Java多线程篇(3)——线程池
文章目录
- 线程池
- ThreadPoolExecutor源码分析
-
- 1、如何提交任务
- 2、如何执行任务
- 3、如何停止过期的非核心线程
- 4、如何使用拒绝策略
- ScheduledThreadPoolExecutor源码分析
线程池
快速过一遍基础知识
7大参数
corePoolSize : 核心线程数
maximumPoolSize: 最大线程数
keepAliveTime: 空闲线程存活时间
TimeUnit: 时间单位
BlockingQueue:任务队列
ThreadFactory: 创建线程的工厂
RejectedExecutionHandler:拒绝策略
拒绝策略
AbortPolicy:中止策略,线程池会抛出异常并中止执行此任务;
CallerRunsPolicy:把任务交给添加此任务的(main)线程来执行;
DiscardPolicy:忽略此任务,忽略最新的一个任务;
DiscardOldestPolicy:忽略最早的任务,最先加入队列的任务。
内置的线程池
SingleThreadExecutor(单线程):1 - 1 - Interge.MAX(核心线程-最大线程-队列长度)
FixedThreadPool(固定大小):N - N - Interge.MAX
CachedThreadPool(缓存):0 - Integer.MAX - 0
ScheduledThreadPool(定时):线程池的另一个关于定时的分支
为什么不推荐使用内置的线程池?
SingleThreadExecutor和FixedThreadPool无法控制队列长度可能导致OOM ,而CachedThreadPool无法控制线程数量可能导致大量的线程创建。
ThreadPoolExecutor源码分析
先不考虑ScheduledThreadPool,后面再单独说明定时线程池。
1、如何提交任务
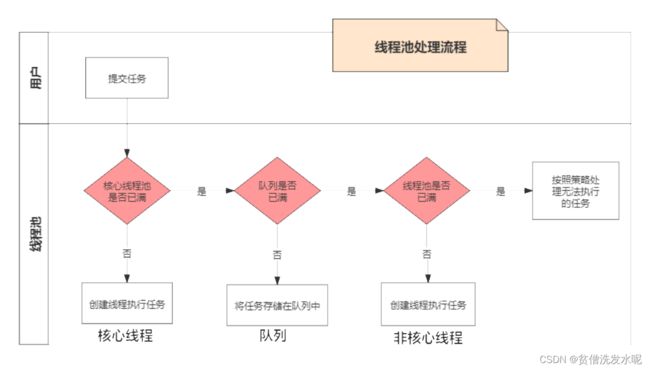
ThreadPoolExecutor#execute
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//新建核心线程
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//加入阻塞队列
if (isRunning(c) && workQueue.offer(command)) {
//双重检测
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
//如果当前没有正在运行的线程,则新增一个非核心线程(任务为null,表示线程的任务将会从阻塞队列中获取)
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//新建非核心线程
else if (!addWorker(command, false))
reject(command);
}
也就是
submit和execute的区别

其实没啥太大的区别,submit最后也是调用的execute,只不过在调用之前封装了task为FutureTask,表示有返回值的任务,最后将返回值返回。
不过有一点需要注意的是。FutureTask,不仅会返回结果,还会把原本runnable中的异常吃了。所以submit提交的任务如果抛异常了,外部是无法感知的。
FutureTask#run

测试结果

2、如何执行任务
ThreadPoolExecutor#addWorker
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (int c = ctl.get();;) {
if (runStateAtLeast(c, SHUTDOWN) && (runStateAtLeast(c, STOP) || firstTask != null || workQueue.isEmpty()))
return false;
for (;;) {
//COUNT_MASK掩码,舍去前3位(因为前3位是状态位,后面的才是任务数)
if (workerCountOf(c) >= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get();
if (runStateAtLeast(c, SHUTDOWN))
continue retry;
}
}
//上面主要是ctl++,其他很多都是检测
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//新建一个worker,封装了firstTask
//(worker也实现了Runnable,相当于对firstTask封装了一层)
w = new Worker(firstTask);
//这里线程的runable实现是worker而不是firstTask
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int c = ctl.get();
//一些检测
if (isRunning(c) || (runStateLessThan(c, STOP) && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
//Thread.start()->runnable.run()也就是worker.run()->runWorker(worker)
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
addWorker新建worker对象,封装了新建的线程对象和原始task。线程的执行调用如下:
thread.start()->runnable.run()也就是worker.run()->runWorker(worker)

ThreadPoolExecutor#runWorker
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock();
boolean completedAbruptly = true;
try {
//worker的task为null(addWorker传入的参数)则从阻塞队列中获取一个task
while (task != null || (task = getTask()) != null) {
w.lock();
//检测是否需要中止线程
if ((runStateAtLeast(ctl.get(), STOP)
|| (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted())
wt.interrupt();
try {
//执行前回调
beforeExecute(wt, task);
try {
//执行任务
task.run();
//执行后回调
afterExecute(task, null);
} catch (Throwable ex) {
afterExecute(task, ex);
throw ex;
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// finally 调用
processWorkerExit(w, completedAbruptly);
}
}
所以runWorker就是如果worker手上有task,就先把手头上的task执行了,然后再(循环)去阻塞队列获取task执行。如果没有就直接去阻塞队列获取task执行。
那么 finally 那里的 processWorkerExit 是干嘛用的?
执行到processWorkerExit要么就是异常情况跳出循环(completedAbruptly=true),要么就是worker手上和阻塞队列均没有task跳出循环(completedAbruptly=false)。
private void processWorkerExit(Worker w, boolean completedAbruptly) {
//如果是异常退出的,此时workerCount还没调整,所以需要工作线程数减1
if (completedAbruptly)
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
//更新 完成任务数,以及移除worker
try {
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
//尝试终止线程
tryTerminate();
int c = ctl.get();
//如果不是异常退出,则根据配置计算需要的最小工作线程数
//如果是异常退出,或者当前工作线程小于上面根据配置计算的最小工作线程
//则都用一个新worker来替换原来的worker
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return;
}
//启动一个worker替换原来的worker
addWorker(null, false);
}
}
总之这段代码的主要作用是在工作线程退出时,更新线程池的状态、计数,以及根据配置来决定是否需要新的worker替代退出的工作线程,以保持线程池的正常运行。
3、如何停止过期的非核心线程
答案在getTask()。
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
// 一些退出的状态就直接返回
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP) || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
//是否需要超时淘汰
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
//在确保当workQueue不为空时至少有一个工作线程的前提下
//来淘汰超出 maximumPoolSize 或者超时的线程
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
//阻塞获取任务
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
//标记超时
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
其实线程池并没有标记谁是核心线程,谁是非核心线程,只关心核心线程和非核心线程的数量。也就是说无论是哪个线程在获取任务时都有可能被标记为timeOut,并且每次获取任务都会根据核心线程数,最大线程数,当前线程数,timeout标记等判断是否需要当前worker,如果不需要就返回null,跳出runWorker的循环,进而结束线程。
4、如何使用拒绝策略
在提交任务的时候,如果addWorker失败就会进入拒绝策略的逻辑。
public void execute(Runnable command) {
//...
//加入阻塞队列
if (isRunning(c) && workQueue.offer(command)) {
//...
if (! isRunning(recheck) && remove(command))
//双重检测失败进入拒绝策略
reject(command);
//...
}
//新建非核心线程
else if (!addWorker(command, false))
//非核心线程添加失败,进入拒绝策略
reject(command);
}
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}
ScheduledThreadPoolExecutor源码分析
.schedule():延迟执行,只执行一次。
.scheduleAtFixedRate():固定频率执行,按照固定的时间间隔来调度任务。
.scheduleWithFixedDelay():固定延迟执行,在上一次任务完成后的固定延迟之后再次执行任务。
无论是哪种都会先将task封装成 ScheduledFutureTask,然后调用 delayedExecute。
以scheduleAtFixedRate为例:
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (period <= 0L)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
//scheduleWithFixedDelay与scheduleAtFixedRate的区别就只在这里
//scheduleWithFixedDelay 传的是 -unit.toNanos(period)
//后续会根据这个值的正负来判断是固定频率还是固定延迟
unit.toNanos(period),
sequencer.getAndIncrement());
//封装成 ScheduledFutureTask
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
//调用 delayedExecute
delayedExecute(t);
return t;
}
delayedExecute
private void delayedExecute(RunnableScheduledFuture<?> task) {
if (isShutdown())
reject(task);
else {
//task添加到队列
//这同样也是自己实现的一个延迟队列,大概的逻辑就是:先按时间排,如果时间一样就按插入的顺序排。
super.getQueue().add(task);
//一些检测
if (!canRunInCurrentRunState(task) && remove(task))
task.cancel(false);
else
//保证有足够的woker正在工作
ensurePrestart();
}
}
void ensurePrestart() {
int wc = workerCountOf(ctl.get());
if (wc < corePoolSize)
//addWorker跟就上面的是一样的了
addWorker(null, true);
else if (wc == 0)
addWorker(null, false);
}
那么凭什么将Worker的task封装成 ScheduledFutureTask 能起到持续调用的效果,来看看他的 run 方法。
ScheduledFutureTask#run
public void run() {
//一些检测
if (!canRunInCurrentRunState(this))
cancel(false);
//如果不是周期性任务就只调用一次(period不为0则表示不是周期性任务)
else if (!isPeriodic())
super.run();
//如果是周期性任务就在调用完之后
//设置下次调用时间并将任务放回队列且保证有足够的woker正在工作
else if (super.runAndReset()) {
setNextRunTime();
reExecutePeriodic(outerTask);
}
}
ScheduledFutureTask#setNextRunTime
private void setNextRunTime() {
long p = period;
//根据period的正负来区分是固定频率还是固定延迟
if (p > 0)
time += p;
else
time = triggerTime(-p);
}
ScheduledThreadPoolExecutor#reExecutePeriodic
void reExecutePeriodic(RunnableScheduledFuture<?> task) {
if (canRunInCurrentRunState(task)) {
//放回队列
super.getQueue().add(task);
if (canRunInCurrentRunState(task) || !remove(task)) {
//保证有足够的woker正在工作
ensurePrestart();
return;
}
}
task.cancel(false);
}
所以ScheduledThreadPoolExecutor的总体框架设计和上面的ThreadPoolExecutor是一样的(毕竟是他的子类)。
最主要的区别在于ScheduledThreadPoolExecutor里worker使用的task是自己内部实现的 ScheduledFutureTask 类,而该类的run方法在执行完后会设置下一次的执行时间并将任务放回队列中等待执行。