线程安全(上)
前言:
在多线程中,并不是说知道怎么使用就完事了,学习完如何使用多线程之后,我们了解到多线程的并发性和随机调度的特性是我们程序员不容易控制的,所以一旦操作不当就会带来许多安全问题,那我们就开始学习线程安全吧!
目录
1.使用多线程带来的风险(硬件角度分析)
2.产生线程安全的原因(5点)
3.线程安全的解决方法
3.1synchronized 监视器锁(monitor lock)
3.3 synchronized的4种修饰写法(实际上2种)
4.volatile关键字(强制读内存)
5.synchronized与volatile区别
1.使用多线程带来的风险(硬件角度分析)
为了让我们好的了解学习什么是线程安全,我以一个经典的触发线程安全的实例来让大家感受一下多线程带来的安全问题。
实例
有这样一个Java程序,要使用多线程的方式对同一个变量进行修改操作,那此时就会触发线程安全问题,我们两个线程分别对同一变量自增到5w,那我们的期望结果就是两个线程对同一变量共同修改的结果就改为10w,但实际结果真的如想想如此吗?。
package Boke;
class Counter1{
public int cout;
public void increase(){
cout++;
}
public int getCout(){
return cout;
}
}
public class SameUpdate {
public static void main(String[] args) throws InterruptedException {
System.out.println("目标结果是:100000");
Counter1 counter1=new Counter1();
//线程t1让cout成员自增到5w
Thread t1=new Thread(()->{
for (int i = 0; i < 5_0000; i++) {
counter1.increase();
}
});
t1.start();
//线程t2让cout成员自增到5w
Thread t2=new Thread(()->{
for (int i = 0; i < 5_0000; i++) {
counter1.increase();
}
});
t2.start();
//等待两个线程都结束
t1.join();
t2.join();
System.out.println("多线程处理下:"+counter1.getCout());
}
}
由运行结果可知实际结果并不是我们想象的一个线程对变量自增5w,两个线程就是10w,那想要搞清楚发生这种情况的原因,那就要先从硬件的角度搞明白计算机是怎么将一条自增语句执行成功的,当执行一段代码,要先后经历第1步从内存读取命令(一条Java代码对应一条或者多条指令)到CPU中,例如上述的自增操作就对应了3条指令,第2步在CPU寄存器中完成相应的运算,第3步返回运算好的结果到内存中。
对于上述业务(单线程情况下)

可见在单线程的情况下,不管调度器怎么随机执行指令顺序,其结果都是一样的,即都要依次经过读取内存,cpu运算,返回运算结果。
对于上述业务(多线程程情况下)
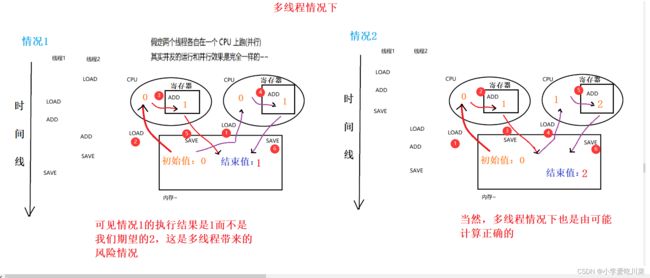
可见多线程的情况下,就会发生这种自增数遗失的尴尬情况,所以通过这个经典简单的例子我们就可以看出,使用多线程看似人畜无害,其实可能出现大问题。
2.产生线程安全的原因(5点)
什么是线程安全呢?简单来说就是在操作系统随机调度的过程中,代码指令的先后执行顺序有无数种可能,如果在这样的情况下,代码逻辑都不会出现问题,那此时我们认为线程是安全的。
标准定义
如果多线程环境下代码运行的结果是符合我们预期的,即在单线程环境应该的结果,则说这个程序是线 程安全的。
那产生线程安全都有哪些原因呢?
原因1
第一种产生线程安全的原因呢,也是最熟悉也是最无奈的操作系统以随机调度,抢占式执行的方式来调度我们的多线程,这也是产生线程安全的"罪恶之源",我们对于这种随机调度的方式是无能为力的。
原因2(原因3的一种)
这第二种,也就是我们上边的哪个用多线程修改同一的一个变量,其实啊,这种原因的本质也是操作系统在执行指令的过程中,采用随机执行的结果,对于这种情况我们可以通过调整程序设计尽量避免上述的情况发生。
注意
注意分析这就话,多线程修改同一个变量,也就是说只有同时满足多线程和修改操作以及同一变量的前提下才有可能会触发线程安全。
1.单线程修改同一变量,没事!
2.多线程读取同一变量,没事!
3.多线程修改不同变量,没事!
原因3
第3种情况是由于操作是否为原子性的操作,当有的线程操作不为原子性时,极大可能发生线程安全问题,什么意思呢?如果一个线程正在对一个变量修改操作,中途其他线程插入进来了也对这个变量进行修改,此时这个操作被打断了,结果就可能是错误的。原子性的操作也就是不可分割的最小操作,例如"="赋值操作,非原子性操作例如上方的自增操作(一共有加载,运算,返回3步操作),为了解决这种情况,我们往往会将非原子性打包成为一个整体(类似于MySQL数据库的事物),此时这个操作就变成了原子性的操作了,我们在多线程这里可以通过加锁( synchronized)的方式完成这种功能(后面详讲)。
原因4
内存可见性,一种由于编译器,JVM或者操作系统"优化"而产生的线程安全问题,经常产生此类问题的场景为一个线程不断读取和判断,另一个线程进行修改 ,所谓优化就是开发者在编写编译器或则操作系统时,考虑到我们写的代码可能不够好,而编写的一系列二进制指令,例如不断重复地读取和判断,读取是读内存操作,判断是读cpu操作,而读内存要比读cpu多耗时3~4个数量级,所以我们的编译器就会将重复的读内存操作优化为只读第一次,直接访问工作内存(实际是 CPU 的寄存器或者 CPU 的缓存),因为反复读取重复的内存数据相比读cpu十分的耗时,所以如果在多线程的情况下,如果另一个线程对数据进行了修改,那读取并判断数据的那个线程就不能及时读取到最新数据,这就是内存可见性,从而引发线程安全问题。
当然我们为了避免操作系统或者编译器这种在多线程情况下的"图快""不图对"优化,我们Java也给我们提供了相应的解决方法,那就是对要操作的变量前加上volatile关键字, 能保证内存可见性 (后面详讲)
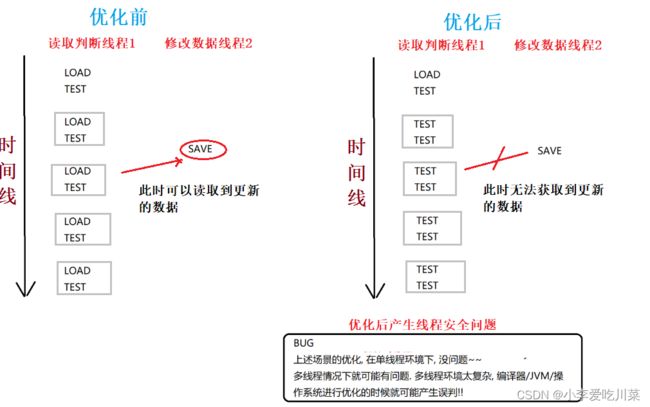
原因5
指令重排序,产生原因也是和内存可见性问题一样由于编译器的"优化"所致,指令重排序是啥呢,指令重排序就是调整了代码的执行顺序,也是一种优化行为,可以达到加快执行速度的好处,如果还不懂,请看简图。
在单线程的情境下,指令重排序的确可以达到加快执行速度的优化效果,但是在多线程里可能就会出现问题,例如我们要实例化一个对象,Student t=new Student(),那这句代码会先后依次执行,1创建内存空间,2在内存空间上构造对象,3将该内存
的引用赋值给t,在单线程下,交换2和3的执行继续,其实并无大碍,但是在多线程的场景下,如果还有一个线程在读取t的引用就会出现问题,我们同样可以使用volatile关键字防止出现指令重排序。
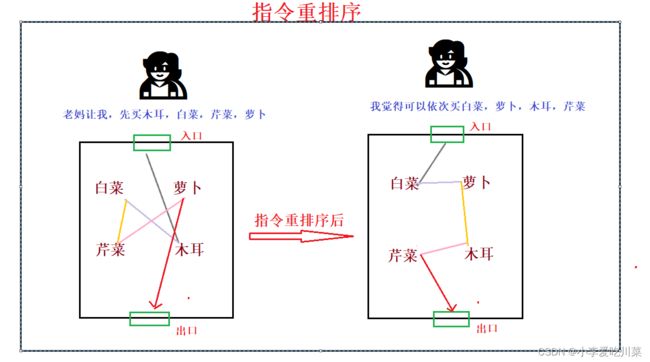

小结

3.线程安全的解决方法
要知道,要想解决所有的线程安全,不是一件容易的事,例如上边我们介绍到的,产生线程安全的根源方法系统随机调度,我们就解决不了,所以我们这里主要介绍如何解决修改操作不是原子性的,加锁和系统优化产生的线程安全问题。
3.1synchronized 监视器锁(monitor lock)
synchronized是Java中的关键字,是一种同步锁,会起到互斥效果, 某个线程执行到某个对象的 synchronized 中时, 其他线程如果也执行到同一个对象 synchronized 就会阻塞等待,注意是同一个对象才会产生阻塞。
进入 synchronized 修饰的代码块 , 相当于 加锁退出 synchronized 修饰的代码块 , 相当于 解锁注意1.synchronized永远都是只对于"对象"加锁的,synchronized 用的锁是存在 Java 对象头里的。 ,例如"类对象"和"普通对象",被加锁的对象实际上就是对象头里与加锁相关的标记信息被修改了,当其他线程都想对同一个对象进行加锁时(也就是都想获取同一把锁时),那这些线程就会进入了阻塞等待,当给对象加锁的线程释放锁之后,其他线程才有机会获取到锁,为什么说是有机会获取到锁呢?因为如果有多个线程都想要获取到同一把锁的话,那她们之间就会发生锁竞争,需注意的是,只有两个线程针对同一个对象加锁时,才会发生锁竞争,如果对于两个不同的对象加锁,则不会有锁竞争。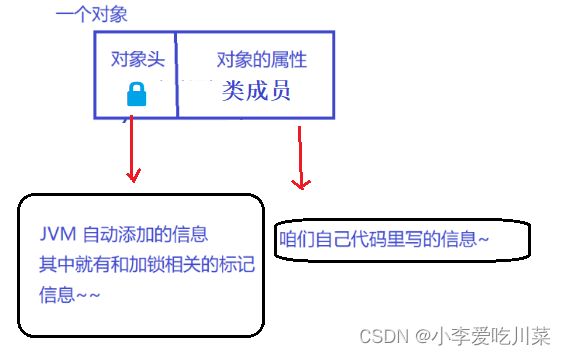 阻塞等待针对每一把锁 , 操作系统内部都维护了一个等待队列 . 当这个锁被某个线程占有的时候 , 其他线程尝试进行加锁, 就加不上了 , 就会阻塞等待 , 一直等到之前的线程解锁之后 , 由操作系统唤醒一个新的线程, 再来获取到这个锁。注意
阻塞等待针对每一把锁 , 操作系统内部都维护了一个等待队列 . 当这个锁被某个线程占有的时候 , 其他线程尝试进行加锁, 就加不上了 , 就会阻塞等待 , 一直等到之前的线程解锁之后 , 由操作系统唤醒一个新的线程, 再来获取到这个锁。注意
- 上一个线程解锁之后, 下一个线程并不是立即就能获取到锁. 而是要靠操作系统来 "唤醒". 这 也就是操作系统线程调度的一部分工作.
- 假设有 A B C 三个线程, 线程 A 先获取到锁, 然后 B 尝试获取锁, 然后 C 再尝试获取锁, 此时 B 和 C 都在阻塞队列中排队等待. 但是当 A 释放锁之后, 虽然 B 比 C 先来的, 但是 B 不一定就能 获取到锁, 而是和 C 重新竞争, 并不遵守先来后到的规则,这就是所谓的锁竞争.
3.2 synchronized的使用及修饰的对象(3个案例)
它修饰的对象有以下几种
1. 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象;
2. 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象;
3. 修改一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象,类对象;
4. 修改一个类,其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象。
实例1
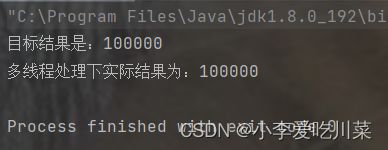
例如我们还是用两个线程对同一个变量进行自增操作(上边多个线程修改同一变量的线程安全问题的实例)作为例子,现在我们通过使用synchronized来解决这个由于操作是非原子操作而引发的线程问题
package Boke;
class Counter1{
public int cout;
//将自增操作所属的对象加锁
//将自增操作打包为原子操作
public synchronized void increase(){
cout++;
}
public int getCout(){
return cout;
}
}
public class SameUpdate {
public static void main(String[] args) throws InterruptedException {
Counter1 counter1=new Counter1();
System.out.println("目标结果是:100000");
//线程t1让cout成员自增到5w
Thread t1=new Thread(()->{
for (int i = 0; i < 5_0000; i++) {
counter1.increase();
}
});
t1.start();
//线程t2让cout成员自增到5w
Thread t2=new Thread(()->{
for (int i = 0; i < 5_0000; i++) {
counter1.increase();
}
});
t2.start();
//等待两个线程都结束
t1.join();
t2.join();
System.out.println("多线程处理下实际结果为:"+counter1.getCout());
}
} 
package Boke;
class Sock{
//该方法实际上是对类对象(仅1个)加锁
public synchronized static void fun1(){
System.out.println("t1获得锁竞争(类对象加锁):fun1()开始");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t1释放锁,fun1()结束");
}
//与fun1()方法一样,也是对类对象加锁
//只不过是代码书写不同
public static void fun2(){
synchronized (Sock.class){
System.out.println("t2获得锁竞争(类对象加锁):fun2()开始");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t2释放锁,fun2()结束");
}
}
}
public class suo {
public static void main(String[] args) throws InterruptedException {
Sock sock=new Sock();
Thread t1=new Thread(()->{
Sock.fun1();
System.out.println("t1 开始");
System.out.println("t1 结束");
});
Thread t2=new Thread(()->{
Sock.fun2();
System.out.println("t2 开始");
System.out.println("t2 结束");
});
t1.start();
t2.start();
t1.join();
t2.join();
}
}

有运行结果和代码可知,因为fun1()和fun2()都是对类对象加锁,线程t1和线程t2第一行代码都想对类对象进行加锁,那此时就会产生锁竞争,所以后拿到锁的线程就会进入线程等待,线程t1先拿到锁,且fun1()和fun2()内部执行时间都较长,所以先拿到锁的线程先执行结束,这是线程对同一个类对象加锁的情况。
实例3(实例化对象)
我们通过synchronized分别对类中的方法进行修饰达到对实例化对象进行加锁操作,观察多线程之间因对同一个对象加锁而产生阻塞等待,引发的代码执行过程,例如下列例子我们预期结果是,线程t1和线程t2都先打印开始,但是t1比t2先结束。
package Boke;
class Sock{
//实际上是对实例化对象加锁(可有多个)
public synchronized void fun3(){
System.out.println("t1获得锁(实例对象加锁),fun3()");
for (int i = 0; i < 50000; i++) {
i++;
}
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t1释放锁,fun3()结束");
}
//与fun4()方法一样,只不过代码书写不同罢了
public void fun4() {
synchronized (this){
System.out.println("t2获得锁(实例对象加锁),fun4()");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t2释放锁,fun4()结束");
}
}
}
public class suo {
public static void main(String[] args) throws InterruptedException {
Sock sock=new Sock();
Thread t1=new Thread(()->{
System.out.println("t1 开始");
sock.fun3();
System.out.println("t1 结束");
});
Thread t2=new Thread(()->{
System.out.println("t2 开始");
sock.fun4();
System.out.println("t2 结束");
});
t1.start();
t2.start();
t1.join();
t2.join();
}
}
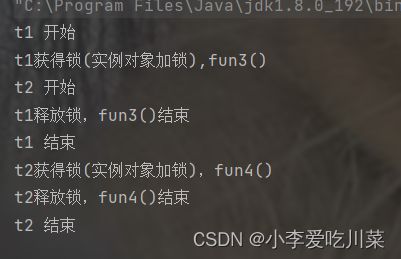
结果可知,的确达到了期望结果,通过synchronized对类的普通方法修饰,都达到了对this对象进行加锁,且调用fun3()和fun4()的实例化对象都是sock,那当两个线程并发执行打印完第一句话之后(大概率情况下,具体情况还得看调度情况),t1线程和t2线程开始进行this对象的锁竞争,由于fun3()和fun4()的内部时间都较长,所以先拿到锁的线程先结束。
3.3 synchronized的4种修饰写法(实际上2种)
使用并书写synchronized的方法已经在上方演示过了,其实写法也就两种,只是针对的加锁对象不同罢了,这里总结一下
第1种synchronized修饰方法
//synchronized修饰静态方法
//该方法实际上是对类对象(仅1个)加锁
public synchronized static void fun1(){
System.out.println("t1获得锁竞争(类对象加锁):fun1()开始");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t1释放锁,fun1()结束");
}
//synchronized修饰普通成员方法
//实际上是对实例化对象加锁(可有多个)
public synchronized void fun3(){
System.out.println("t1获得锁(实例对象加锁),fun3()");
for (int i = 0; i < 50000; i++) {
i++;
}
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t1释放锁,fun3()结束");
}这两种都是在方法名前加上synchronized,前者是对类对象加锁(仅有一个),后者是对当前this对象加锁(不止一个),一个实例化对象对应一个this对象。
第2种synchronized修饰代码块
//synchronized修饰静态代码块
public static void fun2(){
synchronized (Sock.class){
System.out.println("t2获得锁竞争(类对象加锁):fun2()开始");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t2释放锁,fun2()结束");
}
}
//synchronized修饰普通代码块
public void fun4() {
synchronized (this){
System.out.println("t2获得锁(实例对象加锁),fun4()");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t2释放锁,fun4()结束");
}
}这两种都是在方法的代码块中使用synchronized,前者是对类对象加锁(仅有一个),后者是对当前this对象加锁(不止一个),一个实例化对象对应一个this对象。
小结
不管是第一种写法还是第二种写法,其实他们在本质上都是没有差别的,只不过是形式上的差异罢了,他们都是对对象进行加锁(对对象头里的锁标记进行修改),记住这个概念就行了。
4.volatile关键字(强制读内存)
volatile是一个特征修饰符(type specifier).volatile的作用是作为指令关键字,确保本条指令不会因编译器的优化而省略,且要求每次直接读值,这个关键字主要可以解决上边提到的内存可见性问题,使用方法就是在要进行修改的变量前加上volatile,注意该关键字只能使用在类的数据成员变量前。
实例
这个代码演示了内存可见性的问题,我们期望的结果是通过t1线程和t2线程并发执行,当线程t2对变量进行修改后,线程t1就立即执行完毕。
package Boke;
import java.util.Scanner;
public class See {
//用两个线程实现出内存可见性线程安全问题
static int cout=0;
public static void main(String[] args) throws InterruptedException {
//线程t1负责对变量的读和判断
Thread t1=new Thread(()->{
System.out.println("cout==0,t1开始");
//此处编译器已对重复读取的指令进行优化(只读第一次)
while(cout==0){
//让编译器产生优化
}
System.out.println("cout!=0,t1结束");
});
//线程t2负责对t1读取判断的变量进行修改,控制线程t1退出
Thread t2=new Thread(()->{
System.out.println("t2开始");
Scanner scanner=new Scanner(System.in);
System.out.println("请输入一个非零值结束线程t1");
cout=scanner.nextInt();
System.out.println("t2结束");
});
t1.start();
t2.start();
t1.join();
t2.join();
}
}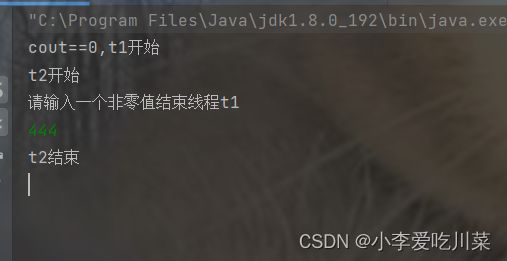
可得到的实际情况是当修改了变量值为非0时,线程t1并没有结束,此时因为编译器优化而产生了线程安全问题(详情请看文章开头介绍),此时我们就可以通过volatile关键字对阻止编译器的这种优化,也就是给这个变量加上了"内存屏障"(二进制指令),JVM在读取这个这个变量时,由于内存屏障,那这个变量就会每次都从内存中读取。
添加volatile后
package Boke;
import java.util.Scanner;
public class See {
//用两个线程实现出内存可见性线程安全问题
//此处使用volatile对成员变量进行修饰,防止编译器优化
volatile static int cout=0;
public static void main(String[] args) throws InterruptedException {
// int a=0;
//线程t1负责对变量的读和判断
Thread t1=new Thread(()->{
System.out.println("cout==0,t1开始");
//此处编译器已对重复读取的指令进行优化(只读第一次)
while(cout==0){
//让编译器产生优化
}
System.out.println("cout!=0,t1结束");
});
//线程t2负责对t1读取判断的变量进行修改,控制线程t1退出
Thread t2=new Thread(()->{
System.out.println("t2开始");
Scanner scanner=new Scanner(System.in);
System.out.println("请输入一个非零值结束线程t1");
cout=scanner.nextInt();
System.out.println("t2结束");
});
t1.start();
t2.start();
t1.join();
t2.join();
}
}
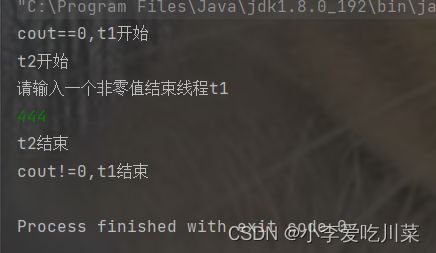
如图加上volatile关键字之后,内存可见性问题得到解决,但其实解决上述代码的内存可见性问题并不是一定要使用volatile关键字,因为这里编译器优化的原因是t1中循环的速度过快,如果适当在循环中加上一些代码减慢循环的速度,那其实也是能避免这种优化行为的,但是实际开中我们并不能确定编译器是否会对我们的代码进行优化,所以一般还是加上volatile最为保险。
5.synchronized与volatile区别
1.synchronized功能:可以保证操作的是原子的,也可以保证内存可见性,也可避免指令重排序。
2.volatile功能:能保证内存可见性和避免指令重排序,但不能保证操作是原子的,。
3.synchronized既能保证操作原子性又能保证内存可见性也可避免指令重排序。,而volatile不能保证操作原子
注意
即使看上去synchronized好像是个"宝贝",它能解决volatile能解决的和不能解决的问题,但实际上,我们在写代码的过程中,因避免一股脑的使用synchronized,因为synchronized是会导致线程阻塞等待的,而正是在这个阻塞过程中,你并不能预测会发生些什么,且当线程再次唤醒时,也不能具体把握时间,造成不必要的时间和cpu资源浪费,可以这样说,一旦盲目的使用synchronized那可以说是与"高性能"没干系了,而我们volatile的优点正是不会使线程进入阻塞等待。
希望以上知识能对你有帮助
