python pandas 轻松通过特定列的值多条件去筛选数据以及contains方法的应用
pandas 轻松筛选数据
通过特定列的值去筛选
import pandas as pd
import numpy as np
a=np.array([['北京','北方','一线','非沿海'],['杭州','南方','二线','非沿海'],['深圳','南方','一线','沿海'],['烟台','北方','三线','沿海']])
df1=pd.DataFrame(a,index=[1,2,3,4],columns=['城市','地理','级别','是否沿海'])
print(df1)
df2=df1.copy()

我们先来筛选初来所有的一线二二线城市
df1[(df1['级别'].isin (['一线','二线']))]

相同,如果我们取反的话就可以筛选出不在一线和二线城市的记录
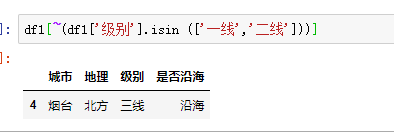
多条件去
df1[((df1['级别'].isin (['一线','二线']))&(df1['是否沿海'].isin(['沿海'])))]

这样就可以轻松的选择特定行数据了,如果是要删除特定行,只需要取反就可以了
df1[~((df1['级别'].isin (['一线','二线']))&(df1['是否沿海'].isin(['沿海'])))]
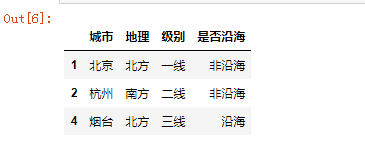
这就等于是删除了特定行
通过contains对数据进行筛选
比如我们去筛选级别在一线和二线的城市信息
df1[df1['级别'].str.contains("一线|二线",na=False)]

同样我们可以通过取反把在一线二线城市的信息全部筛选掉:
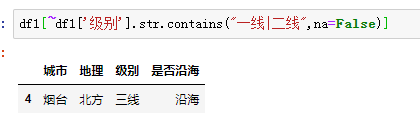
至于多条件就可以使用上述同样的方法