Redis 数据一致性方案的分析与研究
点击下方关注我,然后右上角点击...“设为星标”,就能第一时间收到更新推送啦~~~
一般的业务场景都是读多写少的,当客户端的请求太多,对数据库的压力越来越大,引入缓存来降低数据库的压力是必然选择,目前业内主流的选择基本是使用 Redis 作为数据库的缓存。但是引入缓存以后,对我们系统的设计带来了很大的挑战,其中缓存和数据库的数据一致性问题就是一个非常棘手的问题,今天我们就来聊一聊在项目中,我们用什么方案来解决数据一致性的问题。
1
Redis 的使用场景
![]()
我们在实际项目中,通常情况下的应用是读多写少的,我们一般用 Redis 来解决读数据库的压力问题,也就是说用 Redis 作为缓存来减轻由于客户端频繁查询数据库而对数据库造成的压力。
因此在项目中由客户端直接查询数据库返回数据,变成了客户端查询 Redis 缓存,缓存有数据则直接返回数据,缓存没有数据再去查询数据库,同时数据库的数据写入到 Redis 缓存。
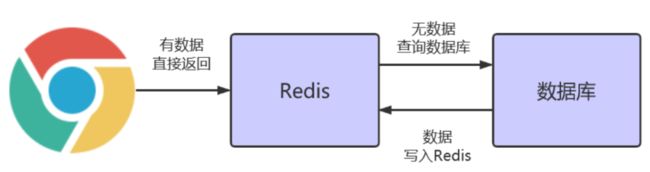
在以上的使用场景中,我们一般缓存热点数据,比如电商平台中的热销商品,用户的登录信息,新闻类平台中的热点新闻等。
2
数据一致性问题产生的原因
![]()
当数据库的数据发生变化的时候,引入 Redis 缓存以后,增加了数据操作难度,既要操作数据库又要操作 Redis,对 Redis和数据库的操作有 2 种方案:
1、先操作 Redis,再操作数据库
2、先操作数据库,再操作 Redis
我们无论选择以上的哪个方案,都希望数据操作要么都成功,要么都失败,我们不希望看到一个失败,一个成功的结果,因为这样就产生了数据不一致的问题。
举个例子说明:
假设 Redis 里缓存了一个热点商品数据,有个 key 为 1001 的商品名称为“华为手机”,数据库里这个 1001 号的商品名称也是华为手机;此时商家觉得商品名称叫华为手机有点宽泛,需要精确一下,把 1001 号商品的名称修改为其对应的具体名称“华为 P40 Pro”。
1、如果我们选择先操作 Redis,再操作数据库的方案,当操作 Redis 成功,操作数据库失败的时候,Redis 里的名称修改为“华为 P40 Pro”,但是数据库的名称还是“华为手机”,产生了数据不一致问题。
2、如果我们选择先操作数据库,再操作 Redis 的方案,当操作数据库成功,操作 Redis 失败的时候,数据库里的名称修改为“华为 P40 Pro”,但是 Redis 的名称还是“华为手机”,产生了数据不一致问题。
由于 Redis 和数据库是 2 个不同的中间件,我们无法通过事务来很好地解决数据一致性的问题,因此只能在数据实时一致性和系统性能上做权衡,选择一个可以接收的方案。
因为数据库是稳定的持久化的系统,比 Redis可靠,我们一般都是以数据库的数据为准,解决这个数据一致性问题的原则就是:我们可以为 Redis 缓存数据设置一个过期的时间,当 Redis 数据过期了就去数据库查询,然后再把数据库的数据写入 Redis 缓存中,确保数据的一致性。
如果在这个过期时间范围内,数据发生了更新操作,当更新操作有一个失败,有一个成功,就会产生不一致的问题,这个过期时间设置的太短了,数据库的压力还是很大,过期时间设置的太长了,不一致性的问题就会凸显,因此我们需要基于以数据库的数据为准的原则下,继续探讨数据一致性问题的解决方案。
3
数据更新时,如何操作 Redis
![]()
当数据更新时,操作数据库我们都很熟悉,直接更新数据库的值就可以了,但是操作 Redis,我们应该怎么办?
1、有人会说,这还不简单,数据变化时,直接更新缓存
2、也有人会说数据变化时把缓存的数据删掉,当查询请求发现缓存没有数据,就会从数据库加载新的数据。
以上的两种方法都可以,那我们该如何选择呢?
如果我们选择更新 Redis 的方案,我们要评估一下更新的代价大不大,比如拿到数据更新到 Redis 需要经过很多表的关联查询,或者多个接口的调用查询,经过大量计算才能得到数据的话,就不要使用更新 Redis 的方案了,因为面对这么复杂的更新流程,不如直接删掉方便。如果要更新的数据直接可以获取到,那么选择更新 Redis 的方案就是可行的。
直接删除 Redis 缓存数据是更加简单的方案,因为缓存数据删了,只能从数据库读取了,这样可以避免不一致性,互联网公司一般选择删除 Redis 的方案。
下面我们用一张图来表示可选的方案:

通过上图,我们可以看出当数据发生变化时,Redis 与数据库的处理流程我们可以从 Redis更新还是删除这 2 个方面分析,然后再从先操作 Redis还是先操作数据库这 2 个方面分析,下面我们按此思路继续深入分析。
4
选择 Redis 更新方案
![]()
1、先更新 Redis,再更新数据库
首先不推荐选择这种方案。
因为我们的数据一致性的基本原则是以数据库的数据为准,所以先更新缓存的话,会存在缓存更新成功,数据库更新失败的情况,此时面临的问题就需要回滚掉刚才更新缓存成功的操作,那么就需要从业务代码里加入很多判断逻辑来处理这种异常,需要考虑数据变化是 insert,update,delete 等,根据不同的场景执行不同的回滚方案,这种回滚操作比较麻烦,对我们业务代码的倾入性也比较大,所以不推荐选择这种方案。
当然,如果业务层面可以接受这种数据的不一致性,异常情况就不需要考虑,选择这种方案也是可以的。
2、先更新数据库,再更新 Redis
先更新数据库,再更新 Redis 的方案,由于把数据库操作放到了前面,如果数据库操作失败,那么客户端再发起一次就可以了。
如果数据库操作成功,Redis 操作失败,此时由于数据库的数据已经设置成功,我们的重点就是讨论如何把 Redis的数据操作成功即可。从客户端层面来看,他提交的数据已经在我们系统里存在了,此时的问题就是我们系统内部如何解决的问题。
对于 Redis 操作失败,我们可选的方案有以下几个,根据业务要求的数据一致性级别,进行权衡选择即可。
1、不做任何操作,等着Redis里的缓存数据过期后,自动从数据库同步最新的数据,此时最严重的数据不一致性周期就是在缓存过期的一段时间(考虑一下这个过期时间的范围);如果在这个时间段内,又有新的更新请求,也许这次就更新缓存成功了。
2、如果数据一致性要求比较高,那么 Redis 操作失败后,我们把这个操作记录下来,异步处理,用 Redis 的数据去和数据库比对,如果不一致,再次更新缓存确保缓存数据与数据库数据一致。
5
选择 Redis 删除方案
![]()
由于目前数据发生变化,主流的方案是选择删除 Redis,所以我们对这个方案重点进行分析。
1、先更新数据库,再删除 Redis
我们如果更新数据库成功,删除 Redis 失败,那么 Redis 里存放的就是一个旧值,也就是删除缓存失败导致缓存和数据库的数据不一致了。
对于删除 Redis 失败的异常情况来进行分析,我们一般有如下的方案:
1、我们可以重试删除,比如:我们可以把删除动作发送到消息队列 MQ,MQ的消费者再去删除这个key,一致尝试删除操作,确保缓存删除成功,这个方案缺陷就是删除缓存的地方,通过代码实现对业务逻辑产生了入侵。
2、另外一种方案,就是完全异步的方案,对业务逻辑没有入侵,通过监听 binlog 的变化来删除缓存。我们更新数据库会产生 binlog,我们可以用一个服务监听数据库 binlog 的变化,异步去删除缓存,阿里开源的 canal 就是可以监听 binlog 的工具,只要数据发生变化就可以删除 Redis 的数据。
2、先删除 Redis,再更新数据库
我们如果删除 Redis 缓存成功,更新数据库失败的话,因为我们是以数据库为准,再查一次就可以了,这个方案看似很理想,感觉没什么问题,其实在并发下也可能产生数据一致性问题。
我们先看一个并发环境下的更新和查询流程:

上面的图表示,Thread-1 是个更新流程,Thread-2 是个查询流程,cpu 执行顺序是:Thread-1 删除缓存成功,此时 Thread-2 获取到 CPU 执行查询缓存没有数据,然后查询数据库把数据库的值写入缓存,因为此时 Thread-1 更新数据库还没有执行,所以缓存里的值是一个旧值(old),最后 CPU 执行 Thread-1 更新数据库成功的代码,那么此时数据库的值是新增(new),这样就产生了数据不一致行的问题。
要解决以上的问题,我们我们一般有如下的可选方案:
1、并发下多线程操作能不能让同一个操作里的 2 个步骤同时操作完成,下一个线程才能执行,让各个线程排队操作,有人说加锁,如果一个服务部署到了多个机器,就变成了分布式锁,或者是分布式队列按顺序去操作数据库或者 Redis,带来的副作用就是数据库本来是并发的,现在变成串行的了,所以这个方案看起来不太可行,加锁或者排队执行的方案降低了系统性能。
2、另外一种放啊就是延时双删的方案,也就是先删除缓存,再更新数据库,当更新数据后休眠一段时间再删除一次缓存。
伪代码如下:
redes.del(key);
db.update(data);
Thread.sleep(2000);
redes.del(key);以上谈到的都是一些解决方案,没有说哪个方案更好,或者哪个方案不行,以上的方案都是基于实时一致性和系统性能的情况下进行权衡选择,根据不同的业务,不同的数据一致性要求,结合系统的性能综合考虑,选择适合自己系统的方案就好。
总的来说,由于我们的基本原则是以数据库为准,那么我们选择的方案就应该把操作数据库放到前面,也就是说我们应该先操作数据库,再操作 Redis,对于并发很高的场景,我们可以在操作数据库之前通过消息队列来降低客户端对数据库的请求压力。