C语言函数(详解)
目录
1、函数是什么
2、库函数
2.1、库函数
2.2自定义函数
3.函数的参数
3.1实际参数(实参)
3.2形式参数(形参)
4.函数的调用
4.1传值调用
4.2传址调用
5.函数的嵌套调用和链式访问
5.1嵌套调用
5.2链式访问
6.函数的声明和定义
6.1函数声明
6.2函数定义
7.函数递归
7.1什么是递归
7.2递归的两个必要条件
7.3递归与迭代
1、函数是什么
数学中我们常见到函数的概念,但是你了解C语言的函数吗?
在维基百科中,对函数的定义是子程序。子程序是一个大型程序中的某部分代码,由一个或多个语句块组成,他负责完成某项特定的任务,而且相较于其他的代码,具备相对的独立性。一般会有输入参数并有返回值,提供对过程的分装和细节的隐藏。这些代码通常被集成为软件库。
2、库函数
2.1、库函数
为什么会有库函数?
我们知道在我们在学习C语言编程的时候,总是在一个代码编写完成之后迫不及待的想知道结果,想把这个结果打印到我们的屏幕上看看。这个时候我们会频繁的使用一些功能:将信息按照一定的格式打印到屏幕上(printf)
在编程的过程中我们会频繁的做一些字符串的拷贝工作(strcpy)
在编程时我们也会计算像n的k次方的这样的运算(pow)
像上面我们描述的基本功能,它们不是业务性的代码。我们在开发过程中每个程序员都可能用得到,为了支持可移植性和提高程序的效率,所以C语言的基础库中提供了一系列类似的库函数,方便程序员进行软件开发。
注:库函数的使用要包含对应的头文件(库函数是把函数放到库里,供别人使用的一种方式,方法是把一些常用到的函数编完放到一个文件里,供不同的人进行调用,调用的时候把它所在的文件名用#include<>加到里面就可以了)
那么怎样学习库函数呢?下面推荐给大家一个学习库函数的网站:
Reference - C++ Reference

这就是C语言的库,通过左边的头文件分类很快就能找到我们需要的头文件,就比如上面圈起来的stdio.h,大家应该都很熟悉,就是我们平常打印(scanf)和输出(printf)函数的头文件。
讲到这,我们先来学习一个数学函数,先让大家熟悉一下怎么使用:

大家可以先看一下这张图,关键部分我都已经在图中写出来,大概看好之后,我来用代码给大家用整数实现pow函数。
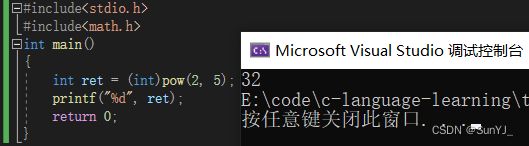
其实我们pow函数里面可以直接用整数,但是前面需要强制类型转换一下,转换成整数(int)类型, 因为 pow 返回的是一个 double 类型的值(如果不知道,上图肯定没有好好看),如果不转换的话会报错。
其次就是因为 pow 是C语言提供给我们的函数,所以我们要加上头文件,#include
就是 pow 所需要的头文件。
我们就先讲一个使用举例让大家了解一下,这样下次遇到不会的函数就可以自己解决了。
2.2自定义函数
如果库函数能干所有的事情,那还要程序员干什么?所以更加重要的是自定义函数。自定义函数和库函数一样,有函数名,返回值类型和函数参数。但是不一样的是这些都是我们自己来设计。这给程序员一个很大的发挥空间。
函数的组成:
ret_type fun_name(para1)
{
statement;//语句项
}
ret_type 返回类型
fun_name 函数名
para1 函数参数
我给大家举个例子就能明白了(写一个函数找出两个数中的最大值)

可以看图中给大家的解释,相信大家对自定义函数的理解又加深了一层(接下来轮到参数了)
3.函数的参数
3.1实际参数(实参)
真实传给函数的参数,叫实参。实参可以是:常量,变量,表达式,函数等。无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。
3.2形式参数(形参)
形式参数是指函数名后括号中的变量,因为形式参数只有在函数被调用的过程中才实例化(分配内存单元),所以叫形式参数。形式参数当函数调用完成之后就自动销毁了。因此形式参数只在函数中有效。
讲到这,我们来实现一个函数用来交换两个整值:

我们可以看到上面实现的函数并没有完成交换,代码又没有错误,为什么不能完成交换呢?
我们来分析一下:
其实我们的形式参数确实收到了实际参数传过来的值,但是形式参数x,y在接收到值之后又开辟了新的空间,跟之前的num1和num2已经不在同一块空间,所以x,y在函数里面虽然完成了交换,但是跟外面的num1和num2并没有关系了。

我们通过调试窗口也可以看到,x,y和num1,num2不在同一块空间,这就导致了我们在Swap1函数里面热闹了半天,跟外面其实一点关系也没有。
怎么解决呢?这就引出来了我们接下来要讲的函数调用。
4.函数的调用
4.1传值调用
函数的形参和实参分别占有不同内存块,形参其实是实参的一份临时拷贝,对形参的修改不会影响实参(这样讲大家大概已经明白了我们刚才其实是传值调用,所以函数里面形参的修改不会影响到外面的实参)
想要解决也很简单,就是我们接下来的传址调用,仔细往下看
4.2传址调用
传址调用是把函数外部创建变量的内存地址传递给函数参数的一种调用函数的方式。这种传参方式可以让函数和函数外边的变量建立起真正的联系,也就是函数内部可以直接操作函数外部的变量。
我们先来看一段简单的传址代码:
int main()
{
int num = 10;
int* p = #
*p = 20;
printf("%d", num);
return 0;
}我们把num的地址传给指针p,p就可以改变num的值。现在我们再看刚才的代码,我们现在是不是可以把num1和num2的地址传过去,然后x和y再通过地址找回来,这样它们之间是不是就建立起了联系,没错,我们现在就试着改造一下刚才的代码:
void Swap2(int* px, int* py)//因为传过来的是地址,所以我们用指针来接收
{
int tmp = 0;
tmp = *px;//相当于tmp = num1
*px = *py;//相当于num1 = num2
*py = tmp;//相当于 num2 = tmp
}
int main()
{
int num1 = 0;
int num2 = 0;
scanf("%d %d", &num1, &num2);
printf("交换前::num1=%d num2=%d\n", num1, num2);
Swap2(&num1, &num2);//我们把num1和num2的地址传过去
printf("交换后::num1=%d num2=%d\n", num1, num2);
return 0;
}我们用这种方法就相当于用*px和*py远程找到了num1和num2然后把它们交换了
注:假如我们需要通过函数改变外面的值,就可以用传址,如果不需要改变外面的值,就可以用传值(不要纠结好坏,各有优缺点)
5.函数的嵌套调用和链式访问
5.1嵌套调用
//函数调用
void new_line(m)
{
printf("hehe\n");
}
int main()
{
new_line();
return 0;
}注:函数是可以嵌套调用的,但是不能嵌套定义(以下代码就是嵌套定义,是绝对不行的)
int main()
{
int Add(int x, int y)
{
return x + y;
}
return 0;
}5.2链式访问
链式访问就是把一个函数的返回值作为另外一个函数的参数。

我们可以看到上面两端代码打印出来都是一样的,第一种就是把函数的返回值放到变量里,第二种就是把函数的返回值作为另外一个函数的参数(printf函数把strlen函数返回的值当成了参数)这就是链式反问。
6.函数的声明和定义
6.1函数声明
1.告诉编译器有一个函数叫什么,参数是什么,返回类型是什么。但是具体是不是存在,函数声明决定不了
2.函数的声明一般出现在函数的使用之前。要满足先声明后使用
3.函数的声明一般要放在头文件中
6.2函数定义
函数的定义是指函数的具体实现,交代函数的功能实现(可以参考以下函数先声明后定义的代码)
//函数的声明
int Add(int x, int y);
int main()
{
int num1 = 0;
int num2 = 0;
scanf("%d %d", &num1, &num2);
//函数的调用
int ret = Add(num1, num2);
printf("%d", ret);
return 0;
}
//函数的定义
int Add(int x,int y)
{
return x + y;
}如果嫌麻烦可以把函数定义写到函数调用的前面,把函数声明省略掉,因为函数定义也是一种特殊的函数声明,但是为了代码美观,就可以写成先声明后定义
我们看了函数的声明之后,可能会有疑问了,函数的声明放在头文件中是什么意思?

通过这张图想必大家有些理解了,但是为什么要写成这样呢?有人觉得可能还不如之前呢。下面我来给大家解释一下。
1.多人协作,假如我们有一个要多人协作完成的代码,难道程序员们都在test.c里面写吗,那岂不是还要排着队写代码,那多麻烦,所以我们就干脆直接头文件声明,另一个.c来定义,主函数来调用就好了。假如我们现在要实现一个计算器,程序员A来写加法,程序员B来写减法,程序员C来写乘法,程序员D来写除法,然后写完之后一合并就好了。
2.代码保护,假如我们写了一个游戏框架,非常好用,其他人都想用,其中有一个公司想付费使用,难道我们直接把源码给他吗?那他用了一次在源码上改一改继续用,下次就不会再买我们的了。所以我们就可以把add.c(拿上面代码举例)改成静态库,再把add.h和add.c给他们,他们看到我们的add.h只知道我们这个函数是干什么的,但是想看这个函数怎么实现的,他永远都不知道这个函数是怎么实现的,这是不是就相当于我们把代码进行了相当的保护。(静态库改变大家可以在网上找一篇专门讲解的,改成静态库他们看到的只有乱码)
7.函数递归
7.1什么是递归
程序调用自身的编程技巧称为递归。递归作为一种算法在程序设计语言中广泛应用。一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量。递归的主要思考方式在于:把大事化小。
7.2递归的两个必要条件
存在限制条件,当满足这个限制条件的时候,递归便不再继续
每次递归调用之后越来越接近这个限制条件
代码举例:输入1234,输出1 2 3 4(递归实现)
void Print(int n)
{
if (n > 9)
{
Print(n / 10);
}
printf("%d ", n % 10);
}
int main()
{
int n = 0;
scanf("%d", &n);
Print(n);
return 0;
}7.3递归与迭代
这里我们直接写题目:求n的阶乘(不考虑溢出)
int Fac(int n)
{
if (n <= 1)
return 1;
else
return n * Fac(n - 1);
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = Fac(n);
printf("%d", ret);
}我们可以去编译器上试一试这段代码,如果给的数小是可以得到正确答案的,但是如果给一个很大的数,就比如10000,代码就会崩溃,为什么呢?因为重复的递归会重复的开辟栈空间,当栈空间被占满之后就会栈溢出了(下面是我给了10000之后的样子)
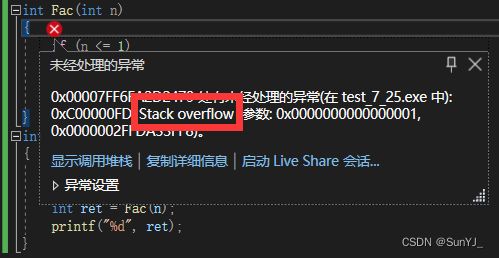
那么我们就要权衡什么时候用递归什么时候用非递归了:
1.如果使用递归很容易想到,写出来的代码没有明显的缺陷,那就可以使用递归
2.但是如果写出的递归代码,有明显的问题,比如:栈溢出、效率低下等,那我们还是要使用迭代的方式来解决问题
大家看完可以去自主研究一下两个问题(还要多做一些递归题目,才能更深入的了解递归)
1.汉诺塔问题
2.青蛙跳台阶问题
如果这篇文章对你有帮助,可以点赞支持一下,谢谢大家!!!