ArrayList和linkedList的区别
ArrayList和linkedList的区别
文章目录
- ArrayList和linkedList的区别
-
- 1. ArrayList 和LinkedList结构不同
- 2. 效率不同
-
- 1.添加效率
-
- 1.往集合中间插入数据时ArrayList比linkedList慢
- 2. ArrayList正好扩容的时候添加数据要比LinkedList慢
- 2. 删除数据
- 3. 查询数据
1. ArrayList 和LinkedList结构不同
可以说ArrayList和LinkedList除了是同属于集合类,其他都是不同的,因为他们本身的实现是两种不同的实现方式,ArrayList 维护的是一个动态数组,LinkedList维护的是一个双向链表,而他们之间的不同是数组与链表的特性比较;
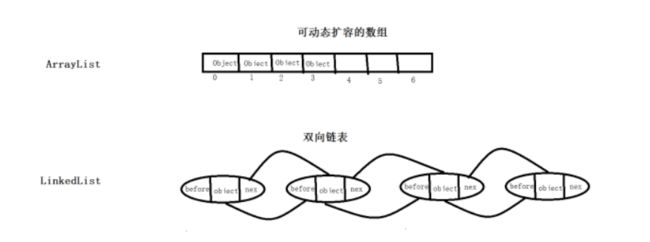
2. 效率不同
网上很多说法都比较笼统“ArrayList查询快、LinkedList添加删除快”,经过实践后发现的结论和上面有一点不同;
1.添加效率
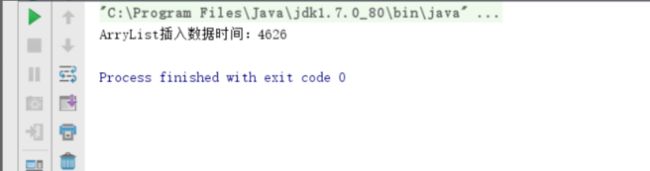
用ArrayList和LinkedList分别插入1000万数据测试,ArrayList 插入1000万数据 4626 毫秒;
LinkedList 插入1000万数据 9546毫秒;
public static void main(String[] args) {
ArrayList arrayList=new ArrayList();
//ArrayList插入1000万数据记时
long arrayStart=System.currentTimeMillis();
for (int i=0;i<10000000;i++){
arrayList.add(i);
}
long arrayInsertTime=System.currentTimeMillis()-arrayStart;
System.out.println("ArryList插入数据时间:"+arrayInsertTime);
}
public static void main·(String[] args) {
LinkedList linkedList=new LinkedList();
//LinkedList插入1000万数据记时
long linkedStart=System.currentTimeMillis();
for (int i=0;i<10000000;i++){
linkedList.add(i);
}
long linkedInsertTime=System.currentTimeMillis()-linkedStart;
System.out.println("LinkedList插入数据时间:"+linkedInsertTime);
}

很明显普通的插入数据ArrayList要比LinkedList要快很多,可为什么普遍的说法是“LinkedList添加删除快”,这里是有前提条件的linkedList在两种情况下插入数据要比ArrayList快.
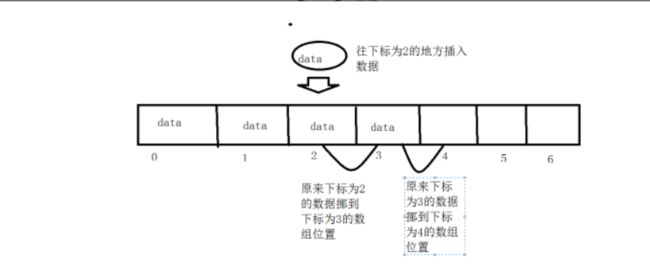
1.往集合中间插入数据时ArrayList比linkedList慢
ArrayList往集合中间插入数据要做两个事:把之前的数据挪开赋值到新的数组位置,然后把需要插入的数据插入到数组对应位置;
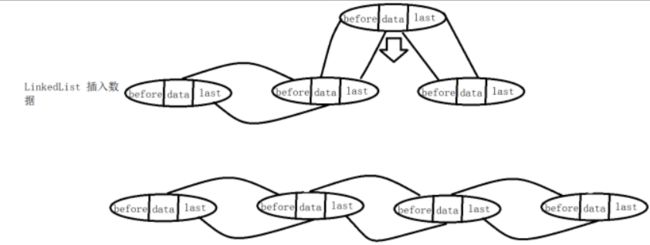
LinkedList只要修改对应位置数据 before 和 last 对象的指向就可以了
2. ArrayList正好扩容的时候添加数据要比LinkedList慢
因为ArrayList维护的是一个数组,所以当容量到达阀值时就会进行扩容,然后会重新分配数据的位置,当数组扩容的时候速度也要比LinkedList慢;
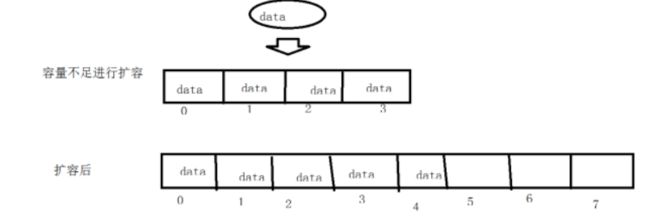
主要有两个因素决定他们的效率,插入的数据量和插入的位置。我们可以在程序里改变这两个因素来测试它们的效率。
当数据量较小时,测试程序中,大约小于30的时候,两者效率差不多,没有显著区别;当数据量较大时,大约在容量的1/10处开始,LinkedList的效率就开始没有ArrayList效率高了,特别到一半以及后半的位置插入时,LinkedList效率明显要低于ArrayList,而且数据量越大,越明显。比如我测试了一种情况,在index=1000的位置(容量的1/10)插入10000条数据和在index=5000的位置以及在index=9000的位置插入10000条数据的运行时间如下:
在index=1000出插入结果:
array time:4
linked time:240
array insert time:20
linked insert time:18
在index=5000处插入结果:
array time:4
linked time:229
array insert time:13
linked insert time:90
在index=9000处插入结果:
array time:4
linked time:237
array insert time:7
linked insert time:92
2. 删除数据
AraayList要比LinkedList慢,原理同往集合中间插入数据一样,ArrayList每次删除数据都要对数组重组;
ArrayList中的随机访问、添加和删除部分源码如下:
//获取index位置的元素值
public E get(int index) {
rangeCheck(index); //首先判断index的范围是否合法
return elementData(index);
}
//将index位置的值设为element,并返回原来的值
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
//将element添加到ArrayList的指定位置
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//将index以及index之后的数据复制到index+1的位置往后,即从index开始向后挪了一位
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element; //然后在index处插入element
size++;
}
//删除ArrayList指定位置的元素
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
//向左挪一位,index位置原来的数据已经被覆盖了
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//多出来的最后一位删掉
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
LinkedList中的随机访问、添加和删除部分源码如下:
//获得第index个节点的值
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
//设置第index元素的值
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
//在index个节点之前添加新的节点
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
//删除第index个节点
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
//定位index处的节点
Node<E> node(int index) {
// assert isElementIndex(index);
//index
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else { //index>=size/2时,从尾开始找
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
3. 查询数据
ArrayList比LinkedList快;
原理是:
ArrayList是数组有下标标记数据位置的,查询时世界返回对应数组下表数据即可;源码如下
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
//直接反回对应数组下表数据
E elementData(int index) {
return (E) elementData[index];
}
LinkedList是链表,没有对数据进行位置标记,每次获取固定位置的数据都需要循环遍历链表如linkedList.get(100),就需要循环100次找到对应的节点返回,源码如下:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
//循环遍历链表找到对应的节点
for (int i = 0; i < index; i++){
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--){
x = x.prev;
return x;
}
}
}