分库分表之sharding-jdbc
教学视频:https://edu.csdn.net/course/detail/26238/325885
一,简介
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
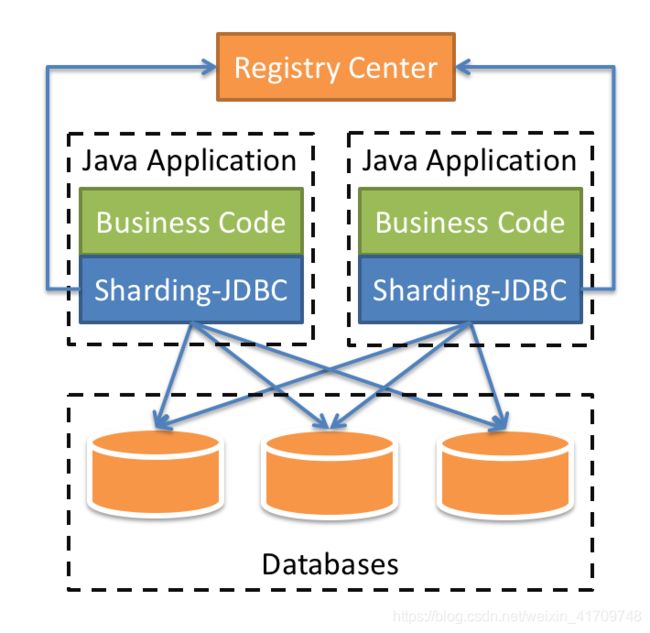
核心概念
1.SQL
逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
真实表
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
数据节点
数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。
绑定表
指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果SQL为
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
其中t_order在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order的条件。故绑定表之间的分区键要完全相同。
2.分片
分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
分片算法
通过分片算法将数据分片,支持通过=、>=、<=、>、<、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
- 精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
- 范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND、>、<、>=、<=进行分片的场景。需要配合StandardShardingStrategy使用。
- 复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
- Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
- 标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND, >, <, >=, <=分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
- 复合分片策略
对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
- 行表达式分片策略
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
- Hint分片策略
对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。
- 不分片策略
对应NoneShardingStrategy。不分片的策略。
二,项目中的应用(SpringBoot)
1.添加依赖
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.0.0-RC1version>
2.配置文件
1.yml(官方文档)
dataSources:
ds0: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds0
username: root
password:
ds1: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds1
username: root
password:
#分片规则
shardingRule:
tables:
t_order:
actualDataNodes: ds${0..1}.t_order${0..1}
databaseStrategy:#分库
inline:
shardingColumn: user_id
algorithmExpression: ds${user_id % 2}
tableStrategy: #分表
inline:
shardingColumn: order_id
algorithmExpression: t_order${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_id
t_order_item:
actualDataNodes: ds${0..1}.t_order_item${0..1}
databaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds${user_id % 2}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_item${order_id % 2}
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_config
defaultDataSourceName: ds0
defaultTableStrategy:
none:
defaultKeyGenerator:
type: SNOWFLAKE
column: order_id
props:
sql.show: true
主键不要设置自增,使用SNOWFLAKE(雪花算法)
2.properties(实际案例)
server.port=8080
#指定mybatis信息
mybatis.mapper-locations=classpath:mapper/*.xml
mybatis.type-aliases-package=com.example.demo.entity
spring.shardingsphere.datasource.names=ds
spring.shardingsphere.datasource.ds.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds.url=jdbc:mysql://localhost:3306/mall?serverTimezone=GMT%2B8&useSSL=false
spring.shardingsphere.datasource.ds.username=root
spring.shardingsphere.datasource.ds.password=root
# 节点
spring.shardingsphere.sharding.tables.user.actual-data-nodes = ds.user_$->{0..2}
# 分表字段id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column = id
# 分表策略 根据id取模,确定数据最终落在那个表中
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression = user_$->{id % 3}
spring.shardingsphere.sharding.tables.user.key-generator.column=id
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
#record表分表策略
spring.shardingsphere.sharding.tables.record.actual-data-nodes = ds.record_$->{0..1}
spring.shardingsphere.sharding.tables.record.table-strategy.inline.sharding-column = id
spring.shardingsphere.sharding.tables.record.table-strategy.inline.algorithm-expression = record_$->{id % 2}
spring.shardingsphere.sharding.tables.record.key-generator.column=id
spring.shardingsphere.sharding.tables.record.key-generator.type=SNOWFLAKE
#order表分表策略
spring.shardingsphere.sharding.tables.order.actual-data-nodes = ds.order_$->{0..1}
spring.shardingsphere.sharding.tables.order.table-strategy.inline.sharding-column = id
spring.shardingsphere.sharding.tables.order.table-strategy.inline.algorithm-expression = order_$->{id % 2}
spring.shardingsphere.sharding.tables.order.key-generator.column=id
spring.shardingsphere.sharding.tables.order.key-generator.type=SNOWFLAKE
spring.main.allow-bean-definition-overriding=true
spring.shardingsphere.props.sql.show = true
spring.main.allow-bean-definition-overriding=true要加上,不要会报错
3.单表操作
dao层
package com.example.demo.dao;
import com.example.demo.entity.User;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface UserDao {
void insert(User user);
User select(int id);
}
<mapper namespace="com.example.demo.dao.UserDao">
<insert id="insert" parameterType="com.example.demo.entity.User">
insert into user
(name,sex,age)
values (#{name},#{sex},#{age})
insert>
<select id="select" resultType="com.example.demo.entity.User">
select * from user where id=#{id}
select>
mapper>
controller层
package com.example.demo.controller;
import com.example.demo.entity.User;
import com.example.demo.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class UserController {
@Autowired
private UserService userService;
@RequestMapping("/add")
public void addUser(){
for (int i =0 ; i< 10 ; i++){
User user=new User();
user.setName("tom"+i);
user.setSex("man");
user.setAge(20+i);
userService.add(user);
}
@RequestMapping("/find")
public User find(int id){
User user = userService.find(id);
return user;
}
}
}
测试添加数据localhost:8080/add后
user_0表中插入了数据

user_1中插入了数据

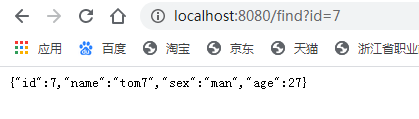
查询接口localhost:8080/find?id=7
4.分表与无分表的表之间的查询
表结构
DROP TABLE IF EXISTS `stu`;
CREATE TABLE `stu` (
`id` int(20) NOT NULL,
`name` varchar(20) NOT NULL,
`age` int(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `record_0` (
`id` bigint(20) NOT NULL,
`sid` int(20) NOT NULL,
`subject` varchar(20) NOT NULL,
`score` int(20) NOT NULL,
PRIMARY KEY (`id`),
KEY `stu_id` (`sid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `record_1` (
`id` bigint(20) NOT NULL,
`sid` int(20) NOT NULL,
`subject` varchar(20) NOT NULL,
`score` int(20) NOT NULL,
PRIMARY KEY (`id`),
KEY `stu_id` (`sid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
其中record表为逻辑表,下面有两个物理表record_0,record_1
dao层
@Mapper
public interface RecordDao {
List<Record> find(String name);
void insert(Record record);
}
<mapper namespace="com.example.demo.dao.RecordDao">
<select id="find" resultType="com.example.demo.entity.Record">
select r.id,r.sid,r.subject,r.score from record r left join stu s on r.sid=s.id where s.name=#{name}
select>
<insert id="insert" parameterType="com.example.demo.entity.Record">
insert into record (sid,subject,score) values (#{sid},#{subject},#{score})
insert>
mapper>
controller层
@RestController
@RequestMapping("/record")
public class RecordController {
@Autowired
private RecordService recordService;
@RequestMapping("/add")
public void add(){
for (int i =1 ; i< 10 ; i++){
Record record=new Record();
record.setSid(i);
record.setSubject("a"+i);
record.setScore(80+i);
recordService.add(record);
}
}
@RequestMapping("/find")
public List<Record> find(String name){
List<Record> recordList = recordService.find(name);
System.out.println(recordList.toString());
return recordList;
}
}
关联条件为record.sid=stu.id,同过查询条件stu.name,查到对应的record表中的数据
调用接口:http://localhost:8080/record/find?name=jack4
[{"id":437010138914619392,"sid":4,"subject":"a5","score":84},{"id":437010372189224960,"sid":4,"subject":"a4","score":84}]
5.多表查询(两个不同分表关键字的表之间的查询)
数据结构
CREATE TABLE `user_0` (
`id` bigint(20) NOT NULL,
`name` varchar(20) NOT NULL,
`sex` varchar(20) NOT NULL,
`age` int(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `user_1` (
`id` bigint(20) NOT NULL,
`name` varchar(20) NOT NULL,
`sex` varchar(20) NOT NULL,
`age` int(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `user_2` (
`id` bigint(20) NOT NULL,
`name` varchar(20) NOT NULL,
`sex` varchar(20) NOT NULL,
`age` int(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `order_0` (
`id` bigint(20) NOT NULL,
`uid` bigint(20) NOT NULL,
`username` varchar(20) NOT NULL,
`goodsname` varchar(20) NOT NULL,
`num` int(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `order_1` (
`id` bigint(20) NOT NULL,
`uid` bigint(20) NOT NULL,
`username` varchar(20) NOT NULL,
`goodsname` varchar(20) NOT NULL,
`num` int(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
逻辑表user下面有三张物理表user_0,user_0,user1,order表下面有两张物理表order_0,order_1,分别用了两张表的主键id作为分表的列名,并且分片的规则也不一样
dao层
@Mapper
public interface OrderDao {
void insert(Order order);
List<Order> find(int age);
}
<mapper namespace="com.example.demo.dao.OrderDao">
<insert id="insert" parameterType="com.example.demo.entity.Order">
insert into order (username,goodsname,num) values (#{username},#{goodsname},#{num})
insert>
<select id="find" resultType="com.example.demo.entity.Order">
-- 这种写法会报错
-- select o.id,o.uid,o.username,o.goodsname,o.num from order o left join on user u where o.uid=u.id and u.age=#{age}
-- 修改用这种写法
select o.id,o.uid,o.username,o.goodsname,o.num from order o, user u where o.uid=u.id and u.age=#{age}
select>
mapper>
这里没有用跟上面单表与多表查询的left join查询,因为那个表的分表的字段(table-strategy.inline.sharding-column)不一样,子查询也无法查到,因为shadrding-jdbc在这里无法解析子查询中的逻辑表
官方文档上的解释为:源码ParsingSQLRouter类的方法tableNames.iterator().next() 获取集合第一个表元素为order,可以使用分片键,优化查询为一次,否则不使用分片键生成2个sql查询2次
解决办法:
1.用select o.id,o.uid,o.username,o.goodsname,o.num from order o, user u where o.uid=u.id and u.age=#{age}
2.在配置文件中的spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column中的值配成一致的,而不是用各自表的主键去配置
controller层
@RequestMapping("/order")
public class OrderController {
@Autowired
private OrderService orderService;
@RequestMapping("/add")
public void add(){
for (int i =0 ; i< 10 ; i++){
Order order=new Order();
order.setUsername("tom"+i);
order.setGoodsname("goods"+i);
order.setNum(i+1);
orderService.insert(order);
}
}
@RequestMapping("/find")
public List<Order> find(int age){
List<Order> list = orderService.find(age);
return list;
}
}
同过user表中的age去查询order表中的详细信息
调用http://localhost:8080/order/find?age=21
[{"id":437253867281842176,"uid":437257314118926336,"username":"tom1","goodsname":"goods1","num":2}]
我们看到控制台中:
Actual SQL: ds ::: select o.id,o.uid,o.username,o.goodsname,o.num from order_1 o, user_2 u where o.uid=u.id and u.age=? ::: [21]
2020-02-20 19:31:50.615 INFO 26008 --- [nio-8080-exec-1] ShardingSphere-SQL : Actual SQL: ds ::: select o.id,o.uid,o.username,o.goodsname,o.num from order_1 o, user_1 u where o.uid=u.id and u.age=? ::: [21]
2020-02-20 19:31:50.615 INFO 26008 --- [nio-8080-exec-1] ShardingSphere-SQL : Actual SQL: ds ::: select o.id,o.uid,o.username,o.goodsname,o.num from order_1 o, user_0 u where o.uid=u.id and u.age=? ::: [21]
2020-02-20 19:31:50.615 INFO 26008 --- [nio-8080-exec-1] ShardingSphere-SQL : Actual SQL: ds ::: select o.id,o.uid,o.username,o.goodsname,o.num from order_0 o, user_2 u where o.uid=u.id and u.age=? ::: [21]
2020-02-20 19:31:50.615 INFO 26008 --- [nio-8080-exec-1] ShardingSphere-SQL : Actual SQL: ds ::: select o.id,o.uid,o.username,o.goodsname,o.num from order_0 o, user_1 u where o.uid=u.id and u.age=? ::: [21]
2020-02-20 19:31:50.615 INFO 26008 --- [nio-8080-exec-1] ShardingSphere-SQL : Actual SQL: ds ::: select o.id,o.uid,o.username,o.goodsname,o.num from order_0 o, user_0 u where o.uid=u.id and u.age=? ::: [21]
sharding-jdbc这里实际上执行了五条查询语句
三.存在的问题
1、跨节点关联查询 Join 问题
切分之前,我们可以通过Join来完成。而切分之后,数据可能分布在不同的节点上,此时Join带来的问题就比较麻烦了,考虑到性能,尽量避免使用Join查询。
解决这个问题的一些方法:
全局表
全局表,也可看做是 “数据字典表”,就是系统中所有模块都可能依赖的一些表,为了避免跨库Join查询,可以将 这类表在每个数据库中都保存一份。这些数据通常很少会进行修改,所以也不担心一致性的问题。
字段冗余
利用空间换时间,为了性能而避免join查询。例:订单表保存userId时候,也将userName冗余保存一份,这样查询订单详情时就不需要再去查询"买家user表"了。
数据组装
在系统层面,分两次查询。第一次查询的结果集中找出关联数据id,然后根据id发起第二次请求得到关联数据。最后将获得到的数据进行字段拼装。
2、跨节点分页、排序、函数问题
跨节点多库进行查询时,会出现Limit分页、Order by排序等问题。分页需要按照指定字段进行排序,当排序字段就是分片字段时,通过分片规则就比较容易定位到指定的分片;
当排序字段非分片字段时,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序,最终返回给用户。
3、全局主键避重问题
如果都用主键自增肯定不合理,如果用UUID那么无法做到根据主键排序,所以我们可以考虑通过雪花ID来作为数据库的主键,
4、数据迁移问题
采用双写的方式,修改代码,所有涉及到分库分表的表的增、删、改的代码,都要对新库进行增删改。同时,再有一个数据抽取服务,不断地从老库抽数据,往新库写,
边写边按时间比较数据是不是最新的。
四,jdbc不支持项
1.DataSource接口
- 不支持timeout相关操作
2.Connection接口
- 不支持存储过程,函数,游标的操作
- 不支持执行native的SQL
- 不支持savepoint相关操作
- 不支持Schema/Catalog的操作
- 不支持自定义类型映射
3.Statement和PreparedStatement接口
- 不支持返回多结果集的语句(即存储过程,非SELECT多条数据)
- 不支持国际化字符的操作
4.对于ResultSet接口
- 不支持对于结果集指针位置判断
- 不支持通过非next方法改变结果指针位置
- 不支持修改结果集内容
- 不支持获取国际化字符
- 不支持获取Array
5.JDBC 4.1
-
不支持JDBC 4.1接口新功能
更多技术文章请关注公众号:架构师Plus,
扫码添加
