Leetcode 01-算法入门与数组-①数据结构与算法简介
LeetCode 01-算法入门与数组-①数据结构与算法简介
一. 数据结构与算法

数据结构是程序的骨架,而算法则是程序的灵魂。
《算法 + 数据结构 = 程序》 是 Pascal 语言之父 Niklaus Emil Wirth 写过的一本非常著名的书。而作为书名的这句话也成为了计算机科学的经典名句。可见,对于程序设计来说,算法和数据结构的关系密不可分。
在学习之前,首先我们要弄清楚什么是算法?什么是数据结构?为什么要学习算法和数据结构?
简单来说,「算法」就是解决问题的方法或者过程。如果我们把问题看成是函数,那么算法就是将输入转换为输出的过程。「数据结构」是数据的计算机表示和相应的一组操作。「程序」则是算法和数据结构的具体实现。
如果我们把「程序设计」比作是做菜的话,那么「数据结构」就是食材和调料,「算法」则是不同的烹饪方式,或者可以看作是菜谱。不同的食材和调料,不同的烹饪方式,有着不同的排列组合。同样的东西,由不同的人做出来,味道自然也是千差万别。
至于为什么要学习算法和数据结构?
还是拿做菜举例子。我们做菜,讲究的是「色香味俱全」。程序设计也是如此,对于待解决的问题,我们追求的是:选择更加合适的「数据结构」,使用花费时间更少、占用空间更小的「算法」。
我们学习算法和数据结构,是为了学会在编程中从时间复杂度、空间复杂度方面考虑解决方案,训练自己的逻辑思维,从而写出高质量的代码,以此提升自己的编程技能,获取更高的工作回报。
当然,这就像是做菜,掌握了食材和调料,学会了烹饪方式,并不意味着你就会做出一盘很好吃的炒菜。同样,掌握了算法和数据结构并不意味着你就会写程序。这需要不断的琢磨和思考,并持续学习,才能成为一名优秀的 厨师(程序员)。
1. 数据结构
数据结构(Data Structure):带有结构特性的数据元素的集合。
简单而言,**「数据结构」**指的是:数据的组织结构,用来组织、存储数据。
展开来讲,数据结构研究的是数据的逻辑结构、物理结构以及它们之间的相互关系,并对这种结构定义相应的运算,设计出相应的算法,并确保经过这些运算以后所得到的新结构仍保持原来的结构类型。
数据结构的作用,就是为了提高计算机硬件的利用率。比如说:操作系统想要查找应用程序 「Microsoft Word」 在硬盘中的哪一个位置存储。如果对硬盘全部扫描一遍的话肯定效率很低,但如果使用「B+ 树」作为索引,就能很容易的搜索到 Microsoft Word 这个单词,然后很快的定位到 「Microsoft Word」这个应用程序的文件信息,从而从文件信息中找到对应的磁盘位置。
而学习数据结构,就是为了帮助我们了解和掌握计算机中的数据是以何种方式进行组织、存储的。
对于数据结构,我们可以按照数据的 「逻辑结构」 和 「物理结构」 来进行分类。
1.1 数据的逻辑结构
逻辑结构(Logical Structure):数据元素之间的相互关系。
根据元素之间具有的不同关系,通常我们可以将数据的逻辑结构分为以下四种:
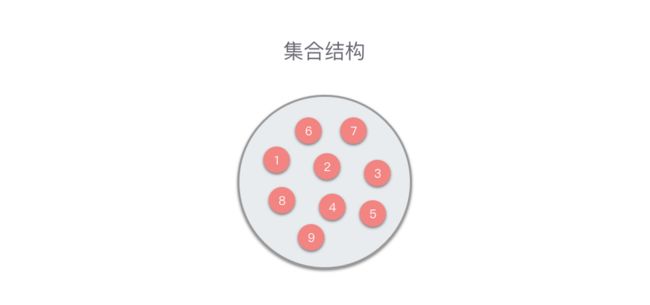
1. 集合结构
集合结构:数据元素同属于一个集合,除此之外无其他关系。
集合结构中的数据元素是无序的,并且每个数据元素都是唯一的,集合中没有相同的数据元素。集合结构很像数学意义上的「集合」。
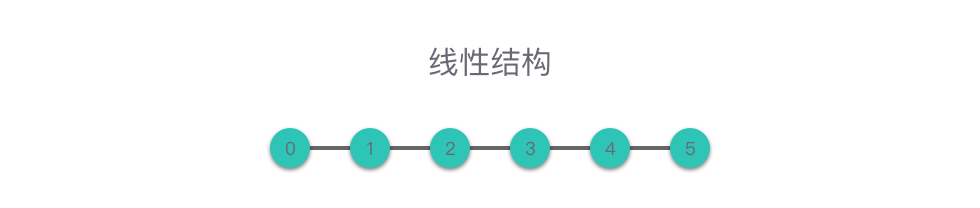
2. 线性结构
线性结构:数据元素之间是「一对一」关系。
线性结构中的数据元素(除了第一个和最后一个元素),左侧和右侧分别只有一个数据与其相邻。线性结构类型包括:数组、链表,以及由它们衍生出来的栈、队列、哈希表。
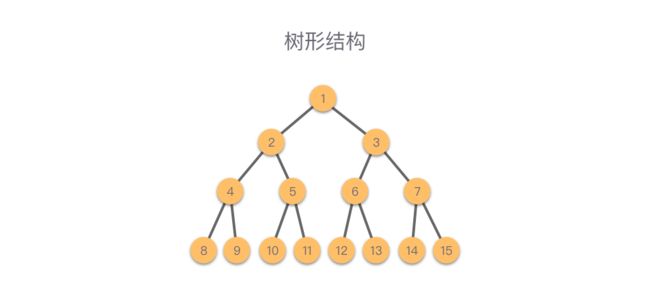
3. 树形结构
树形结构:数据元素之间是「一对多」的层次关系。
最简单的树形结构是二叉树。这种结构可以简单的表示为:根, 左子树, 右子树。 左子树和右子树又有自己的子树。当然除了二叉树,树形结构类型还包括:多叉树、字典树等。
4. 图形结构
图形结构:数据元素之间是「多对多」的关系。
图形结构是一种比树形结构更复杂的非线性结构,用于表示物件与物件之间的关系。一张图由一些小圆点(称为 「顶点」 或 「结点」)和连结这些圆点的直线或曲线(称为 「边」)组成。
在图形结构中,任意两个结点之间都可能相关,即结点之间的邻接关系可以是任意的。图形结构类型包括:无向图、有向图、连通图等。

1.2 数据的物理结构
物理结构(Physical Structure):数据的逻辑结构在计算机中的存储方式。
计算机内有多种存储结构,采用最多的是这两种结构:「顺序存储结构」、「链式存储结构」。
1. 顺序存储结构
顺序存储结构(Sequential Storage Structure):将数据元素存放在一片地址连续的存储单元里,数据元素之间的逻辑关系通过数据元素的存储地址来直接反映。

在顺序存储结构中,逻辑上相邻的数据元素在物理地址上也必然相邻 。
这种结构的优点是:简单、易理解,且实际占用最少的存储空间。缺点是:需要占用一片地址连续的存储单元;并且存储分配要事先进行;另外对于一些操作的时间效率较低(移动、删除元素等操作)。
2. 链式存储结构
链式存储结构(Linked Storage Structure):将数据元素存放在任意的存储单元里,存储单元可以连续,也可以不连续。

链式存储结构中,逻辑上相邻的数据元素在物理地址上可能相邻,可也能不相邻。其在物理地址上的表现是随机的。链式存储结构中,一般将每个数据元素占用的若干单元的组合称为一个链结点。每个链结点不仅要存放一个数据元素的数据信息,还要存放一个指出这个数据元素在逻辑关系的直接后继元素所在链结点的地址,该地址被称为指针。换句话说,数据元素之间的逻辑关系是通过指针来间接反映的。
这种结构的优点是:存储空间不必事先分配,在需要存储空间的时候可以临时申请,不会造成空间的浪费;一些操作的时间效率远比顺序存储结构高(插入、移动、删除元素)。缺点是:不仅数据元素本身的数据信息要占用存储空间,指针也需要占用存储空间,链式存储结构比顺序存储结构的空间开销大。
2. 算法
算法(Algorithm):解决特定问题求解步骤的准确而完整的描述,在计算机中表现为一系列指令的集合,算法代表着用系统的方法描述解决问题的策略机制。
简单而言,「算法」 指的就是解决问题的方法。
展开来讲,算法是某一系列运算步骤,它表达解决某一类计算问题的一般方法,对这类方法的任何一个输入,它可以按步骤一步一步计算,最终产生一个输出。它不依赖于任何一种语言,可以用 自然语言、编程语言(Python、C、C++、Java 等)描述,也可以用 伪代码、流程图 来表示。
下面我们举几个例子来说明什么是算法。
- 示例 1:
问题描述:
- 从上海到北京,应该怎么去?
解决方法:
- 选择坐飞机,坐飞机用的时间最少,但费用最高。
- 选择坐长途汽车,坐长途汽车费用低,但花费时间长。
- 选择坐高铁或火车,花费时间不算太长,价格也不算太贵。
- 示例 2:
问题描述:
- 如何计算 1 + 2 + 3 + … + 100 1 + 2 + 3 + … + 100 1+2+3+…+100 的值?
解决方法:
- 用计算器从 1 1 1 开始,不断向右依次加上 2 2 2,再加上 3 3 3,…,依次加到 100 100 100,得出结果为 5050 5050 5050。
- 根据高斯求和公式:和 = (首项 + 末项) * 项数 / 2,直接算出结果为:$ \frac{(1+100) * 100}{2} = 5050$。
- 示例 3:
问题描述:
- 如何对一个 n n n 个整数构成的数组进行升序排序?
解决方法:
- 使用冒泡排序对 n n n 个整数构成的数组进行升序排序。
- 选择插入排序、归并排序、快速排序等等其他排序算法对 n n n 个整数构成的数组进行升序排序。
以上 3 3 3 个示例中的解决方法都可以看做是算法。从上海去北京的解决方法可以看做是算法,对 1 ∼ 100 1 \sim 100 1∼100 的数进行求和的计算方法也可以看做是算法。对数组进行排序的方法也可以看做是算法。并且从这 3 3 3 个示例中可以看出对于一个特定的问题,往往有着不同的算法。
2.1 算法的基本特性
算法其实就是一系列的运算步骤,这些运算步骤可以解决特定的问题。除此之外,算法 应必须具备以下特性:
- 输入:对于待解决的问题,都要以某种方式交给对应的算法。在算法开始之前最初赋给算法的参数称为输入。比如示例 1 1 1 中的输入就是出发地和目的地的参数(北京,上海),示例 3 3 3 中的输入就是 n n n 个整数构成的数组。一个算法可以有多个输入,也可以没有输入。比如示例 2 2 2 是对固定问题的求解,就可以看做没有输入。
- 输出:算法是为了解决问题存在的,最终总需要返回一个结果。所以至少需要一个或多个参数作为算法的输出。比如示例 1 1 1 中的输出就是最终选择的交通方式,示例 2 2 2 中的输出就是和的结果。示例 3 3 3 中的输出就是排好序的数组。
- 有穷性:算法必须在有限的步骤内结束,并且应该在一个可接受的时间内完成。比如示例 1 1 1,如果我们选择五一从上海到北京去旅游,结果五一纠结了三天也没决定好怎么去北京,那么这个旅游计划也就泡汤了,这个算法自然也是不合理的。
- 确定性:组成算法的每一条指令必须有着清晰明确的含义,不能令读者在理解时产生二义性或者多义性。就是说,算法的每一个步骤都必须准确定义而无歧义。
- 可行性:算法的每一步操作必须具有可执行性,在当前环境条件下可以通过有限次运算实现。也就是说,每一步都能通过执行有限次数完成,并且可以转换为程序在计算机上运行并得到正确的结果。
2.2 算法追求的目标
研究算法的作用,就是为了使解决问题的方法变得更加高效。对于给定的问题,我们往往会有多种算法来解决。而不同算法的 成本 也是不同的。总体而言,一个优秀的算法至少应该追求以下两个目标:
- 所需运行时间更少(时间复杂度更低);
- 占用内存空间更小(空间复杂度更低)。
假设计算机执行一条命令的时间为 1 1 1 纳秒(并不科学),第一种算法需要执行 100 100 100 纳秒,第二种算法则需要执行 3 3 3 纳秒。如果不考虑占用内存空间的话,很明显第二种算法比第一种算法要好很多。
假设计算机一个内存单元的大小为一个字节,第一种算法需要占用 3 3 3 个字节大小的内存空间,第二种算法则需要占用 100 100 100 个字节大小的内存空间,如果不考虑运行时间的话,很明显第一种算法比第二种算法要好很多。
现实中算法,往往是需要同时从运行时间、占用空间两个方面考虑问题。当然,运行时间越少,占用空间越小的算法肯定是越好的,但总是会有各种各样的因素导致了运行时间和占用空间不可兼顾。比如,在程序运行时间过高时,我们可以考虑在空间上做文章,牺牲一定量的空间,来换取更短的运行时间。或者在程序对运行时间要求不是很高,而设备内存又有限的情况下,选择占用空间更小,但需要牺牲一定量的时间的算法。
当然,除了对运行时间和占用内存空间的追求外,一个好的算法还应该追求以下目标:
- 正确性:正确性是指算法能够满足具体问题的需求,程序运行正常,无语法错误,能够通过典型的软件测试,达到预期的需求。
- 可读性:可读性指的是算法遵循标识符命名规则,简洁易懂,注释语句恰当,方便自己和他人阅读,便于后期修改和调试。
- 健壮性:健壮性指的是算法对非法数据以及操作有较好的反应和处理。
这 3 3 3 个目标是算法的基本标准,是所有算法所必须满足的。一般我们对好的算法的评判标准就是上边提到的 所需运行时间更少(时间复杂度更低)、占用内存空间更小(空间复杂度更低)。
3. 总结
3.1 数据结构总结
数据结构可以分为 「逻辑结构」 和 「物理结构」。
-
逻辑结构可分为:集合结构、线性结构、树形结构、图形结构。
-
物理结构可分为:顺序存储结构、链式存储结构。
「逻辑结构」指的是数据之间的 关系,「物理结构」指的是这种关系 在计算机中的表现形式。
例如:线性表中的「栈」,其数据元素之间的关系是一对一的,除头和尾结点之外的每个结点都有唯一的前驱和唯一的后继,这体现的是逻辑结构。而对于栈中的结点来说,可以使用顺序存储(也就是 顺序栈)的方式存储在计算机中,其结构在计算机中的表现形式就是一段连续的存储空间,栈中每个结点和它的前驱结点、后继结点在物理上都是相邻的。当然,栈中的结点也可以使用链式存储(也即是 链式栈),每个结点和它的前驱结点、后继结点在物理上不一定相邻,每个结点是靠前驱结点的指针域来进行访问的。
3.2 算法总结
「算法」 指的就是解决问题的方法。算法是一系列的运算步骤,这些运算步骤可以解决特定的问题。
算法拥有 5 个基本特性:输入、输出、有穷性、确定性、可行性。
算法追求的目标有 5 个:正确性、可读性、健壮性、所需运行时间更少(时间复杂度更低)、占用内存空间更小(空间复杂度更低)。
二. 算法复杂度
1. 算法复杂度简介
算法复杂度(Algorithm complexity):在问题的输入规模为 n n n 的条件下,程序的时间使用情况和空间使用情况。
「算法分析」的目的在于改进算法。正如上文中所提到的那样:算法所追求的就是 所需运行时间更少(时间复杂度更低)、占用内存空间更小(空间复杂度更低)。所以进行「算法分析」,就是从运行时间情况、空间使用情况两方面对算法进行分析。
比较两个算法的优劣通常有两种方法:
- 事后统计:将两个算法各编写一个可执行程序,交给计算机执行,记录下各自的运行时间和占用存储空间的实际大小,从中挑选出最好的算法。
- 预先估算:在算法设计出来之后,根据算法中包含的步骤,估算出算法的运行时间和占用空间。比较两个算法的估算值,从中挑选出最好的算法。
大多数情况下,我们会选择第 2 2 2 种方式。因为第 1 1 1 种方式的工作量实在太大,得不偿失。另外,即便是同一个算法,用不同的语言实现,在不同的计算机上运行,所需要的运行时间都不尽相同。所以我们一般采用预先估算的方法来衡量算法的好坏。
采用预先估算的方式下,编译语言、计算机运行速度都不是我们所考虑的对象。我们只关心随着问题规模 n n n 扩大时,时间开销、空间开销的增长情况。
这里的 「问题规模 n n n」 指的是:算法问题输入的数据量大小。对于不同的算法,定义也不相同。
- 排序算法中: n n n 表示需要排序的元素数量。
- 查找算法中: n n n 表示查找范围内的元素总数:比如数组大小、二维矩阵大小、字符串长度、二叉树节点数、图的节点数、图的边界点等。
- 二进制计算相关算法中: n n n 表示二进制的展开宽度。
一般来说,问题的输入规模越接近,相应的计算成本也越接近。而随着问题输入规模的扩大,计算成本也呈上升趋势。
接下来,我们将具体讲解「时间复杂度」和「空间复杂度」。
2. 时间复杂度
2.1 时间复杂度简介
时间复杂度(Time Complexity):在问题的输入规模为 n n n 的条件下,算法运行所需要花费的时间,可以记作为 T ( n ) T(n) T(n)。
我们将 基本操作次数 作为时间复杂度的度量标准。换句话说,时间复杂度跟算法中基本操作次数的数量正相关。
- 基本操作 :算法执行中的每一条语句。每一次基本操作都可在常数时间内完成。
基本操作是一个运行时间不依赖于操作数的操作。
比如两个整数相加的操作,如果两个数的规模不大,运行时间不依赖于整数的位数,则相加操作就可以看做是基本操作。
反之,如果两个数的规模很大,相加操作依赖于两个数的位数,则两个数的相加操作不是一个基本操作,而每一位数的相加操作才是一个基本操作。
下面通过一个具体例子来说明一下如何计算时间复杂度。
def algorithm(n):
fact = 1
for i in range(1, n + 1):
fact *= i
return fact
把上述算法中所有语句的执行次数加起来 1 + n + n + 1 = 2 n + 2 1 + n + n + 1 = 2n + 2 1+n+n+1=2n+2,可以用一个函数 f ( n ) f(n) f(n) 来表达语句的执行次数: f ( n ) = 2 n + 2 f(n) = 2n + 2 f(n)=2n+2。
则时间复杂度的函数可以表示为: T ( n ) = O ( f ( n ) ) T(n) = O(f(n)) T(n)=O(f(n))。它表示的是随着问题规模 n 的增大,算法执行时间的增长趋势跟 f ( n ) f(n) f(n) 相同。 O O O 是一种渐进符号, T ( n ) T(n) T(n) 称作算法的 渐进时间复杂度(Asymptotic Time Complexity),简称为 时间复杂度。
所谓「算法执行时间的增长趋势」是一个模糊的概念,通常我们要借助像上边公式中 O O O 这样的「渐进符号」来表示时间复杂度。
2.2 渐进符号
渐进符号(Asymptotic Symbol):专门用来刻画函数的增长速度的。简单来说,渐进符号只保留了 最高阶幂,忽略了一个函数中增长较慢的部分,比如 低阶幂、系数、常量。因为当问题规模变的很大时,这几部分并不能左右增长趋势,所以可以忽略掉。
经常用到的渐进符号有三种: Θ \Theta Θ 渐进紧确界符号、 O O O 渐进上界符号、 Ω \Omega Ω 渐进下界符号。接下来我们将依次讲解。
2.2.1 Θ \Theta Θ 渐进紧确界符号
Θ \Theta Θ 渐进紧确界符号:对于函数 f ( n ) f(n) f(n) 和 g ( n ) g(n) g(n), f ( n ) = Θ ( g ( n ) ) f(n) = \Theta(g(n)) f(n)=Θ(g(n))。存在正常量 c 1 c_1 c1、 c 2 c_2 c2 和 n 0 n_0 n0,使得对于所有 n ≥ n 0 n \ge n_0 n≥n0 时,有 0 ≤ c 1 ⋅ g ( n ) ≤ f ( n ) ≤ c 2 ⋅ g ( n ) 0 \le c_1 \cdot g(n) \le f(n) \le c_2 \cdot g(n) 0≤c1⋅g(n)≤f(n)≤c2⋅g(n)。
也就是说,如果函数 f ( n ) = Θ ( g ( n ) ) f(n) = \Theta(g(n)) f(n)=Θ(g(n)),那么我们能找到两个正数 c 1 c_1 c1、 c 2 c_2 c2,使得 f ( n ) f(n) f(n) 被 c 1 ⋅ g ( n ) c_1 \cdot g(n) c1⋅g(n) 和 c 2 ⋅ g ( n ) c_2 \cdot g(n) c2⋅g(n) 夹在中间。
例如: T ( n ) = 3 n 2 + 4 n + 5 = Θ ( n 2 ) T(n) = 3n^2 + 4n + 5 = \Theta(n^2) T(n)=3n2+4n+5=Θ(n2),可以找到 c 1 = 1 c_1 = 1 c1=1, c 2 = 12 c_2 = 12 c2=12, n 0 = 1 n_0 = 1 n0=1,使得对于所有 n ≥ 1 n \ge 1 n≥1,都有 n 2 ≤ 3 n 2 + 4 n + 5 ≤ 12 n 2 n^2 \le 3n^2 + 4n + 5 \le 12n^2 n2≤3n2+4n+5≤12n2。
2.2.2 O O O 渐进上界符号
O O O 渐进上界符号:对于函数 f ( n ) f(n) f(n) 和 g ( n ) g(n) g(n), f ( n ) = O ( g ( n ) ) f(n) = O(g(n)) f(n)=O(g(n))。存在常量 c c c, n 0 n_0 n0,使得当 n > n 0 n > n_0 n>n0 时,有 0 ≤ f ( n ) ≤ c ⋅ g ( n ) 0 \le f(n) \le c \cdot g(n) 0≤f(n)≤c⋅g(n)。
Θ \Theta Θ 符号渐进地给出了一个函数的上界和下界,如果我们只知道一个函数的上界,可以使用 O O O 渐进上界符号。
2.2.3 Ω \Omega Ω 渐进下界符号
Ω \Omega Ω 渐进下界符号:对于函数 f ( n ) f(n) f(n) 和 g ( n ) g(n) g(n), f ( n ) = Ω ( g ( n ) ) f(n) = \Omega(g(n)) f(n)=Ω(g(n))。存在常量 c c c, n 0 n_0 n0,使得当 n > n 0 n > n_0 n>n0 时,有 0 ≤ c ⋅ g ( n ) ≤ f ( n ) 0 \le c \cdot g(n) \le f(n) 0≤c⋅g(n)≤f(n)。
同样,如果我们只知道函数的下界,可以使用 Ω \Omega Ω 渐进下界符号。

2.3 时间复杂度计算
渐进符号可以渐进地描述一个函数的上界、下界,同时也可以描述算法执行时间的增长趋势。
在计算时间复杂度的时候,我们经常使用 O O O 渐进上界符号。因为我们关注的通常是算法用时的上界,而不用关心其用时的下界。
那么具体应该如何计算时间复杂度呢?
求解时间复杂度一般分为以下几个步骤:
- 找出算法中的基本操作(基本语句):算法中执行次数最多的语句就是基本语句,通常是最内层循环的循环体部分。
- 计算基本语句执行次数的数量级:只需要计算基本语句执行次数的数量级,即保证函数中的最高次幂正确即可。像最高次幂的系数和低次幂可以忽略。
- 用大 O 表示法表示时间复杂度:将上一步中计算的数量级放入 O 渐进上界符号中。
同时,在求解时间复杂度还要注意一些原则:
- 加法原则:总的时间复杂度等于量级最大的基本语句的时间复杂度。
如果 T 1 ( n ) = O ( f 1 ( n ) ) T_1(n) = O(f_1(n)) T1(n)=O(f1(n)), T 2 ( n ) = O ( f 2 ( n ) ) T_2(n) = O(f_2(n)) T2(n)=O(f2(n)), T ( n ) = T 1 ( n ) + T 2 ( n ) T(n) = T_1(n) + T_2(n) T(n)=T1(n)+T2(n),则 T ( n ) = O ( f ( n ) ) = m a x ( O ( f 1 ( n ) ) , O ( f 2 ( n ) ) ) = O ( m a x ( f 1 ( n ) , f 2 ( n ) ) ) T(n) = O(f(n)) = max(O(f_1(n)), O(f_2(n))) = O(max(f_1(n), f_2(n))) T(n)=O(f(n))=max(O(f1(n)),O(f2(n)))=O(max(f1(n),f2(n)))。
- 乘法原则:循环嵌套代码的复杂度等于嵌套内外基本语句的时间复杂度乘积。
如果 T 1 = O ( f 1 ( n ) ) T_1 = O(f_1(n)) T1=O(f1(n)), T 2 = O ( f 2 ( n ) ) T_2 = O(f_2(n)) T2=O(f2(n)), T ( n ) = T 1 ( n ) T 2 ( n ) T(n) = T_1(n)T_2(n) T(n)=T1(n)T2(n),则 T ( n ) = O ( f ( n ) ) = O ( f 1 ( n ) ) O ( f 2 ( n ) ) = O ( f 1 ( n ) f 2 ( n ) ) T(n) = O(f(n)) = O(f_1(n))O(f_2(n)) = O(f_1(n)f_2(n)) T(n)=O(f(n))=O(f1(n))O(f2(n))=O(f1(n)f2(n))。
下面通过实例来说明如何计算时间复杂度。
2.3.1 常数 O ( 1 ) O(1) O(1)
一般情况下,只要算法中不存在循环语句、递归语句,其时间复杂度都为 O ( 1 ) O(1) O(1)。
O ( 1 ) O(1) O(1) 只是常数阶时间复杂度的一种表示方式,并不是指只执行了一行代码。只要代码的执行时间不随着问题规模 n n n 的增大而增长,这样的算法时间复杂度都记为 O ( 1 ) O(1) O(1)。
def algorithm(n):
a = 1
b = 2
res = a * b + n
return res
上述代码虽然有 4 4 4 行代码,但时间复杂度也是 O ( 1 ) O(1) O(1),而不是 O ( 3 ) O(3) O(3)。
2.3.2 线性 O ( n ) O(n) O(n)
一般含有非嵌套循环,且单层循环下的语句执行次数为 n n n 的算法涉及线性时间复杂度。这类算法随着问题规模 n n n 的增大,对应计算次数呈线性增长。
def algorithm(n):
sum = 0
for i in range(n):
sum += 1
return sum
上述代码中 sum += 1 的执行次数为 n n n 次,所以这段代码的时间复杂度为 O ( n ) O(n) O(n)。
2.3.3 平方 O ( n 2 ) O(n^2) O(n2)
一般含有双层嵌套,且每层循环下的语句执行次数为 n n n 的算法涉及平方时间复杂度。这类算法随着问题规模 n n n 的增大,对应计算次数呈平方关系增长。
def algorithm(n):
res = 0
for i in range(n):
for j in range(n):
res += 1
return res
上述代码中,res += 1 在两重循环中,根据时间复杂度的乘法原理,这段代码的执行次数为 n 2 n^2 n2 次,所以其时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
2.3.4 阶乘 O ( n ! ) O(n!) O(n!)
阶乘时间复杂度一般出现在与「全排列」、「旅行商问题暴力解法」相关的算法中。这类算法随着问题规模 n n n 的增大,对应计算次数呈阶乘关系增长。
def permutations(arr, start, end):
if start == end:
print(arr)
return
for i in range(start, end):
arr[i], arr[start] = arr[start], arr[i]
permutations(arr, start + 1, end)
arr[i], arr[start] = arr[start], arr[i]
上述代码中实现「全排列」使用了递归的方法。假设数组 a r r arr arr 长度为 n n n,第一层 for 循环执行了 n n n 次,第二层 for 循环执行了 n − 1 n - 1 n−1 次。以此类推,最后一层 for 循环执行了 1 1 1 次,将所有层 for 循环的执行次数累乘起来为 n × ( n − 1 ) × ( n − 2 ) × … × 2 × 1 = n ! n \times (n - 1) \times (n - 2) \times … \times 2 \times 1 = n! n×(n−1)×(n−2)×…×2×1=n! 次。则整个算法的 for 循环中基本语句的执行次数为 n ! n! n! 次,所以对应时间复杂度为 O ( n ! ) O(n!) O(n!)。
2.3.5 对数 O ( log n ) O(\log n) O(logn)
对数时间复杂度一般出现在「二分查找」、「分治」这种一分为二的算法中。这类算法随着问题规模 n n n 的增大,对应的计算次数呈对数关系增长。
def algorithm(n):
cnt = 1
while cnt < n:
cnt *= 2
return cnt
上述代码中 cnt = 1 的时间复杂度为 O ( 1 ) O(1) O(1) 可以忽略不算。while 循环体中 c n t cnt cnt 从 1 1 1 开始,每循环一次都乘以 2 2 2。当大于等于 n n n 时循环结束。变量 c n t cnt cnt 的取值是一个等比数列: 2 0 , 2 1 , 2 2 , … , 2 x 2^0,2^1,2^2,…,2^x 20,21,22,…,2x,根据 2 x = n 2^x = n 2x=n,可以得出这段循环体的执行次数为 log 2 n \log_2n log2n,所以这段代码的时间复杂度为 O ( log 2 n ) O(\log_2n) O(log2n)。
因为 log n = k × log 2 n \log n = k \times \log_2 n logn=k×log2n,这里 k = 3.322 k = 3.322 k=3.322,所以, log n \log n logn 与 log 2 n \log_2 n log2n 的差别比较小。为了方便书写,通常我们将对数时间复杂度写作是 O ( log n ) O(\log n) O(logn)。
2.3.6 线性对数 O ( n × log n ) O(n \times \log n) O(n×logn)
线性对数一般出现在排序算法中,例如「快速排序」、「归并排序」、「堆排序」等。这类算法随着问题规模 n n n 的增大,对应的计算次数呈线性对数关系增长。
def algorithm(n):
cnt = 1
res = 0
while cnt < n:
cnt *= 2
for i in range(n):
res += 1
return res
上述代码中外层循环的时间复杂度为 O ( log n ) O(\log n) O(logn),内层循环的时间复杂度为 O ( n ) O(n) O(n),且两层循环相互独立,则总体时间复杂度为 O ( n × log n ) O(n \times \log n) O(n×logn)。
2.3.7 常见时间复杂度关系
根据从小到大排序,常见的时间复杂度主要有: O ( 1 ) O(1) O(1) < O ( log n ) O(\log n) O(logn) < O ( n ) O(n) O(n) < O ( n × log n ) O(n \times \log n) O(n×logn) < O ( n 2 ) O(n^2) O(n2) < O ( n 3 ) O(n^3) O(n3) < O ( 2 n ) O(2^n) O(2n) < O ( n ! ) O(n!) O(n!) < O ( n n ) O(n^n) O(nn)。
2.4 最佳、最坏、平均时间复杂度
时间复杂度是一个关于输入问题规模 n n n 的函数。但是因为输入问题的内容不同,习惯将「时间复杂度」分为「最佳」、「最坏」、「平均」三种情况。这三种情况的具体含义如下:
- 最佳时间复杂度:每个输入规模下用时最短的输入所对应的时间复杂度。
- 最坏时间复杂度:每个输入规模下用时最长的输入所对应的时间复杂度。
- 平均时间复杂度:每个输入规模下所有可能的输入所对应的平均用时复杂度(随机输入下期望用时的复杂度)。
我们通过一个例子来分析下最佳、最坏、最差时间复杂度。
def find(nums, val):
pos = -1
for i in range(n):
if nums[i] == val:
pos = i
break
return pos
这段代码要实现的功能是:从一个整数数组 n u m s nums nums 中查找值为 v a l val val 的变量出现的位置。如果不考虑 break 语句,根据「2.3 时间复杂度计算」中讲的分析步骤,这个算法的时间复杂度是 O ( n ) O(n) O(n),其中 n n n 代表数组的长度。
但是如果考虑 break 语句,那么就需要考虑输入的内容了。如果数组中第 1 1 1 个元素值就是 v a l val val,那么剩下 n − 1 n - 1 n−1 个数据都不要遍历了,那么时间复杂度就是 O ( 1 ) O(1) O(1),即最佳时间复杂度为 O ( 1 ) O(1) O(1)。如果数组中不存在值为 v a l val val 的变量,那么就需要把整个数组遍历一遍,时间复杂度就变成了 O ( n ) O(n) O(n),即最差时间复杂度为 O ( n ) O(n) O(n)。
这样下来,时间复杂度就不唯一了。怎么办?
我们都知道,最佳时间复杂度和最坏时间复杂度都是极端条件下的时间复杂度,发生的概率其实很小。为了能更好的表示正常情况下的复杂度,所以我们一般采用平均时间复杂度作为时间复杂度的计算方式。
还是刚才的例子,在数组 n u m s nums nums 中查找变量值为 v a l val val 的位置,总共有 n + 1 n + 1 n+1 种情况:「在数组的的 0 ∼ n − 1 0 \sim n - 1 0∼n−1 个位置上」和「不在数组中」。我们将所有情况下,需要执行的语句次数累加起来,再除以 n + 1 n + 1 n+1,就可以得到平均需要执行的语句次数,即: 1 + 2 + 3 + . . . + n + n n + 1 = n ( n + 3 ) 2 ( n + 1 ) \frac{1 + 2 + 3 + ... + n + n}{n + 1} = \frac{n(n + 3)}{2(n + 1)} n+11+2+3+...+n+n=2(n+1)n(n+3)。将公式简化后,得到的平均时间复杂度就是 O ( n ) O(n) O(n)。
通常只有同一个算法在输入内容不同,不同时间复杂度有量级的差距时,我们才会通过三种时间复杂度表示法来区分。一般情况下,使用其中一种就可以满足需求了。
3. 空间复杂度
3.1 空间复杂度简介
空间复杂度(Space Complexity):在问题的输入规模为 n n n 的条件下,算法所占用的空间大小,可以记作为 S ( n ) S(n) S(n)。一般将 算法的辅助空间 作为衡量空间复杂度的标准。
除了执行时间的长短,算法所需储存空间的多少也是衡量性能的一个重要方面。而在「2. 时间复杂度」中提到的渐进符号,也同样适用于空间复杂度的度量。空间复杂度的函数可以表示为 S ( n ) = O ( f ( n ) ) S(n) = O(f(n)) S(n)=O(f(n)),它表示的是随着问题规模 n n n 的增大,算法所占空间的增长趋势跟 f ( n ) f(n) f(n) 相同。
相比于算法的时间复杂度计算来说,算法的空间复杂度更容易计算,主要包括「局部变量(算法范围内定义的变量)所占用的存储空间」和「系统为实现递归(如果算法是递归的话)所使用的堆栈空间」两个部分。
下面通过实例来说明如何计算空间复杂度。
3.1 空间复杂度计算
3.1.1 常数 O ( 1 ) O(1) O(1)
def algorithm(n):
a = 1
b = 2
res = a * b + n
return res
上述代码中使用 a a a、 b b b、 r e s res res 这 3 3 3 个局部变量,其所占空间大小为常数阶,并不会随着问题规模 n n n 的在增大而增大,所以该算法的空间复杂度为 O ( 1 ) O(1) O(1)。
3.1.2 线性 O ( n ) O(n) O(n)
def algorithm(n):
if n <= 0:
return 1
return n * algorithm(n - 1)
上述代码采用了递归调用的方式。每次递归调用都占用了 1 1 1 个栈帧空间,总共调用了 n n n 次,所以该算法的空间复杂度为 O ( n ) O(n) O(n)。
3.1.3 常见空间复杂度关系
根据从小到大排序,常见的算法复杂度主要有: O ( 1 ) O(1) O(1) < O ( log n ) O(\log n) O(logn) < O ( n ) O(n) O(n) < O ( n 2 ) O(n^2) O(n2) < O ( 2 n ) O(2^n) O(2n) 等。
算法复杂度总结
「算法复杂度」 包括 「时间复杂度」 和 「空间复杂度」,用来分析算法执行效率与输入问题规模 n n n 的增长关系。通常采用 「渐进符号」 的形式来表示「算法复杂度」。
常见的时间复杂度有: O ( 1 ) O(1) O(1)、 O ( log n ) O(\log n) O(logn)、 O ( n ) O(n) O(n)、 O ( n × log n ) O(n \times \log n) O(n×logn)、 O ( n 2 ) O(n^2) O(n2)、 O ( n 3 ) O(n^3) O(n3)、 O ( 2 n ) O(2^n) O(2n)、 O ( n ! ) O(n!) O(n!)。
常见的空间复杂度有: O ( 1 ) O(1) O(1)、 O ( log n ) O(\log n) O(logn)、 O ( n ) O(n) O(n)、 O ( n 2 ) O(n^2) O(n2)。
三. LeetCode 入门及攻略
1. LeetCode 是什么
「LeetCode」 是一个代码在线评测平台(Online Judge),包含了 算法、数据库、Shell、多线程 等不同分类的题目,其中以算法题目为主。我们可以通过解决 LeetCode 题库中的问题来练习编程技能,以及提高算法能力。
LeetCode 上有 3000 + 3000+ 3000+ 道的编程问题,支持 16 + 16+ 16+ 种编程语言(C、C++、Java、Python 等),还有一个活跃的社区,可以用于分享技术话题、职业经历、题目交流等。
并且许多知名互联网公司在面试的时候喜欢考察 LeetCode 题目,通常会以手写代码的形式出现。需要面试者对给定问题进行分析并给出解答,有时还会要求面试者分析算法的时间复杂度和空间复杂度,以及算法思路。面试官通过考察面试者对常用算法的熟悉程度和实现能力来确定面试者解决问题的思维能力水平。
所以无论是面试国内还是国外的知名互联网公司,通过 LeetCode 刷题,充分准备好算法,对拿到一个好公司的好 offer 都是有帮助的。
2. LeetCode 新手入门
2.1 LeetCode 注册
- 打开 LeetCode 中文主页,链接:力扣(LeetCode)官网。
- 输入手机号,获取验证码。
- 输入验证码之后,点击「登录 / 注册」,就注册好了。

2.2 LeetCode 题库
「题库」是 LeetCode 上最直接的练习入口,在这里可以根据题目的标签、难度、状态进行刷题。也可以按照随机一题开始刷题。

1. 题目标签
LeetCode 的题目涉及了许多算法和数据结构。有贪心,搜索,动态规划,链表,二叉树,哈希表等等,可以通过选择对应标签进行专项刷题,同时也可以看到对应专题的完成度情况。

2. 题目列表
LeetCode 提供了题目的搜索过滤功能。可以筛选相关题单、不同难易程度、题目完成状态、不同标签的题目。还可以根据题目编号、题解数目、通过率、难度、出现频率等进行排序。
3. 当前进度
当前进度提供了一个直观的进度展示。在这里可以看到自己的练习概况。进度会自动展现当前的做题情况。也可以点击「进度设置」创建新的进度,在这里还可以修改、删除相关的进度。
4. 题目详情
从题目大相关题目点击进去,就可以看到这道题目的内容描述和代码编辑器。在这里还可以查看相关的题解和自己的提交记录。

2.3 LeetCode 刷题语言
大厂在面试算法的时候考察的是基本功,用什么语言没有什么限制,也不会影响成绩。日常刷题建议使用自己熟悉的语言,或者语法简洁的语言刷题。
相对于 Java、Python 而言,C、C++ 相关的语法比较复杂,在做题的时候一方面需要思考思路,另一方面还要研究语法。并且复杂的语法也不利于看懂思路,耗费时间较多,不利于刷题效率。在面试的时候往往需要一个小时内尽可能的完成更多的题目,C++ 一旦语法出错很容易慌乱。当然 LeetCode 周赛的大神更偏向于使用 C++ 刷题,这是因为用 C++ 参加算法竞赛已经成为传统了,绝大多数的 OI / ACM 竞赛选手都是 C++ 大神。
就我个人经历而言,我大学参加 ACM 竞赛的时候,用的是 C、C++ 和一点点的 Java。现在刷 LeetCode 为了更高的刷题效率,选择了 Python。感觉用 Python 刷题能更加专注于算法与数据结构本身,也能获得更快的刷题效率。
人生苦短,我用 Python。
2.4 LeetCode 刷题流程
在「2.2 LeetCode 题库 —— 4. 题目详情」中我们介绍了题目的相关情况。
可以看到左侧区域为题目内容描述区域,在这里可以看到题目的内容描述和一些示例数据。而右侧是代码编辑区域,代码编辑区域里边默认显示了待实现的方法。
我们需要在代码编辑器中根据方法给定的参数实现对应的算法,并返回题目要求的结果。然后还要经过「执行代码」测试结果,点击「提交」后,显示执行结果为「通过」时,才算完成一道题目。

总结一下我们的刷题流程为:
- 在 LeetCode 题库中选择一道自己想要解决的题目。
- 查看题目左侧的题目描述,理解题目要求。
- 思考解决思路,并在右侧代码编辑区域实现对应的方法,并返回题目要求的结果。
- 如果实在想不出解决思路,可以查看题目相关的题解,努力理解他人的解题思路和代码。
- 点击「执行代码」按钮测试结果。
- 如果输出结果与预期结果不符,则回到第 3 步重新思考解决思路,并改写代码。
- 如果输出结果与预期符合,则点击「提交」按钮。
- 如果执行结果显示「编译出错」、「解答错误」、「执行出错」、「超出时间限制」、「超出内存限制」等情况,则需要回到第 3 步重新思考解决思路,或者思考特殊数据,并改写代码。
- 如果执行结果显示「通过」,恭喜你通过了这道题目。
接下来我们将通过「1. 两数之和 - 力扣(LeetCode)」这道题目来讲解如何在 LeetCode 上刷题。
2.5 LeetCode 第一题
2.5.1 题目链接
- 1. 两数之和 - 力扣(LeetCode)
2.5.2 题目大意
描述:给定一个整数数组 n u m s nums nums 和一个整数目标值 t a r g e t target target。
要求:在该数组中找出和为 t a r g e t target target 的两个整数,并输出这两个整数的下标。可以按任意顺序返回答案。
说明:
- 2 ≤ n u m s . l e n g t h ≤ 1 0 4 2 \le nums.length \le 10^4 2≤nums.length≤104。
- − 1 0 9 ≤ n u m s [ i ] ≤ 1 0 9 -10^9 \le nums[i] \le 10^9 −109≤nums[i]≤109。
- − 1 0 9 ≤ t a r g e t ≤ 1 0 9 -10^9 \le target \le 10^9 −109≤target≤109。
- 只会存在一个有效答案。
示例:
- 示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
- 示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
2.5.3 解题思路
思路 1:枚举算法
- 使用两重循环枚举数组中每一个数 n u m s [ i ] nums[i] nums[i]、 n u m s [ j ] nums[j] nums[j],判断所有的 n u m s [ i ] + n u m s [ j ] nums[i] + nums[j] nums[i]+nums[j] 是否等于 t a r g e t target target。
- 如果出现 n u m s [ i ] + n u m s [ j ] = = t a r g e t nums[i] + nums[j] == target nums[i]+nums[j]==target,则说明数组中存在和为 t a r g e t target target 的两个整数,将两个整数的下标 i i i、$ j j j 输出即可。
思路 1:代码
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
for i in range(len(nums)):
for j in range(i + 1, len(nums)):
if i != j and nums[i] + nums[j] == target:
return [i, j]
return []
思路 1:复杂度分析
- 时间复杂度: O ( n 2 ) O(n^2) O(n2),其中 n n n 是数组 n u m s nums nums 的元素数量。
- 空间复杂度: O ( 1 ) O(1) O(1)。
思路 2:哈希表
哈希表中键值对信息为 $target-nums[i] :i,其中 i i i 为下标。
- 遍历数组,对于每一个数 n u m s [ i ] nums[i] nums[i]:
- 先查找字典中是否存在 t a r g e t − n u m s [ i ] target - nums[i] target−nums[i],存在则输出 t a r g e t − n u m s [ i ] target - nums[i] target−nums[i] 对应的下标和当前数组的下标 i i i。
- 不存在则在字典中存入 t a r g e t − n u m s [ i ] target - nums[i] target−nums[i] 的下标 i i i。
思路 2:代码
def twoSum(self, nums: List[int], target: int) -> List[int]:
numDict = dict()
for i in range(len(nums)):
if target-nums[i] in numDict:
return numDict[target-nums[i]], i
numDict[nums[i]] = i
return [0]
思路 2:复杂度分析
- 时间复杂度: O ( n ) O(n) O(n),其中 n n n 是数组 n u m s nums nums 的元素数量。
- 空间复杂度: O ( n ) O(n) O(n)。
理解了上面这道题的题意,就可以试着自己编写代码,并尝试提交通过。也可以通过我的解题思路和解题代码,理解之后进行编写代码,并尝试提交通过。
如果提交结果显示「通过」,那么恭喜你完成了 LeetCode 上的第一题。虽然只是一道题,但这意味着刷题计划的开始!希望你能坚持下去,得到应有的收获。
3. LeetCode 刷题攻略
3.1 LeetCode 前期准备
如果你是一个对基础算法和数据结构完全不懂的小白,那么在刷 LeetCode 之前,建议先学习一下基础的 「数据结构」 和 「算法」 知识,这样在开始刷题的时候才不会那么痛苦。
基础的 「数据结构」 和 「算法」 知识包括:
- 常考的数据结构:数组、字符串、链表、树(如二叉树) 等。
- 常考的算法:分治算法、贪心算法、穷举算法、回溯算法、动态规划 等。
这个阶段推荐看一些经典的算法基础书来进行学习。这里推荐一下我看过的感觉不错的算法书:
- 【书籍】「算法(第 4 版)- 谢路云 译」
- 【书籍】「大话数据结构 - 程杰 著」
- 【书籍】「趣学算法 - 陈小玉 著」
- 【书籍】「算法图解 - 袁国忠 译」
- 【书籍】「算法竞赛入门经典(第 2 版) - 刘汝佳 著」
- 【书籍】「数据结构与算法分析 - 冯舜玺 译」
- 【书籍】「算法导论(原书第 3 版) - 殷建平 / 徐云 / 王刚 / 刘晓光 / 苏明 / 邹恒明 / 王宏志 译」
当然,也可以直接看我写的「算法通关手册」,欢迎指正和提出建议,万分感谢。
- 「算法通关手册」GitHub 地址:https://github.com/itcharge/LeetCode-Py
- 「算法通关手册」电子书网站地址:https://algo.itcharge.cn
3.2 LeetCode 刷题顺序
讲个笑话,从前有个人以为 LeetCode 的题目是按照难易程度排序的,所以他从「1. 两数之和」 开始刷题,结果他卡在了 「4. 寻找两个正序数组的中位数」这道困难题上。
LeetCode 的题目序号并不是按照难易程度进行排序的,所以除非硬核人士,不建议按照序号顺序刷题。如果是新手刷题的话,推荐先从「简单」难度等级的算法题开始刷题。等简单题上手熟练之后,再开始按照标签类别,刷中等难度的题。中等难度的题刷差不多之后,可以考虑刷面试题或者难题。
其实 LeetCode 官方网站上就有整理好的题目不错的刷题清单。链接为:https://leetcode.cn/leetbook/。可以先刷这里边的题目卡片。我这里也做了一个整理。
推荐刷题顺序和目录如下:
1. 初级算法、2. 数组类算法、3. 数组和字符串、4. 链表类算法、5. 哈希表、6. 队列 & 栈、7. 递归、8. 二分查找、9. 二叉树、10. 中级算法、11. 高级算法、12. 算法面试题汇总。
当然还可以通过官方新推出的「学习计划 - 力扣」按计划每天刷题。
或者直接按照我整理的分类刷题列表进行刷题:
- 刷题列表(GitHub 版)链接:点击打开「GitHub 版分类刷题列表」
- 刷题列表(网页版)链接:点击打开「网页版分类刷题列表」
正在准备面试、没有太多时间刷题的小伙伴,可以按照我总结的「LeetCode 面试最常考 100 题」、「LeetCode 面试最常考 200 题」进行刷题。
说明:「LeetCode 面试最常考 100 题」、「LeetCode 面试最常考 200 题」是笔者根据「CodeTop 企业题库」按频度从高到低进行筛选,并且去除了一部分 LeetCode 上没有的题目和重复题目后得到的题目清单。
- 「LeetCode 面试最常考 100 题(GitHub 版)」链接:点击打开「LeetCode 面试最常考 100 题(GitHub 版)」
- 「LeetCode 面试最常考 200 题(GitHub 版)」链接:点击打开「LeetCode 面试最常考 200 题(GitHub 版)」
- 「LeetCode 面试最常考 100 题(网页版)」链接:点击打开「LeetCode 面试最常考 100 题(网页版)」
- 「LeetCode 面试最常考 200 题(网页版)」链接:点击打开「LeetCode 面试最常考 200 题(网页版)」
3.3 LeetCode 刷题技巧
下面分享一下我在刷题过程中用到的刷题技巧。简单来说,可以分为 5 5 5 条:
- 五分钟思考法
- 重复刷题
- 按专题分类刷题
- 写解题报告
- 坚持刷题
3.3.1 五分钟思考法
五分钟思考法:如果一道题如果 5 5 5 分钟之内有思路,就立即动手写代码解题。如果 5 5 5 分钟之后还没有思路,就直接去看题解。然后根据题解的思路,自己去实现代码。如果发现自己看了题解也无法实现代码,就认真阅读题解的代码,并理解代码的逻辑。
这种刷题方法其实跟英语里边的背单词过程是类似的。
一开始零基础学英语的时候,先学最简单的字母,不用纠结为什么这个字母这么写。然后学习简单的单词,也不用去纠结这个单词为啥就是这个意思,学就完事。在掌握了基本词汇之后,再去学习词组,学习短句子,然后长句子,再然后再看文章。
而且,在学英语单词的时候,也不是学一遍就会了。而是不断的重复练习、重复记忆加深印象。
算法刷题也是一样,零基础刷题的时候,不要过分纠结怎么自己就想不出来算法的解法,怎么就想不到更加高效的方法。遇到没有思路的题目,老老实实去看题解区的高赞题解,尽可能的让自己快速入门。
3.3.2 重复刷题
重复刷题:遇见不会的题,多刷几遍,不断加深理解。
算法题有时候一遍刷过去,过的时间长了可能就忘了,看到之前做的题不能够立马想到解题思路。这其实还是跟背单词一样,单词也不是看一遍就完全记住了。所以题目刷完一遍并不是结束了,还需要不断的回顾。
而且,一道题目可能有多种解法,还可能有好的算法思路。
最开始做的时候,可能只能想到一种思路,再做第二遍的时候,很有可能会想到了新的解法,新的优化方式等等。
所以,算法题在做完一遍之后遇见不会的,还可以多刷几遍,不断加深理解。
3.3.3 按专题分类刷题
按专题分类刷题:按照不分专题分类刷题,既可以巩固刚学完的算法知识,还可以提高刷题效率。
在上边「3.2 LeetCode 刷题顺序」我们给出了刷题顺序和目录。这里的刷题顺序其实就是按照不同分类来进行排序的。
我们可以在学习相关算法和数据结构知识时,顺便做一下该算法和数据结构知识专题下对应的题目清单。比如在学习完「链表」相关的基础知识时,可以将「链表」相关的基础题目刷完,或者刷官方 LeetBook 清单 4. 链表类算法 中的对应题目。
按照专题分类刷题的第一个好处是:可以巩固刚学完的算法知识。 如果是第一次学习对应的算法知识,刚学完可能对里边的相关知识理解的不够透彻,或者说可能会遗漏一些关键知识点,这时候可以通过刷对应题目的方式来帮助我们巩固刚学完的算法知识。
按照专题分类刷题的第二个好处是:可以提高刷题效率。 因为同一类算法题目所用到的算法知识其实是相同或者相似的,同一种解题思路可以运用到多道题目中。通过不断求解同一类算法专题下的题目,可以大大的提升我们的刷题速度。
3.3.4 写解题报告
写解题报告:如果能够用简介清晰的语言让别人听懂这道题目的思路,那就说明你真正理解了这道题的解法。
刷算法题,有一个十分有用的技巧,就是 「写解题报告」。如果你刷完一道题,能把这道题的解题步骤,做题思路用通俗易懂的话写成解题报告,那么这道题就算是掌握了。这其实就相当于「费曼学习法」的思维。
这样,也可以减少刷题的遍数。如果在写题的时候遇到之前刷过的题,但一时之间没有思路的,就可以看看自己之前的解题报告。这样就节省了大量重复刷题的时间。
3.3.5 坚持刷题
坚持刷题:算法刷题没有捷径,只有不断的刷题、总结,再刷题,再总结。
千万不要相信很多机构宣传的「3 天带你精通数据结构」、「7 天从算法零基础到精通」能让你快速学会算法知识。
学习算法和数据结构知识,不能靠速成,只能靠不断的积累,一步一步的推敲算法步骤,一遍又一遍的理解算法思想,才能掌握一个又一个的算法知识。而且还要不断的去刷该算法对应专题下的题目,才能将算法知识应用到日常的解题过程中。这样才能算彻底掌握了一个算法或一种解题思路。
根据我过去一年多和小伙伴们一起刷题打卡的经验发现:那些能够坚持每天刷题,并最终学会一整套「基础算法知识」和「基础数据结构知识」的人,总是少数人。
大部分总会因为种种主观和客观原因而放弃了刷题(工作繁忙、学习任务繁重、个人精力有限、时间不足等)。
但不管怎么样,如果你当初选择了学习算法知识,选择了通过刷题来通过面试,以便获取更好的工作岗位。那我希望在达成自己的目标之前,可以一直坚持下去,去「刻意练习」。在刷题的过程中收获知识,通过刷题得到满足感,从而把刷题变成兴趣。
这些话有些鸡汤了,但都是我的心里话。希望大家能够一起坚持刷题,争取早日实现自己的目标。
四. 练习题目
1. 2235. 两整数相加
1.1 题目大意
描述:给定两个整数 num1 和 num2。
要求:返回这两个整数的和。
说明:
- − 100 ≤ n u m 1 , n u m 2 ≤ 100 -100 \le num1, num2 \le 100 −100≤num1,num2≤100。
示例:
示例 1:
输入:num1 = 12, num2 = 5
输出:17
解释:num1 是 12,num2 是 5,它们的和是 12 + 5 = 17,因此返回 17。
示例 2:
输入:num1 = -10, num2 = 4
输出:-6
解释:num1 + num2 = -6,因此返回 -6。
1.2 解题思路
思路 1:直接计算
- 直接计算整数
num1与num2的和,返回num1 + num2即可。
思路 1:代码
class Solution:
def sum(self, num1: int, num2: int) -> int:
return num1 + num2
思路 1:复杂度分析
- 时间复杂度: O ( 1 ) O(1) O(1)。
- 空间复杂度: O ( 1 ) O(1) O(1)。
2. 1929. 数组串联
2.1 题目大意
描述:给定一个长度为 n 的整数数组 nums。
要求:构建一个长度为 2 * n 的答案数组 ans,答案数组下标从 0 开始计数 ,对于所有 0 <= i < n 的 i ,满足下述所有要求:
ans[i] == nums[i]。ans[i + n] == nums[i]。
具体而言,ans 由两个 nums 数组「串联」形成。
说明:
- n = = n u m s . l e n g t h n == nums.length n==nums.length。
- 1 ≤ n ≤ 1000 1 \le n \le 1000 1≤n≤1000。
- 1 ≤ n u m s [ i ] ≤ 1000 1 \le nums[i] \le 1000 1≤nums[i]≤1000。
示例:
输入:nums = [1,2,1]
输出:[1,2,1,1,2,1]
解释:数组 ans 按下述方式形成:
- ans = [nums[0],nums[1],nums[2],nums[0],nums[1],nums[2]]
- ans = [1,2,1,1,2,1]
输入:nums = [1,3,2,1]
输出:[1,3,2,1,1,3,2,1]
解释:数组 ans 按下述方式形成:
- ans = [nums[0],nums[1],nums[2],nums[3],nums[0],nums[1],nums[2],nums[3]]
- ans = [1,3,2,1,1,3,2,1]
2.2 解题思路
思路 1:按要求模拟
- 定义一个数组变量(列表)
ans作为答案数组。 - 然后按顺序遍历两次数组
nums中的元素,并依次添加到ans的尾部。最后返回ans。
思路 1:代码
class Solution:
def getConcatenation(self, nums: List[int]) -> List[int]:
ans = []
for num in nums:
ans.append(num)
for num in nums:
ans.append(num)
return ans
思路 1:复杂度分析
- 时间复杂度: O ( n ) O(n) O(n),其中 n n n 为数组
nums的长度。 - 空间复杂度: O ( n ) O(n) O(n)。如果算上答案数组的空间占用,则空间复杂度为 O ( n ) O(n) O(n)。不算上则空间复杂度为 O ( 1 ) O(1) O(1)。
思路 2:利用运算符
Python 中可以直接利用 + 号运算符将两个列表快速进行串联。即 return nums + nums。
思路 2:代码
class Solution:
def getConcatenation(self, nums: List[int]) -> List[int]:
return nums + nums
思路 2:复杂度分析
- 时间复杂度: O ( n ) O(n) O(n),其中 n n n 为数组
nums的长度。 - 空间复杂度: O ( n ) O(n) O(n)。如果算上答案数组的空间占用,则空间复杂度为 O ( n ) O(n) O(n)。不算上则空间复杂度为 O ( 1 ) O(1) O(1)。
3. 0771. 宝石与石头
3.1 题目大意
描述:给定一个字符串 jewels 代表石头中宝石的类型,再给定一个字符串 stones 代表你拥有的石头。stones 中每个字符代表了一种你拥有的石头的类型。
要求:计算出拥有的石头中有多少是宝石。
说明:
- 字母区分大小写,因此
a和A是不同类型的石头。 - 1 ≤ j e w e l s . l e n g t h , s t o n e s . l e n g t h ≤ 50 1 \le jewels.length, stones.length \le 50 1≤jewels.length,stones.length≤50。
jewels和stones仅由英文字母组成。jewels中的所有字符都是唯一的。
示例:
输入:jewels = "aA", stones = "aAAbbbb"
输出:3
输入:jewels = "z", stones = "ZZ"
输出:0
3.2 解题思路
思路 1:暴力
- 暴力法的思路很直观,遍历字符串
stones - 对于
stones中的每个字符,遍历一次字符串jewels- 如果其和
jewels中的某一个字符相同,则是宝石。
- 如果其和
思路 1:代码
class Solution:
def numJewelsInStones(self, jewels: str, stones: str) -> int:
return sum(s in jewels for s in stones)
思路 1:复杂度分析
-
时间复杂度: O ( m n ) O(mn) O(mn),其中 m m m 是字符串
jewels的长度, n n n 是字符串stones的长度。遍历字符串stones的时间复杂度是 O ( n ) O(n) O(n),对于stones中的每个字符,需要遍历字符串jewels判断是否是宝石,时间复杂度是 O ( m ) O(m) O(m),因此总时间复杂度是 O ( m n ) O(mn) O(mn)。 -
空间复杂度: O ( 1 ) O(1) O(1)。只需要维护常量的额外空间。
思路 2:哈希表
- 用
count来维护石头中的宝石个数。 - 先使用哈希表或者集合存储宝石。
- 再遍历数组
stones,并统计每块石头是否在哈希表中或集合中。- 如果当前石头在哈希表或集合中,则
count += 1。 - 如果当前石头不在哈希表或集合中,则不统计。
- 如果当前石头在哈希表或集合中,则
- 最后返回
count。
思路 2:代码
class Solution:
def numJewelsInStones(self, jewels: str, stones: str) -> int:
jewel_dict = dict()
for jewel in jewels:
jewel_dict[jewel] = 1
count = 0
for stone in stones:
if stone in jewel_dict:
count += 1
return count
思路 2:复杂度分析
- 时间复杂度: O ( m + n ) O(m + n) O(m+n),其中 m m m 是字符串
jewels的长度, n n n 是stones的长度。 - 空间复杂度: O ( m ) O(m) O(m),其中 m m m 是字符串
jewels的长度。
4. 1480. 一维数组的动态和
4.1 题目大意
描述:给定一个数组 nums。
要求:返回数组 nums 的动态和。
说明:
- 动态和:数组前
i项元素和构成的数组,计算公式为runningSum[i] = sum(nums[0] … nums[i])。
示例:
输入:nums = [1,2,3,4]
输出:[1,3,6,10]
解释:动态和计算过程为 [1, 1+2, 1+2+3, 1+2+3+4]。
输入:nums = [1,1,1,1,1]
输出:[1,2,3,4,5]
解释:动态和计算过程为 [1, 1+1, 1+1+1, 1+1+1+1, 1+1+1+1+1]。
4.2 解题思路
思路 1:递推
根据动态和的公式 runningSum[i] = sum(nums[0] … nums[i]),可以推导出:
r u n n i n g S u m = { n u m s [ 0 ] , i = 0 r u n n i n g S u m [ i − 1 ] + n u m s [ i ] , i > 0 runningSum = \begin{cases} nums[0], & i = 0 \cr runningSum[i - 1] + nums[i], & i > 0\end{cases} runningSum={nums[0],runningSum[i−1]+nums[i],i=0i>0
则解决过程如下:
- 新建一个长度等于
nums的数组res用于存放答案。 - 初始化
res[0] = nums[0]。 - 从下标
1开始遍历数组nums,递推更新res[i] = res[i - 1] + nums[i]。 - 遍历结束,返回
res作为答案。
思路 1:代码
class Solution:
def runningSum(self, nums: List[int]) -> List[int]:
size = len(nums)
res = [0 for _ in range(size)]
for i in range(size):
if i == 0:
res[i] = nums[i]
else:
res[i] = res[i - 1] + nums[i]
return res
思路 1:复杂度分析
- 时间复杂度: O ( n ) O(n) O(n)。一重循环遍历的时间复杂度为 O ( n ) O(n) O(n)。
- 空间复杂度: O ( n ) O(n) O(n)。如果算上答案数组的空间占用,则空间复杂度为 O ( n ) O(n) O(n)。不算上则空间复杂度为 O ( 1 ) O(1) O(1)。
5. 0709. 转换成小写字母
5.1 题目大意
描述:给定一个字符串 s。
要求:将该字符串中的大写字母转换成相同的小写字母,返回新的字符串。
说明:
- 1 ≤ s . l e n g t h ≤ 100 1 \le s.length \le 100 1≤s.length≤100。
s由 ASCII 字符集中的可打印字符组成。
示例:
输入:s = "Hello"
输出:"hello"
输入:s = "LOVELY"
输出:"lovely"
5.2 解题思路
思路 1:直接模拟
- 大写字母
A~Z的 ASCII 码范围为[65, 90]。 - 小写字母
a~z的 ASCII 码范围为[97, 122]。
将大写字母的 ASCII 码加 32,就得到了对应的小写字母,则解决步骤如下:
- 使用一个字符串变量
ans存储最终答案字符串。 - 遍历字符串
s,对于当前字符ch:- 如果
ch的 ASCII 码范围在[65, 90],则说明ch为大写字母。将ch的 ASCII 码增加32,再转换为对应的字符,存入字符串ans的末尾。 - 如果
ch的 ASCII 码范围不在[65, 90],则说明ch为小写字母。直接将ch存入字符串ans的末尾。
- 如果
- 遍历完字符串
s,返回答案字符串ans。
思路 1:代码
class Solution:
def toLowerCase(self, s: str) -> str:
ans = ""
for ch in s:
if ord('A') <= ord(ch) <= ord('Z'):
ans += chr(ord(ch) + 32)
else:
ans += ch
return ans
思路 1:复杂度分析
- 时间复杂度: O ( n ) O(n) O(n)。一重循环遍历的时间复杂度为 O ( n ) O(n) O(n)。
- 空间复杂度: O ( n ) O(n) O(n)。如果算上答案数组的空间占用,则空间复杂度为 O ( n ) O(n) O(n)。不算上则空间复杂度为 O ( 1 ) O(1) O(1)。
思路 2:使用 API
Python 语言中自带大写字母转小写字母的 API:lower(),用 API 转换完成之后,直接返回新的字符串。
思路 2:代码
class Solution:
def toLowerCase(self, s: str) -> str:
return s.lower()
思路 2:复杂度分析
- 时间复杂度: O ( n ) O(n) O(n)。一重循环遍历的时间复杂度为 O ( n ) O(n) O(n)。
- 空间复杂度: O ( n ) O(n) O(n)。如果算上答案数组的空间占用,则空间复杂度为 O ( n ) O(n) O(n)。不算上则空间复杂度为 O ( 1 ) O(1) O(1)。
6. 1672. 最富有客户的资产总量
6.1 题目大意
描述:给定一个 m x n 的整数网格 accounts,其中 accounts[i][j] 是第 i 位客户在第 j 家银行托管的资产数量。
要求:返回最富有客户所拥有的资产总量。
说明:
- 客户的资产总量:指的是他们在各家银行托管的资产数量之和。
- 最富有客户:资产总量最大的客户。
- m = = a c c o u n t s . l e n g t h m == accounts.length m==accounts.length。
- n = = a c c o u n t s [ i ] . l e n g t h n == accounts[i].length n==accounts[i].length。
- 1 ≤ m , n ≤ 50 1 \le m, n \le 50 1≤m,n≤50。
- 1 ≤ a c c o u n t s [ i ] [ j ] ≤ 100 1 \le accounts[i][j] \le 100 1≤accounts[i][j]≤100。
示例:
输入:accounts = [[1,2,3],[3,2,1]]
输出:6
解释:
第 1 位客户的资产总量 = 1 + 2 + 3 = 6
第 2 位客户的资产总量 = 3 + 2 + 1 = 6
两位客户都是最富有的,资产总量都是 6 ,所以返回 6。
输入:accounts = [[1,5],[7,3],[3,5]]
输出:10
解释:
第 1 位客户的资产总量 = 6
第 2 位客户的资产总量 = 10
第 3 位客户的资产总量 = 8
第 2 位客户是最富有的,资产总量是 10,随意返回 10。
6.2 解题思路
思路 1:直接模拟
- 使用变量
max_ans存储最富有客户所拥有的资产总量。 - 遍历所有客户,对于当前客户
accounts[i],统计其拥有的资产总量。 - 将当前客户的资产总量与
max_ans进行比较,如果大于max_ans,则更新max_ans的值。 - 遍历完所有客户,最终返回
max_ans作为结果。
思路 1:代码
class Solution:
def maximumWealth(self, accounts: List[List[int]]) -> int:
max_ans = 0
for i in range(len(accounts)):
total = 0
for j in range(len(accounts[i])):
total += accounts[i][j]
if total > max_ans:
max_ans = total
return max_ans
思路 1:复杂度分析
- 时间复杂度: O ( m ∗ n ) O(m * n) O(m∗n)。其中 m m m 和 n n n 分别为二维数组 a c c o u n t s accounts accounts 的行数和列数。两重循环遍历的时间复杂度为 O ( m ∗ n ) O(m * n) O(m∗n) 。
- 空间复杂度: O ( 1 ) O(1) O(1)。