树的基本概念和存储结构
一、树的基本概念
1、树的定义
树是n(n>=0)个结点的有限集。当n = 0时,称为空树。在任意一棵非空树中应满足:
1、有且仅有一个特定的称为根的结点。
2、当n>1时,其余节点可分为m(m>0)个互不相交的有限集T1,T2,…,Tm,其中每个集合本身又是一棵树,并且称为根的子树。
显然,树的定义是递归的,即在树的定义中又用到了自身,树是一种递归的数据结构。树作为一种逻辑结构,同时也是一种分层结构,具有以下特点:
①没有父节点的节点称为根节点;
②每一个非根节点有且只有一个父节点;
③每个子树是不相交的;
④n个结点的树中有n-1条边。
结合图来看,可能会更好理解

这就是一棵典型的二叉树

这里,2,3共有子节点5,也就是5有两个父亲,那么上图就不是树了。

这里,CF组成的子树与DGH组成的子树相交,那么上图也不是树了。
2、基本术语

1、祖先、子孙,父亲、孩子、兄弟:
根节点A到结点K的路径上的任意结点,称为结点K的祖先。如结点B是结点K的祖先,而结点K是结点B的子孙。
路径上最接近结点K的结点E称为K的父亲,而K为结点E的孩子。根节点A是树中唯一没有父亲的结点。
有相同双亲的结点称为兄弟,如结点K和结点L有相同的双亲E,即K和L为兄弟。
2、节点的度、树的度
树中一个结点的孩子个数称为该结点的度,
树中结点的最大度数称为树的度。
如结点B的度为2,结点D的度为3,树的度为3。
3、分支结点、叶子结点
度大于0的结点称为分支结点(又称非终端结点,如BCDEH);
度为0(没有孩子结点)的结点称为叶子结点(又称终端结点,如KLFGMIJ)。
4、结点的深度、高度、层次
结点的层次从树根开始定义,根结点为第1层,它的子结点为第2层,以此类推。
双亲在同一层的结点互为堂兄弟,图中结点G与E,F,H,I,J互为堂兄弟。
结点的深度是从根结点开始自顶向下逐层累加的。
结点的高度是从叶结点开始自底向上逐层累加的。
树的高度(或深度)是树中结点的最大层数。图中树的高度为4。
5、有序树、无序树
树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树。
树中任意节点的子节点之间有顺序关系,这种树称为有序树
6、路径、路径长度。
树中两个结点之间的路径是由这两个结点之间所经过的结点序列构成的,而路径长度是路径上所经过的边的个数。
注意:由于树中的分支是有向的,即从双亲指向孩子,所以树中的路径是从上向下的,同一双亲的两个孩子之间不存在路径。
7、森林
森林是m (m≥0)棵互不相交的树的集合。
森林的概念与树的概念十分相近,因为只要把树的根结点删去就成了森林。反之,只要给m棵独立的树加上一个结点,并把这m棵树作为该结点的子树,则森林就变成了树。
注意:上述概念无须刻意记忆, 根据实例理解即可。
二、树的存储结构
1、双亲表示法
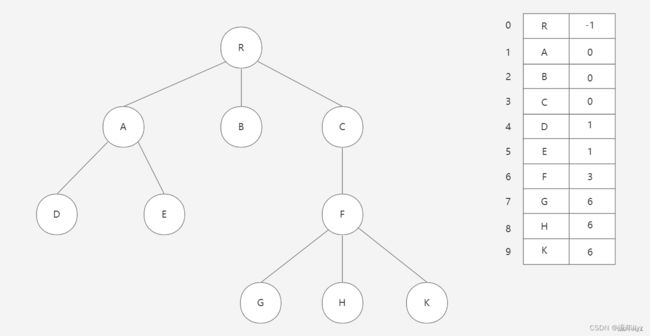
实现:定义结构数组,存放树的结点,每个结点有两个域,分别是数据域和指针域(双亲域),数据域用于存放结点本身信息,指针域用于存放本结点的双亲结点在数组中的位置。
双亲表示的结点结构
| data(数据域) | parent(指针域) |
|---|---|
| 存储结点的数据信息 | 存储该结点的双亲所在数组中的下标 |

双亲表示法示意图:
双亲表示法结构定义:
//结点结构
struct PTNode
{ int data; //数据域
int parent; //双亲域
}PTNode;
//树结构
struct
{
PTNode nodes[100]; //结点数组
int r,n; //根结点位置和结点数
}
双亲表示法的特点
- 由于根结点是没有双亲的,约定根结点的位置位置域为-1.
- 根据结点的
parent指针很容易找到它的双亲结点。所用时间复杂度为O(1),直到parent为-1时,表示找到了树结点的根。 - 缺点:如果要找到孩子结点,需要遍历整个结构才行。
2、孩子链表法
把每个结点的孩子结点排列起来,以单链表作存储结构,则n个结点有n个孩子链表,如果是叶子结点则此单链表为空表,然后n个头指针又组成一个线性表,采用顺序存储结构,存放在一个一维数组中。
孩子表示法有两种结点结构:孩子链表的孩子结点和表头数组的表头结点
- 孩子链表的孩子结点的结点结构:
| child(数据域) | next(指针域) |
|---|---|
| 存储某个结点在表头数组中的下标 | 存储指向某结点的下一个孩子结点的指针 |

- 孩子链表的双亲结点的结点结构:
| data(数据域) | firstchild(头指针域) |
|---|---|
| 存储某个结点的数据信息 | 存储该结点的孩子链表的头指针 |

孩子链表的结构示意图:

孩子链表表示法的结构定义:
//孩子结点
typedef struct CTNode
{ int child;
struct CTNode *next;
}*ChildPtr;
//双亲结点
typedef struct
{ ElemType data;
ChildPtr firstchild;
}CTBox;
//树结构
typedef struct
{ CTBox nodes[100];
int r, n; //根的位置和结点数
}CTree;
特点:找孩子容易,找双亲困难。
对于孩子表示法,查找某个结点的某个孩子,或者找某个结点的兄弟,只需要查找这个结点的孩子单链表即可。但是当要寻找某个结点的双亲时,就不是那么方便了。所以可以将双亲表示法和孩子表示法结合,形成双亲孩子表示法。
树的双亲孩子链表的结构示意图:

树的双亲孩子表示法结构定义:
typedef struct CTNode{ // 孩子结点
int child; // 孩子结点的下标
struct CTNode * next; // 指向下一结点的指针
}*ChildPtr;
typedef struct { // 表头结构
int data; // 存放在数中的结点数据
int parent; // 存放双亲的下标
ChildPtr firstchild; // 指向第一个孩子的指针
}CTBox;
typedef struct { // 树结构
CTBox nodes[100]; // 结点数组
int r; // 根的位置
int n; // 结点树
}CTree;
3、孩子兄弟表示法
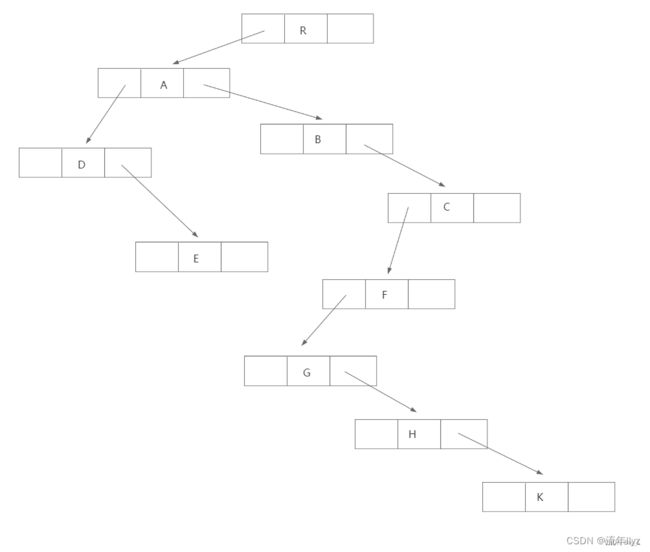
任意一棵树,它的结点的第一个孩子如果存在就是唯一的,它的右兄弟存在也是唯一的。因此,设置两个指针,分别指向该结点的第一个孩子和此结点的右兄弟。
孩子兄弟表示法的结点结构:
| data(数据域) | firstchild(指针域) | rightsib(指针域) |
|---|---|---|
| 存储结点的数据信息 | 存储该结点的第一个孩子的存储地址 | 存储该结点的右兄弟结点的存储地址 |

孩子兄弟表示法结构示意图:
孩子兄弟结点的结构定义:
/* 树的孩子兄弟表示法结构定义*/
typedef struct CSNode{
int data;
struct CSNode * firstchild;
struct CSNode * rightsib;
}CSNode, *CSTree;