stable-diffussion-webui+sd-webui-text2video+SadTalker数字人生产力工具安装配置教程(Linux Ubuntu,避坑帖)
0 背景
虽然网络上已经有很多类似的文章,但是讲linux 上通过 stable-diffussion-webui整合各类生产力插件的还比较少,而且亲测有效的更是凤毛菱角。为了帮助大家避坑,笔者特意利用休息的时间写了这篇文章。力求让小白玩家也能够上手。
在linux整合stable-difussion有什么用:
1、帮助创作者提高生产力。因为主流的A100、H100等显卡都是跑在服务器上面的专业卡,而服务器99%是用Linxu系统。当然您硬是要给服务器装Windows也是可以的,但实际上可能会造成性能浪费。在Linux服务器上配置一台A100显卡的GPU服务器即使是用40G版本的单卡,也能满足一个小型工作室对生产力的需求了。
2、帮助研究AI应用领域的伙伴增强认知,很多东西不自己亲自去搭一个、跑一个、改一个是很难在脑海中形成对知识的深刻认知的。
3、在linux上运行服务会更稳定,更专业。
实验环境:
| 服务器 | SuperMicro 超威 |
| 操作系统 | Ubuntu 20.04.6 LTS Release: 20.04 Codename: focal |
| CPU | Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian Address sizes: 46 bits physical, 57 bits virtual CPU(s): 48 On-line CPU(s) list: 0-47 Thread(s) per core: 2 Core(s) per socket: 12 |
| GPU | Nvidia A100 sxm 40G * 4 (Nvlink 双卡连接) |
| 内存 | 512Gb |
笔者估算在不进行任何量化或其它压缩的情况下能稳定运行的最低配置要求:
| 服务器 | SuperMicro 超威 |
| 操作系统 | Ubuntu 18\20.04.6 LTS Release: 18\20.04 Codename: focal |
| CPU | 4核以上够用就行 |
| GPU | 支持CUDA平台的N卡,显存8G以上。 |
| 内存 | 16Gb以上 |
| 磁盘 | 固态或者机械(40G以上) |
1 介绍
1.1 StableDiffussionWebUI
github地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui
项目简介:
该项目是一个对stable-diffussion生态进行整合的项目,其优点是简单易用,容易上手,截至本文写作时github标星92.5k+。其集成了文生图、图生图、图生文、训练、插件扩展等核心功能。也可以通过扩展插件(extension)集成其它的sd生态下的项目,如文生视频、视频对口型等模型。
其支持windows、linux、macosx 3大操作系统。其中windows有一键安装包。Linux可以通过脚本一键安装(但是对于法力不够的炼丹师在github下载代码和在huggingface下载模型文件将变得极其困难)。
1.1.1 StableDiffusion 介绍
Stable Diffusion is a machine learning model based on latent diffusion that has the capability to convert textual descriptions into high-quality images. Developed collaboratively by CompVis, Stability AI, and LAION, this model is trained on a subset of the LAION-5B database, consisting of 512x512 resolution images. Stable Diffusion is a latent diffusion model that generates desired image samples, such as faces, by progressively removing random Gaussian noise.
Stable Diffusion是一种基于潜在扩散的机器学习模型,能够将文本描述转化为高质量的图像。该模型由CompVis、Stability AI和LAION联合开发,使用LAION-5B数据库的子集进行训练,该数据库包含512x512分辨率的图像。Stable Diffusion是一种潜在扩散模型,通过逐步去除随机高斯噪声来生成感兴趣的图像样本,例如人脸等。
最新版本的SD包含了768*768的数据集进行训练。
常见名词安利:
预训练模型(pre model):也称基座模型,是指在大量数据集上面提前训练好的模型,其本质是一堆参数集,未经过迁移训练,这个时候的预训练模型并不具备特定的专业能力。通常需要大量算力才能训练pre-model,一般大公司或者机构才玩得起。
finetune model: 在预训练模型的基础上通过迁移训练,用以完成特定任务的模型。一般分为全量参数微调和部分参数微调,微调相对于于预训练所消耗的算力资源要小得多,所需要的数据集也要小得多。但是经过微调以后,模型的能力却能得到质变。finetune 后的model使用方式和基座模型一样,放到models/Stable-diffusion。
Loro model:也是一种微调模型,不同的是Loro通常仅微调特定的层,如Linner层(全连接层),非常灵活,开销很小。要想获得不同的lora,可以是到网络上C站或国内的AI图站下载。下载后的lora文件直接放到Stable Diffusion安装目录的models的lora目录里。刷新后就可使用。(炼丹师们口中的丹就是它)
VAE美化模型:VAE,全名Variational autoenconder,中文叫变分自编码器。作用是:滤镜+微调。等于美颜相机。vaemodel通常放到models/VAE
Embeddings:数据嵌入。简单点说就是给模型外挂了一个记忆盘,把一些你需要教它的知识存储在这里面,这个记忆盘实质是一个向量数据库,将你需要嵌入的信息转化为高维向量,然后通过在高维比较相似度来查询数据。模型每次干活前从这里查询相关数据,但严格来说embedding不应该被定义为微调,因为它并没有修改模型本身的参数。在SD中创建Embeddings需要安装cond_stage_model。
DreamBooth:可用于训练预调模型用的。是使用指定主题的图像进行演算,训练后可以让模型产生更精细和个性化的输出图像。
LyCORIS模型:此类模型也可以归为Lora模型,也是属于微调模型的一种。一般文件大小在340M左右。不同的是训练方式与常见的lora不同,但效果似乎会更好不少。使用此类模型,需要安装插件 https://ghproxy.com/https://github.com/KohakuBlueleaf/a1111-sd-webui-locon
1.2 text2video
github地址:https://github.com/kabachuha/sd-webui-text2video
项目简介:
该项目是一个基于sdwebui的文生视频的扩展插件,提供了扩展界面和基础模型。用户在安装插件以后可以替换自己的模型运行,目前支持大部分开源的text2video模型。
1.3 SadTalker
github地址:GitHub - OpenTalker/SadTalker: [CVPR 2023] SadTalker:Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
项目简介:
该项目是一个通过音频驱动图片合成对口型视频的开源项目。你可以提供一段音频(或者文字)驱动一张人物图片去对口型合成视频。
2 安装配置
2.1 安装基础组件
如果你已经安装好了以下基础组件和配置,则可忽略。
#可以使用以下一行命令将Ubuntu的apt源设置为阿里云镜像:
#对于Ubuntu 20.04 (Focal Fossa)版本:
sudo sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list
#对于Ubuntu 18.04 (Bionic Beaver)版本:
sudo sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list
#运行以上命令后,系统会将源地址中的"archive.ubuntu.com"替换为"mirrors.aliyun.com",从而将apt源设置为阿里云镜像。 然后,运行以下命令更新apt源列表:
sudo apt update
# 安装Python3和Python3-venv
sudo apt install wget git python3 python3-venv pip
# 设置pip 阿里云镜像
cp /etc/apt/sources.list /etc/apt/sources.list.backup
curl -o /etc/apt/sources.list http://mirrors.aliyun.com/repo/ubuntu`lsb_release -cs`.list
apt update
# 安装ffmpeg
sudo apt install ffmpeg
# 安装Nvidia驱动和Cuda平台
2.2 安装StableDifussionWebUI
2.1.1 从Gitee下载代码,从源码安装(好处是遇到问题更容易解决,也能做一些自己的修改)。
# 创建应用文件夹
mkdir /usr/local/apps
cd /usr/local/apps
# Clone 代码(这里从Gitee clone,避免网络问题)
git clone https://gitee.com/sd-webui/stable-diffusion-webui.git
或者从镜像clone (git clone https://ghproxy.com/https://github.com/AUTOMATIC1111/stable-diffusion-webui.git)
/usr/local/apps/stable-diffusion-webui
# 修改启动脚本
vi webui.sh
# 定位到第7行代码
# 【ESC】 :7
# 注释这段代码(这是用于识别系统环境的代码,在某些虚拟环境下可能识别不正确,我们不需要它)
# If run from macOS, load defaults from webui-macos-env.sh
if [[ "$OSTYPE" == "darwin"* ]]; then
if [[ -f webui-macos-env.sh ]]
then
source ./webui-macos-env.sh
fi
fi
# 修改下载脚本,将git代码源切换为镜像下载的代码
vi modules/stable-diffusion-webui
# 定位到第232行
# 【ESC】:232
将如下代码:
xformers_package = os.environ.get('XFORMERS_PACKAGE', 'xformers==0.0.20')
gfpgan_package = os.environ.get('GFPGAN_PACKAGE', "https://github.com/TencentARC/GFPGAN/archive/8d2447a2d918f8eba5a4a01463fd48e45126a379.zip")
clip_package = os.environ.get('CLIP_PACKAGE', "https://github.com/openai/CLIP/archive/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1.zip")
openclip_package = os.environ.get('OPENCLIP_PACKAGE', "https://github.com/mlfoundations/open_clip/archive/bb6e834e9c70d9c27d0dc3ecedeebeaeb1ffad6b.zip")
stable_diffusion_repo = os.environ.get('STABLE_DIFFUSION_REPO', "https://github.com/Stability-AI/stablediffusion.git")
k_diffusion_repo = os.environ.get('K_DIFFUSION_REPO', 'https://github.com/crowsonkb/k-diffusion.git')
codeformer_repo = os.environ.get('CODEFORMER_REPO', 'https://github.com/sczhou/CodeFormer.git')
blip_repo = os.environ.get('BLIP_REPO', 'https://github.com/salesforce/BLIP.git')
修改为:
xformers_package = os.environ.get('XFORMERS_PACKAGE', 'https://ghproxy.com/https://github.com/TencentARC/xformers/archive/0.0.20.zip')
gfpgan_package = os.environ.get('GFPGAN_PACKAGE', "https://ghproxy.com/https://github.com/TencentARC/GFPGAN/archive/8d2447a2d918f8eba5a4a01463fd48e45126a379.zip")
clip_package = os.environ.get('CLIP_PACKAGE', "https://ghproxy.com/https://github.com/openai/CLIP/archive/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1.zip")
openclip_package = os.environ.get('OPENCLIP_PACKAGE', "https://ghproxy.com/https://github.com/mlfoundations/open_clip/archive/bb6e834e9c70d9c27d0dc3ecedeebeaeb1ffad6b.zip")
stable_diffusion_repo = os.environ.get('STABLE_DIFFUSION_REPO', "https://ghproxy.com/https://github.com/Stability-AI/stablediffusion.git")
k_diffusion_repo = os.environ.get('K_DIFFUSION_REPO', 'https://ghproxy.com/https://github.com/crowsonkb/k-diffusion.git')
codeformer_repo = os.environ.get('CODEFORMER_REPO', 'https://ghproxy.com/https://github.com/sczhou/CodeFormer.git')
blip_repo = os.environ.get('BLIP_REPO', 'https://ghproxy.com/https://github.com/salesforce/BLIP.git')
# 手动下载官方模型 (如果你的服务器网速不佳,请手动下载模型,再放到对应目录上面)
cd models/Stable-diffusion/
将从https://huggingface.co/stabilityai/stable-diffusion-2-1/tree/main下载的v2-1_768-nonema-pruned.safetensors模型放到这个目录下面。(v2.1的标准模型,当然你也可以去下载其它finetune模型,同样放在这个目录下面即可)
# 启动脚本开始安装,会自动安装StableDifussion以及其它扩展
bash webui.sh --enable-insecure-extension-access --xformers --server-name 0.0.0.0
按照上面这个流程基本都能安装成功,由于本期讲的是插件集成,所以SDWebUI的安装较为简洁。
常见问题:
如果遇到repositories问题可以cd到对应目录,
1、如果有requirements.txt 则 pip install -r requirements.txt
2、如果有setup.py 则 pip install -e .
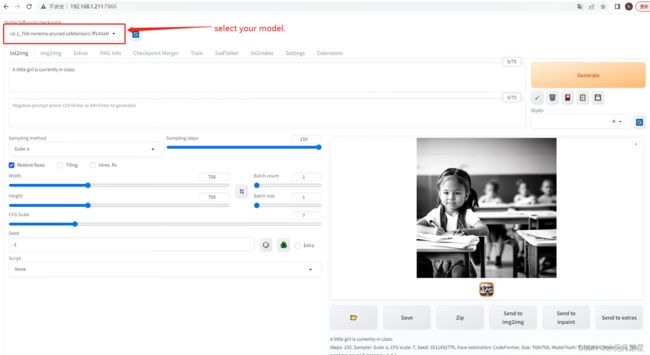
。安装完成后的效果图:
2.3 Text2Video Extension 安装
2.4.1 插件安装
1、选择SDWebUI的extension
2、选择Install From URL
3、点击Install按钮
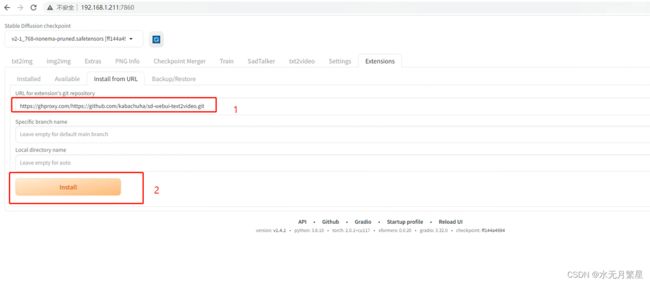
因为这个项目在gitee上也没有很好的搬运工,这里我们使用镜像地址。
https://ghproxy.com/https://github.com/kabachuha/sd-webui-text2video.git2.4.2 模型下载安装
1、在安装完成插件并且重启UI后,sdwebui会自动下载sd-webui-text2video插件适配的模型文件,但是通常情况下我们的服务器可能会遇到下载问题,这个时候就需要通过其它渠道下载好模型到本地电脑,然后再上传到服务器手动安装。
2、下载模型
# 创建路径
cd models;mkdir ModelScope;cd ModelScope;make dir t2v
# 下载模型,并放入对应的文件夹中。以下参考插件官方说明:
VideoCrafter(WIP):
- 通过此链接下载预训练的 T2V 模型,并将 model.ckpt 放入 models/VideoCrafter/model.ckpt 中。然后使用与 ModelScope 相同的 GUI 管道。
型号范围:
- 将模型放入 stable-diffusion-webui/models/text2video,每个完整模型应该有自己的文件夹。模型由四部分组成:
VQGAN_autoencoder.pth、configuration.json和。确保是文本 JSON 文件而不是保存的 HTML 网页(单击右侧的 ⬇️ 字符,不要通过右键单击保存)。建议的要求从 6 GB VRAM 开始。open_clip_pytorch_model.bintext2video_pytorch_model.pthconfiguration.json
突出的微调列表是模型搜索的良好起点。
在此处加入开发或报告问题和功能请求https://github.com/kabachuha/sd-webui-text2video
如果您喜欢这个扩展,请在 GitHub 上给它一个星!
去Huggigface下载预训练模型
damo-vilab/modelscope-damo-text-to-video-synthesis at main
# 最后你的模型目录文件如下
![]()
- models
- ModelScope
- t2v
- configuration.json
- open_clip_pytorch_model.bin
- text2video_pytorch_model.pth
- VQGAN_autoencoder.pth
如果你要切换多个模型也可以如下方式组织模型文件目录:
- models
- ModelScope
- t2v
- configuration.json
{ "framework": "pytorch",
"task": "text-to-video-synthesis",
"model": {
"type": "latent-text-to-video-synthesis",
"model_args": {
"ckpt_clip": "./animov/open_clip_pytorch_model.bin",
"ckpt_unet": "./animov/text2video_pytorch_model.pth",
"ckpt_autoencoder": "./animov/VQGAN_autoencoder.pth",
"max_frames": 25,
"tiny_gpu": 1
},
"model_cfg": {
"unet_in_dim": 4,
"unet_dim": 320,
"unet_y_dim": 768,
"unet_context_dim": 1024,
"unet_out_dim": 4,
"unet_dim_mult": [1, 2, 4, 4],
"unet_num_heads": 8,
"unet_head_dim": 64,
"unet_res_blocks": 2,
"unet_attn_scales": [1, 0.5, 0.25],
"unet_dropout": 0.1,
"temporal_attention": "True",
"num_timesteps": 1000,
"mean_type": "eps",
"var_type": "fixed_small",
"loss_type": "mse"
}
},
"pipeline": {
"type": "latent-text-to-video-synthesis"
}
}- animov
- open_clip_pytorch_model.bin
- text2video_pytorch_model.pth
- VQGAN_autoencoder.pth
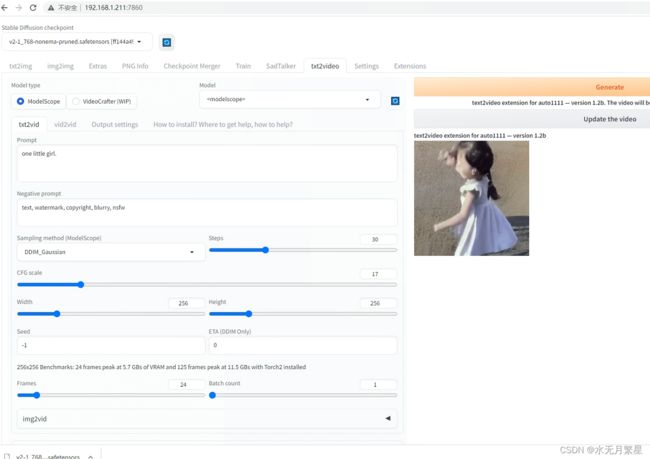
配置好模型文件以后重启sdwebui
运行结果如下:
2.4 SadTalker 安装
2.4.1 插件安装
1、选择SDWebUI的extension
2、选择Install From URL
3、点击Install按钮
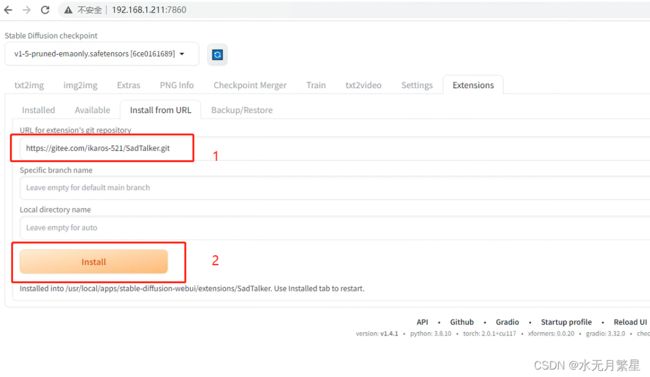
可以看到我们使用了gitee上面的SadTalker仓库(感谢搬运工们)避免可能遇到的网络问题,并节约时间。
https://gitee.com/ikaros-521/SadTalker.git4、然后耐心等待安装完成即可
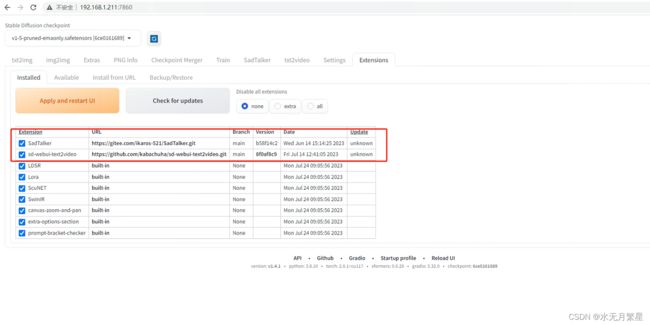
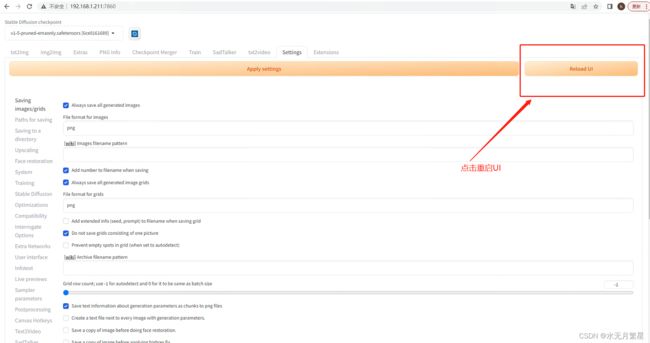
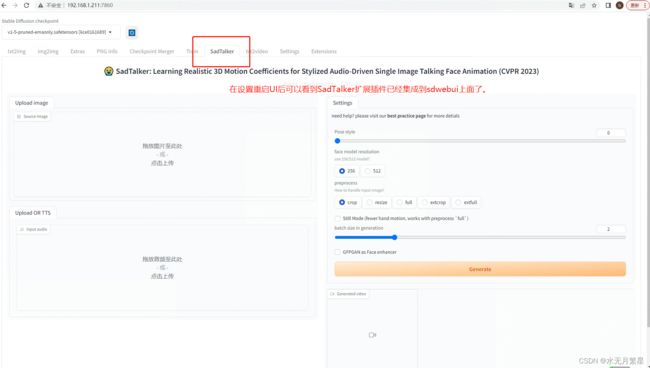
2.4.2 模型下载安装
1、在安装完成插件并且重启UI后,sdwebui会自动下载SadTalker的模型文件,但是通常情况下我们的服务器可能会遇到下载问题,这个时候就需要通过其它渠道下载好模型到本地电脑,然后再上传到服务器手动安装。
参考SadTalker项目的文档,从百度云盘下载模型文件:
百度云盘: we provided the downloaded model in checkpoints, 提取码: sadt. And gfpgan, 提取码: sadt.
2、将下载好的模型文件上传到对应的位置
新建文件夹用于放模型文件
mkdir /usr/local/apps/stable-diffusion-webui/extensions/SadTalker/checkpoints如下图所示将下载的模型文件放入对应目录

cd /usr/local/apps/stable-diffusion-webui/models/GFPGAN
注意:生产视频过程中可能遇到ffmpeg插件版本过低导致的报错。执行下列命令手动升级版本:
# 更新安装包,万能大法
pip install --upgrade imageio-ffmpeg
# 如果还是报错
sudo apt update
sudo apt upgrade ffmpeg重新启动sdwebui即可。
运行效果图:
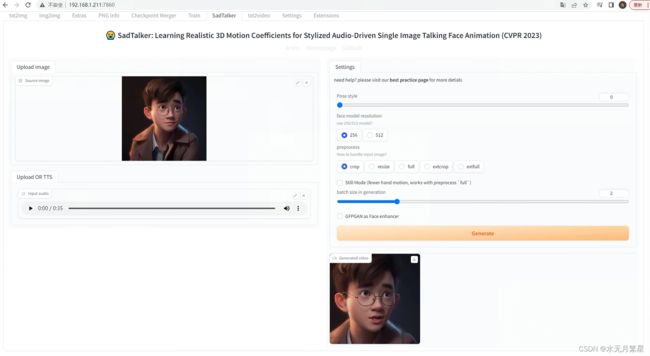
2.5 系统负载情况
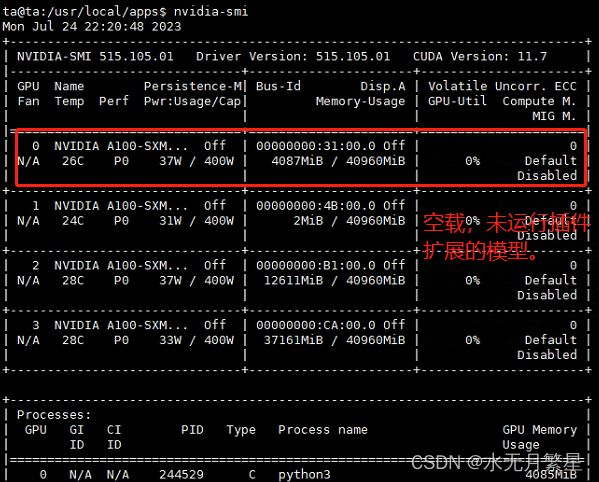
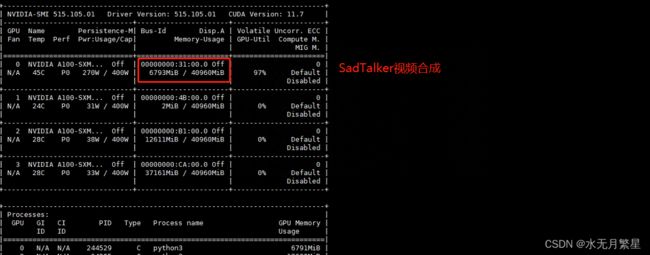
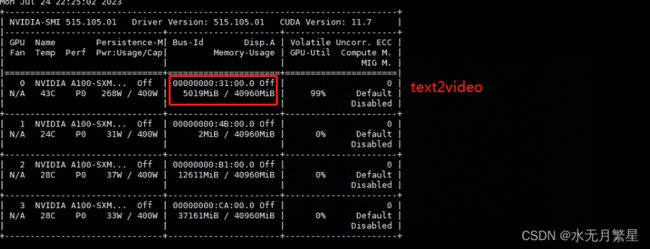
3 参考文献
1.GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
2.https://github.com/kabachuha/sd-webui-text2video
3.GitHub - OpenTalker/SadTalker: [CVPR 2023] SadTalker:Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
4. Stable Diffusion的各类模型介绍(Stable Diffusion研习系列03) - 知乎