kubevela随笔
知识点:
1、application controller执行过程
Application Controller 每次对于应用的轮询包括若干阶段 parsed->revision->policy->reder->exec workflow->state keep-> gc,其中根据 application 状态和配置的不同,会有选择性跳过部分步骤的执行。
- parsed阶段:加载component、trait、policy、workflowstep中定义的需要的所有cue模板,生成appfile
- revision阶段:计算hash值,生成appRev、hash值的计算不包含app.status和app.workflow
- policy阶段: policy预留了部署k8s资源的策略,算是社区预留策略
- render阶段:执行cue模板的渲染工作(json merge),生成要部署的manifest
- exec workflow阶段:部署manifest到k8s 的apiserver,通过APIService路由到clustergateway,分发到不同的子集群
- state-keep阶段:检查集群中资源状态是否和内存中一致
- gc阶段:对关联的资源进行回收
2、webhook:trigger 当制品仓库里推送了新的镜像时,VelaUX 中会收到对应的触发请求,执行对应的workflow,从而完成自动部署
3、healthScope:对application的组件进行周期性健康检查,检查策略是component-definition里的spec.status.healthPolicy或customStatus设置的检查规则,即cue表达式,然后healthScope控制器会不断检查cue表达式是否满足(渲染eval),且检查结果会patch记录到app.status.services字段。其中每次app控制器都会获取所有的k8s对象并填充到context字段。
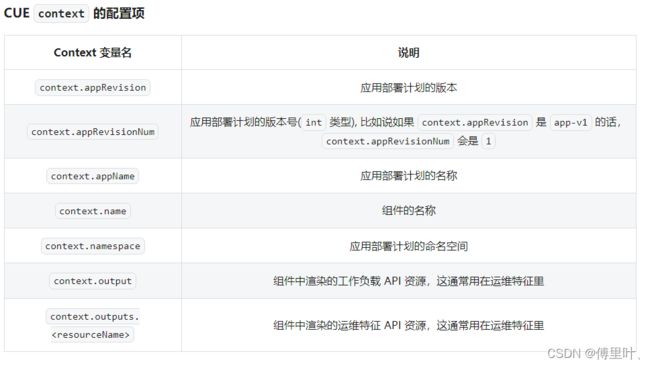
5、CUE context配置项
6、workflowstep执行过程
- 1 在执行workflowstep前会首先计算app的hash是否变化,以及判断wfstatus,如果是finished、terminated、suspended则直接退出,然后会创建对应的workflow的cm,再执行TaskGenerator的run方法;
- 2 run方法中会将workflowstep的cue模板和参数生成的cue.value合并成一个新的cue.value作为taskValue,然后调用doSteps对cue中#component-apply等进行处理,对应会执行具体的provider注册的某个方法。
- 3 生成组件部署所需的Manifest及ControllerRevision
--3.1 applyComponentFunc首先会从appRev中获取workload;
--3.2 生成compManifest,即对应的完整的deployment和service等结构体
--3.2.1 生成用于处理cue模板的pCtx;
--3.2.2 根据component的cue模板(TaskLoader加载的)生成基础的workload(deploy)和auxiliary(service)的cue模板,并存入pCtx.base和pCtx.auxiliaries;
--3.2.3 基于pCtx.base和pCtx.auxiliaries,patch等、并生成compManifest即完整的deployment和service,包括根据trait struct加载trait模板并eval后unify到pCtx.base,并包含trait的patchKey的处理等;对patcher进行处理,但deploy2env中patch一直为空;eval pCtx.base和pCtx.auxiliaries并生成compManifest,即完整的deployment和service;
--3.3 然后给base、auxiliaries,即deployment、service等,添加oam相关的标签和注解,且组件有变化时生成新的componentRev
--3.4 component有变化则在deploy所在ns创建新的componentRevision即ControllerRevision
-4 渲染组件,进行apply前的准备,给workload和auxiliaries添加appRev、appRev-hash、env等标签、并检查是否由该trait管理workload
-5 部署manifest到k8s,首先会将manifest记录在rt中,之后会将manifest patch部署到k8s,并记录被部署的资源到appHandler.appliedResources
-6 分别针对component和trait根据HeathScope和CustomStatus的cue模板进行eval计算状态,并记录到appHandler.services
-7 workflowstep执行完某个provider.handler后会查看wfStatus,如果suspend、ternimated、wait为true,则直接停止workflow,等待被重新触发
8、velaql流程
velaql执行流程:
// 1、组装一个workflowstep,用于完成QueryView
// 2、通过provider注册了需要的方法,并提供了TaskLoader用于加载cue模板
// 3、使用TaskLoader加载cue模板,并生成TaskGenerator函数
// 4、执行上边返回的TaskGenerator函数,并生成executor,然后并把handler放到了对应的executor,然后是很成了taskRunnertaskRunner主要有run和checkPending两个函数,并返回taskRunner
// 5、执行TaskRunner的Run方法,run方法中会将workflowstep的cue模板和参数生成的cue.value合并成一个新的cue.value作为taskValue,然后调用doSteps对cue中#component-apply进行处理,对应会执行具体的provider注册的某个方法
9、ResourceTracker
RT是app的resource的record,通过RT+finalizer相较OwnerReference方式能够自定义的GC策略。
RT的4个核心函数:
Dispatch:将资源记录到RT,然后部署资源;
Delete:mark resource,然后删除resource,应该是deprecated
StateKeep:保证资源始终处于最新版本;
GarbageCollect: 资源回收,包括过期的RT等;
RT的类型:
versioned RT:保存每一更新app spec的记录;
root RT:和app共享生命周期的app的resource的record;
componentRevision RT:track所有dispatch的component controller revision,包括删除等;
10、GC过程
1、初始化cache,以k/v的形式存储所管理的resource
2、Mark阶段
如果app标记为删除则rootRT和CurrentRT也被标记删除;
如果app没有标记删除且回收策略不是passive,则标记删除所有hisRTs;
如果app没有标记删除且回收策略是passive=true,则标记删除没有引用的hisRt;
3、Sweep阶段
遍历rootRT/currentRT/hisRT 如果RT已经被标记为删除,则遍历RT下所有资源,
如果RT下的资源都已被删除,则将RT上的finalizer字段删除,
如果RT下的资源没有被全部删除,则将未删除的资源放到waiting中
4、Finalize阶段
遍历rootRT/currentRT/hisRT,如果RT已经被标记为删除且存在finalizer字段,则遍历每一个RT下的每一个资源,如果该资源仍然存在,则将其删除
5、Garbage crRT阶段
找到正在被使用的crRT,对于没有被使用的crRT则将其删除,并重新更新crRT的ManagedResources
6、Garbage legacy RT阶段
从已部署资源种找到所有的集群信息,遍历每一个集群,找到所有的RT,如果RT.spec.type为空,则将其删除。
11、只要apprev.spec变化就会生成新的appRev,apprev.spec中包括没有status的applicatio、componentDefinitions、traitDefinitions、policyDefinitions、workflowDefinition
12、云原生和KubeVela
云原生是标准化模型,或一套方法论,在应用上云后,为了把云平台的优势发挥出来,需要做的事比较系统的、统筹的描述清楚了,提供了一个如何用好云平台的模板。
比如应用能够利用云平台实现资源的弹性伸缩和动态调度,优化资源利用率,对应hpa、vpa、动态调度器,权重调度器;
再比如自动化部署和管理能力,应用可以随处运行,并且能够通过持续集成、持续交付提升研发、测试与发布的效率,对应fluxcd等。
再比如opentelemetry,可观测性
KubeVela是实践系统,是一个以应用为核心的k8s,k8s是通过pod、service等屏蔽了基础设施层,而KubeVela通过appfile屏蔽了pod、service等。像Rancher等大多数经典 PaaS 都能提供完整的应用生命周期管理功能,但是Rancher等往往扩展性比较差,哪怕这个插件完全基于k8s构建也需要改动代码-测试-发版,而KubeVela的优势在于利用CUE实现了高度可扩展。
13、打补丁
- 使用 patch,为component的workload打补丁;
- 使用 patchOutputs,为component的其他运维特征打补丁;
- 使用 +patchKey=name,image注解,给数组列表打补丁,如果发现重复的键名,补丁数据会直接替换掉它的值;如果没有重复键名,补丁则会自动附加这些数据;
- 使用 +patchStrategy=retainKeys 注解,会将整个对象一起替换掉;
举例以单个anno为对象替换;
metadata: annotations: {
// +patchStrategy=retainKeys
"config.oam.dev/config-revision": parameter.configRevision
}
- 使用 +patchStrategy=jsonPatch 注解,会按照RFC 6902做jsonPatch
- 使用 +patchStrategy=jsonMergePatch 注解,会按照RFC 7396做JsonMergePatch
14、context.output和context.outputs
trait的preApply可能会和context.output冲突;
context.output 字段包含了所有渲染后的workload API 资源,然后 context.outputs.
15、组件间的依赖和参数传递
dependsOn和input&output,参考应用组件间的依赖和参数传递 | KubeVela本节将介绍如何在 KubeVela 中进行组件间的依赖关系和参数传递。 https://kubevela.net/zh/docs/next/end-user/workflow/component-dependency-parameter
https://kubevela.net/zh/docs/next/end-user/workflow/component-dependency-parameter
16、进入Application controller的条件
Watches:
1、ResourceTracker被删除时会触发application进入reconcile
WithEventFilter.UpdateEvent:
2、当ManagedFields、status.Workflow.Steps、Status.Workflow.ContextBackend、Status.Workflow.Message、Status.AppliedResources、Status.Services、ResourceVersion变化时,不考虑进入reconcile。
3、完全没有变化时认为是resync、Generation变化、以及除上述字段外其他字段的变化,会进入reconcile。
17、自定义状态
不管是component还是trait,healthPolicy 对应services的healthy字段,customStatus 对应services的message字段,
18、ClusterGateway简单理解
查询逻辑:
1、ClusterGatewayProxy.Connect(secret转为ClusterGateway, 生成proxyHandler)
2、proxyHandler.ServeHTTP()
3、UpgradeAwareHandler.ServeHTTP()
4、RoundTrip(走的http.transport.RoundTrip即net/http/httputil/reverseproxy.go,没有走自定义的RoundTrip,并通过http.ResponseWriter直接返回数据给前端)

集群健康检查:
单独走的health
19、application spec变更的简单理解
application spec变更时,status的变化过程
实例数 status terminated generation
实例为2,runningWorkflow,false,generation==observerdgeneration 原来的正在部署
实例为3,runningworkflow,false,generation==observerdgeneration+1 变更触发
实例为3,rendering,false,generation==observerdgeneration
实例为3,workflowTerminated,true,generation==observerdgeneration 标识清理status
实例为3,runningWorkflow,false,generation==observerdgeneration 对比app.spec和apprev计算hash code,如果不一致则appliedResources、services、workflowstate被清理,即Initializing workflow
实例为3,runningWorkflow,false,generation==observerdgeneration 部署
-----------------------------------------------------------------------------------------------------------------------
KubeVela性能测试

Kubevela运行在0.5CPU、1Gi的容器里,测试创建3,000 Applications (12,000 Pods in total) on 200 nodes,花费25min,每一次reconcile的平均耗时200ms 并且99% reconciles耗时少于800ms;
Kubevela运行在1CPU、2Gi的容器里,测试创建5,000 Applications (30,000 Pods in total) on 500 nodes,花费21min,reconciles耗时前边相当;
性能测试报告地址 https://kubevela.net/zh/blog/2021/08/30/kubevela-performance-test。