Linux基础指令(三)
目录
- 前言
- 1. echo 指令
-
- 1.1 输出重定向
- 1.2 追加重定向
- 1.3 输入重定向
- 1.4 拓展话题
- 2. more & less 指令
-
- 2.1 more
- 2.2 less
- 3. head & tail 指令
-
- 3.1 head
- 3.2 tail
- 3.3 管道 | 指令
- 3.4 拓展:wc 指令
- 结语:
前言
欢迎各位伙伴来到学习 Linux 指令的 第三天!!!
在上一篇文章 Linux基本指令(二) 当中,我们学会了通过 rmdir 或者是 rm 指令 去删除我们所创建的目录 和 普通文件,然后我们又学习了 cp 拷贝 和 mv 移动 目录 或 普通文件,最后学习了 cat 指令的 简单使用 及其作用。
随着不断的学习,我们学习的指令难度也会逐步上升,同时会慢慢的涉及到一些系统层面的概念性理解话题了。但是为了不影响我们整体的文章类别,我都将这些额外的 关于系统层面的 概念性话题 单独分开了。
我的建议是,有余力的伙伴们,可以去看看。
OK,废话不多说,我们开启今天的学习,
今天我们要学习的是……
1. echo 指令
echo:将数据输出打印到屏幕上

// 其中的 ” > “ ,我们称之为 输出重定向! file.txt 为目标文件
[outlier@localhost test]$ echo "hello,linux" > file.txt
OK,我们先说几个结论:
1、如果目标文件不存在,会自动创建,如果存在,则会直接访问该目标文件
2、访问
a、输出重定向(从文件的开始,覆盖式的写入)
b、追加重定向(从文件的结尾开始,追加式的写入)
而这两者的本质,都是写入!!
上述实操现象: echo 默认是将数据输出打印到屏幕上,
而输出重定向到目标文件之后,我们看到,“hello,linux” 没有被显示到屏幕上,而是被写入到了该目标文件!!
1.1 输出重定向
所以什么是输出重定向?
输出重定向就是将本该输出打印到屏幕的数据,从指定的文件的开始 输出写入到该文件中!!

我们可以看到,输出重定向,每次都是从文件的开始,进行覆盖式的写入,文件中的上一次的数据也就不存在了
1.2 追加重定向

我们可以看到,追加重定向,并不会覆盖掉上一次的数据,而是在上一次的结尾,继续追加写入新的数据。
1.3 输入重定向
再讲输出重定向之前呢,我们再先来看一个指令 – cat。
有人要说啦!cat 指令,我们之前不是已经学习过了吗,怎么又要看它!!!
==》
没错,我们之前确实学习过了。但是今天,我们要将其代入到我们的新内容当中,再次感悟 cat 指令的功能!!!
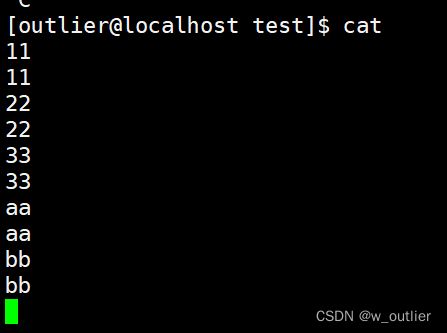
我们可以看到的是,当我们 cat 不带任何选项的时候,我们输入什么,就马上给我们输出打印在屏幕上了。
我们输入的时候,是从哪里输入的呢?? —— 键盘 ?
cat 读取输入又是从哪里读取的呢?? —— 还是键盘,也可以是缓冲区 ?
那… cat 打印的数据又是到了哪里去了呢?? —— 显示器?
对于上述的这些问题,我们都保留着一个疑惑。那就让我们继续往下看,慢慢探索!

结合上面给出的问题的答案,那如果说,cat 就是从键盘 或者 缓冲区读取的,那 cat 文件 又怎么会把文件的数据打印出来呢???
大家是不是突然觉得,被你这么一问,那我之前学到的 cat 指令,不就是显示目标文件的内容吗??!! 现在突然好像不知道 cat 它是干什么的了。
莫慌,听我慢慢道来。通过上面的实验,cat 不带选项,又可以从键盘输入,然后马上就输出到显示器当中,而带了目标文件,则是将目标文件的内容输出到显示器中。
==》
那我们是不是可以这样理解,cat 本来是从键盘读取输入,但也可以改成从 某一特定目标文件读取输入呢?
==》
答案是:没错!cat 就是可以从键盘读取,也可以改为成从文件读取数据!!!
那我们再来看一条指令

有人就不解了,问道!这又是怎么回事呢?? 怎么加了一个 < ,还能输出呢? 这个 < 号,又是个什么鬼??!
OK,我们告诉大家结论
// 我们将其中的 ’ < ‘ , 称之为 ”输入重定向“ !
cat < file.txt
那有人又要问了,哎哎哎,你这不是脱裤子放屁吗?我明明就可以直接 cat file 输出文件的内容,我为什么要再加一个 < 呢???
嗯……!!你这么说,好像也有道理??!!
所以 cat file.txt 和 cat < file.txt 到底有什么不同呢????
ok,那我们就来讲讲所谓 “输入重定向” 其中的奥秘。
其实,它们两个的本质都是一样的,cat 本来是从键盘里读取数据的,但是现在不从键盘读了,转而从指定的文件读取数据,然后,输出打印到屏幕上!
而不同点就在于:
a、cat file.txt 这里的cat,大家可以理解为,它就类似 c语言当中的,先把文件打开,调用类似 fread 这样一个功能的函数,将文件的数据读取出来,然后再打印!
b、cat < file.txt 这里的 cat,可以大概理解为,它底层做的是,它不打开文件了,然后让类似 指向键盘的指针 或者其它某种方式,指向对应文件,进而完成重定向之后,直接打印
OK,我们赶紧总结一下:所以!输入重定向就是,本来应该在键盘读取的内容,变成从文件中读取!!
然后我们在来看几个案例,强化对输入重定项 和 输出重定向的 理解。
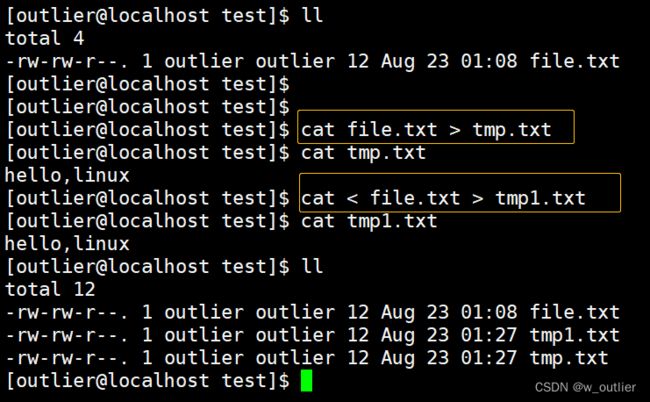
cat file.txt > tmp.txt
cat 本来应该在键盘读取内容变为从 file 文件中读取,又本应该读取完输出打印在屏幕上,变为输出在 tmp 的文件中
(输入重定向) (输出重定向)
cat < file.txt > tmp1.txt
与上面的本质是一样的,只不过输入重定向的 实现方式 不同而已
OK,那我们赶紧总结一下:
< # 就是输出重定向
<< # 就是追加重定向
> # 就是输入重定向
1.4 拓展话题
上述指令,我们讲到了键盘、显示器、还有普通文件,大家都知道,键盘是属于程序的标准输入,而显示器是标准输出。讲到这里,我将抛出一个理论:
Linux下,一切皆文件!!
讲到这里,可能有人要说了,哎哎哎,那键盘、显示器,这哪是文件呐,你这不胡扯?!
关于这个理念的理解,我就不在这里进行说明了,有兴趣的伙伴们,可以看看 Linux下,一切皆文件 这篇文章。
2. more & less 指令
2.1 more
在讲 more 指令时,我们先做好准备工作,我们先将一万行的文本信息 输出重定向到 file文件当中
# 这条指令大家知道这么用就好了
[outlier@localhost ~]$ count=0; while [ $count -le 10000 ]; do echo "hello linux ${count}"; let count++; done > file.txt
此时 file文件当中就有一万行的文本信息了,那么如果此时,我想要将这一万行显示出来,除了用 cat file
还能用什么呢???
[outlier@localhost ~]$ more file.txt #这里就不做演示了
需要注意的这个more 指令呢,它是全屏输出的,也就是屏幕显示满了,它就不显示了,然后我们可以通化 ”回车“ 键来让它继续显示下一行,按 q 即可退出。另外,more 指令呢,是不支持上下翻阅呢,也就是说,往下翻找查阅之后呢,也就不能够往上回翻了。
more指令呢,其实实际生活场景,我们用的比较少,它主要是用于需要逐行阅读的场景下使用。
那有人要问啦!那我不想要全部显示出来,我就想要显示前面的10行 20行,能不能呢?? —— 当然能!
[outlier@localhost ~]$ more -n file.txt # 显示文件的 前n行 内容(n为一个明确的正整数)

2.2 less
less,其实跟 more,它是两个功能基本一样的工具,都是用于查看文件的。
唯一与more不同的两点就是,more 往下翻阅之后,不能往回翻,而 less 可以!!
另外,less 不支持 指定行数显示!!
所以呢,平常的使用中,我们也是更加推荐使用 less,没有为什么,因为它比 more 好用!!
通过 less 查看文本之后呢,我可以也可以通过 / 输入指定信息,less就会在文件当中查找具备该信息的内容

3. head & tail 指令
3.1 head
还是跟上面同样的场景,有一个 file 文件,里面有 一万行的 文本信息,现在我要提取它的前10行,或者前20行,我除了 more -n 的方法,还有吗???
[outlier@localhost ~]$ head file.txt
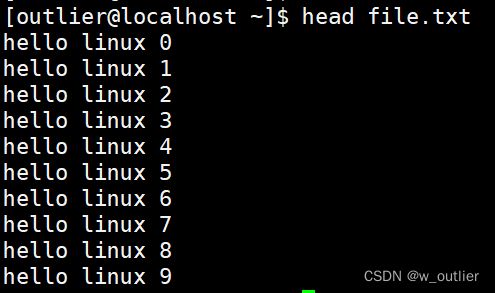
我们看到了,head 不带 任何 选项,它就是默认提取文本中的前10行信息 然后输出到显示器上!!!
那我们是不是也可以通过 -n 选项来达到提取指定行数的信息呢?? —— 没错,可以!
[outlier@localhost ~]$ head -5 file.txt # 从一个文件中 提取指定行数的信息

3.2 tail
那有人又要问啦!! 那我现在不想要前 10 行,我想要倒数10行,能不能办到?? —— 没问题!
[outlier@localhost ~]$ tail file.txt

我们可以看到,tail,它也是默认提取 10 行内容,只不过是倒数的10行
[outlier@localhost ~]$ tail -5 file.txt
// tail 也支持指定行数进行提取,同样的倒数的 n 行信息

3.3 管道 | 指令
那如果此时,我要单独提取 [999,1009] 这一段编号内容的信息呢?? 能不能办到??! —— 能!
a、 文件中的信息编号是从0 - 10000 的,一共10001行,那你现在要编号 999 - 1009,好嘛,那我刚刚才学到了 head指令,就是将指定行数提取出来嘛,那我能不能这样子??我先用 head 将前面的 1010 行提取出来,然后输出重定向到一个临时文件当中!! 再用 tail 取文件倒数 11行,那我不就把 [999 -1009] 这段编号的文本信息拿到了??!!
ok,我们马上实操一下!

实操结果,我很满意,因为跟我想的一模一样!!
那看到这,有人又要说啦!哎哎哎,你这方法好像也不太高效啊?还要创建一个第三方临时文件。
那有人又说啦!临时文件有什么了不起,能慢到哪里去呢??
那也确实不高效,假设文件中是十亿行数据呢?我要提取到临时文件,那是不是要读盘,再往磁盘上写呢??
那……
还有没有其他方法呢?? —— 当然有!
b、那就是通过 管道 来实现!
那什么是管道呢?? —— 简单理解就是,类似天然气管道,石油管道,而不管是什么管道,都是用来传输资源的!!(天然气是资源吧? 石油也是资源的一种吧?)
所以计算机当中的管道 | ,也是一种传输资源的方式!! 那计算机的资源是什么呢??? —— 数据!
所以计算机的的管道,就是用来传输数据的!!!
还记得我们刚刚的问题吗?在一个一万行的文本中,提取 [999,1009]编号的 文本信息
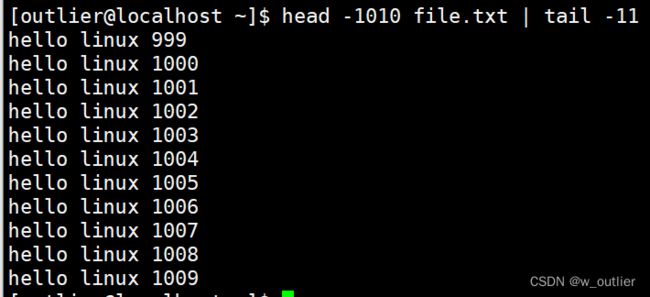
不需要创建第三方临时文件,也就不需要消耗磁盘的读写了。这就是管道的用处!!
有了管道,就可以连接多条命令,进而就可以批量化、流水化的处理数据了。head -1010 file.txt | tail -11 以这条指令为例,head处理完,就将结果交给管道,而tail不再从键盘 或者 文件中读取数据,而是从管道中读取
接下来,再通过一张图解,帮助大家更深刻的理解管道的概念!!

3.4 拓展:wc 指令
wc 就是统计文本行的个数
这也是管道的一个用处,先将 文本中的 1010行 提取输出到管道文件中,再由 tail 从管道中提取倒数 11 行,再将 tail 提取的结果,输出到管道文件中,然后由 wc 统计 最终提取结果的 文本行的个数
head -1010 file.txt | tail -11 | wc -l

结语:
OK,本章的基本指令就讲到这。如果能给你带来一定的帮助,或者是收获,我很开心。
同时,觉得对你有帮助的伙伴们,也可以 点赞 + 收藏⭐️ + 关注➕ 支持一下!
感谢各位观看!!