大型语言模型:SBERT — 句子BERT
了解 siamese BERT 网络如何准确地将句子转换为嵌入
简介
Transformer 在 NLP 领域取得了进化性的进步,这已不是什么秘密。基于 Transformer,还发展出了许多其他机器学习模型。其中之一是 BERT,它主要由几个堆叠的 Transformer 编码器组成。除了用于一系列不同的问题(例如情感分析或问答)之外,BERT 在构建词嵌入(表示单词语义的数字向量)方面变得越来越流行。
以嵌入的形式表示单词具有巨大的优势,因为机器学习算法无法处理原始文本,但可以对向量的向量进行操作。这允许使用欧几里得距离或余弦距离等标准度量来比较不同单词的相似性。
问题在于,在实践中,我们经常需要为整个句子而不是单个单词构建嵌入。然而,基本的 BERT 版本仅在单词级别构建嵌入。因此,后来开发了几种类似 BERT 的方法来解决这个问题,本文[1]将对此进行讨论。通过逐步讨论它们,我们将达到称为 SBERT 的最先进模型。
BERT
首先,让我们回顾一下 BERT 是如何处理信息的。作为输入,它需要一个 [CLS] 标记和由特殊 [SEP] 标记分隔的两个句子。根据模型配置,该信息由多头注意力模块处理 12 或 24 次。然后,输出被聚合并传递到一个简单的回归模型以获得最终标签。

交叉编码器架构
可以使用 BERT 来计算一对文档之间的相似度。考虑在一个大集合中找到最相似的一对句子的目标。为了解决这个问题,每个可能的对都被放入 BERT 模型中。这会导致推理过程中出现二次复杂度。例如,处理 n = 10 000 个句子需要 n * (n — 1) / 2 = 49 995 000 次推理 BERT 计算,这并不是真正可扩展的。
其他方法
分析交叉编码器架构的低效率,为每个句子独立地预先计算嵌入似乎是合乎逻辑的。之后,我们可以直接计算所有文档对上选定的距离度量,这比将平方数的句子对输入 BERT 要快得多。
不幸的是,这种方法对于 BERT 来说是不可能的:BERT 的核心问题是,每次同时传递和处理两个句子时,很难获得仅独立表示单个句子的嵌入。
研究人员试图通过使用 [CLS] 令牌嵌入的输出来消除这个问题,希望它包含足够的信息来表示一个句子。然而,事实证明 [CLS] 对于这项任务根本没有用,因为它最初是在 BERT 中针对下一句预测进行预训练的。
另一种方法是将单个句子传递给 BERT,然后对输出标记嵌入进行平均。然而,获得的结果甚至比简单平均 GLoVe 嵌入还要糟糕。
❝推导独立句子嵌入是 BERT 的主要问题之一。为了缓解这个问题,开发了 SBERT。
❞
SBERT
SBERT 引入了 Siamese 网络概念,这意味着每次两个句子都通过相同的 BERT 模型独立传递。在讨论 SBERT 架构之前,让我们先参考一下 Siamese 网络的一个微妙注释:
- 大多数时候,在科学论文中,暹罗网络架构都是用多个接收如此多输入的模型来描述的。实际上,它可以被认为是具有相同配置和在多个并行输入之间共享权重的单个模型。每当更新单个输入的模型权重时,它们也会同样更新其他输入。

回到 SBERT,在将一个句子传递给 BERT 后,池化层被应用于 BERT 嵌入以获得其较低维度的表示:初始 512 768 维向量被转换为单个 768 维向量。对于池化层,SBERT 作者建议选择平均池化层作为默认层,尽管他们也提到可以使用最大池化策略或简单地采用 [CLS] 令牌的输出。
当两个句子都通过池化层时,我们有两个 768 维向量 u 和 v。通过使用这两个向量,作者提出了三种优化不同目标的方法,这将在下面讨论。
分类目标函数
该问题的目标是将给定的一对句子正确分类为几个类别之一。
生成嵌入 u 和 v 后,研究人员发现从这两个向量派生出另一个向量作为元素绝对差 |u-v| 很有用。他们还尝试了其他特征工程技术,但这一技术显示了最好的结果。
最后,三个向量 u、v 和 |u-v|连接起来,乘以可训练的权重矩阵 W,并将乘法结果输入到 softmax 分类器中,该分类器输出对应于不同类别的句子的归一化概率。交叉熵损失函数用于更新模型的权重。

用于解决此目标的最流行的现有问题之一是 NLI(自然语言推理),其中对于定义假设和前提的给定句子 A 和 B,有必要预测假设是否为真(蕴涵),在给定的前提下,错误(矛盾)或不确定(中立)。对于这个问题,推理过程与训练相同。
正如论文中所述,SBERT 模型最初是在两个数据集 SNLI 和 MultiNLI 上进行训练的,这两个数据集包含一百万个句子对,并带有相应的标签蕴含、矛盾或中性。之后,论文研究人员提到了有关 SBERT 调优参数的详细信息:
❝“我们使用 3 路 softmax 分类器目标函数对一个 epoch 的 SBERT 进行微调。我们使用了 16 的批量大小、学习率为 2e−5 的 Adam 优化器以及超过 10% 的训练数据的线性学习率预热。”
❞
回归目标函数
在这个公式中,在获得向量 u 和 v 后,它们之间的相似度得分直接通过选定的相似度度量来计算。将预测的相似度得分与真实值进行比较,并使用 MSE 损失函数更新模型。默认情况下,作者选择余弦相似度作为相似度度量。

在推理过程中,可以通过以下两种方式之一使用该架构:
- 通过给定的句子对,可以计算相似度得分。推理工作流程与训练完全相同。
- 对于给定的句子,可以提取其句子嵌入(在应用池化层之后)以供以后使用。当我们得到大量句子的集合并旨在计算它们之间的成对相似度分数时,这特别有用。通过将每个句子仅运行一次 BERT,我们提取了所有必要的句子嵌入。之后,我们可以直接计算所有向量之间所选的相似度度量(毫无疑问,它仍然需要二次比较次数,但同时我们避免了像以前那样使用 BERT 进行二次推理计算)。
三重态目标函数
三元组目标引入了三元组损失,该损失是根据通常称为锚、正和负的三个句子计算的。假设锚定句和肯定句非常接近,而锚定句和否定句则非常不同。在训练过程中,模型会评估该对(锚,正)与该对(锚,负)相比的接近程度。从数学上讲,以下损失函数被最小化:
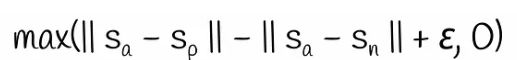
间隔 ε 确保正句子与锚点的距离至少比负句子与锚点的距离近 ε。否则,损失将大于0。默认情况下,在这个公式中,作者选择欧氏距离作为向量范数,参数ε设置为1。
三元组 SBERT 架构与前两种架构的不同之处在于,该模型现在并行接受三个输入句子(而不是两个)。

Code
SentenceTransformers 是一个用于构建句子嵌入的最先进的 Python 库。它包含多个针对不同任务的预训练模型。使用 SentenceTransformers 构建嵌入很简单,下面的代码片段中显示了一个示例。
然后构建的嵌入可用于相似性比较。每个模型都是针对特定任务进行训练的,因此参考文档选择合适的相似性度量进行比较始终很重要。
总结
我们已经了解了一种用于获取句子嵌入的高级 NLP 模型。通过将 BERT 推理执行的二次次数减少为线性,SBERT 在保持高精度的同时实现了速度的大幅增长。
为了最终理解这种差异有多么显着,参考论文中描述的例子就足够了,在这个例子中,研究人员试图在 n = 10000 个句子中找到最相似的一对。在现代 V100 GPU 上,此过程使用 BERT 大约需要 65 小时,而使用 SBERT 只需 5 秒!这个例子表明 SBERT 是 NLP 的巨大进步。
Reference
[1]Source: https://towardsdatascience.com/sbert-deb3d4aef8a4
本文由 mdnice 多平台发布