RT Preempt linux学习笔记
RT Preempt linux学习笔记
一、实时操作系统(Realtime Operating System)
1. 什么是实时操作系统
A real-time system is a time-bound system which has well-defined, fixed time constraints. Processing must be done within the defined constraints or the system will fail. ——from Wikipedia
实时操作系统要求在一个触发信号到来之后能够在一个确定的时间点之前进行响应处理。它与普通的非实时操作系统区别在于:普通操作系统的响应延时受系统负载影响较大,轻负载时可能会满足响应的要求,但是在负载变大的时候响应会变慢,并且这个响应时间是不确定的。因此一个足够快的系统不代表是一个实时操作系统,实时系统必须要求在负载变化的情况下依然能够满足确定的响应时间,如果无法在确定的时候下完成响应,那么会导致系统错误。
2. 实时操作系统指标
确定性:The same input must always yield the same output
- 在实时系统中,事件和数据处理的时间必须是一致的
- 在多任务系统中,关键任务应该是确定的
- CPU共享和外部中断的影响必须完全可预测
延迟:Time elapsed between an event and the reaction to the event
- 最坏情况下的执行时间很难预测,因此我们需要最坏情况下的反应时间
- 延迟是实时操作系统的主要关注点

二、影响实时性的因素
1. view from software(linux)
从某个事件发生到负责处理这个事件的进程开始执行,过程如下:
(1) 硬件检测到某个事件,发送中断请求信号给中断控制器
(2) 中断控制器把中断请求分发给某个处理器
(3) 处理器响应中断请求,执行中断处理程序
(4) 中断处理程序唤醒负责处理这个事件的实时进程
(5) 进程调度器调度进程,选中负责处理这个事件的实时进程
(6) 实时进程开始执行,处理事件
从上面的过程中,我们可以归纳出影响实时性的几个因素:(进程运行前)
-
中断能否及时响应
-
实时进程能否被及时调度
导致处理器不能及时响应中断的因素有:正在执行中断处理程序,或者正处于执行禁止中断的临界区。
对应的解决方法如下:
(1) 中断线程化,也就是使用内核线程执行中断处理函数
(2) 为了减小时钟中断处理程序的执行时间,把高精度定时器的到期模式分为软中断到期模式(HRTIMER_MODE_SOFT )和硬中断到期模式(HRTIMER_MODE_HARD ),大多数高精度定时器使用软中断到期模式,在软中断里面执行
(3) 如果使用内核线程执行中断处理函数,那么原来禁止硬中断的临界区不需要禁止硬中断,为了兼顾非实时内核和实时内核,引入本地锁(local_lock_t),非实时内核把本地锁映射到禁止内核抢占和禁止硬中断,实时内核把本地锁映射到基于实时互斥锁实现的自旋锁
导致实时进程不能被及时调度的因素如下:
(1) 正在执行软中断
(2 )正在执行禁止软中断(调用函数local_bh_disable())的临界区
(3) 正在执行禁止内核抢占(调用函数preempt_disable())的临界区
(4) 正在执行RCU保护(调用函数rcu_read_lock()或rcu_read_lock_bh())的读端临界区,禁止内核抢占
(5) 正在执行自旋锁或读写锁保护的临界区
(6) 需要申请的锁被优先级低的进程持有,导致优先级高的进程等待优先级低的进程,发生优先级反转
对应的解决方法如下:
(1) 软中断全部由软中断线程执行
(2) 如果软中断全部由软中断线程执行,那么原来禁止软中断的临界区可以变成可抢占的,和软中断线程使用本地锁互斥
(3) 在实时内核中大多数禁止内核抢占的临界区可以变成可抢占的,为了兼顾非实时内核和实时内核,引入本地锁,非实时内核把本地锁映射到禁止内核抢占和禁止硬中断,实时内核把本地锁映射到使用实时互斥锁实现的自旋锁
(4) 实现可抢占RCU,把RCU保护的读端临界区变成可以抢占的
(5) 把自旋锁和读写锁替换为可以抢占的、支持优先级继承的锁
(6) 锁支持优先级继承
上面提到的相关解决办法,其实也就是PREEMTP_RT补丁所做的改动。除了进程运行前的这些因素影响实时性外,我们还得考虑进程运行过程中的因素:
(1) Linux内核使用虚拟内存,对用户空间的内存(包括栈、代码段、数据段以及使用函数malloc()或mmap()动态分配的内存)使用惰性分配的策略,如果实时进程访问的虚拟页没有映射到物理页,那么会触发缺页异常,影响实时性
(2) Linux内核在内存不足的时候会回收物理页或者swap到磁盘,导致实时进程访问的虚拟页没有映射到物理页,影响实时性
对应的解决方法:
(1) C库的内存接口对于heap有二级管理,free了之后并不是马上返回给内核态的,我们可以利用这个原理,在程序运行初期就把要用到的heap给提前申请了,这样相关的内存就hold在用户态了。
(2) 实时进程在main()函数里面使用函数malloc()或mmap()预先分配内存,并且调用函数mlockall(),把所有虚拟页映射到物理页,锁定在内存中,阻止内核回收这些物理页
例子如下:
#include */
return 0;
}
(3)提前申请好要用的栈空间(提前pagefault,占好位置)
#define MAX_SAFE_STACK (1024*1024)
void stack_prefault(void)
{
unsigned char dummy[MAX_SAFE_STACK];
memset(dummy, 0, MAX_SAFE_STACK);
}
int main(int argc, char *argv[])
{
stack_prefault();
......
/* */
}
2. view from hardware
-
一些内存总线可以缓冲访问并创建延迟峰值
-
由于总线控制,DMA访问也会引入延迟
-
NUMA结构的内存—远程节点的访问延迟将更长
-
频率缩放(CPU Frequency scaling)
CPU频率可以通过DVFS动态更改(Dynamic Voltage and Frequency Scaling),调整频率会导致执行时间不确定
-
电源管理功能使用睡眠状态,这会引入延迟:CPU休眠得越深,唤醒它所需的时间就越长
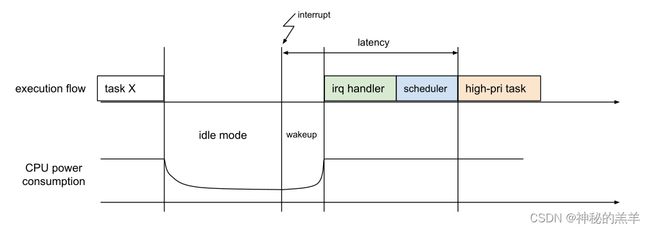
三、抢占模型
打上了PREEMPT_RT补丁后,linux有如下几种抢占模型:
1. CONFIG_PREEMPT_NONE
“No Forced Preemption (Server)”,不可抢占内核。这是传统的抢占模型,目标是使吞吐量最大化。大多数时候提供良好的延迟,但是没有保证,可能偶尔出现长的延迟。这种模型主要用于服务器和科学计算系统。如果希望使内核的处理能力最大化,不考虑调度延迟,那么应该选择这种模型。
2. CONFIG_PREEMPT_VOLUNTARY
“Voluntary Kernel Preemption (Desktop)”,自愿内核抢占。这种模型通过增加抢占点的方式减小延迟。在内核里面选择性地增加了一些抢占点,目的是减小最大调度延迟和对交互事件提供更快的响应,代价是稍微降低吞吐量。当低优先级进程在内核模式执行的时候,在预定的抢占点自愿被抢占。这种模型主要用于桌面系统。它减少了长延迟(几百毫秒到几秒)的发生,但是没有消除。
3. CONFIG_PREEMPT
“Preemptible Kernel (Low-Latency Desktop)”,低延迟可抢占内核。这种模型使除了临界区以外的所有内核代码是可以抢占的。当低优先级进程在内核模式执行的时候,可以非自愿地被抢占。这种模型提供了很低的响应延迟,最坏情况的延迟时间是几毫秒,代价是稍微降低吞吐量和稍微增加运行时开销。这种模型主要用于有毫秒级别延迟需求的桌面系统和嵌入式系统。
4. CONFIG_PREEMPT_RT
“Fully Preemptible Kernel (RT)”,完全抢占内核,也称为实时内核。这种模型把自旋锁和读写锁替换为可以抢占的、支持优先级继承的锁,强制中断线程化,并且引入各种机制来打破长的、不可抢占的临界区。这种模型主要用于延迟要求为100微秒或稍低(几十微秒)的实时系统。
四、为什么linux不是实时操作系统
答:延时具备不确定性。
1. 中断优先级比进程高
linux的中断是运行在中断上下文环境,优先级是比进程高的,所以能随时打断高优先级的任务:

2. 中断响应延时不具备确定性(不支持中断嵌套)
linux在处理中断的时候是关闭中断的,所以中断在执行的时候,其他的中断都进不来,这个设计本身简化了内核,但是对于硬实时的打击是致命的,前面的中断不执行完成,优先级再高的中断也得等着。
比如中断1在执行的过程中,来了中断2,而中断2对应的事情是必须要决定性时延的,由于IRQ1的中断服务程序也是coder写的,我们无法确定这个中断服务程序要执行多久。这显然让高优先级中断2的进入延迟不再具备可预期性。
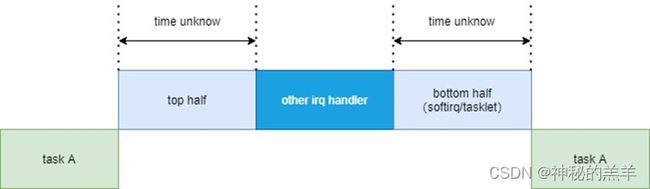
3. softirq/tasklet优先级比进程高
softirq/tasklet是一个比进程上下文优先级更高的上下文。其代码也是coder写的,执行时间不能保证。
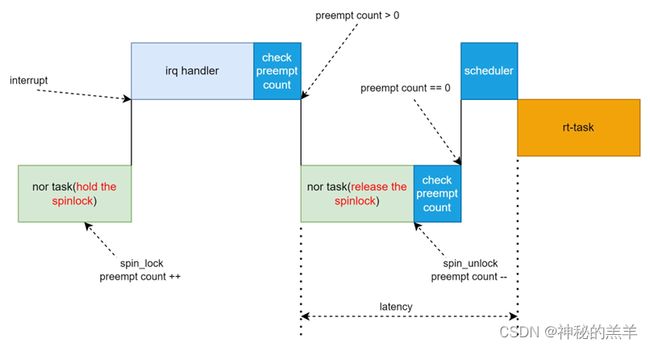
4. 自旋锁(spinlock)
自旋锁引起了持有锁的CPU核的抢占调度的禁止。
假设task1和task2运行在一个核上面,当task1拿到spinlock后,这个核上的抢占调度被禁止,如果在task1持有spinlock的时间内,task2是一个高优先级的实时任务,尽管task2被唤醒,它也不可能立即打断task1的执行,必须等待task1释放spinlock。task1究竟会持有spinlock多久,这个是未知的,所以task2究竟要等多久,也未可知,这显然破坏了决定性的时延。
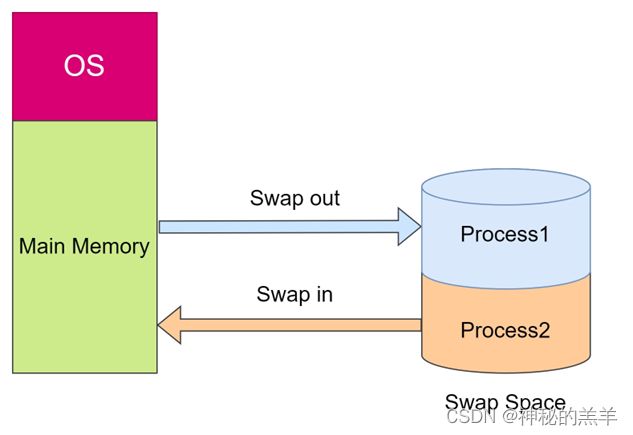
5. linux特殊的内存管理机制:lazy机制 & swap机制
申请内存并不是马上分配的,而是要访问该内存空间的时候才会去分配,创建页表,这就造成了延时。

已经进入内存的东西,也会由于内核的swap机制,会与磁盘进行交换。把实时任务的内存空间给交换出去
假设一个实时的线程被唤醒得以执行,当执行的时候,发现需要访问的临时变量还没有获得内存,代码段可能还在硬盘里,那它又怎么保证实时性呢?
有人会说,那把高优先级的任务放到中断或者softirq里面跑不就完事了吗?这是裸奔的想法,完全就不是linux了。
记住,linux只提供机制,不提供策略。
6. 内核里面充斥着会屏蔽中断的API如local_irq_disable、spin_lock_irqsave等
spin_lock_irqsave这样的API在内核的使用可以说太常见了,它其实是适用于一个经典的场景,就是中断服务程序与线程之间有竞态的情况。spin_lock_irqsave既屏蔽了抢占,又屏蔽了中断,这会导致中断和实时任务的确定性时延造成不可预期的破坏。因为spin_lock_irqsave和spin_lock_irqrestore是coder写的,谁能保证执行时间呢?

7. 进程调度时机充满不确定性
Linux进程调度时机主要有:
-
进程自愿主动让出(yield)
-
进程状态转换的时刻:进程终止、进程睡眠
-
当前进程的时间片用完时(current->counter=0)
-
进程从中断、异常及系统调用返回到用户态时
大多数多任务操作系统都是抢占式操作系统,包括Linux。当任务在用户态下运行并被中断中断时,如果中断处理程序唤醒另一个任务,则可以在中断处理程序返回时立即调度该任务:
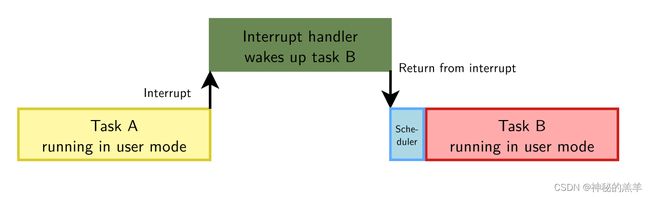
但是,当任务正在执行系统调用时发生了中断,该系统调用必须在调度另一个任务之前完成。这意味着调用调度器来调度另一个任务的时间是不确定的:
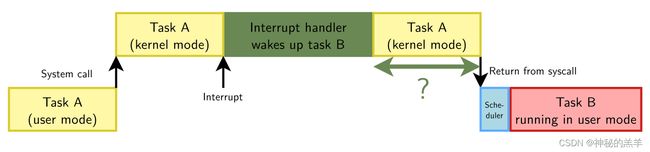
/* arch/arm64/kernel/entry-common.c */
el0_sys
exit_to_user_mode
prepare_exit_to_user_mode
do_notify_resume
schedule()
五、preempt_rt补丁改动关键点
1. 中断
强制中断线程化:
在PREEMPT_RT中,几乎所有的中断处理程序都已线程化(未设置IRQF_NO_THREAD标志)。它把顶半部再分成两部分:一部分是硬中断环境,它其实就是一个所谓的“quick check handler”只检查中断源并ack中断最后唤醒对应的中断处理线程,此过程中对应的中断处于disable状态;另一部分是中断处理线程,处理传统顶半部中的剩余部分。如此一来,关中断时间压缩到极限,实时性大大提高。

/* linux-5.15/kernel/irq/manage.c */
int request_threaded_irq(unsigned int irq, irq_handler_t handler,
irq_handler_t thread_fn, unsigned long irqflags,
const char *devname, void *dev_id)
action->handler = handler;
......
__setup_irq(irq, desc, action);
irq_setup_forced_threading
if (!force_irqthreads()) /* 如果开启了CONFIG_PREEMPT_RT, 这里的force_irqthreads是返回ture的 */
return 0;
new->thread_fn = new->handler; /* 原来的handler存放到thread_fn,线程化 */
new->handler = irq_default_primary_handler; /* handler重新赋值,里面直接return IRQ_WAKE_THREAD*/
static irqreturn_t irq_default_primary_handler(int irq, void *dev_id)
{
return IRQ_WAKE_THREAD;
}
中断线程化是使用内核线程执行中断处理函数,内核线程的名称是“irq/-”(是Linux中断号,是设备名称),调度策略是SCHED_FIFO,实时优先级是50。
2. Softirq
软中断线程化:
在非实时内核中,一部分软中断在中断处理程序的后半部分执行,有时间限制:最多执行10轮,并且总时间不超过2毫秒。剩下的软中断由软中断线程执行,或者在进程开启软中断(调用函数local_bh_enable)的时候执行。每个处理器有一个软中断线程,名称是“ksoftirqd/”(是处理器编号),调度策略是SCHED_NORMAL,优先级是120。
在实时内核中,软中断由软中断线程执行,或者在进程开启软中断的时候执行。中断处理程序的后半部分唤醒当前处理器上的软中断线程。
/* linux-5.15/kernel/softirq.c */
irq_exit
__irq_exit_rcu
invoke_softirq
#ifdef CONFIG_PREEMPT_RT
static inline void invoke_softirq(void)
{
if (should_wake_ksoftirqd())
wakeup_softirqd();
}
#else
static inline void invoke_softirq(void)
{
if (!force_irqthreads() || !__this_cpu_read(ksoftirqd)) {
#ifdef CONFIG_HAVE_IRQ_EXIT_ON_IRQ_STACK
__do_softirq();
#else
do_softirq_own_stack();
#endif
} else {
wakeup_softirqd();
}
}
#endif
3. RCU
解决RCU读端临界区不可抢占的问题:
/* linux-5.15/include/linux/rcupdate.h */
#ifdef CONFIG_PREEMPT_RCU
void __rcu_read_lock(void);
......
#else
static inline void __rcu_read_lock(void)
{
preempt_disable();
}
......
#endif
实时内核强制开启可抢占RCU的配置宏CONFIG_PREEMPT_RCU,rcu_read_lock()、rcu_read_unlock()和call_rcu()这些函数使用可抢占RCU实现,所以使用rcu_read_lock()和rcu_read_unlock()保护的读端临界区是可以抢占的。(注:在新版的内核里面,这个可抢占的RCU在开启CONFIG_PREEMPT宏就会默认使用了)
/* linux-5.15/kernel/rcu/tree_plugin.h */
#ifdef CONFIG_PREEMPT_RCU
void __rcu_read_lock(void)
{
rcu_preempt_read_enter();
if (IS_ENABLED(CONFIG_PROVE_LOCKING))
WARN_ON_ONCE(rcu_preempt_depth() > RCU_NEST_PMAX);
if (IS_ENABLED(CONFIG_RCU_STRICT_GRACE_PERIOD) && rcu_state.gp_kthread)
WRITE_ONCE(current->rcu_read_unlock_special.b.need_qs, true);
barrier(); /* critical section after entry code. */
}
......
#endif
4. 互斥锁
解决优先级翻转问题:
这里先讲一下,什么是优先级翻转(priority inversion):

假设Task C的优先级低,Task A的优先级高。Task C持有互斥锁,Task A申请互斥锁,因为Task C已经占有互斥锁,所以Task A必须睡眠等待,导致优先级高的Task A等待优先级低的Task C。
如果存在Task B,优先级在Task A和Task C之间,那么情况更糟糕。假设Task C仍然持有互斥锁,Task A正在等待。Task B开始运行,因为它的优先级比Task C高,所以它可以抢占Task C,这就导致Task C持有互斥锁的时间延长,Task A被阻塞,优先级比A低的Task B反而可以运行。
**优先级继承(priority inheritance) **可以解决优先级反转问题。如果低优先级的进程持有互斥锁,高优先级的进程申请互斥锁,那么把持有互斥锁的进程的优先级临时提升到申请互斥锁的进程的优先级。在上面的例子中,把Task C的优先级临时提升到Task A的优先级,防止Task B抢占进程Task C,使Task C尽快执行完临界区,减少Task A的等待时间:
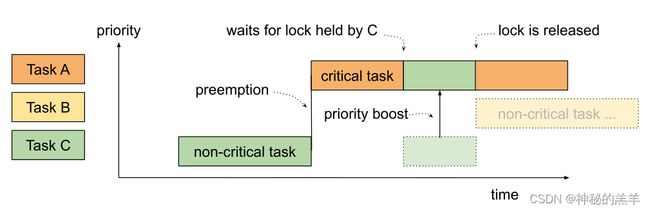
为了实现优先级继承,内核引入了rt-mutex:
/* linux-5.15/include/linux/rtmutex.h */
/**
* The rt_mutex structure
*
* @wait_lock: spinlock to protect the structure
* @waiters: rbtree root to enqueue waiters in priority order;
* caches top-waiter (leftmost node).
* @owner: the mutex owner
*/
struct rt_mutex {
struct rt_mutex_base rtmutex;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
struct rt_mutex_base {
raw_spinlock_t wait_lock; /* 实时锁,使用优先级排队,使用优先级继承算法解决优先级翻转问题,与task_struct强偶合 */
struct rb_root_cached waiters;
struct task_struct *owner;
};
5. 自旋锁
自旋锁(spinlock_t)保护的临界区是不可抢占的,导致实时进程不能被及时调度。实时内核使用实时互斥锁实现自旋锁,临界区是可以抢占的,支持优先级继承,spin_lock_irq()和spin_lock_irqsave()不会禁止硬中断。
#ifdef CONFIG_PREEMPT_RT
typedef struct spinlock {
union {
struct raw_spinlock rlock;
......
}
} spinlock_t;
#else
/* PREEMPT_RT kernels map spinlock to rt_mutex */
#include /* linux-5.15/include/linux/spinlock.h */
static __always_inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock); /* 里面是会调用preempt_disable来关抢占 */
}
/* linux-5.15/include/linux/spinlock_rt.h */
static __always_inline void spin_lock(spinlock_t *lock)
{
rt_spin_lock(lock);
}
void __sched rt_spin_lock(spinlock_t *lock)
{
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
__rt_spin_lock(lock);
}
static __always_inline void __rt_spin_lock(spinlock_t *lock)
{
___might_sleep(__FILE__, __LINE__, 0);
rtlock_lock(&lock->lock);
rcu_read_lock();
migrate_disable();
}
少数使用自旋锁保护的临界区不允许抢占,内核定义了原始自旋锁(raw_spinlock)。在非实时内核中,spinlock和raw_spinlock完全相同。
6. hrtimer
在hrtimer引入以前,linux内核的timer精度和编译时配置选项CONFIG_HZ有关,此配置选项有100、250和1000等几个少数值可选,意思是1秒内分别触发100次、250次、1000次timer中断,分别对应10ms、4ms和1ms的精度。显而易见CONFIG_HZ配得越大,timer中断次数越多,处理时钟中断的负载越高,所以CONFIG_HZ不能太大,但1ms的精度对于实时性系统又太差了。在linux-2.6.16中引入hrtimer(High Resolution Timer)的支持,timer中断和CONFIG_HZ脱钩,系统能在硬件timer的精度允许范围内触发中断,故其精度通常能达到纳秒级,具体精度和系统底层硬件提供的timer有关,比如若底层硬件有25MHZ的时钟,那么理论上hrtimer可以提供40纳秒精度的timer。
六、减少延时(latency)的一些措施
1. CPU 绑定(CPU Pinning)
-
Linux内核调度程序允许设置有关允许运行每个任务的CPU内核的约束
-
确保进程不会迁移到另一个核心
-
这种机制称为进程的cpu亲和性
-
使用cpuset子系统和sched_setffinity系统调用来选择cpu
-
使用taskset -p 在指定的cpu上启动一个新进程
2. CPU隔离(CPU Isolation)
用户可以通过CPU亲和机制将进程绑定到CPU内核上,但是内核也可能在这些cpu上调度其他进程。
-
Isolcpus可以在内核命令行上传递
-
调度程序不会使用隔离的cpu
cpuset是一种允许细分CPU调度池的机制,它们在运行时通过cpusetfs创建:
mount -t cpuset none /dev/cpuset
在cpuset主目录中随意创建cpuset:
mkdir /dev/cpuset/rt-set
mkdir /dev/cpuset/non-rt-set
每个cpu被分配一个cpu核池:
echo 2,3 > /dev/cpuset/rt-set
echo 0,1 > /dev/cpuset/non-rt-set
我们可以选择在每个集合中运行哪个任务:
echo PID > /dev/cpuset/non-rt-set/tasks
echo PID > /dev/cpuset/rt-set/tasks
3. 中断亲和度(IRQ affinity)
- 中断由特定的CPU核心处理
- 处理中断的默认CPU是CPU 0
- 在多cpu系统上,可以很好地平衡cpu之间的中断处理
- irq可以通过调整/proc/irq/XX/smp_affinity来固定到cpu上
4. 内存管理
当要求内核分配一些内存时,linux会给应用程序一个虚拟地址范围,这个虚拟范围在访问时才会被映射到一个物理内存范围,这将为应用程序引入page fault延迟。所有内存都应该在应用程序初始化时锁定并访问。在初始化时访问内存称为内存预设(prefaulting)。这涉及堆内存,也涉及栈。
- 在init时调用mlockall(MCL_CURRENT | MCL_FUTURE)来锁定所有内存区域
- 分配所有内存并在初始化时访问它
- 不要调用fork(),因为子进程将会copy-on-write页面
- 配置malloc不返回分配的空间给系统
mallopt(M_TRIM_THRESHOLD, -1)
5. 相关锁的使用
- 在创建多线程应用程序时,使用pthread_mutex_t
- 避免使用没有owner的信号量
- 开启优先级继承(PI):
pthread_mutexattr_setprotocol(&mattr, PTHREAD_PRIO_INHERIT);
6. 关闭某些内核配置
一些配置选项不适合在实时运行的时候开启:
-
CONFIG_LOCKUP_DETECTOR
-
CONFIG_DETECT_HUNG_TASK
-
CONFIG_DEBUG_*
-
CONFIG_ARM_CPUIDLE
Why? Because 优先级为99的内核任务可能会引入延迟;由于大量的日志记录,它们中的大多数都会引入延迟
7. 减少printk的使用
传统linux内核中printk可在关中断、禁止抢占的上下文环境中调用,printk最终会调用console driver输出,而console driver一般会利用spinlock进行互斥,在PREEMPT_RT环境中,spinlock是可睡眠的锁,故而printk有可能导致在关中断、禁止抢占的情形下睡眠,这是不能接受行为。
8. MISC
少用fork & mmap系统调用 ,实在不可避免也是静态使用。少用signal & semaphore,这些同步原语是可睡眠的,进程切换出去开销太大了。