sklearn评分函数roc_auc_score和f1_score中参数average的说明
roc_auc_score和f1_score中参数average的说明
本文记录在python第三方库sklearn的两个评分函数 sklearn.metrics.roc_auc_score(计算AUC) 和 sklearn.metrics.f1_score(计算F1)中的参数“average”的几种方式。
两个评分函数
本文主要解释参数"average",其他参数不做解释,可参考官网(见参考文档)
roc_auc_score
sklearn.metrics.roc_auc_score(y_true, y_score, *, average=‘macro’, sample_weight=None, max_fpr=None, multi_class=‘raise’, labels=None)
对于 roc_auc_score,其 average 的选择方式有
{‘micro’, ‘macro’, ‘samples’, ‘weighted’} or None, default = ’macro’
micro
通过将标签指标矩阵的每个元素视为标签来全局计算指标。
macro
计算每个标签的指标,并找到它们的未加权平均值。注意这没有考虑标签不平衡。
samples
计算每个实例的指标,并找到它们的平均值。当y_true 为二进制时将被忽略。
weighted
计算每个标签的指标,并找到它们的平均值,按支持度加权(每个标签的真实实例数),该选项考虑了标签不平衡的情况。
f1_score
sklearn.metrics.f1_score(y_true, y_pred, labels=None, pos_label=1, average=‘binary’, sample_weight=None,zero_division=‘warn’)
{‘micro’, ‘macro’, ‘samples’, ‘weighted’, ‘binary’} or None, default=’binary’}
注意与roc_auc_score的区别,f1_score多了一个选项,“binary”,并且默认是该选项。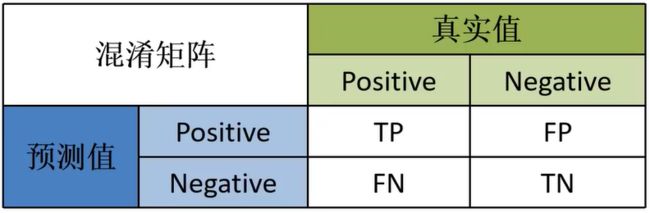
F1分数可以解释为精度和查全率的加权平均值,其中F1分数在1时达到最佳值,在0时达到最差值。精度和查全率对F1分数的相对贡献相等。F1分数的公式为:
F1 = 2 * (precision * recall) / (precision + recall)
其中,precision = TP / (TP + FP);recall = TP / (TP + FN)
binary
仅报告由指定的类的结果pos_label。仅在目标(y_{true,pred})为二进制时适用。
micro
通过统计全部的 TP、FN、FP来计算F1
macro
计算每个标签的指标,并找到其未加权平均值。这没有考虑标签不平衡。
weighted
计算每个标签的指标,并找到其平均权重(每个标签的真实实例数)。这改变了“宏观 macro”以解决标签的不平衡。(所以类别不平衡时尝试用weighted) 这可能导致F得分不在精确度和召回率之间。
samples
计算每个实例的指标,并找到其平均值(仅对不同于accuracy_score的多标签分类有意义 )
通俗解释 macro 和 micro:
macro:宏平均(Macro-averaging)
把每个类别都当成二分类,分别计算出各个类别 对应的precision,recall, f1 , 然后求所有类别的precision,recall,f1的平均值,得到最终的precision recall f1. 这里假设所有分类都是一样的重要,所以 整体结果受小类别(数量比较少的target)的影响比较大。
micro:微平均(Micro-averaging)
把各个类别当成二分类,统计各自的混淆矩阵,然后统计加和 比例 得到一个最终的 混淆矩阵,再计算precision,recall,f1
参考文档
- sklearn官网roc_auc_score
- sklearn官网f1_score
- 机器学习评价指标ROC中 macro,micro 的区别