Kafka介绍
1. Kafka的基本介绍
1.1 什么是Kafka?
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- 支持在线水平扩展
1.2 kafka的特点
- 解耦。Kafka具备消息系统的优点,只要生产者和消费者数据两端遵循接口约束,就可以自行扩展或修改数据处理的业务过程。
- 高吞吐量、低延迟。即使在非常廉价的机器上,Kafka也能做到每秒处理几十万条消息,而它的延迟最低只有几毫秒。
- 持久性。Kafka可以将消息直接持久化在普通磁盘上,且磁盘读写性能优异。
- Kafka集群支持热扩展,Kaka集群启动运行后,用户可以直接向集群添。
- 容错性。Kafka会将数据备份到多台服务器节点中,即使Kafka集群中的某一台加新的Kafka服务节点宕机,也不会影响整个系统的功能。
- 支持多种客户端语言。Kafka支持Java、.NET、PHP、Python等多种语言。
- 支持多生产者和多消费者。
1.3 kafka的主要应用场景
- 消息处理(MQ)
KafKa可以代替传统的消息队列软件,数据量不会影响到KafKa的速度,分布式容灾好,稳定性强队列在使用中最怕丢失数据,KafKa能做到理论上的写成功不丢失 - 分布式日志系统(Log)
- 流式处理
2.kafka的架构
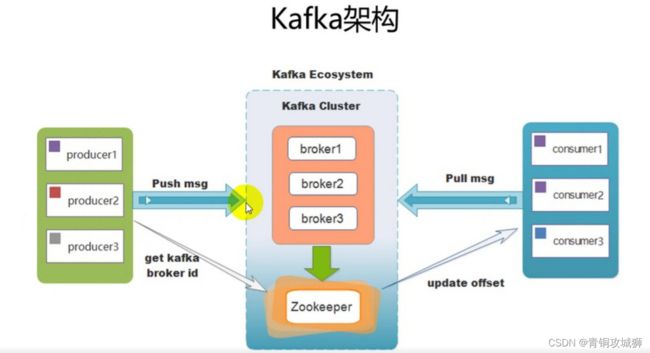
- Kafka Cluster:由多个服务器组成。每个服务器单独的名字broker(掮客)。
- kafka broker:kafka集群中包含的服务器。kafka集群中包含一个或者多个服务实例,这种服务实例被称为Broker
- Kafka Producer:消息生产者、发布消息到 kafka 集群的终端或服务。
- Kafka consumer:消息消费者、负责消费数据。
- Kafka Topic: 主题,一类消息的名称。存储数据时将一类数据存放在某个topci下,消费数据也是消费一类数据。
订单系统:创建一个topic,叫做order。
用户系统:创建一个topic,叫做user。
商品系统:创建一个topic,叫做product。 - Kafka Partition:分区,物理上的概念,每个topic包含一个或多个partition,一个partition对应一个文件夹,这个文件夹下存储partition的数据和索引文件,每个partition内部是有序的
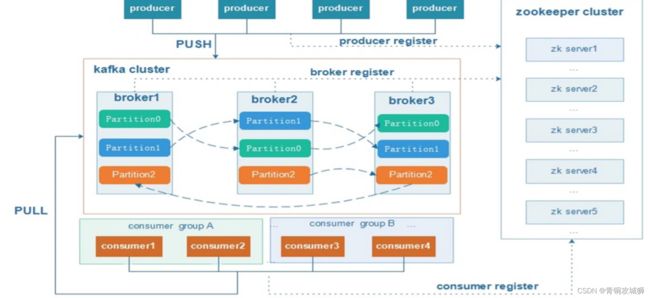
注意:Kafka的元数据都是存放在zookeeper中。kafka支持消息持久化,消费端为拉模型来拉取数据,消费状态和订阅关系有客户端负责维护,消息消费完后,不会立即删除,会保留历史消息。因此支持多订阅时,消息只会存储一份就可以了。
3. Apache kafka原理
3.1分区副本机制
kafka有三层结构:kafka有多个主题,每个主题有多个分区,每个分区又有多条消息。
分区机制:主要解决了单台服务器存储容量有限和单台服务器并发数限制的问题 ,一个分片的不同副本不能放到同一个broker上。当主题数据量非常大的时候,一个服务器存放不了,就将数据分成两个或者多个部分,存放在多台服务器上。每个服务器上的数据,叫做一个分片

- 分区对于 Kafka 集群的好处是:实现负载均衡,高存储能力、高伸缩性。
- 分区对于消费者来说,可以提高并发度,提高效率。
副本:副本备份机制解决了数据存储的高可用问题,当数据只保存一份的时候,有丢失的风险。为了更好的容错和容灾,将数据拷贝几份,保存到不同的机器上。
面试问题:
1. kafka的副本都有哪些作用?
- 多个follower副本通常存放在和leader副本不同的broker中。通过这样的机制实现了高可用,当某台机器挂掉后,其他follower副本也能迅速“转正”,开始对外提供服务。
- 在kafka中,实现副本的目的就是冗余备份,且仅仅是冗余备份,所有的读写请求都是由leader副本进行处理的。follower副本仅有一个功能,那就是从leader副本拉取消息,尽量让自己跟leader副本的内容一致。
2. follower副本为什么不对外提供服务?
- 这个问题本质上是对性能和一致性的取舍。如果follower对外提供服务,首先,性能是肯定会有所提升的。但同时,会出现一系列问题。类似数据库事务中的幻读,脏读。(因为需要数据的同步,如果未同步完,就会出现数据的问题)
- 比如现在写入一条数据到kafka主题a,消费者b从主题a消费数据,却发现消费不到,因为消费者b去读取的那个分区副本中,最新消息还没写入。而这个时候,另一个消费者c却可以消费到最新那条数据,因为它消费了leader副本。
3.2kafka保证数据不丢失
从Kafka的大体角度上可以分为数据生产者,Kafka集群,还有就是消费者,而要保证数据的不丢失也要从这三个角度去考虑。
3.2.1 消息生产者
消息生产者保证数据不丢失:消息确认机制(ACK机制),参考值有三个:
0:无需等待来自broker的确认而继续发送下一批消息,效率最高,可靠性最低
1:收到Leader副本成功写入通知,就认为推送消息成功
-1:只有收到分区内所有副本的成功写入的通知才认为推送消息成功,效率最低,可靠性最高
//producer无需等待来自broker的确认而继续发送下一批消息。
//这种情况下数据传输效率最高,但是数据可靠性确是最低的。
properties.put(ProducerConfig.ACKS_CONFIG,"0");
//producer只要收到一个分区副本成功写入的通知就认为推送消息成功了。
//这里有一个地方需要注意,这个副本必须是leader副本。
//只有leader副本成功写入了,producer才会认为消息发送成功。
properties.put(ProducerConfig.ACKS_CONFIG,"1");
//ack=-1,简单来说就是,producer只有收到分区内所有副本的成功写入的通知才认为推送消息成功了。
properties.put(ProducerConfig.ACKS_CONFIG,"-1");
3.2.2 消息消费者
为什么消费者丢失数据?
- 由于Kafka consumer默认是自动提交位移的(先更新位移,再消费消息),如果消费程序出现故障,没消费完毕,此时已经更新了offset,则丢失了消息,此时,broker并不知道。
解决方案:
- enable.auto.commit=false 关闭自动提交位移
- 在消息被完整处理之后再手动提交位移
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
4. 生产者消息分发策略
kafka在数据生产的时候,有一个数据分发策略。默认的情况使用DefaultPartitioner.class类。
public interface Partitioner extends Configurable, Closeable {
/**
* Compute the partition for the given record.
*
* @param topic The topic name
* @param key The key to partition on (or null if no key)
* @param keyBytes The serialized key to partition on( or null if no key)
* @param value The value to partition on or null
* @param valueBytes The serialized value to partition on or null
* @param cluster The current cluster metadata
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
/**
* This is called when partitioner is closed.
*/
public void close();
}
- 如果是用户指定了partition,生产者就不会调用DefaultPartitioner.partition()方法,数据分发策略的时候,可以指定数据发往哪个partition。
- 当ProducerRecord 的构造参数中有partition的时候,就可以发送到对应partition上
/**
* Creates a record to be sent to a specified topic and partition
*
* @param topic The topic the record will be appended to
* @param partition The partition to which the record should be sent
* @param key The key that will be included in the record
* @param value The record contents
*/
public ProducerRecord(String topic, Integer partition, K key, V value) {
this(topic, partition, null, key, value, null);
}
- 如果指定key,是取决于key的hash值
- 如果不指定key,轮询分发
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
//获取该topic的分区列表
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
//获得分区的个数
int numPartitions = partitions.size();
//如果key值为null
if (keyBytes == null) {
//如果没有指定key,那么就是轮询
// 维护一个key为topic的ConcurrentHashMap,并通过CAS操作的方式对value值执行递增+1操作
int nextValue = nextValue(topic);
//获取该topic的可用分区列表
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
//如果可用分区大于0
// 执行求余操作,保证消息落在可用分区上
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
}
else {
// 没有可用分区的话,就给出一个不可用分区
return Utils.toPositive(nextValue) % numPartitions;
}
}
else {
//不过指定了key,key肯定就不为null
// 通过计算key的hash,确定消息分区
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
5. 消费者负载均衡机制
同一个分区中的数据,只能被一个消费者组中的一个消费者所消费。例如 P0分区中的数据不能被Consumer Group A中C1与C2同时消费。
消费组:一个消费组中可以包含多个消费者,properties.put(ConsumerConfig.GROUP_ID_CONFIG,“groupName”);
如果该消费组有四个消费者,主题有四个分区,那么每人一个。多个消费组可以重复消费消息。 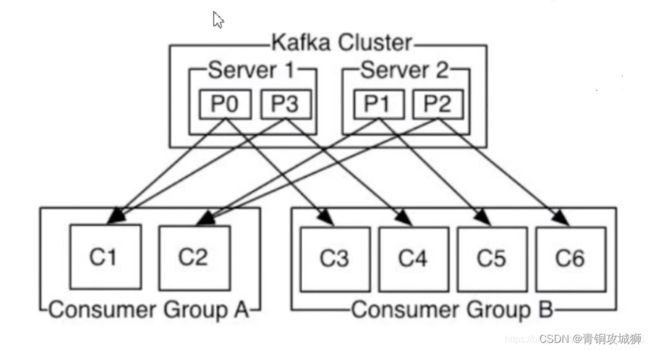
- 如果有3个Partition, p0/p1/p2,同一个消费组有3个消费者,c0/c1/c2,则为一一对应关系;
- 如果有3个Partition, p0/p1/p2,同一个消费组有2个消费者,c0/c1,则其中一个消费者消费2个分区的数据,另一个消费者消费一个分区的数据;
-如果有2个Partition, p0/p1,同一个消费组有3个消费者,c0/c1/c3,则其中有一个消费者空闲,另外2个消费者消费分别各自消费一个分区的数据;
6. Java API操作kafka
- 创建maven的工程, 导入kafka相关的依赖
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>1.0.0version>
dependency>
- 生产者代码
public class ProducerDemo {
public static String topic = "test";//定义主题
public static void main(String[] args) throws Exception {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.200.20:9092,192.168.200.20:9093,192.168.200.20:9094");
//网络传输,对key和value进行序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//创建消息生产对象,需要从properties对象或者从properties文件中加载信息
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
try {
while (true) {
//设置消息内容
String msg = "Hello," + new Random().nextInt(100);
//将消息内容封装到ProducerRecord中
ProducerRecord<String, String> record = new ProducerRecord<String, String>(topic, msg);
kafkaProducer.send(record);
System.out.println("消息发送成功:" + msg);
Thread.sleep(500);
}
}
finally {
kafkaProducer.close();
}
}
}
- 消费者代码
public class ProducerDemo {
public static String topic = "lagou";//定义主题
public static void main(String[] args) throws Exception {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.200.20:9092,192.168.200.20:9093,192.168.200.20:9094");
//网络传输,对key和value进行序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//指定组名
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
kafkaConsumer.subscribe(Collections.singletonList(ProducerDemo.topic));// 订阅消息
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println(String.format("topic:%s,offset:%d,消息:%s",
record.topic(), record.offset(), record.value()));
}
}
}
}