SPPNet——空间金字塔池化
论文链接:https://arxiv.org/pdf/1406.4729.pdf
一、SPPNet简介
SPP就是在卷积神经网络的卷积层和第一层全连接层之间加入一层空间金字塔池化层,时使得网络可以接受任意尺寸的图片作为输入。
不采用SPP的一般卷积神经网络都得要求输入的图片具有固定的尺寸,因为经过最后一层卷积层到第一层全连接层的过程中需要把卷积层以及池化层提取到的特征进行flatten,然后将其输入第一层全连接层,而全连接层的权重矩阵的大小是固定的,所以一般网络必须保证图片的尺寸从而来保证flatten后送入第一层全连接层的特征的长度。所以传统的卷积神经网络一般会先对图像进行裁剪,拉伸等处理保证输入网络的每一张图片大小一致。以下为SPPNet和传统卷积神经网络架构的对比:

SPP的优点有以下几点:
第一:解决输入图片尺寸大小不一造成的缺陷。
第二:由于把一个feature map从不同的角度进行特征提取,再聚合的特点,显示了算法的robust的特性。
第三:同时也在object recognition任务中增加了识别的精度。
SPPNet的具体结构和处理步骤如下图所示:
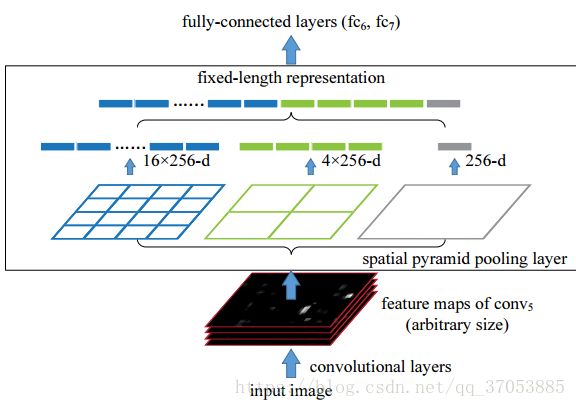
(假设第一层全连接层需要送入的特征个数为21个)
首先获取最后一层卷积层(conv5)提取到的特征,对该层进行多尺度的划分与池化处理。
第一张图片,我们把一张完整的图片(feature map),分成了16个块,也就是每个块的大小就是(w/4,h/4);
第二张图片,划分了4个块,每个块的大小就是(w/2,h/2);
第三张图片,把一整张图片作为了一个块,也就是块的大小为(w,h)
最有将在三张图片上获取到的图片的feature进行拼接,送入到第一层的全连接层。
空间金字塔最大池化的过程,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出神经元。上面的三种不同刻度的划分,每一种刻度我们称之为:金字塔的一层,每一个图片块大小我们称之为:windows size了。对于一个宽为w,高为h的feature map,如果你希望,金字塔的某一层输出n*n个特征,那么你就要用windows size大小为:(ceil(w/n),ceil(h/n) )进行池化了,此外该层pooling的stride应该设置为stridex=ceil(w/n),stridey=ceil(h/n),cell为向上取整,目的是对除不尽的情况做特殊处理。
二、SPPNet的代码实现
以下为SPP的核心代码
import math
def spatial_pyramid_pool(self,previous_conv, num_sample, previous_conv_size, out_pool_size):
'''
previous_conv: a tensor vector of previous convolution layer
num_sample: an int number of image in the batch
previous_conv_size: an int vector [height, width] of the matrix features size of previous convolution layer
out_pool_size: a int vector of expected output size of max pooling layer
returns: a tensor vector with shape [1 x n] is the concentration of multi-level pooling
'''
# print(previous_conv.size())
for i in range(len(out_pool_size)):
# print(previous_conv_size)
h_wid = int(math.ceil(previous_conv_size[0] / out_pool_size[i]))
w_wid = int(math.ceil(previous_conv_size[1] / out_pool_size[i]))
h_pad = int(math.ceil(h_wid*out_pool_size[i] - previous_conv_size[0] + 1)/2)
w_pad = int(math.ceil(w_wid*out_pool_size[i] - previous_conv_size[1] + 1)/2)
maxpool = nn.MaxPool2d((h_wid, w_wid), stride=(h_wid, w_wid), padding=(h_pad, w_pad))
x = maxpool(previous_conv)
if(i == 0):
spp = x.view(num_sample,-1)#view()函数将一个feature转化成为batchsize行,和y列,y为每一个sample经过特征提取之后的feature个数,关于view()函数的具体说明详见文章底部的Reference
# print("spp size:",spp.size())
else:
# print("size:",spp.size())
spp = torch.cat((spp,x.view(num_sample,-1)), 1)
return spp
以下为SPPNet框架的代码
import torch
import torch.nn as nn
from torch.nn import init
import functools
from torch.autograd import Variable
import numpy as np
import torch.nn.functional as F
from spp_layer import spatial_pyramid_pool
class SPP_NET(nn.Module):
'''
A CNN model which adds spp layer so that we can input multi-size tensor
'''
def __init__(self, opt, input_nc, ndf=64, gpu_ids=[]):
super(SPP_NET, self).__init__()
self.gpu_ids = gpu_ids
self.output_num = [4,2,1]
self.conv1 = nn.Conv2d(input_nc, ndf, 4, 2, 1, bias=False)
self.conv2 = nn.Conv2d(ndf, ndf * 2, 4, 1, 1, bias=False)
self.BN1 = nn.BatchNorm2d(ndf * 2)
self.conv3 = nn.Conv2d(ndf * 2, ndf * 4, 4, 1, 1, bias=False)
self.BN2 = nn.BatchNorm2d(ndf * 4)
self.conv4 = nn.Conv2d(ndf * 4, ndf * 8, 4, 1, 1, bias=False)
self.BN3 = nn.BatchNorm2d(ndf * 8)
self.conv5 = nn.Conv2d(ndf * 8, 64, 4, 1, 0, bias=False)
self.fc1 = nn.Linear(64×(4*4+2*2+1*1),4096)
self.fc2 = nn.Linear(4096,1000)
def forward(self,x):
x = self.conv1(x)
x = self.LReLU1(x)
x = self.conv2(x)
x = F.leaky_relu(self.BN1(x))
x = self.conv3(x)
x = F.leaky_relu(self.BN2(x))
x = self.conv4(x)
# x = F.leaky_relu(self.BN3(x))
# x = self.conv5(x)
spp = spatial_pyramid_pool(x,1,[int(x.size(2)),int(x.size(3))],self.output_num)
# print(spp.size())
fc1 = self.fc1(spp)
fc2 = self.fc2(fc1)
s = nn.Sigmoid()
output = s(fc2)
return output
三、SPPNet在目标检测中的应用
SPPNet最初是运用物体目标检测中,其具体的操作过程如下所示:
1.首先在待检测的图片中选择性的收缩出2K个候选的窗口。
2.将原图片送入到卷积神经网络,进行一次性的特征提取。获得原图像的feature map。
3.通过公式
( x , y ) = ( S ⋅ x ′ , S ⋅ y ′ ) x ′ = ⌊ x / S ⌋ + 1 y ′ = ⌊ y / S ⌋ + 1 (x,y)=(S\cdot x',S\cdot y' )\\ x' = \lfloor x/S \rfloor+1\\ y'=\lfloor y/S \rfloor+1 (x,y)=(S⋅x′,S⋅y′)x′=⌊x/S⌋+1y′=⌊y/S⌋+1
计算得到2k个的候选窗口在feature map中的对应位置 ,其中
(x,y)是指原图片中点的坐标,(x’,y’)指的是feature map中点的坐标,S则是所有CNN的过程中stride的乘积。
四、反思与总结
问题阐述:
虽然SPPNET可以使得网络可以接受不同尺寸的图片的输入,但是在深度学习中我们一般采用批处理(batch)数据来训练网络,然而一个batch中的数据必须保证图片的尺寸在各个维度上面必须是一致的(因为训练的过程需要将批量的数组转化为张量的形式)。因此SPPNET接受不同图片尺寸作为网络的输入的情况也只适用于batch_size=1的时候。
总结:
对于模型的训练将batch_size设置为1明显是不合理的,这样会导致模型最终难以收敛。所以SPPNET在深度学习中主要的应用应该在于从特征提取的最后一个feature map中进行多尺度的感知(不同尺寸的pooling_size)以增强特征的表现能力。这也是SPPNET的主要作用。而对于不同的size的图片我们为了保证原有图片的flexibility的时候主要还是采用图片尺寸的等比例缩放以及相关的填充,以保证图片具有相同大小的尺寸以及特征不丢失。
References:
https://blog.csdn.net/hjimce/article/details/50187655
https://github.com/yueruchen/sppnet-pytorch
https://blog.csdn.net/whut_ldz/article/details/78882532
https://github.com/bonopi07/SPPNet_PyTorch/blob/master/src/KISnet.py
editor by:SaulZhang 2018-08-18 In Xi’an