDD
- 为lazy模式,不会触发job的产生
- map、flatMap
- 触发:Action
- 返回值:非RDD
- 触发job的产生
- count、first
- 转换:Transformation
附录一:AirFlow安装
直接在node1上安装
1、安装Python
-
安装依赖
yum -y install zlib zlib-devel bzip2 bzip2-devel ncurses ncurses-devel readline readline-devel openssl openssl-devel openssl-static xz lzma xz-devel sqlite sqlite-devel gdbm gdbm-devel tk tk-devel gcc yum install mysql-devel -y yum install libevent-devel -y -
添加Linux用户及组
# 添加py用户 useradd py # 设置密码 '123456' passwd py # 创建anaconda安装路径 mkdir /anaconda # 赋予权限 chown -R py:py /anaconda -
上传并执行Anaconda安装脚本
cd /anaconda rz chmod u+x Anaconda3-5.3.1-Linux-x86_64.sh sh Anaconda3-5.3.1-Linux-x86_64.sh-
自定义安装路径
Anaconda3 will now be installed into this location: /root/anaconda3 - Press ENTER to confirm the location - Press CTRL-C to abort the installation - Or specify a different location below [/root/anaconda3] >>> /anaconda/anaconda3
-
-
添加到系统环境变量
# 修改环境变量 vi /root/.bash_profile # 添加下面这行 export PATH=/anaconda/anaconda3/bin:$PATH # 刷新 source /root/.bash_profile # 验证 python -V -
配置pip
mkdir ~/.pip touch ~/.pip/pip.conf echo '[global]' >> ~/.pip/pip.conf echo 'trusted-host=mirrors.aliyun.com' >> ~/.pip/pip.conf echo 'index-url=http://mirrors.aliyun.com/pypi/simple/' >> ~/.pip/pip.conf # pip默认是10.x版本,更新pip版本 pip install PyHamcrest==1.9.0 pip install --upgrade pip # 查看pip版本 pip -V
2、安装AirFlow
-
安装
pip install --ignore-installed PyYAML pip install apache-airflow[celery] pip install apache-airflow[redis] pip install apache-airflow[mysql] pip install flower pip install celery -
验证
airflow -h ll /root/airflow
3、安装Redis
-
下载安装
wget https://download.redis.io/releases/redis-4.0.9.tar.gz tar zxvf redis-4.0.9.tar.gz -C /opt cd /opt/redis-4.0.9 make -
启动
cp redis.conf src/ cd src nohup /opt/redis-4.0.9/src/redis-server redis.conf > output.log 2>&1 & -
验证
ps -ef | grep redis
4、配置启动AirFlow
-
修改配置文件:airflow.cfg
[core] #18行:时区 default_timezone = Asia/Shanghai #24行:运行模式 # SequentialExecutor是单进程顺序执行任务,默认执行器,通常只用于测试 # LocalExecutor是多进程本地执行任务使用的 # CeleryExecutor是分布式调度使用(可以单机),生产环境常用 # DaskExecutor则用于动态任务调度,常用于数据分析 executor = CeleryExecutor #30行:修改元数据使用mysql数据库,默认使用sqlite sql_alchemy_conn = mysql://airflow:airflow@localhost/airflow [webserver] #468行:web ui地址和端口 base_url = http://localhost:8085 #474行 default_ui_timezone = Asia/Shanghai #480行 web_server_port = 8085 [celery] #735行 broker_url = redis://localhost:6379/0 #736 celery_result_backend = redis://localhost:6379/0 #743 result_backend = db+mysql://airflow:airflow@localhost:3306/airflow -
初始化元数据数据库
-
进入mysql
mysql -uroot -p set global explicit_defaults_for_timestamp =1; exit -
初始化
airflow db init
-
-
配置Web访问
airflow users create --lastname user --firstname admin --username admin --email [email protected] --role Admin --password admin -
启动
# 以后台进程方式,启动服务 airflow webserver -D airflow scheduler -D airflow celery flower -D airflow celery worker -D -
关闭【不用执行】
# 统一杀掉airflow的相关服务进程命令 ps -ef|egrep 'scheduler|flower|worker|airflow-webserver'|grep -v grep|awk '{print $2}'|xargs kill -9 # 下一次启动之前 rm -f /root/airflow/airflow-*
5、验证AirFlow
- Airflow Web UI:
node1:8085

- Airflow Celery Web:
node1:5555

tor是单进程顺序执行任务,默认执行器,通常只用于测试
LocalExecutor是多进程本地执行任务使用的
CeleryExecutor是分布式调度使用(可以单机),生产环境常用
DaskExecutor则用于动态任务调度,常用于数据分析
executor = CeleryExecutor
#30行:修改元数据使用mysql数据库,默认使用sqlite
sql_alchemy_conn = mysql://airflow:airflow@localhost/airflow
[webserver]
#468行:web ui地址和端口
base_url = http://localhost:8085
#474行
default_ui_timezone = Asia/Shanghai
#480行
web_server_port = 8085
[celery]
#735行
broker_url = redis://localhost:6379/0
#736
celery_result_backend = redis://localhost:6379/0
#743
result_backend = db+mysql://airflow:airflow@localhost:3306/airflow
- 初始化元数据数据库
- 进入mysql
```
mysql -uroot -p
set global explicit_defaults_for_timestamp =1;
exit
```
- 初始化
```
airflow db init
```
- 配置Web访问
```shell
airflow users create --lastname user --firstname admin --username admin --email [email protected] --role Admin --password admin
-
启动
# 以后台进程方式,启动服务 airflow webserver -D airflow scheduler -D airflow celery flower -D airflow celery worker -D -
关闭【不用执行】
# 统一杀掉airflow的相关服务进程命令 ps -ef|egrep 'scheduler|flower|worker|airflow-webserver'|grep -v grep|awk '{print $2}'|xargs kill -9 # 下一次启动之前 rm -f /root/airflow/airflow-*
5、验证AirFlow
- Airflow Web UI:
node1:8085