嵩天《Python网络爬虫与信息提取》实例4:股票数据定向爬虫
这一部分将结合嵩天老师在网络爬虫专题课程讲解的requests库和re库的知识进行股票数据定向爬虫代码编写,同时运用json库和csv库对爬取的股票信息数据进行处理与保存。
说明:爬虫练习仅为学习,不做商用,如有侵权,烦请联系删除!
目标网站:
东方财富网 http://quote.eastmoney.com/center/gridlist.html#sz_a_board (获取股票列表)
富途牛牛网 https://www.futunn.com/quote/cn(获取个股信息)
爬取目标:通过东方财富网获取股票列表,借此构造链接从富途牛牛网获取个股信息并保存到本地列表中。
相关库名:requests/re/json/csv
目录
1.网页解析
2.代码设计
3.执行结果
1.网页解析
首先选取东方财富网 http://quote.eastmoney.com/center/gridlist.html#sz_a_board 作为获取股票列表的网站,随机选取其中的深圳A股列表作为接下来爬取的目标,可以看到,页面会显示股票代码、名称等信息:

鼠标右键查看页面源代码,ctrl+f调出搜索框,将其中第一只股票的代码“300182”复制到搜索框,搜索结果为0,即源代码文本中并没有相关信息,说明可能是以json数据的格式保存的,而嵩天老师的网课中东方财富网的列表信息是保存在源代码中的,所以接下来获取股票列表的代码就需要进行相应的修改。

继续查找数据存储位置,鼠标右键点击检查→网络,刷新页面后得到相关的请求URL信息,浏览后发现get?cb=jOuery这条存储着股票信息,事实上,不仅是股票代码和名称,其他信息诸如最新价、涨跌幅、成交量也一一保存在此,所以其实可以直接从东方财富网爬取个股信息。但是嵩天老师的做法是从一个网站获取列表,再构建URL从另一个网站爬取个股信息,这里还是仿照嵩天老师的做法,正好借此练习跨网站爬虫。

从“预览”切换到“标头”查看此URL的具体链接,如下:

复制如下,同样的方法找到第二页的这个请求URL,也复制到此,对比发现此时pn的值由1变为了2,说明后期改变此处数值即可实现翻页功能。同时pn前的一串数字发生了变化,第一页是1642145238723,第二页则是1642145238721:
http://29.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124020678321600938476_1642145238723&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1642145238724
http://29.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124020678321600938476_1642145238721&pn=2&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1642145238803
猜测这串数字是毫秒级别的时间戳,将其中第一页的这串数字复制到时间戳在线转换网站时间戳 | 时间戳转换 | Unix timestamp,发现果真如此,不过经过测试发现并不需要构造即时时间戳,只改变页码也可以获得其他页的信息。

接下来看获取个股信息的网站,从富途牛牛网随机选取一只深圳交易所的股票,打开其个股页面如下,可以看到,个股网页链接的最后是由“股票代码-SZ”组成,说明后期仅需要通过东方财富网获取股票代码列表,再利用列表中的代码构造链接,就可以得到个股网页。

同样的,鼠标右键查看页面源代码,ctrl+f调出搜索框,再将价格复制到搜索框可以看到股票的价格信息在代码文本中的位置,其他信息也保存在此,说明此时个股信息是写在源代码文本中的。

如图,可以看到个股其他信息如最高/今开/成交额等信息都是保存在"stockInfo"标签下,后期直接通过代码获取相应标签下的信息即可。

2.代码设计
完整代码如下,主要参考嵩天老师慕课中提供的源代码,但因为网页存储数据方式的不同,所以变动之处较多,相关讲解见注释:
#实例:股票数据定向爬虫
import requests
import re
import json
import csv
def getHTMLText(url):
#定义获取网页源代码文本内容的函数
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62'}
r=requests.get(url,headers=headers,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
def getStockList(lst,stockURL):
html=getHTMLText(stockURL)
data=re.search(('.*?"diff":(.*?)}}'),html).group(1)
#使用正则表达式匹配股票信息存储位置
jsonData=json.loads(data)
#将数据使用json格式化
for i in range(20):
#代码保存在f12键值中
f=jsonData[i]
lst.append(f['f12'])
def getStockInfo(lst,stockURL,datas):
count=0
#创建一个计数器用于打印爬取进展
for stock in lst:
count=count+1
print('正在处理富途牛牛网第{}只股票'.format(count))
url=stockURL+stock+'-SZ'
#构建个股网页链接
html=getHTMLText(url)
#调用函数打开网页
data=re.search(('"stockInfo":(.*?})'),html).group(1)
#个股信息都以字典的形式放置在"stockInfo"标签下,用正则表达式匹配提取出此处的个股信息源代码文本
dictData=json.loads(data)
#将数据使用json格式化为字典形式
datas.append(dictData)
#保存到列表中
key=list(dictData.keys())
#提取字典中的键名作为表头
return key
def saveStockInfo(key,datas):
with open(r'C:\Users\zhong\Desktop\stockData.csv','a',newline='') as f:
#'a'表示以追加的形式写入数据,newline=''表示数据之间不空行,此处数据好像是gbk格式,所以不需要指定编码为utf-8
writer=csv.DictWriter(f,fieldnames=key)
#提前预览列名,接下来写入数据时会一一对应
writer.writeheader()
#写入列名
writer.writerows(datas)
#写入个股信息数据
def main():
stock_list_url='http://66.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408511497985758365_1642161610438&pn={}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1642161610439'
#获取股票列表的链接,这里给出的是东方财富网深证A股的列表数据请求URL链接,其中页码处留空
stock_info_url='https://www.futunn.com/stock/'
#富途牛牛网获取个股信息的基础链接,这里在其后加上“股票代码-SZ”即可打开个股网页
stockList=[]
#设置一个空列表用于放置股票代码
datas=[]
#创建一个列表用于放置个股数据
page=2
#设置股票列表爬取的页码
for i in range(page):
print('开始处理东方财富网第{}页股票列表'.format(i+1))
url=stock_list_url.format(i+1)
#构造东方财富网股票列表链接
getStockList(stockList,url)
#调用函数收集股票列表网页中的股票代码数据
key=getStockInfo(stockList,stock_info_url,datas)
#调用函数收集并保存个股信息数据
saveStockInfo(key,datas)
print('执行完毕')
main()3.执行结果
IDLE页面执行结果显示如下:

保存到本地的csv文件打开如下:
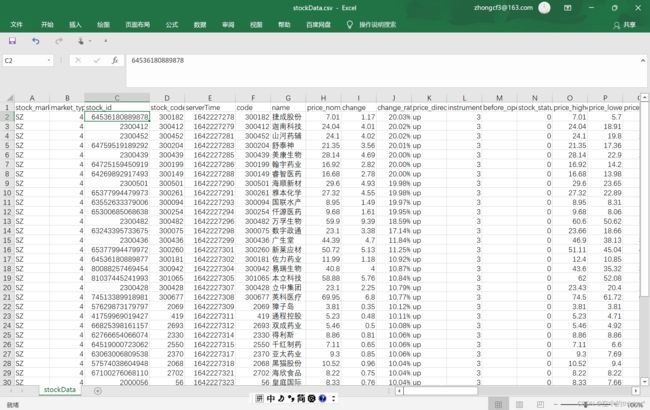
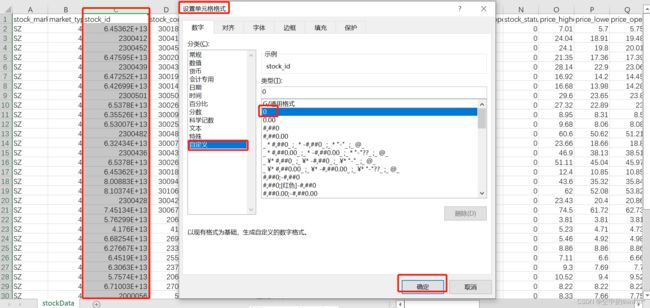
事实上这里的stocs_id等数据因为长度超过了10所以一开始是显示为E+的形式,如图所示:

解决这一数字显示问题的方法是选中此类数字所在列,鼠标右键选择设置单元格格式→数字→自定义→类型处下拉选择0,最后点击确定,数字就能正常显示了。
在编写代码的过程中还是遇到了颇多问题的,不过没有将其一一记录下来,大部分都是数据保存方面的问题,主要还是因为对数据格式方面的基础知识不了解导致的,最后经过不断调整能够保存好完整的数据,也算圆满了。
之前学习这部分网课的时候因为网页改版在修改代码时一筹莫展,完全没有主动依据实际情况改编代码的魄力与能力,如今再次学习这一章节的课程,已经能够成功爬取想要的信息了,果然还是事在人为,那就,不断学习吧,常学常新,加油~
参考资料:
嵩天. Python网络爬虫与信息提取[EB/OL].https://www.icourse163.org/course/BIT-1001870001.