LeetCode 324 周赛
2506. 统计相似字符串对的数目
给你一个下标从 0 开始的字符串数组 words 。
如果两个字符串由相同的字符组成,则认为这两个字符串 相似 。
- 例如,
"abca"和"cba"相似,因为它们都由字符'a'、'b'、'c'组成。 - 然而,
"abacba"和"bcfd"不相似,因为它们不是相同字符组成的。
请你找出满足字符串 words[i] 和 words[j] 相似的下标对 (i, j) ,并返回下标对的数目,其中 0 <= i < j <= word.length - 1 。
提示:
1 <= words.length <= 1001 <= words[i].length <= 100words[i]仅由小写英文字母组成
示例:
输入:words = ["aba","aabb","abcd","bac","aabc"]
输出:2
解释:共有 2 对满足条件:
- i = 0 且 j = 1 :words[0] 和 words[1] 只由字符 'a' 和 'b' 组成。
- i = 3 且 j = 4 :words[3] 和 words[4] 只由字符 'a'、'b' 和 'c' 。
思路:
统计每个字符串中都出现了哪些字母,然后用暴力进行两两比较,找出相似的字符串即可。
关键是如何表示一个字符串的组成?
比如abac,abc,这两个串都只由a,b,c三个字符串组成。我们如何表示这种特征?
由于字符串仅由小写英文字母组成,而小写英文字母一共只有26个,我们可以用一共26位的二进制数来表示某个字符串的组成。a对应二进制串的第一位,b对应第二位,…,z对应第26位。
如果某个字符在字符串中出现了,我们将对应的位置为1,否则置为0。这样对每个字符串进行一下处理,就能得到这个字符串的特征表示。然后用两重循环进行两两比较即可。
一个int有32位,足够存储这样的状态了。所以我们将每个字符串处理成一个int即可。
class Solution {
public:
int similarPairs(vector<string>& words) {
int n = words.size();
vector<int> st(n); // 特征数组
for (int i = 0; i < n; i++) {
int s = 0;
for (char c : words[i]) s |= 1 << (c - 'a');
st[i] = s;
}
int ans = 0;
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
if (st[i] == st[j]) ans++;
}
}
return ans;
}
};
2507. 使用质因数之和替换后可以取到的最小值
给你一个正整数 n 。
请你将 n 的值替换为 n 的 质因数 之和,重复这一过程。
- 注意,如果
n能够被某个质因数多次整除,则在求和时,应当包含这个质因数同样次数。
返回 n 可以取到的最小值。
提示:
2 <= n <= 10^5
示例:
输入:n = 15
输出:5
解释:最开始,n = 15 。
15 = 3 * 5 ,所以 n 替换为 3 + 5 = 8 。
8 = 2 * 2 * 2 ,所以 n 替换为 2 + 2 + 2 = 6 。
6 = 2 * 3 ,所以 n 替换为 2 + 3 = 5 。
5 是 n 可以取到的最小值。
思路:
模拟即可,这道题考察的是质数相关的知识(质因数分解)。
class Solution {
public:
int smallestValue(int n) {
int pre = 0;
// 当处理前和处理后得到的n相同, 则无法继续变小了
while (pre != n) {
pre = n; // 暂存处理前的n
int sum = 0;
// 进行质因数分解
for (int i = 2; i <= n / i; i++) {
while (n % i == 0) {
sum += i;
n /= i;
}
}
if (n > 1) sum += n;
n = sum; // 处理后的n
}
return n;
}
};
2508. 添加边使所有节点度数都为偶数
给你一个有 n 个节点的 无向 图,节点编号为 1 到 n 。再给你整数 n 和一个二维整数数组 edges ,其中 edges[i] = [ai, bi] 表示节点 ai 和 bi 之间有一条边。图不一定连通。
你可以给图中添加 至多 两条额外的边(也可以一条边都不添加),使得图中没有重边也没有自环。
如果添加额外的边后,可以使得图中所有点的度数都是偶数,返回 true ,否则返回 false 。
点的度数是连接一个点的边的数目。
提示:
3 <= n <= 10^52 <= edges.length <= 10^5edges[i].length == 21 <= ai, bi <= nai != bi- 图中不会有重边
示例:
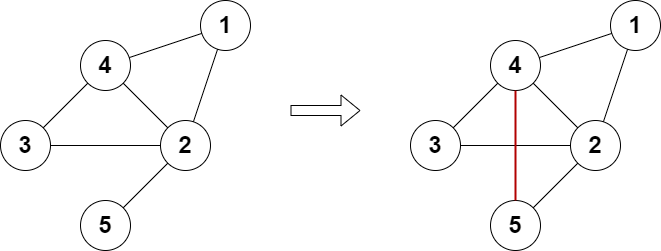
输入:n = 5, edges = [[1,2],[2,3],[3,4],[4,2],[1,4],[2,5]]
输出:true
解释:上图展示了添加一条边的合法方案。
最终图中每个节点都连接偶数条边。
思路:
这道题目,我自己做的时候是采用的分类讨论,因为最多添加2条额外的边,情况非常少。
我们的目标是添加至多2条边,使得所有点的度数都为偶数。
首先来看,添加一条边,这条边一定会连接2个点,会使得2个点的度数各自增加1。所以添加一条边,最多能干掉2个奇数度数的点。至多2条边,则最多干掉4个奇数度数的点。
我们考虑图中度数为奇数的点的个数oddNum
-
oddNum = 0,直接返回true -
oddNum = 1,直接返回false,因为添加一条边,一定会使得2个点的度数各自加1 -
oddNum = 2,设这两个点为a,b- 如果
a, b之间不存在边,则直接在a, b之间连一条边即可,返回true; - 如果
a, b之间存在边,则不能连接a, b(因为会形成自环);尝试在a, b之外找一个点x,x与a, b之间都没有边,则可以连一条边a, x,再连一条边b, x;若能找到这样的点x,返回true;
- 如果
-
oddNum = 3,直接返回false,只要个数为奇数,都一定返回false -
oddNum = 4,设这4个点为a, b, c, d因为最多只能连2条边,所以这两条边的4个顶点都一定是
a, b, c, d,关键看如何两两组合。只需要枚举全部的组合(实际一共只有3种组合),只要有1种组合方式合法,就返回
true -
oddNum > 4,直接返回false超过4后,若为奇数肯定不行;若为偶数则边不够用。
由上面的分析可知,当度数为奇数的点的个数,为奇数时,直接返回false即可;个数为偶数时,只需要对2和4的情况分类讨论一下,超过4的也直接返回false即可。
关键在于我们如何快速判断两个点之间是否存在边。这里我采用的是将一对邻接点[a, b]看成一个二维状态,然后将二维状态转成一维。
typedef long long LL;
class Solution {
public:
// 这里若开一个二维数组, 或者二维的vector, 会超出内存限制
unordered_set<LL> adj; // 邻接点的关系
int n;
bool isAdjacent(int a, int b) {
return adj.count((LL) a * n + b);
}
bool isPossible(int n, vector<vector<int>>& edges) {
this->n = n;
// 统计每个点的度
vector<int> dg(n + 1);
for (auto& e : edges) {
int a = e[0], b = e[1];
dg[a]++;
dg[b]++;
adj.emplace((LL) a * n + b);
adj.emplace((LL) b * n + a);
}
// 度数为奇数的点
vector<int> oddNodes;
for (int i = 1; i <= n; i++) {
if (dg[i] & 1) oddNodes.push_back(i);
}
int oddNum = oddNodes.size();
// 若为奇数, 或超过4, 直接返回false
if ((oddNum & 1) || oddNum > 4) return false;
if (oddNum == 0) return true;
// 讨论2的情况
if (oddNum == 2) {
int a = oddNodes[0], b = oddNodes[1];
if (!isAdjacent(a, b)) return true; // 直接连接a,b
// 尝试找到一个与a和b都不相邻的点
for (int i = 1; i <= n; i++) {
if (i == a || i == b) continue;
if (!isAdjacent(i, a) && !isAdjacent(i, b)) return true; // 找到了这样的点
}
// 没找到
return false;
}
// 讨论4的情况
if (oddNum == 4) {
int a = oddNodes[0], b = oddNodes[1], c = oddNodes[2], d = oddNodes[3];
if (!isAdjacent(a, b) && !isAdjacent(c, d)) return true;
if (!isAdjacent(a, c) && !isAdjacent(b, d)) return true;
if (!isAdjacent(a, d) && !isAdjacent(b, c)) return true;
}
return false;
}
};
2509. 查询树中环的长度
给你一个整数 n ,表示你有一棵含有 2 n − 1 2^n - 1 2n−1 个节点的 完全二叉树 。根节点的编号是 1 ,树中编号在 [ 1 , 2 n − 1 − 1 ] [1, 2^{n - 1} - 1] [1,2n−1−1] 之间,编号为 val 的节点都有两个子节点,满足:
- 左子节点的编号为
2 * val - 右子节点的编号为
2 * val + 1
给你一个长度为 m 的查询数组 queries ,它是一个二维整数数组,其中 queries[i] = [ai, bi] 。对于每个查询,求出以下问题的解:
- 在节点编号为
ai和bi之间添加一条边。 - 求出图中环的长度。
- 删除节点编号为
ai和bi之间新添加的边。
注意:
- 环 是开始和结束于同一节点的一条路径,路径中每条边都只会被访问一次。
- 环的长度是环中边的数目。
- 在树中添加额外的边后,两个点之间可能会有多条边。
请你返回一个长度为 m 的数组 answer ,其中 answer[i] 是第 i 个查询的结果*。*
提示:
2 <= n <= 30m == queries.length1 <= m <= 10^5queries[i].length == 21 <= ai, bi <= 2^n - 1ai != bi
示例:

输入:n = 3, queries = [[5,3],[4,7],[2,3]]
输出:[4,5,3]
解释:上图是一棵有 23 - 1 个节点的树。红色节点表示添加额外边后形成环的节点。
- 在节点 3 和节点 5 之间添加边后,环为 [5,2,1,3] ,所以第一个查询的结果是 4 。删掉添加的边后处理下一个查询。
- 在节点 4 和节点 7 之间添加边后,环为 [4,2,1,3,7] ,所以第二个查询的结果是 5 。删掉添加的边后处理下一个查询。
- 在节点 2 和节点 3 之间添加边后,环为 [2,1,3] ,所以第三个查询的结果是 3 。删掉添加的边。
思路:
这场周赛的T4还是比较简单的。
只需要找到两个点的最近公共祖先,看一下这个公共祖先到两个点之间的路径长度,将两条路径长度相加,再加上1(新添加的边),即可。
由于是完全二叉树,找2个点的公共祖先还是比较简单的,先将两个点按照深度进行对齐,然后同时往上走即可。每次寻找最近公共祖先最多需要30次运算,而查询一共是10^5,总的复杂度为3 × 10^6,是不会超时的。所以直接这样暴力做就行了。
class Solution {
public:
// 找到编号为x的节点所处的深度
// 第0层的节点编号范围是[2^0, 2^1)
// ....
// 第n层的节点编号范围是[2^n,2^(n+1))
// 只需要找到最后一个满足 2^n >= x 的 n 即可
int search(int x) {
int l = 0, r = 30;
while (l < r) {
int mid = l + r + 1 >> 1;
if (x >= (1 << mid)) l = mid;
else r = mid - 1;
}
return l;
}
// 找到a和b的最近公共祖先, 然后返回公共祖先到这两个点的距离的长度之和
int find(int a, int b) {
// 先将a和b进行对齐
int mx = max(a, b), mi = min(a, b);
int dep_mi = search(mi), dep_mx = search(mx);
int gap = dep_mx - dep_mi, ret = gap;
while (gap--) mx /= 2;
// 然后一起向上走
while (mx != mi) {
ret += 2;
mx /= 2;
mi /= 2;
}
return ret;
}
vector<int> cycleLengthQueries(int n, vector<vector<int>>& queries) {
int k = queries.size();
vector<int> ans(k);
for (int i = 0; i < k; i++) {
int a = queries[i][0], b = queries[i][1];
ans[i] = find(a, b) + 1;
}
return ans;
}
};
总结
很遗憾没有参加这场周赛,痛失一次AK的机会!
T1是暴力模拟(可以留意一下使用位运算提取特征的技巧);T2是数论(分解质因数);T3是分类讨论;T4是一道简单的图论,找最近公共祖先。