LeetCode动态规划题解
动态规划
- 基础理论
- 基础题目
-
- 746. 使用最小花费爬楼梯
- 62. 不同路径
- 63. 不同路径 II
- 面试题 08.02. 迷路的机器人(☆☆)
- 剑指 Offer 13. 机器人的运动范围
- 1293. 网格中的最短路径
- 343. 整数拆分
- 96. 不同的二叉搜索树
- 背包问题
-
- 01背包问题:
- 416. 分割等和子集
- 1049. 最后一块石头的重量 II
- 494. 目标和
- 474. 一和零
- 完全背包:
- 518. 零钱兑换 II(组合问题,先遍历物品后遍历背包)
- 377. 组合总和 Ⅳ(完全背包排列问题,先遍历背包后遍历物品)
- 322. 零钱兑换
- 279. 完全平方数
- 139. 单词拆分(☆☆)
- 打家劫舍
-
- 198. 打家劫舍
- 213. 打家劫舍 II(☆)
- 337. 打家劫舍 III(☆☆☆)
- 股票问题
-
- 121. 买卖股票的最佳时机
- 122. 买卖股票的最佳时机 II
- 123. 买卖股票的最佳时机 III(☆☆)
- 188. 买卖股票的最佳时机 IV(☆☆)
- 309. 最佳买卖股票时机含冷冻期(☆☆☆)
- 714. 买卖股票的最佳时机含手续费
- 子序列问题
-
- 300. 最长递增子序列
- 354. 俄罗斯套娃信封问题
- 674. 最长连续递增序列
- 673. 最长递增子序列的个数(☆☆☆)
- 718. 最长重复子数组
- 1143. 最长公共子序列
- 1035. 不相交的线
- 53. 最大子序和
- 392. 判断子序列
- 115. 不同的子序列(☆☆☆)
- 583. 两个字符串的删除操作(☆☆)
- 72. 编辑距离(☆☆☆)
- 647. 回文子串(☆☆☆)
- 516. 最长回文子序列(☆☆)
- 5. 最长回文子串(☆)
- 1147. 段式回文
- 差值问题
-
- 1218. 最长定差子序列(☆☆)
- 1027. 最长等差数列(☆)
- 413. 等差数列划分(☆)
- 1262. 可被三整除的最大和(☆☆)
- 矩阵问题
-
- 289. 生命游戏
- 面试题 17.24. 最大子矩阵
- 面试问题:
-
- 486. 预测赢家(☆☆☆)
- 剑指 Offer 13. 机器人的运动范围
- 940. 不同的子序列 II
- 983. 最低票价
- 730. 统计不同回文子序列
- 283. 移动零
- 73. 矩阵置零(☆☆)
- 384. 打乱数组
- 134. 加油站(贪心算法)
- 11. 盛最多水的容器(贪心☆☆)
- 55. 跳跃游戏
- 45. 跳跃游戏 II
- 200. 岛屿数量(DFS☆)
- 74. 搜索二维矩阵(二分、BST☆☆)
- 剑指 Offer 04. 二维数组中的查找(只能BST)
- 79. 单词搜索(回溯算法)
- 334. 递增的三元子序列
- 146. LRU 缓存机制(☆☆☆☆)
- 23. 合并K个升序链表(☆☆☆)
- 41. 缺失的第一个正数(☆☆☆)
- 面试题 17.19. 消失的两个数字
- 4. 寻找两个正序数组的中位数(☆☆☆)
- 49. 字母异位词分组
- 295. 数据流的中位数(☆☆☆)
- 149. 直线上最多的点数(☆☆☆)
- 208. 实现 Trie (前缀树)(☆☆☆)
- 974. 和可被 K 整除的子数组
- 560. 和为K的子数组
- 剑指 Offer 49. 丑数
- 剑指 Offer 44. 数字序列中某一位的数字
- 剑指 Offer 43. 1~n 整数中 1 出现的次数
- 457. 环形数组是否存在循环
- 992. K 个不同整数的子数组
- 剑指 Offer 35. 复杂链表的复制
- 48. 旋转图像
- 1654. 到家的最少跳跃次数
基础理论
对于动态规划:
• 确定dp数组(dp table)以及下标的含义
• 确定递推公式
• dp数组如何初始化
• 确定遍历顺序
• 举例推导dp数组
基础题目
746. 使用最小花费爬楼梯
数组的每个下标作为一个阶梯,第 i 个阶梯对应着一个非负数的体力花费值 cost[i](下标从 0 开始)。
每当你爬上一个阶梯你都要花费对应的体力值,一旦支付了相应的体力值,你就可以选择向上爬一个阶梯或者爬两个阶梯。
请你找出达到楼层顶部的最低花费。在开始时,你可以选择从下标为 0 或 1 的元素作为初始阶梯。
代码:
class Solution {
public:
int minCostClimbingStairs(vector<int>& cost) {
//dp[i]:登上第i阶台阶花费最小的体力值
//确定递推公式:
//数组如何初始化
//确定遍历顺序
vector<int> dp(2, 0);
dp[0] = cost[0];
dp[1] = cost[1];
for(int i = 2; i < cost.size(); i++)
{
int minCost = min(dp[0], dp[1])+cost[i];
dp[0] = dp[1];
dp[1] = minCost;
}
for(int i = 0; i < dp.size(); i++) cout<<dp[i]<<" ";
return min(dp[0], dp[1]);
}
};
思考如何每次可以跨m阶台阶如何使cost最小呢?
class Solution {
public:
int climbStairs(int n) {
vector<int> dp(n + 1, 0);
dp[0] = 1;
for (int i = 1; i <= n; i++) { // 遍历背包
for (int j = 1; j <= m; j++) { // 遍历物品
if (i - j >= 0) dp[i] += dp[i - j];
}
}
return dp[n];
}
};
62. 不同路径
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
63. 不同路径 II
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
两道题基本一致,因为只能从右或者下走,所以其实就是这两个之和
初始化很关键
代码:
class Solution {
public:
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
//dp[i][j]:达到i,j为右下角时的总共有多少条路径
//递推公式:dp[i][j] = dp[i-1][j] + dp[i][j-1]
//初始化:dp[0][*] = dp[*][0] = 1;
int m = obstacleGrid.size();
int n = obstacleGrid[0].size();
vector<vector<int>> dp(m, vector<int>(n, 0));
for(int i = 0; i < m; i++)
{
if(obstacleGrid[i][0] == 1) break;
dp[i][0] = 1;
}
for(int j = 0; j < n; j++)
{
if(obstacleGrid[0][j] == 1) break;
dp[0][j] = 1;
}
for(int i = 1; i < m; i++)
{
for(int j = 1; j < n; j++)
{
if(obstacleGrid[i][j] == 1) continue;
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
return dp[m-1][n-1];
}
};
面试题 08.02. 迷路的机器人(☆☆)
设想有个机器人坐在一个网格的左上角,网格 r 行 c 列。机器人只能向下或向右移动,但不能走到一些被禁止的网格(有障碍物)。设计一种算法,寻找机器人从左上角移动到右下角的路径。

网格中的障碍物和空位置分别用 1 和 0 来表示。
返回一条可行的路径,路径由经过的网格的行号和列号组成。左上角为 0 行 0 列。如果没有可行的路径,返回空数组
思路:典型的DFS算法题
深度搜索配合剪枝,因为只有深度搜索的话,会遍历所有的可能,剪枝就是在已经发现不可能到达的点也标1
class Solution {
public:
vector<vector<int>> pathWithObstacles(vector<vector<int>>& obstacleGrid) {
result.clear();
if(dfs(obstacleGrid,0, 0)) return result;
return vector<vector<int>>();
}
private:
vector<vector<int>>result;
bool dfs(vector<vector<int>>& obstacleGrid, int m, int n)
{
if(m >= obstacleGrid.size() || n >= obstacleGrid[0].size() || obstacleGrid[m][n] == 1) return false;
result.push_back(vector<int>{m, n});
if((m == obstacleGrid.size()-1 && n == obstacleGrid[0].size()-1) || dfs(obstacleGrid, m, n+1) || dfs(obstacleGrid, m+1, n)) return true;
//不可到达
result.pop_back();
obstacleGrid[m][n] = 1;
return false;
}
};
剑指 Offer 13. 机器人的运动范围
地上有一个m行n列的方格,从坐标 [0,0] 到坐标 [m-1,n-1] 。一个机器人从坐标 [0, 0] 的格子开始移动,它每次可以向左、右、上、下移动一格(不能移动到方格外),也不能进入行坐标和列坐标的数位之和大于k的格子。例如,当k为18时,机器人能够进入方格 [35, 37] ,因为3+5+3+7=18。但它不能进入方格 [35, 38],因为3+5+3+8=19。请问该机器人能够到达多少个格子?
class Solution {
public:
int movingCount(int m, int n, int k) {
//dp[i][j]:目前到[i][j] 可以达到的最大方格
//推到公式:if(true) {if(dp[i-1][j] || dp[i+1][j] || dp[i][j-1] || dp[i][j+1]) dp[i][j] = 1}
//初始化:
vector<vector<int>> dp(m, vector<int>(n,0));
int res = 1;
//初始化
if(!k) return 1;
dp[0][0] = 1;
for(int i = 0; i < m; i++) {
for(int j = 0; j < n; j++) {
if((i==0 && j ==0) || isVaild(i, j, k) == false) continue;
if(i-1 >= 0) dp[i][j] |= dp[i-1][j];
if(j-1 >= 0) dp[i][j] |= dp[i][j-1];
res += dp[i][j];
}
}
return res;
}
bool isVaild(int i, int j, int k) {
//if(i > k || j > k) return false;
int sum = 0;
while(i || j) {
sum = sum + i % 10 + j % 10;
i /= 10;
j /= 10;
}
return sum <= k;
}
};
1293. 网格中的最短路径
给你一个 m * n 的网格,其中每个单元格不是 0(空)就是 1(障碍物)。每一步,您都可以在空白单元格中上、下、左、右移动。
如果您 最多 可以消除 k 个障碍物,请找出从左上角 (0, 0) 到右下角 (m-1, n-1) 的最短路径,并返回通过该路径所需的步数。如果找不到这样的路径,则返回 -1。
struct State {
int x, y;
int r;
State(int x_, int y_, int r_) {
x = x_;
y = y_;
r = r_;
}
};
class Solution {
int dx[4] = {1, 0, -1, 0};
int dy[4] = {0, 1, 0, -1};
public:
int shortestPath(vector<vector<int>>& g, int k) {
int m = g.size(), n = g[0].size();
if(k >= m + n - 3) return m + n - 2;
vector<vector<vector<bool>>> visited(m, vector<vector<bool>>(n, vector<bool>(k + 1, 0)));
queue<State> Q;
Q.emplace(0, 0, k);
int step = 0;
while(!Q.empty()) {
int s = Q.size();
while(s--) {
auto p = Q.front();
Q.pop();
int x = p.x, y = p.y;
int r = p.r;
if(x == m - 1 && y == n - 1 && r >= 0) return step;
if(visited[x][y][r] == 1) continue;
visited[x][y][r] = 1;
for(int k = 0; k < 4; k++) {
if(x + dx[k] >= 0 && x + dx[k] < m && y + dy[k] >= 0 && y + dy[k] < n) {
if(g[x + dx[k]][y + dy[k]] == 1 && r >= 1) Q.emplace(x + dx[k], y + dy[k], r - 1);
else if(g[x + dx[k]][y + dy[k]] == 0)
Q.emplace(x + dx[k], y + dy[k], r);
}
}
}
step++;
}
return -1;
}
};
343. 整数拆分
给定一个正整数 n,将其拆分为至少两个正整数的和,并使这些整数的乘积最大化。 返回你可以获得的最大乘积。
如果划分为两个之和可以方便比较,但是如果划分为多个的话,那怎么算?事实上,因为我们是递归的,我们前面计算过的dp[i-j]已经是最大值,没必要进行拆分,因为递归公式dp[i] = max(j*(i-j), j*dp[i-j])
代码:
class Solution {
public:
int integerBreak(int n) {
//dp[i] : 数值为i时可以得到的最大乘积dp[i]
//递推公式:dp[i] = max(j*(i-j), j*dp[i-j])其中j * (i-j)实际上是2个数的乘积,j * dp[i-j]是三个数以上的乘积
//初始化
vector<int> dp(n+1, 0);
dp[0] = 0; dp[1] = 1;
for(int i = 2; i <= n; i++)
{
for(int j = 0; j < i; j++)
{
int tmp = max(j*(i-j), j*dp[i-j]);
dp[i] = max(tmp, dp[i]);
}
}
return dp[n];
}
};
96. 不同的二叉搜索树
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
元素1为头结点搜索树的数量 = 右子树有2个元素的搜索树数量 * 左子树有0个元素的搜索树数量
元素2为头结点搜索树的数量 = 右子树有1个元素的搜索树数量 * 左子树有1个元素的搜索树数量
元素3为头结点搜索树的数量 = 右子树有0个元素的搜索树数量 * 左子树有2个元素的搜索树数量
有2个元素的搜索树数量就是dp[2]。
有1个元素的搜索树数量就是dp[1]。
有0个元素的搜索树数量就是dp[0]。 递推公式:dp[i] += dp[j-1] * dp[i-j]
class Solution {
public:
int numTrees(int n) {
vector<int> dp(n+1, 0);
dp[0] = 1;
for(int i = 1; i <= n; i++)
{
for(int j = 1; j <= i; j++)
{
dp[i] += dp[j-1] * dp[i-j];
}
}
return dp[n];
}
};
背包问题
01背包问题:
有N件物品和一个最多能被重量为W 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。
1.确定dp数组以及下标的含义
对于背包问题,有一种写法, 是使用二维数组,即dp[i][j] 表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。
2.确定递推公式
对于一个物品要么不放进背包,要么放进背包两种选择
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
3.数组初始化(由递推公式进行推导,但是需要注意必须倒叙保证物品只放入一次)
// 倒叙遍历
vector<vector<int>> dp(weight.size() + 1, vector<int>(bagWeight + 1, 0));
for (int j = bagWeight; j >= weight[0]; j--) {
dp[0][j] = dp[0][j - weight[0]] + value[0]; // 初始化i为0时候的情况
}
4.确定遍历顺序
对于二维数组:先遍历背包再遍历物品或者两种相反都可以
// weight数组的大小 就是物品个数
for(int i = 1; i < weight.size(); i++) { // 遍历物品
for(int j = 0; j <= bagWeight; j++) { // 遍历背包容量
if (j < weight[i]) dp[i][j] = dp[i - 1][j]; // 这个是为了展现dp数组里元素的变化
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
// weight数组的大小 就是物品个数
for(int j = 0; j <= bagWeight; j++) { // 遍历背包容量
for(int i = 1; i < weight.size(); i++) { // 遍历物品
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
对于一维滚动数组:
初始化:dp数组在推导的时候一定是取价值最大的数,如果题目给的价值都是正整数那么非0下标都初始化为0就可以了,如果题目给的价值有负数,那么非0下标就要初始化为负无穷。
遍历顺序:
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
416. 分割等和子集
给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
只有确定了以下四点,才能套用01背包
背包的体积为sum / 2
背包要放⼊的商品(集合⾥的元素)重量为 元素的数值,价值也为元素的数值
背包如何正好装满,说明找到了总和为
sum /2 的⼦集。
背包中每⼀个元素是不可重复放⼊。
class Solution {
public:
bool canPartition(vector<int>& nums) {
int sum = accumulate(nums.begin(), nums.end(), 0);
if(sum % 2 != 0) return false;
int target = sum / 2;
//容量为j的背包,所背的物品价值最大为dp[j]
vector<int> dp(target+1, 0);
//递推公式:dp[j] = max(dp[j], dp[j-nums[i]]+nums[i]);
//初始化:dp[0] = 0
//遍历顺序
for(int i = 0; i < nums.size(); i++)
{
for(int j = target; j >= nums[i]; j--)
{
dp[j] = max(dp[j], dp[j-nums[i]] + nums[i]);
}
}
if(dp[target] == target) return true;
return false;
}
};
1049. 最后一块石头的重量 II
有一堆石头,用整数数组 stones 表示。其中 stones[i] 表示第 i 块石头的重量。
每一回合,从中选出任意两块石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x <= y。那么粉碎的可能结果如下:
如果 x == y,那么两块石头都会被完全粉碎;
如果 x != y,那么重量为 x 的石头将会完全粉碎,而重量为 y 的石头新重量为 y-x。
最后,最多只会剩下一块 石头。返回此石头 最小的可能重量 。如果没有石头剩下,就返回 0。
本题其实就是尽量让⽯头分成重量相同的两堆,相撞之后剩下的⽯头最⼩, 这样就化解成01背包问题了。
class Solution {
public:
int lastStoneWeightII(vector<int>& stones) {
int sum = accumulate(stones.begin(), stones.end(), 0);
//if(sum % 2 == 0) return 0;
int target = sum / 2;
vector<int> dp(target+1, 0);
for(int i = 0; i < stones.size(); i++)
{
for(int j = target; j >= stones[i]; j--)
{
dp[j] = max(dp[j], dp[j-stones[i]] + stones[i]);
}
}
return (sum - dp[target]) - dp[target];
}
};
494. 目标和
给你一个整数数组 nums 和一个整数 target 。
向数组中的每个整数前添加 ‘+’ 或 ‘-’ ,然后串联起所有整数,可以构造一个 表达式 :
例如,nums = [2, 1] ,可以在 2 之前添加 ‘+’ ,在 1 之前添加 ‘-’ ,然后串联起来得到表达式 “+2-1” 。
返回可以通过上述方法构造的、运算结果等于 target 的不同 表达式 的数目。

class Solution {
public:
int findTargetSumWays(vector<int>& nums, int target) {
//背包容量为j时,表达式的数目为dp[j]
//递推公式:dp[j] += dp[j-nums[i]]
//初始化:dp[0] = 1;
//遍历顺序
int sum = accumulate(nums.begin(), nums.end(), 0);
if(target > sum) return 0;//没有方案
if((sum + target) % 2 == 1) return 0;
int left = (sum + target) / 2;
vector<int> dp(left+1, 0);
dp[0] = 1;
for(int i = 0; i < nums.size(); i++)
{
for(int j = left; j >= nums[i]; j--)
{
dp[j] += dp[j-nums[i]];
}
}
return dp[left];
}
};
474. 一和零
给你一个二进制字符串数组 strs 和两个整数 m 和 n 。
请你找出并返回 strs 的最大子集的大小,该子集中 最多 有 m 个 0 和 n 个 1 。
如果 x 的所有元素也是 y 的元素,集合 x 是集合 y 的 子集 。
思路:主要是不仅仅是一维01背包,而是两个维度的背包,本质上没有什么改变,数组dp[i][j]表示的是最多有i个0和1的最大子集, 也是先遍历物品,然后遍历背包
class Solution {
public:
int findMaxForm(vector<string>& strs, int m, int n) {
//i个0、j个1的最大子集dp[i][j]
//递推公式dp[i][j] = max(dp[i][j], dp[i- zeroNum][j-oneNum]+1)
//初始化:dp[0][0] = 0;
//遍历顺序
vector<vector<int>> dp(m+1, vector<int>(n+1, 0));
for(string str : strs )//遍历物品
{
int zeroNum = 0, oneNum = 0;
for(char c : str)
{
if(c == '0') zeroNum++;
else oneNum++;
}
//遍历背包
for(int i = m; i >= zeroNum; i--)
{
for(int j = n; j >= oneNum; j--)
{
dp[i][j] = max(dp[i][j], dp[i- zeroNum][j-oneNum]+1);
}
}
}
return dp[m][n];
}
};
完全背包:
有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。
完全背包和01背包问题唯一不同的地方就是,每种物品有无限件
完全背包的遍历顺序:
01背包中二维dp数组的两个for遍历的先后循序是可以颠倒了,一维dp数组的两个for循环先后循序一定是先遍历物品,再遍历背包容量。
在完全背包中,对于一维dp数组来说,其实两个for循环嵌套顺序同样无所谓!
但是如果问装满背包有几种方式的话?那么先遍历背包还是先遍历物品就有很大区别了。
如果先遍历物品就是组合问题,先遍历背包就是排列问题
在求装满背包有⼏种⽅案的时候,认清遍历顺序是⾮常关键的。
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
for (int i = 0; i < coins.size(); i++) { // 遍历物品
for (int j = coins[i]; j <= amount; j++) { // 遍历背包容量
dp[j] += dp[j - coins[i]];
}
}
先把coin[0] 加入计算然后再把coin[5]加入计算,得到只有{coin【0】, coin【5】}e而不会出现{coin【5】, coin【0】},记录的是组合数
518. 零钱兑换 II(组合问题,先遍历物品后遍历背包)
给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。
请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。
假设每一种面额的硬币有无限个。
题目数据保证结果符合 32 位带符号整数
class Solution {
public:
int change(int amount, vector<int>& coins) {
//dp[j]:凑成总⾦额j的货币组合数为dp[j]
//递推公式:dp[j] += dp[j-coins[i]]
//初始化:dp[0] = 1;
vector<int> dp(amount+1, 0);
dp[0] = 1;
for(int i = 0; i < coins.size(); i++)//先遍历物品
{
for(int j = coins[i]; j <= amount; j++)//再遍历背包
{
dp[j] += dp[j-coins[i]];
}
}
return dp[amount];
}
};
377. 组合总和 Ⅳ(完全背包排列问题,先遍历背包后遍历物品)
给你一个由 不同 整数组成的数组 nums ,和一个目标整数 target 。请你从 nums 中找出并返回总和为 target 的元素组合的个数。
题目数据保证答案符合 32 位整数范围。
class Solution {
public:
int combinationSum4(vector<int>& nums, int target) {
//dp[j]:背包容量为j时组合的个数
//递推公式:dp[j] += dp[j-nums[i]]
//初始化:
//遍历顺序:先遍历背包后遍历物品
vector<int> dp(target+1, 0);
dp[0] = 1;
for(int j = 0; j <= target; j++)//先遍历背包
{
for(int i = 0; i < nums.size(); i++)//遍历物品
{
if(j - nums[i] >= 0 && dp[j] <= INT_MAX - dp[j-nums[i]]) dp[j] += dp[j-nums[i]];
}
}
return dp[target];
}
};
322 零钱兑换、279完全平方数 、139单词拆分都是求最小数
322. 零钱兑换
给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
你可以认为每种硬币的数量是无限的。
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
//dp[j]:背包容量为j时最小的硬币个数
//递推公式:dp[j] = min(dp[j], dp[j-coins[i]]+ 1) ;
//初始化:
//遍历顺序:先遍历物品再遍历背包
vector<int> dp(amount+1, INT_MAX);
dp[0] = 0;
for(int i = 0; i < coins.size(); i++)
{
for(int j = coins[i]; j <= amount; j++)
{
if(dp[j - coins[i]] != INT_MAX) dp[j] = min(dp[j], dp[j-coins[i]]+1);
}
}
return dp[amount] == INT_MAX? -1 : dp[amount];
}
};
279. 完全平方数
给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, …)使得它们的和等于 n。你需要让组成和的完全平方数的个数最少。
给你一个整数 n ,返回和为 n 的完全平方数的 最少数量 。
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
class Solution {
public:
int numSquares(int n) {
//dp[j]:背包容量也就是和为j的最小数量
//递推公式:dp[j] = min(dp[j], dp[j-i*i]+1)
//初始化
//遍历顺序:两个顺序都可以
vector<int> dp(n+1, INT_MAX);
dp[0] = 0;
for(int i = 1; i <= sqrt(n); i++)//遍历物品
{
for(int j = i* i; j <= n; j++)
{
if(dp[j - i*i] != INT_MAX) dp[j] = min(dp[j], dp[j-i*i]+1);
}
}
if(dp[n] == INT_MAX) return -1;
return dp[n];
}
};
139. 单词拆分(☆☆)
给定一个非空字符串 s 和一个包含非空单词的列表 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
说明:
拆分时可以重复使用字典中的单词。
你可以假设字典中没有重复的单词。
思路:字符串s就是背包,单词列表就是物品
判断一个字符串满不满足条件,对于dp[i]来说,就是判断dp[j]以及(i-j)的字符串在不在单词表中,同时记录一个set来记录单词表,提高查询速度
dp[“onetwothreefour”] = dp[“onetwothree"这一段] && 判断一下"four”
dp[“onetwothreefour”] = dp[“onetwothre"这一段] && 判断一下"efour”
只要发现一个存在,那么就变为true
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
//dp[i] : 字符串⻓度为i的话, dp[i]为true,表示可以拆分为⼀个或多个在字典中出现的单词
//if(substr(s, i, j) && dp[i] = true) dp[j] = true;
//初始化:
//遍历顺序:先遍历物品再遍历背包
unordered_set<string> set(wordDict.begin(), wordDict.end());
//for(auto c : wordDict) set.insert(c);
vector<bool> dp(s.size()+1, false);
dp[0] = true;
//获取最长字符串的长度
int maxLength = 0;
for(auto c : wordDict) maxLength = std::max(maxLength, (int)c.size());
for(int i = 1; i <= s.size(); i++)//先遍历背包
{
for(int j = max(i-maxLength, 0); j < i; j++)//先遍历物品
{
string word = s.substr(j, i-j);
if(set.find(word) != set.end() && dp[j] == true) dp[i] = true;
}
}
return dp[s.size()];
}
};
打家劫舍
198. 打家劫舍
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
思路:主要是递推公式,对于dp[i],存在两种状态,偷与不偷,偷的话就是dp[i-2] + nums[i],不偷的话就是dp[i-1]
class Solution {
public:
int rob(vector<int>& nums) {
//dp[i]:到第i个房屋所能偷到的最大金额
//递推公式:dp[i] = max(dp[i-2]+nums[i], dp[i-1])
//初始化:dp[0] = nums[0],dp[1] = max();
//遍历顺序
if(nums.size() == 1) return nums[0];
vector<int> dp(nums.size());
dp[0] = nums[0], dp[1] = max(nums[0], nums[1]);
for(int i = 2; i < nums.size(); i++)
{
dp[i] = max(dp[i-1], dp[i-2] + nums[i]);
}
return max(dp[nums.size()-2], dp.back());
}
};
213. 打家劫舍 II(☆)
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警 。
给定一个代表每个房屋存放金额的非负整数数组,计算你 在不触动警报装置的情况下 ,能够偷窃到的最高金额。
思路:对于环形数组。拆分为三种情况,一种是去掉收尾只考虑中间的,第二种考虑头部和中间(不考虑尾结点),第三种考虑尾结点和中间部分(不考虑头结点),但实际上情况2,3已经包含情况1,因此只考虑2,3即可,然后按照198求出比较
class Solution {
public:
int rob(vector<int>& nums) {
if(nums.size() == 1) return nums[0];
return max(helper(nums, 0, nums.size()-2), helper(nums, 1, nums.size()-1));
}
int helper(vector<int>& nums, int start, int end)
{
if(start == end) return nums[start];
vector<int> dp(nums.size());
dp[start] = nums[start]; dp[start+1] = max(nums[start+1],nums[start]);
for(int i = start+2; i <= end; i++)
{
dp[i] = max(dp[i-1], dp[i-2]+nums[i]);
}
return max(dp[end], dp[end-1]);
}
};
337. 打家劫舍 III(☆☆☆)
在上次打劫完一条街道之后和一圈房屋后,小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为“根”。 除了“根”之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果两个直接相连的房子在同一天晚上被打劫,房屋将自动报警。
计算在不触动警报的情况下,小偷一晚能够盗取的最高金额。
思路:树形DP
1.动态规划其实就是使用状态转移容器来记录状态的变化,这里可以使用一个长度为2的数组,记录当前节点偷与不偷所得到的的最大金钱。
2.结合树的后续遍历,进行递归,单层逻辑中讨论偷与不偷
class Solution {
public:
int rob(TreeNode* root) {
if(root == nullptr) return 0;
vector<int>dp = dfs(root);
return max(dp[0], dp[1]);
}
vector<int> dfs(TreeNode* cur)
{
//dp[0]:不偷;dp[1]:偷
if(cur == nullptr) return vector<int>{0,0};
vector<int> left = dfs(cur->left);
vector<int> right = dfs(cur->right);
vector<int>dp(2,0);
//不偷
dp[0] = max(left[0], left[1]) + max(right[0], right[1]);//因为不偷,所以两个孩子可偷可不偷,看那个最大
//偷
dp[1] = left[0] + right[0] + cur->val;//两个孩子决不能偷
return dp;
}
};
股票问题
121. 买卖股票的最佳时机
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
贪心算法:
class Solution {
public:
int maxProfit(vector<int>& prices) {
int res = INT_MIN;
int lowPrice = prices[0];
for(int i = 0; i < prices.size(); i++)
{
res = max(res, prices[i] - lowPrice);
lowPrice = min(lowPrice, prices[i]);
}
return res;
}
};
dp算法(状态压缩):
class Solution {
public:
int maxProfit(vector<int>& prices) {
int len = prices.size();
vector<vector<int>> dp(2, vector<int>(2)); // 注意这⾥只开辟了⼀个2 * 2⼤⼩的⼆维数组
dp[0][0] -= prices[0];
dp[0][1] = 0;
for (int i = 1; i < len; i++) {
dp[i % 2][0] = max(dp[(i - 1) % 2][0], -prices[i]);
dp[i % 2][1] = max(dp[(i - 1) % 2][1], prices[i] + dp[(i - 1) % 2][0]);
}
return dp[(len - 1) % 2][1];
}
};
122. 买卖股票的最佳时机 II
给定一个数组 prices ,其中 prices[i] 是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
贪心算法:
class Solution {
public:
int maxProfit(vector<int>& prices) {
if(prices.size() == 1) return 0;
int res = 0;
for(int i = 1; i < prices.size(); i++)
{
res += max(0, prices[i] - prices[i-1]);
}
return res;
}
};
class Solution {
public:
int maxProfit(vector<int>& prices) {
int len = prices.size();
vector<vector<int>> dp(len, vector<int>(2, 0));
dp[0][0] -= prices[0];
dp[0][1] = 0;
for (int i = 1; i < len; i++) {
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]); // 注意这⾥是和121. 买卖股票的最佳时机唯⼀不同的地⽅。
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i]);
}
return dp[len - 1][1];
}
};
123. 买卖股票的最佳时机 III(☆☆)
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
class Solution {
public:
int maxProfit(vector<int>& prices) {
//dp[i][j]中 i表示第i天, j为 [0 - 4] 五个状态(无操作,第一次买入/卖出,第二次买入/卖出), dp[i][j]表示第i天状态j所剩最⼤现⾦。
//递推公式:dp[i][j] = max(dp[i-1][j], dp[i-1][j-1] +- prices[i])
//初始化:dp[0][0] = 0, dp[0][1] = dp[0][3] = -prices[0]
//遍历顺序
if(prices.size() == 1) return 0;
vector<vector<int>> dp(prices.size(), vector<int>(5, 0));
dp[0][1] = -prices[0]; dp[0][3] = -prices[0];
for(int i = 1; i < prices.size(); i++)
{
dp[i][0] = dp[i-1][0];
dp[i][1] = max(dp[i-1][1], dp[i-1][0] - prices[i]);
dp[i][2] = max(dp[i-1][2], dp[i-1][1] + prices[i]);
dp[i][3] = max(dp[i-1][3], dp[i-1][2] - prices[i]);
dp[i][4] = max(dp[i-1][4], dp[i-1][3] + prices[i]);
}
return dp[prices.size()-1][4];
}
};
188. 买卖股票的最佳时机 IV(☆☆)
给定一个整数数组 prices ,它的第 i 个元素 prices[i] 是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
class Solution {
public:
int maxProfit(int k, vector<int>& prices) {
//完全就是123的翻版
if(prices.size() == 0) return 0;
vector<vector<int>> dp(prices.size(), vector<int>(2*k+1, 0));
for(int j = 1; j < 2*k; j += 2) dp[0][j] = -prices[0];
for(int i = 1; i < prices.size(); i++)
{
for(int j = 0; j < 2*k-1; j+=2)
{
dp[i][j+1] = std::max(dp[i-1][j+1], dp[i-1][j] - prices[i]);
dp[i][j+2] = std::max(dp[i-1][j+2], dp[i-1][j+1] + prices[i]);
}
}
return dp[prices.size()-1][2*k];
//return 0;
}
};
309. 最佳买卖股票时机含冷冻期(☆☆☆)
给定一个整数数组,其中第 i 个元素代表了第 i 天的股票价格 。
设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票):
你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)
class Solution {
public:
int maxProfit(vector<int>& prices) {
//主要是区分四个状态:dp[i][j](j <= 3)
/*
dp[i][0]:买入股票状态(今天买入股票, 之前买入保持)
dp[i][1]:卖出股票状态,至少两天前卖出股票一直保持卖出状态
dp[i][2]:今天卖出股票
dp[i][3]:今天为冷冻状态,但是冷冻期状态不可持续,只有一天!
*/
//递推公式
/*
dp[i][0] = max(dp[i-1][0], dp[i-1][3]-prices[i], dp[i-1][1]-prices[i])
dp[i][1] = max(dp[i-1][2], dp[i-1][3])
dp[i][2] = dp[i-1][0]+prices[i]
dp[i][3] = dp[i-1][2]
*/
//初始化 dp[0][0] = -prices[0]
int n = prices.size();
if(n == 0) return 0;
vector<vector<int>> dp(n, vector<int>(4, 0));
dp[0][0] = -prices[0];
for(int i = 1; i < n; i++)
{
dp[i][0] = max(dp[i-1][0], max(dp[i-1][1], dp[i-1][3]) - prices[i]);
dp[i][1] = max(dp[i-1][1], dp[i-1][3]);
dp[i][2] = dp[i-1][0]+prices[i];
dp[i][3] = dp[i-1][2];
}
return max({dp[n-1][1], dp[n-1][2], dp[n-1][3]});
}
};
714. 买卖股票的最佳时机含手续费
给定一个整数数组 prices,其中第 i 个元素代表了第 i 天的股票价格 ;非负整数 fee 代表了交易股票的手续费用。
你可以无限次地完成交易,但是你每笔交易都需要付手续费。如果你已经购买了一个股票,在卖出它之前你就不能再继续购买股票了。
返回获得利润的最大值。
注意:这里的一笔交易指买入持有并卖出股票的整个过程,每笔交易你只需要为支付一次手续费。
贪心算法:
class Solution {
public:
int maxProfit(vector<int>& prices, int fee) {
int n = prices.size();
int buy = prices[0] + fee;
int profit = 0;
for (int i = 1; i < n; ++i) {
if (prices[i] + fee < buy) {
buy = prices[i] + fee;
}
else if (prices[i] > buy) {
profit += prices[i] - buy;
buy = prices[i];//核心代码
}
}
return profit;
}
};
动态规划:
class Solution {
public:
int maxProfit(vector<int>& prices, int fee) {
// dp[i][0] 表示第 i 天交易完后手里没有股票的最大利润,
// dp[i][1] 表示第 i 天交易完后手里持有一支股票的最大利润(i 从 0 开始)。
int n = prices.size();
vector<vector<int>> dp(prices.size(), vector<int>(2, 0));
dp[0][1] = -prices[0];
for(int i = 1; i < prices.size(); i++) {
dp[i][0] = max(dp[i-1][0], dp[i-1][1]+prices[i] - fee);
dp[i][1] = max(dp[i-1][1], dp[i-1][0] - prices[i]);
}
return dp[n-1][0];
}
};
子序列问题
300. 最长递增子序列
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
if(nums.size() < 2) return nums.size();
vector<int> dp(nums.size(), 1);
int res = 0;
for(int i = 1; i < nums.size(); i++)
{
for(int j = 0; j < i; j++)
{
if(nums[i] > nums[j])
{
dp[i] = max(dp[i], dp[j]+1);
}
}
res = max(res, dp[i]);
}
return res;
}
};
354. 俄罗斯套娃信封问题
给你一个二维整数数组 envelopes ,其中 envelopes[i] = [wi, hi] ,表示第 i 个信封的宽度和高度。
当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。
请计算 最多能有多少个 信封能组成一组“俄罗斯套娃”信封(即可以把一个信封放到另一个信封里面)。
注意:不允许旋转信封。
class Solution {
public:
static bool cmp(vector<int> &a, vector<int> &b)
{
return a[0] == b[0] ? a[1] < b[1] : a[0] < b[0];
//return a[0] < b[0];
}
int maxEnvelopes(vector<vector<int>>& envelopes) {
//dp[i]:到信封索引i的最大值
//状态方程:if(envelopes[j][0] < envelopes[i][0] & envelopes[j][1] < envelopes[i][1]) dp[i] = max(dp[i], dp[j]+1);
//初始化:dp[i] = 1;
if(envelopes.size() < 2) return envelopes.size();
sort(envelopes.begin(), envelopes.end(), cmp);
for(int i = 0; i < envelopes.size(); i++)
{
cout << envelopes[i][0] << " "<< envelopes[i][1] << endl;
}
int res = 0;
vector<int> dp(envelopes.size(),1);
for(int i = 1; i < envelopes.size(); i++) {
for(int j = 0; j < i; j++) {
if(envelopes[j][0] < envelopes[i][0] & envelopes[j][1] < envelopes[i][1]) dp[i] = max(dp[i], dp[j]+1);
}
res = max(res, dp[i]);
}
return res;;
}
};
674. 最长连续递增序列
给定一个未经排序的整数数组,找到最长且 连续递增的子序列,并返回该序列的长度。
连续递增的子序列 可以由两个下标 l 和 r(l < r)确定,如果对于每个 l <= i < r,都有 nums[i] < nums[i + 1] ,那么子序列 [nums[l], nums[l + 1], …, nums[r - 1], nums[r]] 就是连续递增子序列。
dp规划:
class Solution {
public:
int findLengthOfLCIS(vector<int>& nums) {
if (nums.size() == 0) return 0;
int result = 1;
vector<int> dp(nums.size() ,1);
for (int i = 0; i < nums.size() - 1; i++) {
if (nums[i + 1] > nums[i])
{ // 连续记录
dp[i + 1] = dp[i] + 1;
}
if (dp[i + 1] > result) result = dp[i + 1];
}
return result;
}
};
贪心:
class Solution {
public:
int findLengthOfLCIS(vector<int>& nums) {
//贪心算法
if(nums.size() == 0) return 0;
int result = 1;
int count = 1;
for(int i = 0; i < nums.size()-1; i++)
{
if(nums[i+1] > nums[i]) count++;
else count = 1;
result = max(result, count);
}
return result;
}
};
673. 最长递增子序列的个数(☆☆☆)
给定一个未排序的整数数组,找到最长递增子序列的个数。

class Solution {
public:
int findNumberOfLIS(vector<int>& nums) {
//dp[i]:到i为止的最长递增子序列的长度;count[i]:到i为止的最长曾子序列的个数
//初始化状态dp[i] = count[i] = 1;
//递推公式:if(nums[i] > nums[j])
if(nums.size() < 2) return nums.size();
vector<int> dp(nums.size(), 1);
vector<int> count(nums.size(), 1);
int longest = 0;
for(int i = 1; i < nums.size(); i++)
{
for(int j = 0; j < i; j++)
{
if(nums[i] > nums[j])
{
if(dp[i] < dp[j]+1)
{
dp[i] = dp[j]+1;
count[i] = count[j];
}
else if(dp[i] == dp[j]+1)
{
count[i] += count[j];
}
}
}
longest = max(longest, dp[i]);//统计最长的数组长度
}
int res = 0;
for(int i = 0; i < nums.size(); i++)
{
if(dp[i] == longest) res += count[i];
}
return res;
}
};
718. 最长重复子数组
给两个整数数组 A 和 B ,返回两个数组中公共的、长度最长的子数组的长度。
思路:
dp[i][j] :以下标i - 1为结尾的A,和以下标j - 1为结尾的B,最长重复子数组长度为dp[i][j]。状态公式: 根据dp[i][j]的定义,dp[i][j]的状态只能由dp[i - 1][j - 1]推导出来。 即当A[i - 1]和B[j - 1]相等的时候,dp[i][j] = dp[i - 1][j - 1] + 1;
class Solution {
public:
int findLength(vector<int>& nums1, vector<int>& nums2) {
//dp[i][j]:以下标i-1为结尾的A,以下标j-1为结尾的B,最长重复子数组长度为dp[i][j]
//递推公式:dp[i][j] = dp[i-1][j-1]+1
//初始化:dp[0][j] = dp[i][0] = 0;
vector<vector<int>> dp(nums1.size()+1, vector<int>(nums2.size()+1, 0));
int res=0;
for(int i = 1; i <= nums1.size(); i++)
{
for(int j = 1; j <= nums2.size(); j++)
{
if(nums2[j-1] == nums1[i-1]) dp[i][j] = dp[i-1][j-1] + 1;
res = max(dp[i][j], res);
}
}
return res;
}
};
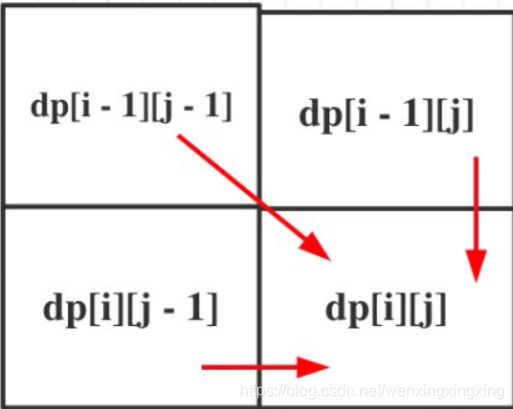
1143. 最长公共子序列
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如,“ace” 是 “abcde” 的子序列,但 “aec” 不是 “abcde” 的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
1035. 不相交的线
在两条独立的水平线上按给定的顺序写下 nums1 和 nums2 中的整数。
现在,可以绘制一些连接两个数字 nums1[i] 和 nums2[j] 的直线,这些直线需要同时满足满足:
nums1[i] == nums2[j]
且绘制的直线不与任何其他连线(非水平线)相交。
请注意,连线即使在端点也不能相交:每个数字只能属于一条连线。
以这种方法绘制线条,并返回可以绘制的最大连线数。
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
//dp[i][j]:⻓度为[0, i - 1]的字符串text1与⻓度为[0, j - 1]的字符串text2的最⻓公共⼦序列为dp[i][j]
//递推公式:if(A[i-1] == B[j-1]) dp[i][j] = max(dp[i-1][j], dp[i][j-1])+1; else dp[i][j]= max(dp[i-1][j], dp[i][j-1])
//初始化
if(text1.size() == 0 || text2.size() == 0) return 0;
vector<vector<int>> dp(text1.size()+1, vector<int>(text2.size()+1, 0));
for(int i = 1; i <= text1.size();i++)
{
for(int j = 1; j <= text2.size(); j++)
{
if(text2[j-1] == text1[i-1])
{
dp[i][j] = dp[i-1][j-1] + 1;
}
else
{
dp[i][j]= max(dp[i-1][j], dp[i][j-1]);
}
}
}
return dp[text1.size()][text2.size()];
}
};
53. 最大子序和
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
动态规划:
class Solution {
public:
int maxSubArray(vector<int>& nums) {
if (nums.size() == 0) return 0;
vector<int> dp(nums.size());
dp[0] = nums[0];
int result = dp[0];
for (int i = 1; i < nums.size(); i++) {
dp[i] = max(dp[i - 1] + nums[i], nums[i]); // 状态转移公式
if (dp[i] > result) result = dp[i]; // result 保存dp[i]的最⼤值
}
return result;
}
};
贪心:
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int res = INT_MIN;
int tmp = 0;
for(int i = 0; i < nums.size(); i++)
{
tmp += nums[i];
res = max(tmp, res);
tmp = max(tmp, 0);
}
return res;
}
};
392. 判断子序列
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
进阶: 如果有大量输入的 S,称作 S1, S2, … , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T的子序列。在这种情况下,你会怎样改变代码?
动态规划:
class Solution {
public:
bool isSubsequence(string s, string t) {
//dp[i][j]:以i-1下标s与j-1下标的t为结尾的最长子序列
//递推公式if(s[i-1] == t[j-1]) dp[i][j] = dp[i-1][j-1]=1,else dp[i][j] == dp[i][j-1](如果不相同就相当于删除t[j],那么此时就是s[i-1] 与t[j-2]对比了)
//初始化
if(s.size() > t.size()) return false;
vector<vector<int>> dp(s.size()+1, vector<int>(t.size()+1, 0));
for(int i = 1; i < s.size()+1; i++)
{
for(int j = 1; j <= t.size(); j++)
{
if(s[i-1] == t[j-1]) dp[i][j] = dp[i-1][j-1]+1;
else dp[i][j] = dp[i][j-1];
}
}
return dp[s.size()][t.size()] == s.size();
}
};
双指针:
class Solution {
public:
bool isSubsequence(string s, string t) {
//双指针
if(s.size() > t.size()) return false;
int j = 0;
int count = 0;
for(int i = 0; i < s.size(); i++)
{
for(; j < t.size(); j++)
{
if(s[i] == t[j])
{
cout<<s[i]<<" ";
j++;
count++;
break;
}
}
}
return count == s.size();
}
};
115. 不同的子序列(☆☆☆)
给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。
字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,“ACE” 是 “ABCDE” 的一个子序列,而 “AEC” 不是)
题目数据保证答案符合 32 位带符号整数范围。
class Solution {
public:
int numDistinct(string s, string t) {
//dp[i][j]:以i-1为结尾的字符串s中出现以j-1为结尾出现t的子序列的个数
//递推公式:if(s[i-1] == t[j-1]) dp[i][j] = d[i-1][j-1]+d[i-1][j] else dp[i][j] = dp[i-1][j];
//初始化p[i][0]=1:对于空类,肯定是为1的;dp[0][j] = 0(j>0):空类不包含任何子类
vector<vector<uint64_t>> dp(s.size() + 1, vector<uint64_t>(t.size() +1));
for (int i = 0; i < s.size(); i++) dp[i][0] = 1;
for (int j = 1; j < t.size(); j++) dp[0][j] = 0;
for (int i = 1; i <= s.size(); i++) {
for (int j = 1; j <= t.size(); j++) {
if (s[i - 1] == t[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
} else {
dp[i][j] = dp[i - 1][j];
}
}
}
return dp[s.size()][t.size()];
}
};
583. 两个字符串的删除操作(☆☆)
给定两个单词 word1 和 word2,找到使得 word1 和 word2 相同所需的最小步数,每步可以删除任意一个字符串中的一个字符。
class Solution {
public:
int minDistance(string word1, string word2) {
//dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数。
/*
递推公式:
当word1[i - 1] 与 word2[j - 1]相同的时候
当word1[i - 1] 与 word2[j - 1]不相同的时候
当word1[i - 1] 与 word2[j - 1]相同的时候, dp[i][j] = dp[i - 1][j - 1];
当word1[i - 1] 与 word2[j - 1]不相同的时候,有三种情况:
情况⼀:删word1[i - 1],最少操作次数为dp[i - 1][j] + 1
情况⼆:删word2[j - 1],最少操作次数为dp[i][j - 1] + 1
情况三:同时删word1[i - 1]和word2[j - 1],操作的最少次数为dp[i - 1][j - 1] + 2
那最后当然是取最⼩值,所以当word1[i - 1] 与 word2[j - 1]不相同的时候,递推公式: dp[i][j] =
min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1});
*/
//初始化dp[i][0] = i, dp[0][j]=j
vector<vector<int>> dp(word1.size()+1, vector<int>(word2.size()+1, 0));
for(int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for(int j = 0; j <= word2.size(); j++) dp[0][j] = j;
for(int i = 1; i <= word1.size(); i++)
{
for(int j = 1; j <= word2.size(); j++)
{
if(word2[j-1] == word1[i-1]) dp[i][j] = dp[i-1][j-1];
else dp[i][j] = min({dp[i-1][j]+1, dp[i][j-1]+1, dp[i-1][j-1]+2});
}
}
return dp[word1.size()][word2.size()];
}
};
其实本题也可以转化为求最长公共子序列的问题:
class Solution {
public:
int minDistance(string text1, string text2) {
//dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2的最长公共子序列
//递推公式:
vector<vector<int>> dp(text1.size()+1, vector<int>(text2.size()+1, 0));
for(int i = 1; i <= text1.size();i++)
{
for(int j = 1; j <= text2.size(); j++)
{
if(text2[j-1] == text1[i-1])
{
dp[i][j] = dp[i-1][j-1] + 1;
}
else
{
dp[i][j]= max(dp[i-1][j], dp[i][j-1]);
}
}
}
return text2.size() + text1.size() - 2 * dp[text1.size()][text2.size()];
}
};
72. 编辑距离(☆☆☆)
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
插入一个字符
删除一个字符
替换一个字符
class Solution {
public:
int minDistance(string word1, string word2) {
//dp[i][j]:表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。
/*
递推公式;if(word1[i-1] == word2[j-1]) dp[i][j] = dp[i-1][j-1]
if (word1[i - 1] != word2[j - 1])
操作⼀: word1增加⼀个元素,使其word1[i - 1]与word2[j - 1]相同,那么就是以下标i-2为结尾的
word1 与 i-1为结尾的word2的最近编辑距离 加上⼀个增加元素的操作。
即 dp[i][j] = dp[i - 1][j] + 1;
操作⼆: word2添加⼀个元素,使其word1[i - 1]与word2[j - 1]相同,那么就是以下标i-1为结尾的
word1 与 j-2为结尾的word2的最近编辑距离 加上⼀个增加元素的操作。
即 dp[i][j] = dp[i][j - 1] + 1;
这⾥有同学发现了,怎么都是添加元素,删除元素去哪了。
word2添加⼀个元素,相当于word1删除⼀个元素,例如 word1 = "ad" , word2 = "a", word2添加⼀
个元素d,也就是相当于word1删除⼀个元素d,操作数是⼀样!
操作三:替换元素, word1替换word1[i - 1],使其与word2[j - 1]相同,此时不⽤增加元素,那么以下标
i-2为结尾的word1 与 j-2为结尾的word2的最近编辑距离 加上⼀个替换元素的操作。
即 dp[i][j] = dp[i - 1][j - 1] + 1;
综上,当 if (word1[i - 1] != word2[j - 1]) 时取最⼩的,即: dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j],
dp[i][j - 1]}) + 1;
*/
/*初始化:
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
*/
//遍历顺序,从左到右
vector<vector<int>> dp(word1.size()+1, vector<int>(word2.size()+1, 0));
for(int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
for(int i = 1; i <= word1.size(); i++)
{
for(int j = 1; j <= word2.size(); j++)
{
if(word2[j-1] == word1[i-1]) dp[i][j] = dp[i-1][j-1];
else dp[i][j] = min({dp[i-1][j], dp[i][j-1], dp[i-1][j-1]}) + 1;
}
}
return dp[word1.size()][word2.size()];
}
};
647. 回文子串(☆☆☆)
给定一个字符串,你的任务是计算这个字符串中有多少个回文子串。
具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。
动态规划:
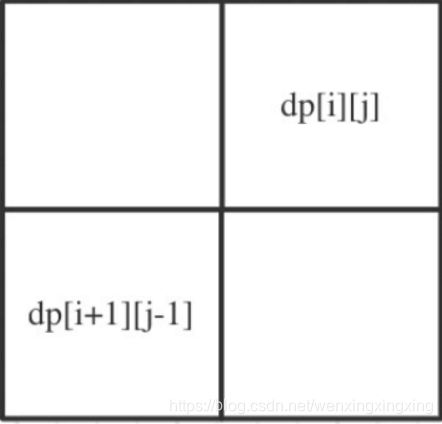
class Solution {
public:
int countSubstrings(string s) {
//布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的⼦串是否是回⽂⼦串,如果是dp[i][j]为true,否则为false。
/*递推公式:
整体上是两种,就是s[i]与s[j]相等, s[i]与s[j]不相等这两种。
当s[i]与s[j]不相等,那没啥好说的了, dp[i][j]⼀定是false。
当s[i]与s[j]相等时,这就复杂⼀些了,有如下三种情况
情况⼀:下标i 与 j相同,同⼀个字符例如a,当然是回⽂⼦串
情况⼆:下标i 与 j相差为1,例如aa,也是⽂⼦串
情况三:下标: i 与 j相差⼤于1的时候,例如cabac,此时s[i]与s[j]已经相同了,我们看i到j区间是
不是回⽂⼦串就看aba是不是回⽂就可以了,那么aba的区间就是 i+1 与 j-1区间,这个区间是不是
回⽂就看dp[i + 1][j - 1]是否为true。
*/
//初始化,全部为false
//遍历顺序⼀定要从下到上,从左到右遍历,这样保证dp[i + 1][j - 1]都是经过计算的
vector<vector<bool>> dp(s.size(), vector<bool>(s.size(), false));
int result = 0;
for(int i = s.size()-1; i >= 0; i--)
{
for(int j = i; j < s.size(); j++)
{
if(s[i] == s[j])
{
if (j - i <= 1) { // 情况⼀ 和 情况⼆
result++;
dp[i][j] = true;
} else if (dp[i + 1][j - 1]) { // 情况三
result++;
dp[i][j] = true;
}
}
}
}
return result;
}
};
双指针:
class Solution {
public:
int countSubstrings(string s) {
if(s.size() < 2) return s.size();
int count = 0;
for(int i = 0; i < s.size(); i++)
{
count += dfs(s,i,i);//中心开花,奇偶都要考虑
count += dfs(s, i, i+1);
}
return count;
}
int dfs(const string& s, int i, int j)
{
int res = 0;
while (i >= 0 && j < s.size() && s[i] == s[j]) {
i--;
j++;
res++;
}
return res;
}
};
516. 最长回文子序列(☆☆)
给定一个字符串 s ,找到其中最长的回文子序列,并返回该序列的长度。可以假设 s 的最大长度为 1000 。

动态规划
1、确定dp数组(dp table)以及下标的含义
dp[i][j]:字符串s在[i, j]范围内最长的回文子序列的长度为dp[i][j]
2、确定递推公式
在判断回文子串的题目中,关键逻辑就是看s[i]与s[j]是否相同。
if s[i] == s[j],那么dp[i][j] = dp[i + 1][j - 1] + 2;
if s[i] != s[j], 那么dp[i][j] = max({dp[i+1][j], dp[i][j-1]})
3、初始化
当i与j相同,那么dp[i][j]一定是等于1的, 即:一个字符的回文子序列长度就是1。
其他情况dp[i][j]初始为0就行
4、确定遍历顺序
由递推公式可得dp[i][j] = dp[i + 1][j - 1] + 2 和 dp[i][j] = max(dp[i + 1][j], dp[i][j - 1])
所以遍历i的时候一定要从下到上遍历,这样才能保证,下一行的数据是经过计算的。
class Solution {
public:
int longestPalindromeSubseq(string s) {
//dp[i][j]:字符串s在[i, j]范围内最⻓的回⽂⼦序列的⻓度为dp[i][j]
//递推公式if(s[i] == s[j]) dp[i][j] = dp[i+1][j-1]+2 else dp[i][j] = max(dp[i-1][j], dp[i][j-1]);
//初始化dp[i][i] = 1;
//遍历顺序:从下到上,从左到右
vector<vector<int>> dp(s.size(), vector<int>(s.size(), 0));
for (int i = 0; i < s.size(); i++) dp[i][i] = 1;
for(int i = s.size()-1; i >= 0; i--)
{
for(int j = i+1; j < s.size(); j++)
{
if(s[i] == s[j]) dp[i][j] = dp[i+1][j-1]+2;
else dp[i][j] = max(dp[i+1][j], dp[i][j-1]);
}
}
return dp[0][s.size()-1];
}
};
5. 最长回文子串(☆)
给你一个字符串 s,找到 s 中最长的回文子串。
双指针:
class Solution {
public:
string longestPalindrome(string s) {
if(s.size() < 2) return s;
string str;
int count = 0;
for(int i = 0; i < s.size(); i++)
{
count = max(count, dfs(s,i,i));
count = max(count, dfs(s,i,i+1));
if(count > str.size()) str = s.substr(i - (count-1)/2, count);//这里是取字符串,注意索引的起始位置
}
return str;
}
int dfs(const string& s, int i, int j)
{
int res = 0;
while (i >= 0 && j < s.size() && s[i] == s[j]) {
if(i == j) res++;
else res += 2;
i--;
j++;
}
return res;
}
};
动态规划:
class Solution {
public:
string longestPalindrome(string s) {
int n = s.size();
string ans;
if (s.empty()) return 0;
int len = 1;
vector<vector<bool>> dp(n, vector<bool>(n, false)); //dp[i][j]代表下标从i到j的子串是否回文
for (int i = n - 1; i >= 0; i--){ //注意:i要反向遍历,因为下面会出现dp[i+1][j-1]
for (int j = i; j < n; j++){
if(s[i] == s[j]) {
if(i == j) dp[i][j] = true;
else if(j == i+1) dp[i][j] = true;
else {
dp[i][j] = dp[i+1][j-1];
}
}
if(dp[i][j] && j-i+1>=len) {
len = j-i+1;
ans = s.substr(i, j-i+1);
}
}
}
return ans;
}
};
1147. 段式回文
段式回文 其实与 一般回文 类似,只不过是最小的单位是 一段字符 而不是 单个字母。
举个例子,对于一般回文 “abcba” 是回文,而 “volvo” 不是,但如果我们把 “volvo” 分为 “vo”、“l”、“vo” 三段,则可以认为 “(vo)(l)(vo)” 是段式回文(分为 3 段)。
给你一个字符串 text,在确保它满足段式回文的前提下,请你返回 段 的 最大数量 k。
如果段的最大数量为 k,那么存在满足以下条件的 a_1, a_2, …, a_k:
每个 a_i 都是一个非空字符串;
将这些字符串首位相连的结果 a_1 + a_2 + … + a_k 和原始字符串 text 相同;
对于所有1 <= i <= k,都有 a_i = a_{k+1 - i}。
class Solution {
public:
int longestDecomposition(string text) {
int res = 0;
int prev = 0;
int S = text.size();
for (int i = 0; i < S / 2; ++i) {
if ((text.substr(prev, i - prev + 1)) == text.substr(S - 1 - i, i - prev + 1)) {
res += 2;
prev = i + 1;
}
}
if (S % 2 == 1 || prev < S / 2)
++res;
return res;
}
};
差值问题
1218. 最长定差子序列(☆☆)
给你一个整数数组 arr 和一个整数 difference,请你找出并返回 arr 中最长等差子序列的长度,该子序列中相邻元素之间的差等于 difference 。
子序列 是指在不改变其余元素顺序的情况下,通过删除一些元素或不删除任何元素而从 arr 派生出来的序列。
思路:一般遇到等差等字眼的动态规划,都会使用差值difference作为dp数组的切入点
因为如果还是一如既往使用数组作为下标索引作为切入点,会造成不必要的复杂度
因此本题的dp[i]其实是dp[value],但是如果是value的话,那么必须》=0,所以需要对索引进行哈希扩展,一般就是加上一个最大的数使其值永远为正数就可以
但是上述仍然会有一个问题,那就是占空间,所以更好地办法就是采用map进行存储
利用map降低空间复杂度:
class Solution {
public:
int longestSubsequence(vector<int>& arr, int difference) {
//dp[i]:以索引i为结尾的最长等差子序列的长度
//递推公式:if(a[i] = arr[j]+difference) dp[i] = max(dp[i], dp[j]+1);
//初始化:dp[i] = 1
unordered_map<int, int>map;
int res = 0;
for(int i = 0; i < arr.size(); i++)
{
map[arr[i]] = max(map[arr[i]], map[arr[i] - difference] + 1);
res = max(res, map[arr[i]]);
}
return res;
}
};
数组:
class Solution {
public:
int longestSubsequence(vector<int>& arr, int difference) {
//dp[i]:以索引i为结尾的最长等差子序列的长度
//递推公式:if(a[i] = arr[j]+difference) dp[i] = max(dp[i], dp[j]+1);
//初始化:dp[i] = 1
int n = arr.size();
vector<int> dp(2e5, 0);
int res = 0;
int stdd = 1e5;
for(int i = 0; i < n; i++)
{
int index = stdd + arr[i];
dp[index] = max(dp[index], dp[index - difference]+1);
dp[index] = max(dp[index], 1);
res = max(res, dp[index]);
}
return res;
}
};
1027. 最长等差数列(☆)
给定一个整数数组 A,返回 A 中最长等差子序列的长度。
回想一下,A 的子序列是列表 A[i_1], A[i_2], …, A[i_k] 其中 0 <= i_1 < i_2 < … < i_k <= A.length - 1。并且如果 B[i+1] - B[i]( 0 <= i < B.length - 1) 的值都相同,那么序列 B 是等差的。
对于每一个索引建立以差值的等差子序列
思路:dp[i][value]:对于每一个索引i都有差值的最长子序列
class Solution {
public:
int longestArithSeqLength(vector<int>& nums) {
//dp[nums[i]][] = max()
vector<vector<int>> dp(nums.size(), vector<int>(20000, 1));
int stdd = 10000;
int res = 0;
for(int i = 0; i < nums.size(); i++)
{
for(int j = 0; j < i; j++)
{
int value = stdd + nums[i] - nums[j];
dp[i][value] = max(dp[i][value], dp[j][value]+1);
res = max(res, dp[i][value]);
}
}
return res;
}
};
413. 等差数列划分(☆)
如果一个数列至少有三个元素,并且任意两个相邻元素之差相同,则称该数列为等差数列。
例如,以下数列为等差数列:
1, 3, 5, 7, 9
7, 7, 7, 7
3, -1, -5, -9
以下数列不是等差数列。
1, 1, 2, 5, 7
数组 A 包含 N 个数,且索引从0开始。数组 A 的一个子数组划分为数组 (P, Q),P 与 Q 是整数且满足 0<=P
元素 A[P], A[p + 1], …, A[Q - 1], A[Q] 是等差的。并且 P + 1 < Q 。
函数要返回数组 A 中所有为等差数组的子数组个数。
class Solution {
public:
int numberOfArithmeticSlices(vector<int>& nums) {
if(nums.size() < 3) return 0;
vector<int> dp(nums.size(), 0);
for(int i = 1; i < nums.size()-1; i++)
{
if(nums[i] - nums[i-1] == nums[i+1] - nums[i])
{
dp[i] = max(dp[i], dp[i-1] + 1);
}
}
for(int i = 0; i < dp.size(); i++) cout<<dp[i]<<" ";
return accumulate(dp.begin(), dp.end(), 0);
}
};
1262. 可被三整除的最大和(☆☆)
给你一个整数数组 nums,请你找出并返回能被三整除的元素最大和。
思路:要转为为从余数的角度来思考问题
dp[i][0]表示nums[0…i]模三余零的最大和
dp[i][1]表示nums[0…i]模三余一的最大和
dp[i][2]表示nums[0…i]模三余二的最大和状态方程: dp[i][] = max{dp[i-1][],dp[i-1][] + nums[i]} ( 取值为 0,1,2)
初始化:dp[0][0] = 0; dp[0][1]=INT_MIN; dp[0][2] = INT_MIN; 遍历顺序:for(int i
= 1; i <= nums.size(); i++)
class Solution {
public:
int maxSumDivThree(vector<int>& nums) {
//dp[i][0-2]:表示到索引i-1模三余0-2的最大和
//递推公式:dp[i][*] = max(dp[i][*], dp[i-1]+nums[i])
//初始化:dp[0][0] = 0; dp[0][1]=INT_MIN; dp[0][2] = INT_MIN;
vector<int> dp(3, 0);
for(int i = 0; i < nums.size(); i++)
{
int a,b,c;
//首选更新前一个dp[i-1]
a = dp[0] + nums[i];
b = dp[1] + nums[i];
c = dp[2] + nums[i];
dp[a%3] = max(dp[a%3], a);
dp[b%3] = max(dp[b%3], b);
dp[c%3] = max(dp[c%3], c);
}
return dp[0];
}
};
状态压缩:
class Solution {
public:
int maxSumDivThree(vector<int>& nums) {
//dp[i][0-2]:表示到索引i-1模三余0-2的最大和
//递推公式:dp[i][*] = max(dp[i][*], dp[i-1]+nums[i])
//初始化:dp[0][0] = 0; dp[0][1]=INT_MIN; dp[0][2] = INT_MIN;
vector<int> dp(3, 0);
for(int i = 0; i < nums.size(); i++)
{
int a,b,c;
a = dp[0] + nums[i];
b = dp[1] + nums[i];
c = dp[2] + nums[i];
dp[a%3] = max(dp[a%3], a);
dp[b%3] = max(dp[b%3], b);
dp[c%3] = max(dp[c%3], c);
}
return dp[0];
}
};
矩阵问题
289. 生命游戏
根据 百度百科 ,生命游戏,简称为生命,是英国数学家约翰·何顿·康威在 1970 年发明的细胞自动机。
给定一个包含 m × n 个格子的面板,每一个格子都可以看成是一个细胞。每个细胞都具有一个初始状态:1 即为活细胞(live),或 0 即为死细胞(dead)。每个细胞与其八个相邻位置(水平,垂直,对角线)的细胞都遵循以下四条生存定律:
如果活细胞周围八个位置的活细胞数少于两个,则该位置活细胞死亡;
如果活细胞周围八个位置有两个或三个活细胞,则该位置活细胞仍然存活;
如果活细胞周围八个位置有超过三个活细胞,则该位置活细胞死亡;
如果死细胞周围正好有三个活细胞,则该位置死细胞复活;
下一个状态是通过将上述规则同时应用于当前状态下的每个细胞所形成的,其中细胞的出生和死亡是同时发生的。给你 m x n 网格面板 board 的当前状态,返回下一个状态。
class Solution {
public:
void gameOfLife(vector<vector<int>>& board) {
//首先使判断整体全部判断细胞的状态然后,在一次性改变细胞的状态
//这里最主要就是活细胞变为死细胞就是1->0,那么在全部判断之前还不能改变,我们可以做一个标记,将1->2,这样在最后一步进行判断,
//同理,如果死细胞变为活细胞,0->1,也是先做个标记,0->-2
int m = board.size();
int n = board[0].size();
for(int i = 0; i < m; i++) {
for(int j = 0; j < n; j++) {
int live = liveCell(board, i, j);
cout<<live<<" ";
//如果是活细胞,判断是否为死细胞 1->2
if(board[i][j] > 0) {
if(live < 2 || live > 3) board[i][j] = 2;
} else { //是死细胞,判断是否为活细胞0-> -2
if(live == 3) board[i][j] = -2;
}
}
cout<<endl;
}
//进行状态更新
for(int i = 0; i < m; i++) {
for(int j = 0; j < n; j++) {
if(board[i][j] == 2) board[i][j] = 0;
else if(board[i][j] == -2) board[i][j] = 1;
}
}
return;
}
int liveCell(vector<vector<int>>& board, int row, int col) {
int m = board.size();
int n = board[0].size();
int neighbors[3] = {0, 1, -1};
int live = 0;
for(int i = 0; i < 3; i++){
for(int j = 0; j < 3; j++){
if(!(neighbors[i] == 0 && neighbors[j] == 0)) {
int r = row + neighbors[i];
int c = col + neighbors[j];
if((r < m && r >= 0) && (c < n && c >= 0) && board[r][c] > 0)
live += 1;
}
}
}
return live;
}
};
面试题 17.24. 最大子矩阵
给定一个正整数、负整数和 0 组成的 N × M 矩阵,编写代码找出元素总和最大的子矩阵。
返回一个数组 [r1, c1, r2, c2],其中 r1, c1 分别代表子矩阵左上角的行号和列号,r2, c2 分别代表右下角的行号和列号。若有多个满足条件的子矩阵,返回任意一个均可。
class Solution {
public:
vector<int> getMaxMatrix(vector<vector<int>>& matrix) {
int m=matrix.size(), n=matrix[0].size();
int maxMat=INT32_MIN;
vector<int> ans(4, -1);
for(int r1=0;r1<m;++r1){//遍历起始行
vector<int> nums(n);//矩阵某两行间元素按列求和
for(int r2=r1;r2<m;++r2){//遍历结束行
//最大字段和问题
int dp=0, start=-1;
for(int i=0;i<n;++i){//遍历和数组,实际上是边遍历边完成求和
nums[i]+=matrix[r2][i];//将新的一行中第i个元素加到前面若干行在位置i的和
if(dp>0){//前面的字段有和为正,可以把前面一部分也带上
dp+=nums[i];
}
else{//前面一段为负,拖后腿直接抛弃
dp=nums[i];
start=i;
}
if(dp>maxMat){//不断记录较好的结果
maxMat=dp;
ans[0]=r1;
ans[1]=start;
ans[2]=r2;
ans[3]=i;
}
}
}
}
return ans;
}
};
面试问题:
486. 预测赢家(☆☆☆)
给定一个表示分数的非负整数数组。 玩家 1 从数组任意一端拿取一个分数,随后玩家 2 继续从剩余数组任意一端拿取分数,然后玩家 1 拿,…… 。每次一个玩家只能拿取一个分数,分数被拿取之后不再可取。直到没有剩余分数可取时游戏结束。最终获得分数总和最多的玩家获胜。
给定一个表示分数的数组,预测玩家1是否会成为赢家。你可以假设每个玩家的玩法都会使他的分数最大化。
class Solution {
public:
bool PredictTheWinner(vector<int>& nums) {
//dp[i][j]:在索引[i,j]的子数组中,当前玩家和另一玩家的差的最大值,注意当前玩家并不一定是先手
//递推公式:dp[i][j] = max(nums[i] - dp[i+1][j], nums[j]-dp[i][j-1]);对于i==j dp[i][i] = nums[i];
//初始化:因为必须保证i
//遍历顺序:从下到上,从左到右
if(nums.size() % 2 == 0) return true;
vector<vector<int>> dp(nums.size(), vector<int>(nums.size(), 0));
//初始化;
for(int i = 0; i < nums.size(); i++) dp[i][i] = nums[i];
for(int i = nums.size()-2; i >= 0; i--) {
for(int j = i+1; j < nums.size(); j++) {
dp[i][j] = max(nums[i] - dp[i+1][j], nums[j]- dp[i][j-1]);
}
}
return dp[0][nums.size()-1] >= 0;
}
};
剑指 Offer 13. 机器人的运动范围
地上有一个m行n列的方格,从坐标 [0,0] 到坐标 [m-1,n-1] 。一个机器人从坐标 [0, 0] 的格子开始移动,它每次可以向左、右、上、下移动一格(不能移动到方格外),也不能进入行坐标和列坐标的数位之和大于k的格子。例如,当k为18时,机器人能够进入方格 [35, 37] ,因为3+5+3+7=18。但它不能进入方格 [35, 38],因为3+5+3+8=19。请问该机器人能够到达多少个格子?
class Solution {
public:
int movingCount(int m, int n, int k) {
//dp[i][j]:目前到[i][j] 可以达到的最大方格
//推到公式:if(true) {if(dp[i-1][j] || dp[i+1][j] || dp[i][j-1] || dp[i][j+1]) dp[i][j] = 1}
//初始化:
vector<vector<int>> dp(m, vector<int>(n,0));
int res = 0;
//初始化
for(int i = 0; i < m; i++) {
if(isVaild(i,0,k)) {
dp[i][0] = 1;
res++;
}
else break;
}
for(int j = 1; j < n; j++) {
if(isVaild(0,j,k)) {
dp[0][j] = 1;
res++;
}
else break;
}
for(int i = 1; i < m; i++) {
for(int j = 1; j < n; j++) {
if(isVaild(i,j,k)) {
if(dp[i-1][j] || dp[i][j-1] || (i+1<m && dp[i+1][j]) || (j+1<n && dp[i][j+1])) {
dp[i][j] = 1;
res++;
}
}
}
}
return res;
}
bool isVaild(int i, int j, int k) {
//if(i > k || j > k) return false;
int sum = 0;
while(i || j) {
sum = sum + i % 10 + j % 10;
i /= 10;
j /= 10;
}
return sum <= k;
}
};
940. 不同的子序列 II
给定一个字符串 S,计算 S 的不同非空子序列的个数。
因为结果可能很大,所以返回答案模 10^9 + 7
虽然解决这题的代码很短,但它的算法并不是很容易设计。我们会用动态规划先求出包括空序列的所有子序列,再返回答案之前再减去空序列。
我们用 dp[k] 表示 S[0 … k] 可以组成的不同子序列的数目。如果 S 中的所有字符都不相同,例如 S =
“abcx”,那么状态转移方程就是简单的 dp[k] = dp[k-1] * 2,例如 dp[2] = 8,它包括 (“”, “a”,“b”, “c”, “ab”, “ac”, “bc”, “abc”) 这 8 个不同的子序列,而 dp[3] 在这些子序列的末尾增加x,就可以得到额外的 8 个不同的子序列,即 (“x”, “ax”, “bx”, “cx”, “abx”, “acx”, “bcx”, “abcx”),因此 dp[3] = 8 * 2 = 16。但当 S 中有相同字母的时候,就要考虑重复计数的问题了,例如当 S = “abab” 时,我们有:
dp[0] = 2,它包括 (“”, “a”);
dp[1] = 4,它包括 (“”, “a”, “b”, “ab”);
dp[2] = 7,它包括 (“”, “a”, “b”, “aa”, “ab”, “ba”, “aba”);
dp[3] = 12,它包括 (“”, “a”, “b”, “aa”, “ab”, “ba”, “bb”, “aab”, “aba”,
“abb”, “bab”, “abab”)。当从 dp[2] 转移到 dp[3] 时,我们只会在 dp[2] 中的 (“b”, “aa”, “ab”, “ba”, “aba”)
的末尾增加 b,而忽略掉 (“”, “a”),因为它们会得到重复的子序列。我们可以发现,这里的 (“”, “a”) 刚好就是
dp[0],也就是上一次增加 b 之前的子序列集合。因此我们就得到了如下的状态转移方程:dp[k] = 2 * dp[k - 1] - dp[last[S[k]] - 1]
即在计算 dp[k] 时,首先会将 dp[k - 1] 对应的子序列的末尾添加 S[k] 得到额外的 dp[k - 1]
个子序列,并减去重复出现的子序列数目,这个数目即为上一次添加 S[k] 之前的子序列数目 dp[last[S[k]] - 1]。
class Solution {
public:
int distinctSubseqII(string s) {
//dp[i]:S[0 .. k) 可以组成的不同子序列的数目
//递推公式:dp[i+1] = 2 * dp[i] - dp[last[s[i]] - 1]
//初始化:dp[0] = 1;
//遍历顺序
long int M = 1000000007;
int n = s.size();
vector<long int> dp(s.size()+1, 0);
//dp[0] = 1;
vector<int> last(26, -1);// 定义count数组,保存每个字符最近一次出现的位置
for(int i = 0; i < s.size(); i++) {
if(last[s[i] - 'a'] < 0) {// 如果S[i]未出现过
dp[i+1] = dp[i] * 2 + 1;
} else {
dp[i+1] = dp[i]*2 - dp[last[s[i] - 'a']];
if(dp[i+1] < 0) dp[i+1] += M;
}
dp[i+1] %= M;
last[s[i] - 'a'] = i;// 更新last数组中S[i]的最新位置
}
return dp[n];
}
};
假设当前有N个不同的seq,每个seq加上一个新的字母,又是新的N个不同sequence了。
但新的seq中,有一部分原来就有。
比如新的字母是'a',那么原来以'a'结尾的seq,每一个都会存在新的这N个seq中。
到这里,解题思路就比较清楚了。
我们需要用一个数组int endsWith[26],
endsWith[i]来表示以第i个字母结束的sequence数量。
最后修饰一下代码细节。
数组全部初始化为0。
正好按照题目要求,空string不计作subseq。
每次更新的时候,end[i] = sum(end) + 1。
加一的原因是,比如我们遇到新字母'a',新的N个seq里不包含“a”,需要额外加上。
vector<long> ends(26);
const long M = 1e9+7;
for(char c : s) {
ends[c-'a'] = accumulate(ends.begin(), ends.end(), 1L) % M;
}
return accumulate(ends.begin(), ends.end(), 0L) % M;
983. 最低票价
在一个火车旅行很受欢迎的国度,你提前一年计划了一些火车旅行。在接下来的一年里,你要旅行的日子将以一个名为 days 的数组给出。每一项是一个从 1 到 365 的整数。
火车票有三种不同的销售方式:
一张为期一天的通行证售价为 costs[0] 美元;
一张为期七天的通行证售价为 costs[1] 美元;
一张为期三十天的通行证售价为 costs[2] 美元。
通行证允许数天无限制的旅行。 例如,如果我们在第 2 天获得一张为期 7 天的通行证,那么我们可以连着旅行 7 天:第 2 天、第 3 天、第 4 天、第 5 天、第 6 天、第 7 天和第 8 天。
返回你想要完成在给定的列表 days 中列出的每一天的旅行所需要的最低消费。
class Solution {
public:
int mincostTickets(vector<int>& days, vector<int>& costs) {
//dp[i]:第i天的最低话费,思路转变为从上车买票改为下车买票
//递推公式:分为非旅游日dp[i] = dp[i-1],对于旅游日:dp[i] = min(dp[i], dp[i-1] + cost[0], dp[max(i-7),0]+ cost[1], dp[max(i-30),0]+ cost[2])
//初始化
unordered_set<int> set;
for(int i : days) set.insert(i);
vector<int> dp(days.back()+1, 10000);
dp[0] = 0;
for(int i = 1; i <= days.back(); i++) {
if(set.find(i) == set.end()) dp[i] = dp[i-1];
else {
dp[i] = min({dp[i], dp[i-1] + costs[0], dp[max(i-7, 0)]+ costs[1], dp[max(i-30, 0)]+ costs[2]});
}
}
return dp[days.back()];
}
};
730. 统计不同回文子序列
给定一个字符串 S,找出 S 中不同的非空回文子序列个数,并返回该数字与 10^9 + 7 的模。
通过从 S 中删除 0 个或多个字符来获得子序列。
如果一个字符序列与它反转后的字符序列一致,那么它是回文字符序列。
如果对于某个 i,A_i != B_i,那么 A_1, A_2, … 和 B_1, B_2, … 这两个字符序列是不同的。
class Solution {
public:
int countPalindromicSubsequences(string s) {
int strSize = s.size();
const int M = 1e9+7;
//dp[i][j]:表示的s[i,j]这段字符串中不同的回文子序列的个数
vector<vector<int>> dp(strSize, vector<int>(strSize, 0));
//初始化:单个长度的字符串也是一个回文子序列
for(int i = 0; i < strSize; i++) {
dp[i][i] = 1;
}
//开始动态规划
for(int i = strSize-2; i >= 0; i--) {
for(int j = i+1; j < strSize; j++) {
//上面的两层for循环用于穷举区间[i, j],i用于确定区间的起点,j确定区间的尾端,并且区间的长度都是由2逐渐增大
if(s[i] == s[j]) {
//left用于寻找与s[i]相同的左端第一个下标,right用于寻找与s[i]相同的右端第一个下标
int left = i+1, right = j-1;
while(left <= right && s[left] != s[i]) left++;
while(left <= right && s[right] != s[i]) right--;
if(left > right) {
//中间没有和S[i]相同的字母,例如"aba"这种情况
//其中dp[i + 1][j - 1]是中间部分的回文子序列个数,因为中间的所有子序列可以单独存在,也可以再外面包裹上字母a,所以是成对出现的,要乘2。
//加2的原因是外层的"a"和"aa"也要统计上
dp[i][j] = dp[i+1][j-1]*2 + 2;
} else if(left == right) {
//中间只有一个和S[i]相同的字母,就是"aaa"这种情况,
//其中乘2的部分跟上面的原因相同,
//加1的原因是单个字母"a"的情况已经在中间部分算过了,外层就只能再加上个"aa"了。
dp[i][j] = dp[i + 1][j - 1] * 2 + 1;
} else {
//中间至少有两个和S[i]相同的字母,就是"aabaa"这种情况,
//其中乘2的部分跟上面的原因相同,要减去left和right中间部分的子序列个数的原因是其被计算了两遍,要将多余的减掉。
dp[i][j] = dp[i+1][j-1] * 2 - dp[left+1][right-1];
}
} else {
//dp[i][j - 1] + dp[i + 1][j]这里计算了dp[i + 1][j - 1]两遍
dp[i][j] = dp[i][j - 1] + dp[i + 1][j] - dp[i + 1][j - 1];
}
dp[i][j] = (dp[i][j] < 0) ? dp[i][j] + M : dp[i][j] % M;
}
}
return dp[0][strSize - 1];
}
};
283. 移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
void moveZeroes(int* nums, int numsSize) {
int i = 0,j = 0;
for(i = 0 ; i < numsSize; i++)
{
if(nums[i] != 0)
{
nums[j++] = nums[i];
}
}
while(j < numsSize)
{
nums[j++] = 0;
}
}
73. 矩阵置零(☆☆)
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
进阶:
一个直观的解决方案是使用 O(mn) 的额外空间,但这并不是一个好的解决方案。
一个简单的改进方案是使用 O(m + n) 的额外空间,但这仍然不是最好的解决方案。
你能想出一个仅使用常量空间的解决方案吗?
class Solution {
public:
void setrow(vector<vector<int>>& matrix, int num) {//对行置零
for(int i = 0; i < matrix[0].size(); i++) {
matrix[num][i] = 0;
}
}
void setcol(vector<vector<int>>& matrix, int num) {//对列置零
for(int i = 0; i < matrix.size(); i++) {
matrix[i][num] = 0;
}
}
void setZeroes(vector<vector<int>>& matrix) {
//利用两个标记记录首行和首列是否需要置零
bool row = false, col = false;
for(int i = 0; i < matrix.size(); i++) {//判断列是否需要置零
if(matrix[i][0] == 0) {
col = true;
break;
}
}
for(int j = 0; j < matrix[0].size(); j++) {//判断行是否需要置零
if(matrix[0][j] == 0) {
row = true;
break;
}
}
for(int i = 1; i < matrix.size(); i++) {//从[1,1]开始判断,如果为0就把行首和列首置零
for(int j = 1; j < matrix[0].size(); j++) {
if(matrix[i][j] == 0) {
matrix[i][0] = 0;
matrix[0][j] = 0;
}
}
}
for(int i = 1; i < matrix[0].size(); i++) {//不能从0开始
if(matrix[0][i] == 0) setcol(matrix, i);
}
for(int i = 1; i < matrix.size(); i++) {
if(matrix[i][0] == 0) setrow(matrix, i);
}
if(row == true) setrow(matrix, 0);
if(col == true) setcol(matrix, 0);
}
};
384. 打乱数组
给你一个整数数组 nums ,设计算法来打乱一个没有重复元素的数组。
实现 Solution class:
Solution(int[] nums) 使用整数数组 nums 初始化对象
int[] reset() 重设数组到它的初始状态并返回
int[] shuffle() 返回数组随机打乱后的结果
class Solution {
public:
Solution(vector<int>& nums) {
res = nums;
}
/** Resets the array to its original configuration and return it. */
vector<int> reset() {
return res;
}
/** Returns a random shuffling of the array. */
vector<int> shuffle() {
vector<int> Vshuffle = res;
for(int i = res.size()-1; i >= 0; i--) {
int index = rand() % (i+1);
swap(Vshuffle[index], Vshuffle[i]);
}
return Vshuffle;
}
private:
vector<int> res;
};
/**
* Your Solution object will be instantiated and called as such:
* Solution* obj = new Solution(nums);
* vector param_1 = obj->reset();
* vector param_2 = obj->shuffle();
*/
134. 加油站(贪心算法)
在一条环路上有 N 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1。
说明:
如果题目有解,该答案即为唯一答案。
输入数组均为非空数组,且长度相同。
输入数组中的元素均为非负数。
class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
//如果可以作为起始点,那么gas[i]>=cost[i]是一定的;
for(int i = 0; i < cost.size(); i++) {
int res = gas[i] - cost[i];
int index = (i+1) % cost.size();
while(res >= 0 && index != i) {
res += gas[index] - cost[index];
index = (index+1) % cost.size();
}
if(res >= 0 && index == i) return index;
}
return -1;
}
};
11. 盛最多水的容器(贪心☆☆)
给你 n 个非负整数 a1,a2,…,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0) 。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水
class Solution {
public:
int maxArea(vector<int>& height) {
//贪心算法
if(height.size() < 1) return -1;
int res = 0;
int left = 0, right = height.size()-1;
while(left < right) {
int h = min(height[left], height[right]);
res = max(res, h*(right-left));
if(height[left] < height[right]) left++;
else right--;
}
return res;
}
};
55. 跳跃游戏
给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标。
class Solution {
public:
bool canJump(vector<int>& nums) {
int cover = 0;
for(int i = 0; i <= cover; i++)
{
cover=max(i+nums[i], cover);
if(cover >= nums.size()-1) return true;
}
return false;
}
};
45. 跳跃游戏 II
给你一个非负整数数组 nums ,你最初位于数组的第一个位置。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
你的目标是使用最少的跳跃次数到达数组的最后一个位置。
假设你总是可以到达数组的最后一个位置。
class Solution {
public:
int jump(vector<int>& nums) {
if(nums.size() < 2) return 0;
int cur = 0, next = 0;
int res = 0;
for(int i = 0; i < nums.size()-1; i++) {
next = max(i+nums[i], next);
if(i == cur) {
cur = next;
res++;
}
}
return res;
}
};
200. 岛屿数量(DFS☆)
给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
class Solution {
public:
int numIslands(vector<vector<char>>& grid) {
int islandNum = 0;
for(int i = 0; i < grid.size(); i++){
for(int j = 0; j < grid[0].size(); j++){
if(grid[i][j] == '1'){
infect(grid, i, j);
islandNum++;
}
}
}
return islandNum;
}
//感染函数
void infect(vector<vector<char>>& grid, int i, int j){
if(i < 0 || i >= grid.size() ||j < 0 || j >= grid[0].size() || grid[i][j] != '1')
{
return;
}
grid[i][j] = '2';
infect(grid, i + 1, j);
infect(grid, i - 1, j);
infect(grid, i, j + 1);
infect(grid, i, j - 1);
}
};
74. 搜索二维矩阵(二分、BST☆☆)
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
每行中的整数从左到右按升序排列。
每行的第一个整数大于前一行的最后一个整数。
从右上和左下看就是一颗BST树
//直接将二维化为一维的二分
class Solution {
public:
bool searchMatrix(vector<vector<int>>& matrix, int target) {
//二分法
if(matrix.empty()||matrix[0].empty())return 0;
int left = 0, right = matrix.size() * matrix[0].size() - 1;
int n = matrix[0].size();
while(left <= right) {
int mid = left + (right - left)/2;
if(matrix[mid/n][mid%n] > target) right = mid - 1;
else if(matrix[mid/n][mid%n] < target) left = mid + 1;
else return true;
}
return false;
}
};
//因为每一行递增,每一列递增。所以我们可以从右上角往左下角找或者从左下角往右上角找。每次比较可以排除一行或者一列,时间复杂度为O(m+n)
bool searchMatrix(vector<vector<int>>& matrix,int target){
if(matrix.empty()||matrix[0].empty())return 0;
//从左下角上右上角寻找目标值
int x=matrix.size()-1,y=0;
while(x>=0&&y<matrix[0].size())
{
if(matrix[x][y]>target)x--;//[x,y]的值比目标值大,上移
else if(matrix[x][y]<target)y++;//[x,y]的值比目标值小,右移
else return true;
}
return false;
}
剑指 Offer 04. 二维数组中的查找(只能BST)
在一个 n * m 的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个高效的函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
原因在于,第一行的最后一位并不大于第二行的第一位,所以并不能用二分
class Solution {
public:
bool findNumberIn2DArray(vector<vector<int>>& matrix, int target) {
//二分查找
if(matrix.empty()||matrix[0].empty())return 0;
int row = 0, col = matrix[0].size()-1;
while(row < matrix.size() && col >= 0) {
int num = matrix[row][col];
if(num < target) {
row++;
} else if(num > target) col--;
else return true;
}
return false;
}
};
79. 单词搜索(回溯算法)
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。

class Solution {
public:
bool exist(vector<vector<char>>& board, string word) {
int m = board.size();
int n = board[0].size();
if(board.size()*board[0].size() < word.size()) return false;
int k = 0;
vector<vector<int>>grid(m, vector<int>(n, 0));
for(int i = 0; i < m; i++)
{
for(int j = 0; j < n; j++)
{
if(board[i][j] == word[0])
{
if(dfs(board, i, j, word, k, grid)) return true;
}
//if(count >= word.size()) return true;
}
}
return false;
}
bool dfs(vector<vector<char>>& board, int i, int j, string& word, int k, vector<vector<int>>& grid) {
if(k >= word.size()) return true;
if(i < 0 || i >= board.size() || j < 0 || j >= board[0].size() || grid[i][j] != 0 || board[i][j] != word[k]) return false;
//判断本次递归的结点是不是有
if(board[i][j] == word[k])
{
k++;
grid[i][j] = 1;
if(dfs(board, i+1, j, word, k, grid) || dfs(board, i-1, j, word, k, grid) || dfs(board, i, j+1, word, k, grid) || dfs(board, i, j-1, word, k, grid)) return true;
k--;
grid[i][j] = 0;
}
return false;
}
};
334. 递增的三元子序列
给你一个整数数组 nums ,判断这个数组中是否存在长度为 3 的递增子序列。
如果存在这样的三元组下标 (i, j, k) 且满足 i < j < k ,使得 nums[i] < nums[j] < nums[k] ,返回 true ;否则,返回 false 。
class Solution {
public:
bool increasingTriplet(vector<int>& nums) {
//利用两个val来记录最小的
if(nums.size() < 3) return false;
int minVal = INT_MAX, secondVal = INT_MAX;
for(int val : nums) {
if(val <= minVal) minVal = val;
else if(val <= secondVal) secondVal = val;
else return true;
}
return false;
}
};
146. LRU 缓存机制(☆☆☆☆)
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制 。
实现 LRUCache 类:
LRUCache(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存
int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
void put(int key, int value) 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
进阶:你是否可以在 O(1) 时间复杂度内完成这两种操作?
class LRUCache {
/*
// key 映射到 Node(key, val)
HashMap map;
// Node(k1, v1) <-> Node(k2, v2)...
DoubleList cache;
int get(int key) {
if (key 不存在) {
return -1;
} else {
将数据 (key, val) 提到开头;
return val;
}
}
void put(int key, int val) {
Node x = new Node(key, val);
if (key 已存在) {
把旧的数据删除;
将新节点 x 插入到开头;
} else {
if (cache 已满) {
删除链表的最后一个数据腾位置;
删除 map 中映射到该数据的键;
}
将新节点 x 插入到开头;
map 中新建 key 对新节点 x 的映射;
}
}
*/
public:
LRUCache(int capacity) :cap(capacity){
}
int get(int key) {
if(map.find(key) == map.end()) return -1;
auto key_value = *map[key];
cache.erase(map[key]);
cache.push_front(key_value);
map[key] = cache.begin();
return key_value.second;
}
void put(int key, int value) {
if(map.find(key) == map.end()) {
if(cache.size() == cap) {
map.erase(cache.back().first);
cache.pop_back();
}
} else {
cache.erase(map[key]);
}
cache.push_front({key,value});
map[key] = cache.begin();
}
private:
int cap;
list<pair<int,int>> cache;
unordered_map<int, list<pair<int, int>>::iterator> map;
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/
手写一个双向链表:
struct DLinkedNode {
int key, value;
DLinkedNode* prev;
DLinkedNode* next;
DLinkedNode(): key(0), value(0), prev(nullptr), next(nullptr) {}
DLinkedNode(int _key, int _value): key(_key), value(_value), prev(nullptr), next(nullptr) {}
};
class LRUCache {
private:
unordered_map<int, DLinkedNode*> cache;
DLinkedNode* head;
DLinkedNode* tail;
int size;
int capacity;
public:
LRUCache(int _capacity): capacity(_capacity), size(0) {
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head->next = tail;
tail->prev = head;
}
int get(int key) {
if (!cache.count(key)) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
DLinkedNode* node = cache[key];
moveToHead(node);
return node->value;
}
void put(int key, int value) {
if (!cache.count(key)) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode* node = new DLinkedNode(key, value);
// 添加进哈希表
cache[key] = node;
// 添加至双向链表的头部
addToHead(node);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode* removed = removeTail();
// 删除哈希表中对应的项
cache.erase(removed->key);
// 防止内存泄漏
delete removed;
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
DLinkedNode* node = cache[key];
node->value = value;
moveToHead(node);
}
}
void addToHead(DLinkedNode* node) {
node->prev = head;
node->next = head->next;
head->next->prev = node;
head->next = node;
}
void removeNode(DLinkedNode* node) {
node->prev->next = node->next;
node->next->prev = node->prev;
}
void moveToHead(DLinkedNode* node) {
removeNode(node);
addToHead(node);
}
DLinkedNode* removeTail() {
DLinkedNode* node = tail->prev;
removeNode(node);
return node;
}
};
23. 合并K个升序链表(☆☆☆)
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
return merge(lists, 0, lists.size()-1);
}
ListNode* merge(vector<ListNode*>& lists, int left, int right) {
if(left > right) return nullptr;
if(left == right) return lists[left];
int mid = left + (right - left) / 2;
ListNode* l = merge(lists, left, mid);
ListNode* r = merge(lists, mid+1, right);
return mergeTwoLists(l, r);
}
//合并两个链表
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if(l1 == NULL) return l2;
if(l2 == NULL) return l1;
if(l1->val <= l2->val)
{
l1->next = mergeTwoLists(l1->next, l2);
return l1;
}
else
{
l2->next = mergeTwoLists(l1, l2->next);
return l2;
}
return l1;
}
};
41. 缺失的第一个正数(☆☆☆)
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。
请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案
遍历一次数组把大于等于1的和小于数组大小的值放到原数组对应位置,然后再遍历一次数组查当前下标是否和值对应,如果不对应那这个下标就是答案,否则遍历完都没出现那么答案就是数组长度加1。
class Solution {
public:
int firstMissingPositive(vector<int>& nums) {
for (int i = 0; i < nums.size(); ++i) {
while (0 < nums[i] && nums[i] <= nums.size() && nums[i] != nums[nums[i]-1]) {
swap(nums[i], nums[nums[i]-1]);
}
}
for (int i = 0; i < nums.size(); ++i) {
if (nums[i] != i+1) {
return i+1;
}
}
return nums.size() + 1;
}
};
面试题 17.19. 消失的两个数字
给定一个数组,包含从 1 到 N 所有的整数,但其中缺了两个数字。你能在 O(N) 时间内只用 O(1) 的空间找到它们吗?
以任意顺序返回这两个数字均可。
class Solution {
public:
vector<int> missingTwo(vector<int>& nums) {
//数组后补两个-1,使用抽屉原理对数组进行排序,O(n)的时间复杂度,再遍历一遍数组找到两个-1的位置就是答案
vector<int> res;
nums.push_back(-1);
nums.push_back(-1);
for(int i=0;i<nums.size();i++){
while(nums[i] != -1 && nums[i]!=i+1) swap(nums[i],nums[nums[i]-1]);
}
for(int i = 0; i < nums.size(); i++) {
if(nums[i] != i+1) res.push_back(i+1);
if(res.size() == 2) return res;
}
return res;
}
};
4. 寻找两个正序数组的中位数(☆☆☆)
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
这道题让我们求两个有序数组的中位数,而且限制了时间复杂度为O(log (m+n)),看到这个时间复杂度,自然而然的想到了应该使用二分查找法来求解。那么回顾一下中位数的定义,如果某个有序数组长度是奇数,那么其中位数就是最中间那个,如果是偶数,那么就是最中间两个数字的平均值。这里对于两个有序数组也是一样的,假设两个有序数组的长度分别为m和n,由于两个数组长度之和 m+n 的奇偶不确定,因此需要分情况来讨论,对于奇数的情况,直接找到最中间的数即可,偶数的话需要求最中间两个数的平均值。为了简化代码,不分情况讨论,我们使用一个小trick,我们分别找第 (m+n+1) / 2 个,和 (m+n+2) / 2 个,然后求其平均值即可,这对奇偶数均适用。加入 m+n 为奇数的话,那么其实 (m+n+1) / 2 和 (m+n+2) / 2 的值相等,相当于两个相同的数字相加再除以2,还是其本身。
这里我们需要定义一个函数来在两个有序数组中找到第K个元素,下面重点来看如何实现找到第K个元素。首先,为了避免产生新的数组从而增加时间复杂度,我们使用两个变量i和j分别来标记数组nums1和nums2的起始位置。然后来处理一些边界问题,比如当某一个数组的起始位置大于等于其数组长度时,说明其所有数字均已经被淘汰了,相当于一个空数组了,那么实际上就变成了在另一个数组中找数字,直接就可以找出来了。还有就是如果K=1的话,那么我们只要比较nums1和nums2的起始位置i和j上的数字就可以了。难点就在于一般的情况怎么处理?因为我们需要在两个有序数组中找到第K个元素,为了加快搜索的速度,我们要使用二分法,对K二分,意思是我们需要分别在nums1和nums2中查找第K/2个元素,注意这里由于两个数组的长度不定,所以有可能某个数组没有第K/2个数字,所以我们需要先检查一下,数组中到底存不存在第K/2个数字,如果存在就取出来,否则就赋值上一个整型最大值。如果某个数组没有第K/2个数字,那么我们就淘汰另一个数字的前K/2个数字即可。有没有可能两个数组都不存在第K/2个数字呢,这道题里是不可能的,因为我们的K不是任意给的,而是给的m+n的中间值,所以必定至少会有一个数组是存在第K/2个数字的。最后就是二分法的核心啦,比较这两个数组的第K/2小的数字midVal1和midVal2的大小,如果第一个数组的第K/2个数字小的话,那么说明我们要找的数字肯定不在nums1中的前K/2个数字,所以我们可以将其淘汰,将nums1的起始位置向后移动K/2个,并且此时的K也自减去K/2,调用递归。反之,我们淘汰nums2中的前K/2个数字,并将nums2的起始位置向后移动K/2个,并且此时的K也自减去K/2,调用递归即可。
class Solution {
public:
double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2) {
int m = nums1.size();
int n = nums2.size();
int left = (m + n + 1) / 2;
int right = (m + n + 2) / 2;
return (dfs(nums1, 0, nums2, 0, left) + dfs(nums1, 0, nums2, 0, right)) / 2.0;
}
//i: nums1的起始位置 j: nums2的起始位置
int dfs(vector<int>& nums1,int i, vector<int>& nums2, int j, int k) {
if(i >= nums1.size()) return nums2[j+k-1];//nums1为空
if(j >= nums2.size()) return nums1[i+k-1];//nums2为空
if(k==1) return min(nums1[i], nums2[j]);
int midVal1 = (i + k/2 - 1 < nums1.size())? nums1[i+k/2-1]:INT_MAX;
int midVal2 = (j + k/2 - 1 < nums2.size())? nums2[j+k/2-1]:INT_MAX;
if(midVal1 < midVal2) {
return dfs(nums1, i +k/2, nums2, j, k-k/2);
} else {
return dfs(nums1, i , nums2, j+k/2, k-k/2);
}
}
};
49. 字母异位词分组
给定一个字符串数组,将字母异位词组合在一起。可以按任意顺序返回结果列表。
字母异位词指字母相同,但排列不同的字符串。
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>>res;
unordered_map<string, vector<string>> map;
for(int i = 0; i < strs.size(); i++) {
string str = strs[i];
sort(str.begin(), str.end());
map[str].push_back(strs[i]);
}
for(auto ite = map.begin(); ite != map.end(); ite++) {
res.push_back(ite->second);
}
return res;
}
};
295. 数据流的中位数(☆☆☆)
中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。
例如,
[2,3,4] 的中位数是 3
[2,3] 的中位数是 (2 + 3) / 2 = 2.5
设计一个支持以下两种操作的数据结构:
void addNum(int num) - 从数据流中添加一个整数到数据结构中。
double findMedian() - 返回目前所有元素的中位数。
插入排序
保持输入容器始终排序算法: 哪种算法允许将一个数字添加到已排序的数字列表中,但仍保持整个列表的排序状态?插入排序!
我们假设当前列表已经排序。当一个新的数字出现时,我们必须将它添加到列表中,同时保持列表的排序性质。这可以通过使用二分搜索找到插入传入号码的正确位置来轻松实现。
(记住,列表总是排序的)。一旦找到位置,我们需要将所有较高的元素移动一个空间,以便为传入的数字腾出空间。当插入查询的数量较少或者中间查找查询的数量大致相同。 此方法会很好地工作
class MedianFinder {
vector<int> store; // resize-able container
public:
// Adds a number into the data structure.
void addNum(int num)
{
if (store.empty())
store.push_back(num);
else
store.insert(lower_bound(store.begin(), store.end(), num), num); // binary search and insertion combined
}
// Returns the median of current data stream
double findMedian()
{
int n = store.size();
return n & 1 ? store[n / 2] : (store[n / 2 - 1] + store[n / 2]) * 0.5;
}
};
如果我们可以用以下方式维护两个堆:
用于存储输入数字中较小一半的最大堆 用于存储输入数字的较大一半的最小堆 这样就可以访问输入中的中值:它们组成堆的顶部!
如果满足以下条件:
两个堆都是平衡的(或接近平衡的) 最大堆包含所有较小的数字,而最小堆包含所有较大的数字 那么我们可以这样说:
最大堆中的所有数字都小于或等于最大堆的top元素(我们称之为 xx) 最小堆中的所有数字都大于或等于最小堆的顶部元素(我们称之为 yy)
那么 xx 和 yy 几乎小于(或等于)元素的一半,大于(或等于)另一半。这就是中值元素的定义。这使我们在这种方法中遇到了一个巨大的难题:平衡这两个堆!
算法:
两个优先级队列: 用于存储较小一半数字的最大堆 lo 用于存储较大一半数字的最小堆 hi 最大堆 lo 允许存储的元素最多比最小堆 hi
多一个。因此,如果我们处理了 kk 元素: 如果 k=2n+1 \quad(\forall,n \in \mathbb
z)k=2∗n+1(∀,n∈z) 则允许 lo 持有 n+1n+1 元素,而 hi 可以持有 nn 元素。 如果
k=2n\quad(\forall,n\in\mathbb z)k=2∗n(∀,n∈z),那么两个堆都是平衡的,并且每个堆都包含 n个元素。
class MedianFinder {
private:
priority_queue<int> lo;//大顶堆
priority_queue<int, vector<int>, greater<int>> hi;//小顶堆
public:
// Adds a number into the data structure.
void addNum(int num)
{
lo.push(num);
hi.push(lo.top());
lo.pop();
if(lo.size() < hi.size()) {
lo.push(hi.top());
hi.pop();
}
}
// Returns the median of current data stream
double findMedian()
{
if(hi.size() < lo.size()) return (double)lo.top();
else return (lo.top() + hi.top()) * 0.5;
}
};
/**
* Your MedianFinder object will be instantiated and called as such:
* MedianFinder* obj = new MedianFinder();
* obj->addNum(num);
* double param_2 = obj->findMedian();
*/
149. 直线上最多的点数(☆☆☆)
给你一个数组 points ,其中 points[i] = [xi, yi] 表示 X-Y 平面上的一个点。求最多有多少个点在同一条直线上。
class Solution {
public:
int maxPoints(vector<vector<int>>& points) {
int result = 0;
int len = points.size();
if (len == 1) return 1;
for (int i = 0; i < len; ++i) {//i表示数组中的第i+1个点
//same是用来表示和i一样的点
int same = 1;
for(int j = i+1; j < len; j++) {//j表示数组中的第j+1个点
int count = 0;
//i,j在数组中是重复点,计数
if(points[i][0] == points[j][0] && points[i][1] == points[j][1]) same++;
else {// i和j不是重复点,则计算和直线ij在一条直线上的点
count++;
int xDiff = (points[i][0] - points[j][0]);// Δx1
int yDiff = (points[i][1] - points[j][1]);// Δy1
for(int k = j + 1; k < len; k++) {
if(xDiff * (points[i][1] - points[k][1]) == yDiff * (points[i][0] - points[k][0])){
count++;
}
}
}
result = max(result, same+count);
}
if(result > len/2) return result;// 若某次最大个数超过所有点的一半,则不可能存在其他直线通过更多的点
}
return result;
}
};
class Solution {
public:
int maxPoints(vector<vector<int>>& points) {
int result = 0;
int len = points.size();
if (len == 1) return 1;
for (int i = 0; i < len; ++i) {
unordered_map<double, int> mp;
for (int j = 0; j < len; ++j) {
if (i != j) {
double gradient = (points[i][1] - points[j][1]) * 1.0 / (points[i][0] - points[j][0]);
if (mp.count(gradient)) {
mp[gradient] ++;
}
else {
mp[gradient] = 2;
}
}
}
for (auto [x, y] : mp) {
result = max(result, y);
}
}
return result;
}
};
208. 实现 Trie (前缀树)(☆☆☆)
Trie(发音类似 “try”)或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
Trie() 初始化前缀树对象。
void insert(String word) 向前缀树中插入字符串 word 。
boolean search(String word) 如果字符串 word 在前缀树中,返回 true(即,在检索之前已经插入);否则,返回 false 。
boolean startsWith(String prefix) 如果之前已经插入的字符串 word 的前缀之一为 prefix ,返回 true ;否则,返回 false 。
class Trie {
public:
/** Initialize your data structure here. */
Trie() {
isEnd = false;
memset(next, 0, sizeof(next));
isEnd = false;
memset(next, 0, sizeof(next));
}
/** Inserts a word into the trie. */
void insert(string word) {
Trie* node = this;
for(char c : word) {
if(node->next[c-'a'] == NULL) {
node->next[c-'a'] = new Trie();
}
node = node->next[c-'a'];
}
node->isEnd = true;
}
/** Returns if the word is in the trie. */
bool search(string word) {
Trie* node = this;
for(char c : word) {
node = node->next[c-'a'];
if(node == NULL) return false;
}
return node->isEnd;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
bool startsWith(string prefix) {
Trie* node = this;
for(char c: prefix) {
node = node->next[c-'a'];
if(node == NULL) return false;
}
return true;
}
private:
Trie* next[26];
bool isEnd;
};
/**
* Your Trie object will be instantiated and called as such:
* Trie* obj = new Trie();
* obj->insert(word);
* bool param_2 = obj->search(word);
* bool param_3 = obj->startsWith(prefix);
*/
974. 和可被 K 整除的子数组
给定一个整数数组 A,返回其中元素之和可被 K 整除的(连续、非空)子数组的数目。
class Solution {
public:
int subarraysDivByK(vector<int>& nums, int k) {
//同余定理
unordered_map<int, int>map;
map[0] = 1;
int sum = 0, res = 0;
for(int e : nums) {
sum += e;
int zero = (sum % k + k) % k;
if(map.count(zero)) {
res += map[zero];
}
++map[zero];
}
return res;
}
};
560. 和为K的子数组
给定一个整数数组和一个整数 k,你需要找到该数组中和为 k 的连续的子数组的个数。
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
unordered_map<int,int> map;
int sum = 0;
map[0] = 1;
int res = 0;
for(int e : nums) {
sum += e;
if(map.count(sum-k)) res += map[sum - k];
map[sum]++;
}
return res;
}
};
剑指 Offer 49. 丑数
我们把只包含质因子 2、3 和 5 的数称作丑数(Ugly Number)。求按从小到大的顺序的第 n 个丑数。
class Solution {
public:
int nthUglyNumber(int n) {
//dp[i]:表示第I+1个最小丑数
//递推公式:
//初始化:dp[0] = 1;
vector<int> dp(n,0);
dp[0] = 1;//初始化丑数
int i = 0, j = 0, k = 0;//初始分别指向三个有序链表第一个元素,这三个有序链表是想象出来的,分别就是ugly数组元素分别乘以2,3,5得到的
for(int idx = 1; idx < n; idx++) {
int tmp = min({dp[i]*2, dp[j]*3, dp[k]*5});
//三个链表可能有相同元素,所以只要是最小的,都要移动指针
if(tmp == dp[i]*2) i++;
if(tmp == dp[j]*3) j++;
if(tmp == dp[k]*5) k++;
dp[idx] = tmp;
}
return dp[n-1];
}
};
剑指 Offer 44. 数字序列中某一位的数字
数字以0123456789101112131415…的格式序列化到一个字符序列中。在这个序列中,第5位(从下标0开始计数)是5,第13位是1,第19位是4,等等。
请写一个函数,求任意第n位对应的数字。
class Solution {
public:
int findNthDigit(int n) {
long base = 9, dig = 1, num = 0;
while(n > dig * base) {
n -= base * dig;
num += base;
base *= 10;
dig++;
}
num += (n-1)/dig + 1;//找到那个数字
int index = (n-1)%dig;//找到在数字中的索引
string s = to_string(num);
return int(s[index] - '0');
}
};
剑指 Offer 43. 1~n 整数中 1 出现的次数
输入一个整数 n ,求1~n这n个整数的十进制表示中1出现的次数。
例如,输入12,1~12这些整数中包含1 的数字有1、10、11和12,1一共出现了5次。
class Solution {
public:
int countDigitOne(int n) {
//高位、低位、现在位
int high = n;
int low = 0;
int cur = 0;
//
int count = 0;
long num = 1;
while(high != 0 || cur != 0) {
cur = high % 10;
high /= 10;
if(cur == 0) count += high * num;
else if(cur == 1) count += high * num + 1 + low;
else count += high*num + num;
low = cur * num + low;
num *= 10;
}
return count;
}
};
457. 环形数组是否存在循环
存在一个不含 0 的 环形 数组 nums ,每个 nums[i] 都表示位于下标 i 的角色应该向前或向后移动的下标个数:
如果 nums[i] 是正数,向前 移动 nums[i] 步
如果 nums[i] 是负数,向后 移动 nums[i] 步
因为数组是 环形 的,所以可以假设从最后一个元素向前移动一步会到达第一个元素,而第一个元素向后移动一步会到达最后一个元素。
数组中的 循环 由长度为 k 的下标序列 seq :
遵循上述移动规则将导致重复下标序列 seq[0] -> seq[1] -> … -> seq[k - 1] -> seq[0] -> …
所有 nums[seq[j]] 应当不是 全正 就是 全负
k > 1
如果 nums 中存在循环,返回 true ;否则,返回 false 。
具体地,我们检查每一个节点,令快慢指针从当前点出发,快指针每次移动两步,慢指针每次移动一步,期间每移动一次,我们都需要检查当前单向边的方向是否与初始方向是否一致,如果不一致,我们即可停止遍历,因为当前路径必然不满足条件。为了降低时间复杂度,我们可以标记每一个点是否访问过,过程中如果我们的下一个节点为已经访问过的节点,则可以停止遍历。
在实际代码中,我们无需新建一个数组记录每个点的访问情况,而只需要将原数组的对应元素置零即可(题目保证原数组中元素不为零)。遍历过程中,如果快慢指针相遇,或者移动方向改变,那么我们就停止遍历,并将快慢指针经过的点均置零即可。
class Solution {
public:
bool circularArrayLoop(vector<int>& nums) {
n = nums.size();
for(int i = 0; i < nums.size(); i++) {
int slow = i, fast = next(i, nums);
//检查同向
while(nums[fast] * nums[slow] > 0 && nums[next(fast, nums)] * nums[slow] > 0) {
if(fast == slow) {
if(slow == next(slow, nums)) break;//存在长度为1的同向环
else return true;
}
//指针移动
fast = next(next(fast, nums), nums);
slow = next(slow, nums);
}
int k = i;
while(nums[k] * nums[next(k, nums)] > 0) {
int tmp = k;
k = next(k, nums);
nums[tmp] = 0;
}
}
return false;
}
private:
int n;
int next(int num, vector<int>& nums) {//计算出下一个位置的下标
return (((num + nums[num]) % n) + n) % n;//把这个下标固定到0~n-1内
}
};
992. K 个不同整数的子数组
给定一个正整数数组 A,如果 A 的某个子数组中不同整数的个数恰好为 K,则称 A 的这个连续、不一定不同的子数组为好子数组。
(例如,[1,2,3,1,2] 中有 3 个不同的整数:1,2,以及 3。)
返回 A 中好子数组的数目。
「最多存在 KK 个不同整数的子区间的个数」- 「恰好存在 K 个不同整数的子区间的个数」=「最多存在 K - 1K−1 个不同整数的子区间的个数」
class Solution {
public:
int subarraysWithKDistinct(vector<int>& nums, int k) {
return help(nums,k) - help(nums,k-1);
}
int help(vector<int>& nums, int k) {
int left = 0, right = 0, res = 0;
unordered_map<int, int>m;
while(right < nums.size()) {
m[nums[right]]++;
right++;
while(m.size() > k) {
m[nums[left]]--;
if(m[nums[left]] == 0) m.erase(nums[left]);
left++;
}
res += right-left;
}
return res;
}
};
剑指 Offer 35. 复杂链表的复制
请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者 null。

/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
Node* copyRandomList(Node* head) {
if(head == nullptr) return nullptr;
Node* cur = head;
// 1. 复制各节点,并构建拼接链表
while(cur != nullptr){
Node* tmp = new Node(cur->val);
tmp->next = cur->next;
cur->next = tmp;
cur = tmp->next;
}
// 2. 构建各新节点的 random 指向
cur = head;
while(cur != nullptr) {
if(cur->random != nullptr) {
cur->next->random = cur->random->next;
}
cur = cur->next->next;
}
// 3. 拆分两链表
cur = head->next;
Node* pre = head, *res = head->next;
while(cur->next != nullptr) {
pre->next = pre->next->next;
cur->next = cur->next->next;
pre = pre->next;
cur = cur->next;
}
pre->next = nullptr; // 单独处理原链表尾节点
return res; // 返回新链表头节点
}
};
48. 旋转图像
给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
int n = matrix.size();
// 水平翻转
for (int i = 0; i < n / 2; ++i) {
for (int j = 0; j < n; ++j) {
swap(matrix[i][j], matrix[n - i - 1][j]);
}
}
// 主对角线翻转
for (int i = 0; i < n; ++i) {
for (int j = 0; j < i; ++j) {
swap(matrix[i][j], matrix[j][i]);
}
}
}
};
1654. 到家的最少跳跃次数
有一只跳蚤的家在数轴上的位置 x 处。请你帮助它从位置 0 出发,到达它的家。
跳蚤跳跃的规则如下:
它可以 往前 跳恰好 a 个位置(即往右跳)。
它可以 往后 跳恰好 b 个位置(即往左跳)。
它不能 连续 往后跳 2 次。
它不能跳到任何 forbidden 数组中的位置。
跳蚤可以往前跳 超过 它的家的位置,但是它 不能跳到负整数 的位置。
给你一个整数数组 forbidden ,其中 forbidden[i] 是跳蚤不能跳到的位置,同时给你整数 a, b 和 x ,请你返回跳蚤到家的最少跳跃次数。如果没有恰好到达 x 的可行方案,请你返回 -1 。
class Solution {
public:
//到家的最少跳跃次数
struct point {
int back;
int pos;
int step;
point(int back, int pos, int step) {
this->back = back;
this->pos = pos;
this->step = step;
}
};
int minimumJumps(vector<int>& forbidden, int a, int b, int x) {
//不能跳到负整数位置 和 forbidden 位置
//不能连续往后跳两次
unordered_set<int> uset;
for (auto k : forbidden) uset.insert(k);
queue<point> q;
q.push(point(0, 0, 0));
while (!q.empty()) {
point p = q.front();
q.pop();
if (p.pos == x) return p.step;
//前
if (uset.count(p.pos + a) == 0 && p.pos + a <= 6000) {
q.push(point(0, p.pos + a, p.step + 1));
uset.insert(p.pos + a); //加入队列就标记为访问过
}
//后
if (p.pos - b >= 0 && uset.count(p.pos - b) == 0 && p.back == 0) {
q.push(point(1, p.pos - b, p.step + 1));
//向后不需要标记为访问过
}
}
return -1;
}
};