LLM(一)| 百川智能baichuan7B、13B、53B以及baichuan2总结
之前在文章baichuan-53B VS ChatGLM-6B对比中做过百川大模型53B和ChatGLM 6B模型的效果对比,由于百川大模型的内测模型是53B,因此本次对比参数量差异较大,但仍然可以看到两个模型的效果。百川大模型在benchmark上有超越ChatGLM和LLaMA的迹象,尤其是在中文任务上的表现,下面分别对7B、13B和53B模型进行简单总结:

一、baichuan-7B
2023年6月15日,百川智能发布了baichuan-7B,它基于 Transformer 结构,在大约1.2万亿 tokens 上训练的70亿参数模型,支持中英双语,上下文窗口长度为4096。
项目地址:https://github.com/baichuan-inc/baichuan-7B
预训练模型:https://huggingface.co/baichuan-inc/baichuan-7B
modelscope:https://modelscope.cn/models/baichuan-inc/baichuan-7B/
数据
-
原始数据包括开源的中英文数据和自行抓取的中文互联网数据,以及部分高质量知识性数据。
-
参考相关数据工作,频率和质量是数据处理环节重点考虑的两个维度。我们基于启发式规则和质量模型打分,对原始数据集进行篇章和句子粒度的过滤。在全量数据上,利用局部敏感哈希方法,对篇章和句子粒度做滤重。
整体流程如下所示:
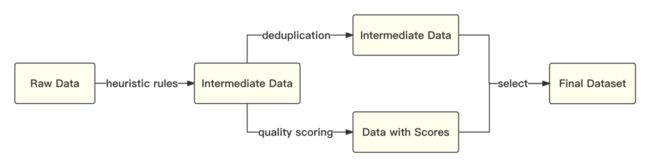
-
经过不断的调整和多轮测试,最终确认了一个在下游任务上表现最好的中英文配比。
-
我们使用了一个基于自动学习的数据权重策略,对不同类别的数据进行配比。
训练稳定性和吞吐
在原本的 LLaMA 框架上进行诸多修改以提升训练时的吞吐,具体包括:
-
算子优化技术:采用更高效算子,如 Flash-Attention,NVIDIA apex 的 RMSNorm 等。
-
算子切分技术:将部分计算算子进行切分,减小内存峰值。
-
混合精度技术:降低在不损失模型精度的情况下加速计算过程。
-
训练容灾技术:训练平台和训练框架联合优化,IaaS + PaaS 实现分钟级的故障定位和任务恢复。
-
通信优化技术,具体包括:
-
采用拓扑感知的集合通信算法,避免网络拥塞问题,提高通信效率。
-
根据卡数自适应设置 bucket size,提高带宽利用率。
-
根据模型和集群环境,调优通信原语的触发时机,从而将计算和通信重叠。
-
基于上述的几个优化技术,我们在千卡 A800 显卡上达到了 7B 模型 182 TFLOPS 的吞吐,GPU 峰值算力利用率高达 58.3%。
最终的loss如下图:

二、baichuan-13B
2023年7月11日,百川智能正式发布130亿参数通用大语言模型(Baichuan-13B-Base)。并且官方对此的评价是:性能最强的中英文百亿参数量开源模型。
项目地址:https://github.com/Baichuan-inc/Baichuan-13B
预训练模型:https://huggingface.co/baichuan-inc/Baichuan-13B-Base
对话模型:https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
Model Scope:https://modelscope.cn/models/Baichuan-inc/Baichuan-13B-Chat/summary
Baichuan-13B 有如下几个特点:
-
更大尺寸、更多数据:Baichuan-13B 在 Baichuan-7B 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096;
-
同时开源预训练和对齐模型:预训练模型是适用开发者的『 基座 』,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源我们同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署;
-
更高效的推理:为了支持更广大用户的使用,同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上;
-
开源免费可商用:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用;
2.1 推理和部署
2.1.1 GPU直接部署
安装环境
pip install -r requirements.txt方法一:Python代码方式
>>> import torch>>> from transformers import AutoModelForCausalLM, AutoTokenizer>>> from transformers.generation.utils import GenerationConfig>>> tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-13B-Chat", use_fast=False, trust_remote_code=True)>>> model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)>>> model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan-13B-Chat")>>> messages = []>>> messages.append({"role": "user", "content": "世界上第二高的山峰是哪座"})>>> response = model.chat(tokenizer, messages)>>> print(response)乔戈里峰。世界第二高峰———乔戈里峰西方登山者称其为k2峰,海拔高度是8611米,位于喀喇昆仑山脉的中巴边境上
模型加载指定 device_map='auto',会使用所有可用显卡。如需指定使用的设备,可以使用类似 export CUDA_VISIBLE_DEVICES=0,1(使用了0、1号显卡)的方式控制。
方法二:命令行方式
python cli_demo.py方法三:web方式
依靠streamlit运行以下命令,会在本地启动一个 web 服务,把控制台给出的地址放入浏览器即可访问。
streamlit run web_demo.py2.1.2 量化部署
Baichuan-13B 支持 int8 和 int4 量化,用户只需在推理代码中简单修改两行即可实现。请注意,如果是为了节省显存而进行量化,应加载原始精度模型到 CPU 后再开始量化;避免在from_pretrained时添加device_map='auto'或者其它会导致把原始精度模型直接加载到 GPU 的行为的参数。
int8量化
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", torch_dtype=torch.float16, trust_remote_code=True)model = model.quantize(8).cuda()
int4量化
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", torch_dtype=torch.float16, trust_remote_code=True)model = model.quantize(4).cuda()
量化前后占用显存情况如下:
| Precision | GPU Mem (GB) |
|---|---|
| bf16 / fp16 | 26.0 |
| int8 | 15.8 |
| int4 | 9.7 |
量化后在各个 benchmark 上的结果和原始版本对比如下:
| Model 5-shot | C-Eval | MMLU | CMMLU |
|---|---|---|---|
| Baichuan-13B-Base | 52.4 | 51.6 | 55.3 |
| Baichuan-13B-Base-int8 | 51.2 | 49.9 | 54.5 |
| Baichuan-13B-Base-int4 | 47.6 | 46.0 | 51.0 |
2.1.3 CPU部署
使用CPU进行推理大概需要 60GB 内存
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", torch_dtype=torch.float32, trust_remote_code=True)2.2 微调
开发者可以对 Baichuan-13B-Base 或 Baichuan-13B-Chat 进行微调使用。团队测试了与 Baichuan-13B 兼容的微调工具 LLaMA Efficient Tuning,并给出全量微调和 LoRA微调的两种示范。
输入数据为放置在项目data目录下的 json 文件,用--dataset选项指定(参考下面示例),多个输入文件用,分隔。json 文件示例格式和字段说明如下:
[{"instruction": "What are the three primary colors?","input": "","output": "The three primary colors are red, blue, and yellow."},....]
json 文件中存储一个列表,列表的每个元素是一个 sample。其中instruction代表用户输入,input是可选项,如果开发者同时指定了instruction和input,会把二者用\n连接起来代表用户输入;output代表期望的模型输出。
2.2.1 全量微调
微调环境:8 * Nvidia A100 80 GB + deepspeed
deepspeed --num_gpus=8 src/train_bash.py \--stage sft \--model_name_or_path baichuan-inc/Baichuan-13B-Base \--do_train \--dataset alpaca_gpt4_en,alpaca_gpt4_zh \--finetuning_type full \--output_dir path_to_your_sft_checkpoint \--overwrite_cache \--per_device_train_batch_size 4 \--per_device_eval_batch_size 4 \--gradient_accumulation_steps 8 \--preprocessing_num_workers 16 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 100 \--eval_steps 100 \--learning_rate 5e-5 \--max_grad_norm 0.5 \--num_train_epochs 2.0 \--dev_ratio 0.01 \--evaluation_strategy steps \--load_best_model_at_end \--plot_loss \--fp16 \--deepspeed deepspeed.json
deep_speed.json 配置示例:
{"train_micro_batch_size_per_gpu": "auto","zero_allow_untested_optimizer": true,"fp16": {"enabled": "auto","loss_scale": 0,"initial_scale_power": 16,"loss_scale_window": 1000,"hysteresis": 2,"min_loss_scale": 1},"zero_optimization": {"stage": 2,"allgather_partitions": true,"allgather_bucket_size": 5e8,"overlap_comm": false,"reduce_scatter": true,"reduce_bucket_size": 5e8,"contiguous_gradients" : true}}
2.2.2 LoRA微调
微调环境:1 * Nvidia A100 80 GB
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \--stage sft \--model_name_or_path baichuan-inc/Baichuan-13B-Base \--do_train \--dataset alpaca_gpt4_en,alpaca_gpt4_zh \--finetuning_type lora \--lora_rank 8 \--lora_target W_pack \--output_dir path_to_your_sft_checkpoint \--overwrite_cache \--per_device_train_batch_size 4 \--per_device_eval_batch_size 4 \--gradient_accumulation_steps 8 \--preprocessing_num_workers 16 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 100 \--eval_steps 100 \--learning_rate 5e-5 \--max_grad_norm 0.5 \--num_train_epochs 2.0 \--dev_ratio 0.01 \--evaluation_strategy steps \--load_best_model_at_end \--plot_loss \--fp16
同样还有其他微调框架可以支持微调baichuan-13B-Base模型,比如Firefly,想了解的读者可以参考文章微调百川Baichuan-13B保姆式教程,手把手教你训练百亿大模型。
三、baichuan-53B
8 月 8 日,百川智能发布新一代大模型 Baichuan-53B。不同于此前发布的 7B 和 13B 模型,Baichuan-53B 并没有走开源路线。Baichuan-53B 支持中英双语,在知识性上表现优异,相对此前两款模型有更好的表现,擅长知识问答、文本创作等领域。
百川强调了 Baichuan-53B 的三个技术优势:预训练数据、搜索增强和对齐能力,其中前两者与百川团队中丰富的搜索引擎经验有较强相关性。
预训练数据
预训练阶段,王小川表示,此前团队做搜索引擎的经验,让百川能够又快又好地完成前期数据积累,这也是百川此前两款开源模型能够迅速推出的原因之一。
「团队背景做了很多年的搜索,所以整个中文互联网里哪里有好的数据,我们团队是最清楚的,怎么把这些数据收集回来,质量做好,识别出来,我们以前有很强的积累和方法论。」百川智能联合创始人、大语言模型技术负责人陈炜鹏说道。
-
百川希望构建一个全面的世界知识体系,覆盖各个领域和学科的知识,通过整合各类信息源,确保文化、科学、技术等方面广泛的知识覆盖;
-
目前百川已经建立了一套系统的数据质量体系,包括低质、优质、类别等,确保整个预训练过程中维持高标准的数据质量,以让数据为最终模型训练的目标服务;
-
为保证数据的多样性并有效处理重复信息,百川设计了一个多粒度的大规模聚类系统。通过使用先进的聚类算法和方法,识别和整合相似或相关的数据,为去重、采样提供支撑;
-
百川还开发了一种细粒度的自动化匹配算法,自动配比各类任务,例如课程学习。从而实现个性化的模型学习,使预训练数据能够更精确地匹配用户需求;
搜索增强
王小川始终认为,过去 20 年搜索技术的积累是百川在大模型领域的优势。初期,这样的观点在行业里是一种「非共识」。
这次 Baichuan-53B 的开发过程中,百川应用了更多搜索相关的技术,实现模型优化与改进。
-
动态响应策略,依赖 Prompt,将指令任务细化为 16 个独立类别,覆盖各种用户指令的场景。
-
智能化搜索词生成,通过对问答样本进行精细化的人工标注,捕捉和理解用户多元化的志林需求。
-
高质量搜索结果筛选,百川构建了一个搜索结果相关性模型,对从搜索内容和知识库中获取的信息进行相关性频分,从而筛选出高质量的搜索引用内容,减少在知识抽取阶段引入的无关、低质量的信息。
-
回答结果的搜索增强,RLHF,让 Baichuan 大模型参照搜索结果,针对用户请求生成高价值且具有实时性的回答。
在采访中,陈炜鹏表示,不同于 ChatGPT 和 Bing 用插件将搜索和模型连接的方式,百川希望大模型和搜索引擎在模型层面有更强的交互。
「搜索和模型的结合从非常底层的地方就开始了。」王小川总结说。
四、baichuan2
9 月 6 日下午的发布会上,百川智能宣布正式开源微调后的 Baichuan-2 大模型。

这是百川自 8 月发布 Baichuan-53B 大模型后的又一次新发布。本次开源的模型包括 Baichuan2-7B、Baichuan2-13B、Baichuan2-13B-Chat 与其 4bit 量化版本,并且均为免费可商用。
除了模型的全面公开之外,百川智能此次还开源了模型训练的 Check Point,并公开了 Baichuan 2 技术报告,详细介绍了新模型的训练细节。百川智能创始人兼 CEO 王小川表示,希望此举能够帮助大模型学术机构、开发者和企业用户深入了解大模型的训练过程,更好地推动大模型学术研究和社区的技术发展。
-
Baichuan 2 大模型开原链接:https://github.com/baichuan-inc/Baichuan2
-
技术报告:https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf
Baichuan2-13B-Base 相比上一代 13B 模型,数学能力提升 49%,代码能力提升 46%,安全能力提升 37%,逻辑推理能力提升 25%,语义理解能力提升 15%。
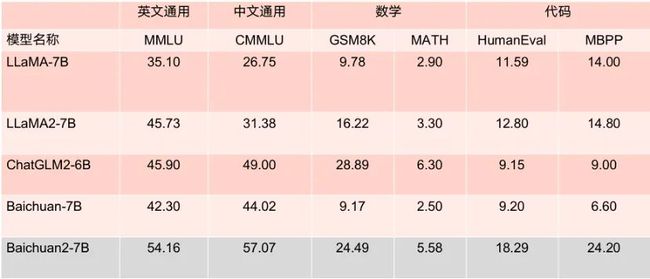
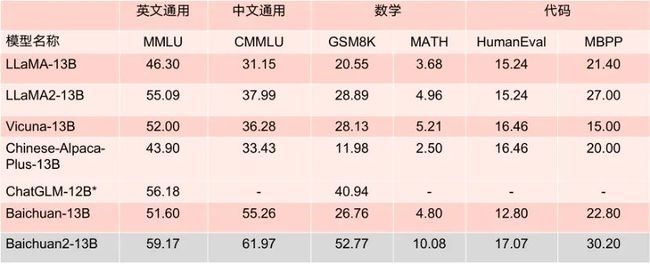
参考文献:
[1] https://mp.weixin.qq.com/s/DY0ZyV6-hVS8VN803K8H4w
[2] https://github.com/hiyouga/LLaMA-Efficient-Tuning
[3] https://mp.weixin.qq.com/s/gkom1eKDnXHzYf7JHG_gSQ
[4] https://mp.weixin.qq.com/s/ivMsRkN8RBq1V6sGJNzrnw