工作5年,没用过分布式锁,正常吗?
公司想招聘一个5年开发经验的后端程序员,看了很多简历,发现一个共性问题,普遍都没用过分布式锁,这正常吗?
下面是已经入职的一位小伙伴的个人技能包,乍一看,还行,也没用过分布式锁。

午休的时候,和她聊了聊,她之前在一家对日的公司。
- 需求是产品谈好的;
- 系统设计、详细设计是PM做的;
- 接口文档、数据库设计书是日本公司提供的;
- 最夸张的是,就连按钮的颜色,文档中都有标注...
- 她需要做的,就只是照着接口文档去编码、测试就ok了。
有的面试者工作了5年,做的都是自家产品,项目只有两个,翻来覆去的改BUG,加需求,做运维。 技术栈很老,还是SSM那一套,最近在改造,终于用上了SpringBoot... 微服务、消息中间件、分布式锁根本没用过...
还有的面试者,在XX大厂工作,中间做了一年C#,一年Go,一看简历很华丽,精通三国语言,其实不然,都处于入门阶段,毫无竞争力可言。
一时兴起,说多了,言归正传,总结一篇分布式锁的文章,丰富个人简历,提高面试level,给自己增加一点谈资,秒变面试小达人,BAT不是梦。
一、分布式锁的重要性与挑战
1.1 分布式系统中的并发问题
在现代分布式系统中,由于多个节点同时操作共享资源,常常会引发各种并发问题。这些问题包括竞态条件、数据不一致、死锁等,给系统的稳定性和可靠性带来了挑战。让我们深入探讨在分布式系统中出现的一些并发问题:
竞态条件

竞态条件指的是多个进程或线程在执行顺序上产生了不确定性,从而导致程序的行为变得不可预测。在分布式系统中,多个节点同时访问共享资源,如果没有合适的同步机制,就可能引发竞态条件。例如,在一个电商平台中,多个用户同时尝试购买一个限量商品,如果没有良好的同步机制,就可能导致超卖问题。
数据不一致

在分布式系统中,由于数据的拆分和复制,数据的一致性可能受到影响。多个节点同时对同一个数据进行修改,如果没有适当的同步措施,就可能导致数据不一致。例如,在一个社交网络应用中,用户在不同的节点上修改了自己的个人资料,如果没有同步机制,就可能导致数据不一致,影响用户体验。
死锁

死锁是指多个进程或线程因相互等待对方释放资源而陷入无限等待的状态。在分布式系统中,多个节点可能同时竞争资源,如果没有良好的协调机制,就可能出现死锁情况。例如,多个节点同时尝试获取一组分布式锁,但由于顺序不当,可能导致死锁问题。。
二、分布式锁的基本原理与实现方式
2.1 分布式锁的基本概念
分布式锁是分布式系统中的关键概念,用于解决多个节点同时访问共享资源可能引发的并发问题。以下是分布式锁的一些基本概念:
- 锁(Lock):锁是一种同步机制,用于确保在任意时刻只有一个节点(进程或线程)可以访问共享资源。锁可以防止竞态条件和数据不一致问题。
- 共享资源(Shared Resource):共享资源是多个节点需要访问或修改的数据、文件、服务等。在分布式系统中,多个节点可能同时尝试访问这些共享资源,从而引发问题。
- 锁的状态:锁通常有两种状态,即锁定状态和解锁状态。在锁定状态下,只有持有锁的节点可以访问共享资源,其他节点被阻塞。在解锁状态下,任何节点都可以尝试获取锁。
- 竞态条件(Race Condition):竞态条件指的是多个节点在执行顺序上产生了不确定性,导致程序的行为变得不可预测。在分布式系统中,竞态条件可能导致多个节点同时访问共享资源,破坏了系统的一致性。
- 数据不一致(Data Inconsistency):数据不一致是指多个节点对同一个数据进行修改,但由于缺乏同步机制,数据可能处于不一致的状态。这可能导致应用程序出现错误或异常行为。
- 死锁(Deadlock):死锁是多个节点因相互等待对方释放资源而陷入无限等待的状态。在分布式系统中,多个节点可能同时竞争资源,如果没有良好的协调机制,就可能出现死锁情况。
分布式锁的基本目标是解决这些问题,确保多个节点在访问共享资源时能够安全、有序地进行操作,从而保持数据的一致性和系统的稳定性。
2.2 基于数据库的分布式锁
原理与实现方式
一种常见的分布式锁实现方式是基于数据库。在这种方式下,每个节点在访问共享资源之前,首先尝试在数据库中插入一条带有唯一约束的记录。如果插入成功,说明节点成功获取了锁;否则,说明锁已经被其他节点占用。
数据库分布式锁的原理比较简单,但实现起来需要考虑一些问题。以下是一些关键点:
- 唯一约束(Unique Constraint):数据库中的唯一约束确保了只有一个节点可以成功插入锁记录。这可以通过数据库的表结构来实现,确保锁记录的键是唯一的。
- 超时时间(Timeout):为了避免节点在获取锁后崩溃导致锁无法释放,通常需要设置锁的超时时间。如果节点在超时时间内没有完成操作,锁将自动释放,其他节点可以获取锁。
- 事务(Transaction):数据库事务机制可以确保数据的一致性。在获取锁和释放锁的过程中,可以使用事务来包装操作,确保操作是原子的。

在图中,节点A尝试在数据库中插入锁记录,如果插入成功,表示节点A获取了锁,可以执行操作。操作完成后,节点A释放了锁。如果插入失败,表示锁已经被其他节点占用,节点A需要处理锁争用的情况。
优缺点
| 优点 | 缺点 |
| 实现相对简单,不需要引入额外的组件。 | 性能相对较差,数据库的IO开销较大。 |
| 可以使用数据库的事务机制确保数据的一致性。 | 容易产生死锁,需要谨慎设计。 |
| 不适用于高并发场景,可能成为系统的瓶颈。 |
这个表格对基于数据库的分布式锁的优缺点进行了简明的总结。
2.3 基于缓存的分布式锁
原理与实现方式
另一种常见且更为高效的分布式锁实现方式是基于缓存系统,如Redis。在这种方式下,每个节点尝试在缓存中设置一个带有过期时间的键,如果设置成功,则表示获取了锁;否则,表示锁已经被其他节点占用。
基于缓存的分布式锁通常使用原子操作来实现,确保在并发环境下锁的获取是安全的。Redis提供了类似SETNX(SET if Not
eXists)的命令来实现这种原子性操作。此外,我们还可以为锁设置一个过期时间,避免节点在获取锁后崩溃导致锁一直无法释放。
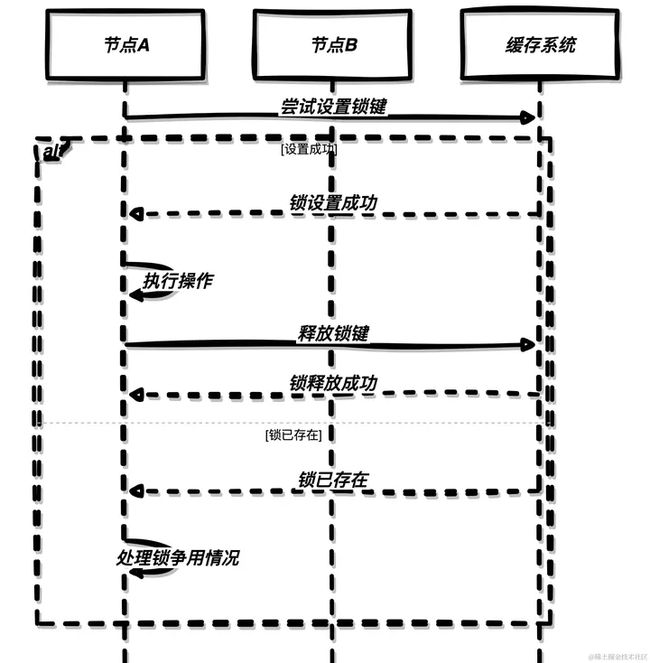
上图中,节点A尝试在缓存系统中设置一个带有过期时间的锁键,如果设置成功,表示节点A获取了锁,可以执行操作。操作完成后,节点A释放了锁键。如果设置失败,表示锁已经被其他节点占用,节点A需要处理锁争用的情况。
优缺点
| 优点 | 缺点 |
| 性能较高,缓存系统通常在内存中操作,IO开销较小。 | 可能存在缓存失效和节点崩溃等问题,需要额外处理。 |
| 可以使用缓存的原子操作确保获取锁的安全性。 | 需要依赖外部缓存系统,引入了系统的复杂性。 |
| 适用于高并发场景,不易成为系统的瓶颈。 |
通过基于数据库和基于缓存的分布式锁实现方式,我们可以更好地理解分布式锁的基本原理以及各自的优缺点。根据实际应用场景和性能要求,选择合适的分布式锁实现方式非常重要。
三、Redis分布式锁的实现与使用
3.1 使用SETNX命令实现分布式锁
在Redis中,可以使用SETNX(SET if Not eXists)命令来实现基本的分布式锁。SETNX命令会尝试在缓存中设置一个键值对,如果键不存在,则设置成功并返回1;如果键已存在,则设置失败并返回0。通过这一机制,我们可以利用SETNX来创建分布式锁。
以下是一个使用SETNX命令实现分布式锁的Java代码示例:
import redis.clients.jedis.Jedis;
public class DistributedLockExample {
private Jedis jedis;
public DistributedLockExample() {
jedis = new Jedis("localhost", 6379);
}
public boolean acquireLock(String lockKey, String requestId, int expireTime) {
Long result = jedis.setnx(lockKey, requestId);
if (result == 1) {
jedis.expire(lockKey, expireTime);
return true;
}
return false;
}
public void releaseLock(String lockKey, String requestId) {
String storedRequestId = jedis.get(lockKey);
if (storedRequestId != null && storedRequestId.equals(requestId)) {
jedis.del(lockKey);
}
}
public static void main(String[] args) {
DistributedLockExample lockExample = new DistributedLockExample();
String lockKey = "resource:lock";
String requestId = "request123";
int expireTime = 60; // 锁的过期时间
if (lockExample.acquireLock(lockKey, requestId, expireTime)) {
try {
// 执行需要加锁的操作
System.out.println("Lock acquired. Performing critical section.");
Thread.sleep(1000); // 模拟操作耗时
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lockExample.releaseLock(lockKey, requestId);
System.out.println("Lock released.");
}
} else {
System.out.println("Failed to acquire lock.");
}
}
}3.2 设置超时与防止死锁
在上述代码中,我们通过使用expire命令为锁设置了一个过期时间,以防止节点在获取锁后崩溃或异常退出,导致锁一直无法释放。设置合理的过期时间可以避免锁长时间占用而导致的资源浪费。
3.3 锁的可重入性与线程安全性
分布式锁需要考虑的一个问题是可重入性,即同一个线程是否可以多次获取同一把锁而不被阻塞。通常情况下,分布式锁是不具备可重入性的,因为每次获取锁都会生成一个新的标识(如requestId),不会与之前的标识相同。
为了解决可重入性的问题,我们可以引入一个计数器,记录某个线程获取锁的次数。当线程再次尝试获取锁时,只有计数器为0时才会真正获取锁,否则只会增加计数器。释放锁时,计数器减少,直到为0才真正释放锁。
需要注意的是,为了保证分布式锁的线程安全性,我们应该使用线程本地变量来存储requestId,以防止不同线程之间的干扰。

四、分布式锁的高级应用与性能考虑
4.1 锁粒度的选择
在分布式锁的应用中,选择合适的锁粒度是非常重要的。锁粒度的选择会直接影响系统的性能和并发能力。 一般而言,锁粒度可以分为粗粒度锁和细粒度锁。
- 粗粒度锁:将较大范围的代码块加锁,可能导致并发性降低,但减少了锁的开销。适用于对数据一致性要求不高,但对并发性能要求较低的场景。
- 细粒度锁:将较小范围的代码块加锁,提高了并发性能,但可能增加了锁的开销。适用于对数据一致性要求高,但对并发性能要求较高的场景。
在选择锁粒度时,需要根据具体业务场景和性能需求进行权衡,避免过度加锁或锁不足的情况。
4.2 基于RedLock的多Redis实例锁
RedLock算法是一种在多个Redis实例上实现分布式锁的算法,用于提高锁的可靠性。由于单个Redis实例可能由于故障或网络问题而导致分布式锁的失效,通过使用多个Redis实例,我们可以降低锁失效的概率。
RedLock算法的基本思想是在多个Redis实例上创建相同的锁,并使用SETNX命令来尝试获取锁。在获取锁时,还需要检查大部分Redis实例的时间戳,确保锁在多个实例上的时间戳是一致的。只有当大部分实例的时间戳一致时,才认为锁获取成功。
以下是基于RedLock的分布式锁的Java代码示例:
import redis.clients.jedis.Jedis;
public class RedLockExample {
private static final int QUORUM = 3;
private static final int LOCK_TIMEOUT = 500;
private Jedis[] jedisInstances;
public RedLockExample() {
jedisInstances = new Jedis[]{
new Jedis("localhost", 6379),
new Jedis("localhost", 6380),
new Jedis("localhost", 6381)
};
}
public boolean acquireLock(String lockKey, String requestId) {
int votes = 0;
long start = System.currentTimeMillis();
while ((System.currentTimeMillis() - start) < LOCK_TIMEOUT) {
for (Jedis jedis : jedisInstances) {
if (jedis.setnx(lockKey, requestId) == 1) {
jedis.expire(lockKey, LOCK_TIMEOUT / 1000); // 设置锁的超时时间
votes++;
}
}
if (votes >= QUORUM) {
return true;
} else {
// 未获取到足够的票数,释放已获得的锁
for (Jedis jedis : jedisInstances) {
if (jedis.get(lockKey).equals(requestId)) {
jedis.del(lockKey);
}
}
}
try {
Thread.sleep(50); // 等待一段时间后重试
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
return false;
}
public void releaseLock(String lockKey, String requestId) {
for (Jedis jedis : jedisInstances) {
if (jedis.get(lockKey).equals(requestId)) {
jedis.del(lockKey);
}
}
}
public static void main(String[] args) {
RedLockExample redLockExample = new RedLockExample();
String lockKey = "resource:lock";
String requestId = "request123";
if (redLockExample.acquireLock(lockKey, requestId)) {
try {
// 执行需要加锁的操作
System.out.println("Lock acquired. Performing critical section.");
Thread.sleep(1000); // 模拟操作耗时
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
redLockExample.releaseLock(lockKey, requestId);
System.out.println("Lock released.");
}
} else {
System.out.println("Failed to acquire lock.");
}
}
}4.3 分布式锁的性能考虑
分布式锁的引入会增加系统的复杂性和性能开销,因此在使用分布式锁时需要考虑其对系统性能的影响。
一些性能优化的方法包括:
- 减少锁的持有时间:尽量缩短代码块中的加锁时间,以减少锁的竞争和阻塞。
- 使用细粒度锁:避免一次性加锁过多的资源,尽量选择合适的锁粒度,减小锁的粒度。
- 选择高性能的锁实现:比如基于缓存的分布式锁通常比数据库锁性能更高。
- 合理设置锁的超时时间:避免长时间的锁占用,导致资源浪费。
- 考虑并发量和性能需求:根据系统的并发量和性能需求,合理设计锁的策略和方案。
分布式锁的高级应用需要根据实际情况来选择适当的策略,以保证系统的性能和一致性。在考虑性能优化时,需要综合考虑锁的粒度、并发量、可靠性等因素。

五、常见并发问题与分布式锁的解决方案对比
5.1 高并发场景下的数据一致性问题
在高并发场景下,数据一致性是一个常见的问题。多个并发请求同时修改相同的数据,可能导致数据不一致的情况。分布式锁是解决这一问题的有效方案之一,与其他解决方案相比,具有以下优势:
- 原子性保证: 分布式锁可以保证一组操作的原子性,从而确保多个操作在同一时刻只有一个能够执行,避免了并发冲突。
- 简单易用: 分布式锁的使用相对简单,通过加锁和释放锁的操作,可以有效地保证数据的一致性。
- 广泛适用: 分布式锁适用于不同的数据存储系统,如关系型数据库、NoSQL数据库和缓存系统。
相比之下,其他解决方案可能需要更复杂的逻辑和额外的处理,例如使用乐观锁、悲观锁、分布式事务等。虽然这些方案在一些场景下也是有效的,但分布式锁作为一种通用的解决方案,在大多数情况下都能够提供简单而可靠的数据一致性保证。
5.2 唯一性约束与分布式锁
唯一性约束是另一个常见的并发问题,涉及到确保某些操作只能被执行一次,避免重复操作。例如,在分布式环境中,我们可能需要确保只有一个用户能够创建某个资源,或者只能有一个任务被执行。
分布式锁可以很好地解决唯一性约束的问题。当一个请求尝试获取分布式锁时,如果获取成功,说明该请求获得了执行权,可以执行需要唯一性约束的操作。其他请求获取锁失败,意味着已经有一个请求在执行相同操作了,从而避免了重复操作。
与其他解决方案相比,分布式锁的实现相对简单,不需要修改数据表结构或增加额外的约束。而其他方案可能涉及数据库的唯一性约束、队列的消费者去重等,可能需要更多的处理和调整。
六、最佳实践与注意事项
6.1 分布式锁的最佳实践
分布式锁是一种强大的工具,但在使用时需要遵循一些最佳实践,以确保系统的可靠性和性能。以下是一些关键的最佳实践:
选择合适的场景
分布式锁适用于需要确保数据一致性和控制并发的场景,但并不是所有情况都需要使用分布式锁。在设计中,应仔细评估业务需求,选择合适的场景使用分布式锁,避免不必要的复杂性。
例子:
适合使用分布式锁的场景包括:订单支付、库存扣减等需要强一致性和避免并发问题的操作。
反例:
对于只读操作或者数据不敏感的操作,可能不需要使用分布式锁,以避免引入不必要的复杂性。
锁粒度的选择
在使用分布式锁时,选择适当的锁粒度至关重要。锁粒度过大可能导致性能下降,而锁粒度过小可能增加锁争用的风险。需要根据业务场景和数据模型选择恰当的锁粒度。
例子:
在订单系统中,如果需要同时操作多个订单,可以将锁粒度设置为每个订单的粒度,而不是整个系统的粒度。
反例:
如果锁粒度过大,比如在整个系统级别上加锁,可能会导致并发性能下降。
设置合理的超时时间
为锁设置合理的超时时间是防止死锁和资源浪费的重要步骤。过长的超时时间可能导致锁长时间占用,而过短的超时时间可能导致锁被频繁释放,增加了锁争用的可能性。
例子:
如果某个操作的正常执行时间不超过5秒,可以设置锁的超时时间为10秒,以确保在正常情况下能够释放锁。
反例:
设置过长的超时时间可能导致锁被长时间占用,造成资源浪费。
6.2 避免常见陷阱与错误
在使用分布式锁时,还需要注意一些常见的陷阱和错误,以避免引入更多问题:
重复释放锁
在释放锁时,确保只有获取锁的请求才能进行释放操作。重复释放锁可能导致其他请求获取到不应该获取的锁。
例子:
// 错误的释放锁方式
if (storedRequestId != null) {
jedis.del(lockKey);
}正例:
// 正确的释放锁方式
if (storedRequestId != null && storedRequestId.equals(requestId)) {
jedis.del(lockKey);
}锁的可重入性
在实现分布式锁时,考虑锁的可重入性是必要的。某个请求在获取了锁后,可能还会在同一个线程内再次请求获取锁。在实现时需要保证锁是可重入的。
例子:
// 错误的可重入性处理
if (lockExample.acquireLock(lockKey, requestId, expireTime)) {
// 执行操作
lockExample.acquireLock(lockKey, requestId, expireTime); // 错误:再次获取锁
lockExample.releaseLock(lockKey, requestId);
}正例:
// 正确的可重入性处理
if (lockExample.acquireLock(lockKey, requestId, expireTime)) {
try {
// 执行操作
} finally {
lockExample.releaseLock(lockKey, requestId);
}
}锁的正确释放
确保锁的释放操作在正确的位置进行,以免在锁未释放的情况下就进入了下一个阶段,导致数据不一致。
例子:
// 错误的锁释放位置
if (lockExample.acquireLock(lockKey, requestId, expireTime)) {
// 执行操作
lockExample.releaseLock(lockKey, requestId); // 错误:锁未释放就执行了下一步操作
// 执行下一步操作
}正例:
// 正确的锁释放位置
if (lockExample.acquireLock(lockKey, requestId, expireTime)) {
try {
// 执行操作
} finally {
lockExample.releaseLock(lockKey, requestId);
}
}不应滥用锁
分布式锁虽然能够解决并发问题,但过度使用锁可能会降低系统性能。在使用分布式锁时,需要在性能和一致性之间做出权衡。
例子:
不应该在整个系统的每个操作都加上分布式锁,以避免锁竞争过于频繁导致性能问题。
正例:
只在必要的操作中加入分布式锁,以保证一致性的同时最大程度地减少锁竞争。
通过遵循以上最佳实践和避免常见陷阱与错误,可以更好地使用分布式锁来实现数据一致性和并发控制,确保分布式系统的可靠性和性能。