【Java-Crawler】一文学会使用WebMagic爬虫框架
WebMagic
爬虫主要分为采集、处理、存储三个部分。
在学 WebMagic 框架之前,需要了解 HttpClient、Jsoup(Java HTML Parse) 库,或者说会他们的基本使用。因为 WebMagic 框架内部运用了他们,在你出现问题看源码去查错时,如果不知道 HttpClient、Jsoup 的话,可能不知道怎么回事。主要是 WebMagic 如果脱离了这俩就不能说是一个容易入门的爬虫框架了。
WebMagic官方文档
WebMagic 架构
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider(容器)将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。WebMagic的设计参考了Scapy(Python的一个框架),但是实现方式更Java化一些。
而Spider则将这几个组件组织起来,让它们可以互相交互,流程化的执行,可以认为Spider是一个大的容器,它也是WebMagic逻辑的核心。
WebMagic总体架构图如下:
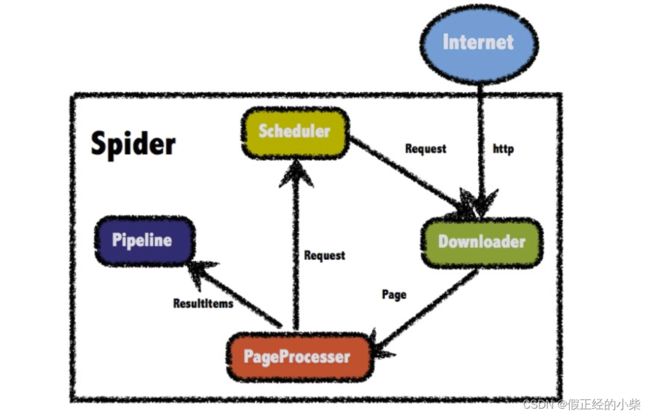
WebMagic 四大组件
1.Downloader
Downloader(下载器)负责从互联网上下载页面,以便后续处理,可以理解为抓数据。
2.PageProcessor
PageProcessor(页面处理器)负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。简单理解解析数据。
3.Scheduler
Scheduler(调度器)负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
4.Pipeline
Pipeline (管道)定义了结果保存的方式,如果需要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
四大组件都是Spider中的属性
用于数据流转的对象
1. Request
Request是对URL地址的一层封装,一个Request对应一个URL地址。
它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方式。
除了URL本身外,它还包含一个Key-Value结构的字段extra。你可以在extra中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。例如附加上一个页面的一些信息等。
2. Page
Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。
Page是WebMagic抽取过程的核心对象,它提供一些方法可供抽取、结果保存等。在第四章的例子中,我们会详细介绍它的使用。
3. ResultItems
ResultItems相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。它的API与Map很类似,值得注意的是它有一个字段skip,若设置为true,则不应被Pipeline处理。
编写基本的爬虫
1. 实现PageProcessor接口
将PageProcessor 的定制分为三个部分,分别是爬虫的配置、页面元素的抽取和链接的发现。
public class JobProcessor implements PageProcessor {
/**
* 该方法负责解析页面
* @param page
*/
@Override
public void process(Page page) {
// 解析返回的数据page,并且把解析的结果放到 resultItems中
// 如果没有制定pipeline输出的位置,是直接输出在控制台上
page.putField("title",page.getHtml().css("title").all());
}
private Site site = Site.me();
@Override
public Site getSite() {
return site;
}
// 主函数,执行爬虫
public static void main(String[] args) {
Spider.create(new JobProcessor())
.addUrl("https://www.51cto.com/") // 设置爬取数据的页面
.run();// 执行爬虫
}
}
2 使用Selectable抽取元素
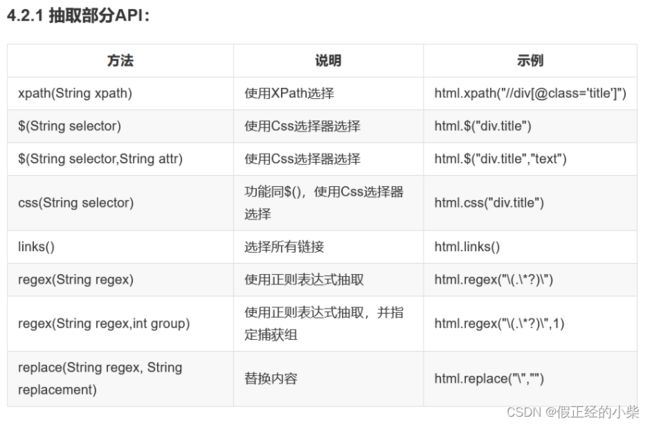
Selectable相关的抽取元素链式API是WebMagic的一个核心功能。使用Selectable接口,你可以直接完成页面元素的链式抽取,也无需去关心抽取的细节。
在刚才的例子中可以看到,page.getHtml()返回的是一个Html对象,它实现了Selectable接口。这个接口包含一些重要的方法,我将它分为两类:抽取部分和获取结果部分。
WebMagic 里主要使用了三种抽取技术:XPath、正则表达式和CSS选择器。另外,对于JSON 格式的内容,可以使用JSONPath去解析。
下面是三种抽取方式的例子:XPath、正则、CSS选择器,也可以整合
@Override
public void process(Page page) {
// 解析返回的数据page,并且把解析的结果放到 resultItems中
// 如果没有制定pipeline输出的位置,是直接输出在控制台上
// css选择器
page.putField("title",page.getHtml().css("title").all());
// 正则表达式
page.putField("p1",page.getHtml().xpath("//div[@class=top]/top/template/div/a/p").regex(".*电话.*").all());
// XPath
page.putField("p",page.getHtml().xpath("//div[@class=top]/top/template/div/a/p").all());
}
XPath 中 /text() 就相当于 Element 中方法 text(),反正 XPath、正则、CSS选择器三种抽取方式都挺重要的。

(get和toString是一致的结果,默认多条结果的情况下为第一条)
3. 获取链接
pageProcessor 解析完页面有两种情况,一种是将数据输出通过Pipeline组件,一种是通过Scheduler组件将链接存储,下次自动解析。
// 获取链接
page.addTargetRequests(page.getHtml().css("div.blog-nav-box ul li").links().regex("https.*").all());
4. 使用 Pipeline 保存数据
WebMagic 用于保存结果的组件叫做 Pipeline。我们现在通过"控制台输出"这件事也是通过一个内置的 Pipeline 完成的,它叫做 ConsolePipelineline,初始化的时候添加了控制台Pipeline。
那么,我现在需要把结果保存到文件中,怎么做呢?只将 Pipeline 的实现换成"FilePipeline"即可。
5. 爬虫的配置、启动和终止
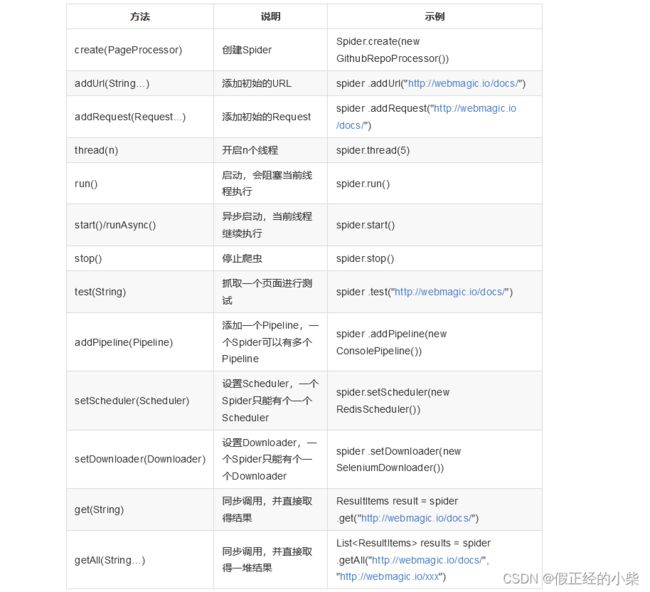
1. Spider
Spider是爬虫启动的入口。在启动爬虫之前,我们需要使用一个PageProcessor创建一个Spider对象(通过调用Spider静态的create()方法),然后使用run()进行启动。同时Spider的其他组件(Downloader、Scheduler、Pipeline)都可以通过set方法来进行设置。
2. 爬虫的配置 Site
对站点本身的一些配置信息,例如编码、HTTP头、超时时间、重试策略等、代理等,都可以通过设置Site对象来进行配置。
private Site site = Site.me()
.setCharset("utf-8")
.setTimeOut(10000) // 设置超时时间,单位是毫秒
.setRetrySleepTime(3000) // 设置重试的间隔时间
.setRetryTimes(3); // 设置重试次数
@Override
public Site getSite() {
return site;
}

爬虫分类
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(爬所有的数据)、聚集网络爬虫(爬感兴趣的数据)、增量式网络爬虫(爬变化的数据)、深层网络爬虫(爬经过处理才能获得的数据)。实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
1. 通用网络爬虫
通用网络爬虫又称全网爬虫(Scalable Web Crawler),爬行对象从一些种子 URL 扩充到整个 web,主要为门户站点搜索引擎和大型 Web 服务提供商采集数据。
这类网络爬虫的爬行范围和数量是巨大的,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求相对较低,同时由于待刷新的页面太多,通常采用并行工作方式,但需要较长时间才能刷新一次页面。
简单来说就是互联网上抓取所有数据(如:百度)
2. 聚集网络爬虫(常用)
聚集网络爬虫(Focused Crawler),又称主题网络爬虫(Topical Crawler),是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫。
和通用网络爬虫相比,聚集爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求。
简单的说就是互联网上只抓取某一种数据。(如:慢慢买)
3. 增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler)是指对已下载网页采取增量式更新和只爬行新产生的或者已经发送变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生或发生更新的页面,并不重新下载没有发送变化的页面,可有效减少数据下载量,及时更新已爬行的网页,减少时间和空间上的耗费,但是增加了爬行算法的复杂度和实现难度。
简单来说就是互联网上只爬取刚刚更新的数据。
4. Deep Web 爬虫
Web 页面按存在方式可以分为表层网页(Surface Web)和深层网页(Deep Web),也称 Invisible Web Pages 或 Hidden Web)。
表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的 Web 网页。
Deep Web 是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交了一些关键字才能获得到的 Web 页面。
Scheduler(调度器)组件
WebMagic 提供了 Scheduler 可以帮助我们解决 URL 的管理问题。
Scheduler 是 WebMagic 中进行 URL 管理的组价。一般来说,Scheduler 包括两个作用:
- 对待抓取的 URL 队列进行管理。
- 对已抓取的 URL 进行去重。
WebMagic内置了几个常用的Scheduler。如果你只是在本地执行规模比较小的爬虫,那么基本无需定制Scheduler,但是了解一下已经提供的几个Scheduler还是有意义的(默认是QueueScheduler)。


去重部分被单独抽象成了一个接口:DuplicateRemover,从而可以为同一个 Scheduler 选择不同的去重方式,以适应不同的需要,目前提供了两种去重方式。

所有默认的Scheduler都使用HashSetDuplicateRemover来进行去重,(除开RedisScheduler是使用Redis的set进行去重)。如果你的URL较多,使用HashSetDuplicateRemover会比较占用内存,所以也可以尝试以下BloomFilterDuplicateRemover,使用方式:
@Scheduled(initialDelay = 1000,fixedDelay = 100000)
public void process(){
Spider.create(new JobProcessor())
.addUrl(url)
.setScheduler(new QueueScheduler().setDuplicateRemover(new BloomFilterDuplicateRemover(100000)))
.thread(5)
.run();
}
三种去重方式
- HashSet
- 使用 Java 中的 HashSet 不能重复的特点去重。优点是容易理解。使用方便。
- 缺点:占用内存大,性能较低。
- Redis 去重
- 使用 Redis 的 set 进行去重。优点是速度快(Redis本身速度就很快),而且去重不会占用爬虫服务器的资源,可以处理更大数据量的数据爬取。
- 缺点:需要准备 Redis 服务器,增加开发和使用成本。
- 布隆过滤器(BloomFilter)
- 使用布隆过滤器也可以实现去重,优点是占用的内存要比使用 HashSet 要小很多,也适合大量数据的去重操作。
- 缺点:有误判的可能。没有重复可能会判定重复,但是重复数据一定会判定重复,就是可能丢失数据。对于爬虫来说是可以接受的。
- 布隆过滤器(Bloom Filter)是由 Burton Howard Bloom 于 1970 年提出,它是一种 space efficient 的概率型数据结构,用于判断一个元素是否在集合中。在垃圾邮件过滤的黑白名单方法、爬虫(Crawler)的网址判重模块中经常会用到。
- 哈希表也能用于判断元素是否在集合中,但是布隆过滤器只需要哈希表的 1/8 或 1/4 的空间负责度就能完成同样的问题。布隆过滤器可以插入元素,但不可以删除已有的元素。
其中的元素越多,误报率越大,但是漏报是不可能的。
使用 WebMagic 的优点和缺点
优点:
- 易上手,直接添加依赖然后去实现
PageProcessor就可以开始操作了。 - 提供了IO和多线程,高效且稳定。
- 是具有模块化的,且很容易拓展。
缺点:
- 仅能解析静态页面,获取静态页面的原生 HTML,但现在很多网页都是动态生产的,很多都是< script >标签组成的未被浏览器解析的。也就是说 WebMagic 不支持 JavaScript 解析。
好在使用 Selenium + ChromeDriver 可以解决它(这玩意给小编整了俩天,整吐了,接下来梳理篇博客来整理一下)。也可以写个自己的 Downloader 组件并用 Spider 去配置它,但小编搞了半天没搞出来。