本文已收录至GitHub,推荐阅读 Java随想录
微信公众号:Java随想录
原创不易,注重版权。转载请注明原作者和原文链接
这篇文章来聊聊缓存。在处理高流量的互联网应用时,缓存起着至关重要的作用,是优化网站性能的第一手段。
缓存可以显著地提高系统的性能和用户体验,让访问速度更快。
提到缓存,我们往往首先想到的就是Redis。确实,Redis是缓存最常见的实现手段,但Redis并不是「银弹」,在某些场景下Redis未必是最佳选项。
本文会介绍几种缓存方案,希望能帮读者打开思路。具体实际应用场景中该使用哪种方案,各位读者见仁见智了。
Nginx缓存
Nginx可以通过「Proxy Buffer」和「Proxy Cache」实现缓存的目的。
Proxy Buffer
Nginx的Proxy Buffer是用来临时存储从代理服务器收到的响应数据的。
在反向代理场景中,Nginx会从后端服务器接收响应,然后再将这些响应发送给客户端。如果响应速度较慢,或者一次性数据量较大,可能会导致Nginx阻塞,不能及时处理其他请求。
这时候,Proxy Buffer就显得非常有用,它可以暂存这部分数据,让Nginx能够继续处理其他请求。
举个例子,假设有一个大文件需要通过Nginx从后端服务器传输到用户浏览器。当Nginx从后端服务器获取该文件时,如果没有使用Proxy Buffer,Nginx就必须一直等待整个文件都传输完毕,才能释放出来处理其他请求。
但如果启用了Proxy Buffer,那么Nginx就可以把接收到的数据先存放到Buffer里,然后逐步传输给用户,同时也能处理其他请求。这样就大大提高了Nginx的并发处理能力。
Nginx中Proxy Buffer默认是开启的,Proxy Buffer相关参数主要有以下几个:
- proxy_buffering:这是一个开关,用于控制是否启用nginx对后端服务器响应进行缓存。默认值为
on。 - proxy_buffers:定义了需要使用多少个、每个多大的内存缓存区来处理响应。它的设置格式为
number size,比如 "8 4k" 或者 "4 8k"。nginx的默认设置为"8 4k"或"4 8k",取决于操作系统的页面大小。 - proxy_buffer_size:定义读取响应头部的缓冲区大小。这通常不需要修改,除非你预期会有非常大的响应头。这个大小也定义了一次可以读取的最大量数据,因此如果可能接收到超大的回应,则需要增大这个值。默认值为读取
proxy_buffers的第一个参数。 - proxy_busy_buffers_size:在HTTP响应从被代理服务器读入且尚未传送给客户端时,该值限制了可以在busy buffer中使用的内存数。这个值必须小于或等于
proxy_buffers中提供的最大值。没有默认值,但必须设置为不大于proxy_buffers的大小。 - proxy_temp_file_write_size:设置子请求写入临时文件时数据的大小。默认值是8KB或者与 proxy_buffers 相同。
- proxy_max_temp_file_size:设置可以存储在临时文件中的最大数据量,默认值为1024MB。如果超过这个值,nginx将开始删除旧的临时文件。
- proxy_temp_path:定义了存储临时文件的路径。默认是系统的临时目录。
结合上面参数,示例配置如下:
http {
proxy_buffering on;
proxy_buffer_size 4k;
proxy_buffers 8 16k;
proxy_busy_buffers_size 24k;
proxy_temp_file_write_size 32k;
proxy_max_temp_file_size 0;
server {
listen 80;
location / {
proxy_pass http://backend;
proxy_temp_path /path/to/temp;
}
}
}这个配置中,开启了Nginx对后端服务器响应的缓存。同时,设置了读取响应头部的缓冲区大小为4KB,处理响应的内存缓冲区数量为8个,每个16KB。在HTTP响应从被代理服务器读入且尚未传送给客户端时,可以在busy buffer中使用的内存数限制为24KB。子请求写入临时文件时数据的大小设定为32KB。并且设置了可以存储在临时文件中的最大数据量为0,表示没有上限。而临时文件的存储路径则是"/path/to/temp"。
Proxy Cache
Proxy Cache可以将代理的请求结果缓存下来,当有相同的请求到达时,直接返回缓存的结果而不用再次向后端服务器请求,这大大减少了后端服务器的压力并提高了前端响应速度。
Proxy Cache 相关参数主要有以下几个:
- proxy_cache_path:这个指令定义了缓存的存储路径和其他参数。例如,
levels定义了缓存目录的层次结构,keys_zone定义了共享内存区域的名称和大小,用于存储缓存键表,而max_size则限制了缓存的最大大小。 - proxy_cache:此参数设置使用哪个缓存。参数值应该与
proxy_cache_path中定义的keys_zone相同。 - proxy_cache_valid:此参数指定不同HTTP响应状态码的缓存有效期。
- proxy_cache_methods:确定哪种类型的请求会被缓存,默认只缓存GET和HEAD。
- proxy_cache_key:定义了用于存储每个响应的缓存键,如果没有默认设置,通常使用 URL 和 / 或 请求头作为键。
- proxy_cache_use_stale:当错误发生或更新的响应过期时,允许发送"陈旧"的响应给客户端,默认情况下是关闭的。
- proxy_cache_background_update:此指令告诉Nginx在后台异步更新缓存项,当缓存项即将过期时,此指令可以确保客户端总是从缓存中获取响应,而不必等待新的响应,默认情况下是关闭的。
- proxy_cache_lock:当多个相同请求同时达到时,只允许一个请求更新缓存,其他请求将等待直到缓存更新完成,默认情况下是关闭的。
结合上面参数,示例配置如下:
http {
proxy_cache_path /var/nginx/cache levels=1:2 keys_zone=my_cache:10m max_size=1g inactive=60m use_temp_path=off;
server {
location / {
proxy_cache my_cache;
proxy_pass http://my_upstream;
proxy_cache_key "$scheme$request_method$host$request_uri";
proxy_cache_methods GET HEAD POST;
proxy_cache_valid 200 302 10m;
proxy_cache_valid 404 1m;
proxy_cache_use_stale error timeout updating http_500 http_502 http_503 http_504;
proxy_cache_background_update on;
proxy_cache_lock on;
}
}
}这段配置会对通过反向代理的GET、HEAD和POST请求进行缓存,并设置了各种状态码的缓存有效时间。它还启用了在后台异步更新缓存项的功能,以及在有多个相同请求时防止缓存雪崩的锁机制。
CDN缓存
CDN,也就是内容分发网络(Content Delivery Network),它将网站的内容缓存在全球范围内的服务器上。当用户访问网站时,CDN会选择与用户最近的服务器提供服务,从而减少延迟,加快加载速度。
CDN一般会对静态内容进行缓存,如HTML页面,CSS样式表,Javascript脚本,图片和视频等,因为这些文件类型的内容在给定的时间内变化不大。
关于如何设置CDN,这通常涉及以下步骤:
- 选择一个CDN服务提供商:根据你的需求,比如地域覆盖、价格、特性等来选择一个合适的CDN提供商。
- 注册和购买CDN服务:在选定的CDN服务提供商那里注册账户,并购买CDN服务。
- 配置CDN:根据提供商的指导配置CDN,通常包括指定你的原始服务器(origin server)以及哪些内容需要通过CDN来分发。
- 更新DNS记录:将你的网站域名的DNS记录指向CDN提供商。这样,当用户访问你的网站时,他们会被重定向到最近的CDN边缘节点。
至于CDN缓存如何生效,一般是这样的:
- 用户请求一个网页或其他资源(如图像、视频、CSS或JS文件等)。
- 如果这个请求的资源已经在CDN的边缘节点被缓存了,那么CDN会直接将此资源提供给用户,这样就大大减少了响应时间。
- 如果请求的资源没有在CDN节点被缓存,那么CDN会向原始服务器请求该资源,然后将它提供给用户,并在本地边缘节点上存储一份副本,以便下次有用户请求同样的资源时可以直接提供。
CDN服务商通常会提供各种工具和选项来定制你的CDN缓存行为,例如设置某些资源的缓存持续时间(TTL),或者设置某些URL路径不使用缓存等。
堆缓存
Java堆内存也可以用来存储缓存对象。
相比较分布式缓存,使用堆缓存最大的好处就是没有序列化/反序列化的成本。当然缺点也很明显,当缓存的数据量很大时,GC(垃圾回收)暂停时间会变长,存储容量受限于堆空间大小,并且堆缓存无法被多个进程或者多个节点共享。
堆缓存一般用来存储访问频率很高的少量数据,一般通过软引用/弱引用来存储缓存对象,即当堆内存不足时,可以强制回收这部分内存释放堆内存空间。
堆缓存的实现可以非常简单,下面是一段简单的Java堆缓存(Heap Cache)代码示例。在这个例子中,我们将使用Java内置的 LinkedHashMap 类实现一个简单的LRU(最近最少使用)缓存:
import java.util.LinkedHashMap;
import java.util.Map;
public class HeapCache extends LinkedHashMap {
private static final long serialVersionUID = -842570167583755019L;
private final int capacity;
public HeapCache(int capacity) {
super(capacity, 0.75F, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > capacity;
}
public static void main(String[] args) {
HeapCache cache = new HeapCache<>(2);
cache.put(1, "a");
cache.put(2, "b");
cache.get(1); // 访问元素使其变为最新
cache.put(3, "c"); // 这会使得键为2的元素被移除,因为它是最近最少使用的
System.out.println(cache.keySet()); // 输出应为 [1, 3]
}
} 除了JDK自带的类,我们还可以借助一些框架来实现堆缓存。其中,Caffeine Cache是极为推荐的选择。关于如何集成Caffeine Cache的具体信息,可以参阅我之前的文章:本地缓存无冕之王Caffeine Cache。
分布式缓存
分布式缓存相比于本地缓存有以下几个主要优点:
- 可共享:分布式缓存可以被多个进程或服务共享,这是本地缓存无法做到的。
- 可扩展性:分布式缓存可以很容易地添加更多的节点到系统中,以增加总体的缓存容量。这对于需要处理大量数据的应用是非常重要的。
- 容错性:如果单个节点失败,那么该节点上的缓存数据可以从其他节点复制或重新计算。因此,分布式缓存可以提供比本地缓存更高的可用性和数据持久性。
当提及分布式缓存,相信大家会首先想到Redis。这里简单介绍下如何使用Redisson客户端在Java中操作Redis。
首先,我们需要在项目的pom.xml文件中添加Redisson的依赖:
org.redisson
redisson
最新版本
下一步,我们创建一个Java类用来连接到Redis服务器并执行一些操作:
import org.redisson.Redisson;
import org.redisson.api.RBucket;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonExample {
public static void main(String[] args) {
// 创建配置对象
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
// 根据配置,创建RedissonClient实例
RedissonClient redissonClient = Redisson.create(config);
// 获取bucket对象,并将其设置为"Hello, Redisson"
RBucket bucket = redissonClient.getBucket("exampleBucket");
bucket.set("Hello, Redisson");
// 确认设置成功
System.out.println(bucket.get());
// 关闭RedissonClient连接
redissonClient.shutdown();
}
} 网上关于Redis的文章众多,这里只做下简单介绍,不多赘述。
数据库缓存
MySQL查询缓存是一个可选的特性,它可以保存数据库查询结果,当相同的查询再次发生时,直接从缓存中返回结果,减少了数据检索的时间。
然而,要注意的是,查询缓存对于经常更新的数据库可能不适用,因为每次表的数据更改时,所有针对该表的查询都需要从缓存中删除。
以下是如何开启和配置MySQL查询缓存:
在MySQL服务器配置文件(my.cnf或my.ini)中添加或修改如下设置:
[mysqld] query_cache_size = 26214400 query_cache_type = ON其中
query_cache_size设置缓存大小(单位:字节),query_cache_type设置为ON来启用查询缓存。- 重启MySQL服务以应用更改。
当查询缓存被启用和配置后,MySQL会自动缓存查询结果,无需手动干预。
在MySQL 5.7及其之前的版本中,查询缓存是默认开启的。但在MySQL 8.0及后续版本中已经被移除,取而代之的是性能模式(Performance Schema)和信息模式(Information Schema)。
优点:
- 对于静态或者很少更新的表,查询缓存可以显著提高查询性能。
- 对于有大量重复查询的场景,例如网站页面渲染,查询缓存能够减少数据库压力。
缺点:
- 对于频繁更新的表,查询缓存可能导致性能下降。每次表数据更改时,针对该表的所有缓存查询结果都需要被清除。
- 查询缓存占用了一定的内存资源。
MySQL的查询缓存在某些情况下可以显著提高数据库性能,但也有可能成为性能瓶颈。
在启用查询缓存前,首先明确是否真正需要它。如果你的数据库更多地进行读取操作而不是写入,且大部分查询重复率高,查询缓存可能会有所帮助。如果你的数据库经常进行写入操作,查询缓存可能会导致性能下降,因为每次数据变化都需要清除或者更新缓存。
多级缓存
以上所述,每种缓存方案都有其优点和局限性,并无绝对的好坏之分。应根据具体的应用场景,选取最适合的缓存策略。
但是我们可以综合多种缓存方案,以达到相对最优的效果,这就是「多级缓存方案」。
实际上,在计算机操作系统中,我们就能看到多级缓存的例子:
操作系统的多级缓存层次通常由以下几个层次组成:
- 寄存器:这是计算机最快的存储区域。它位于CPU内部,并被用于存储即将被处理的数据和指令。
- CPU高速缓存:也称作L1、L2和L3缓存,这些缓存被用于存储CPU可能会频繁使用的数据和指令。L1是最快但容量最小的缓存,然后是L2,最后是L3。
- 主存(RAM):这是计算机的主要内存区域,用于存储正在运行的程序和数据。
- 磁盘缓存:在磁盘和主存之间提供了一层缓存,以加快对磁盘数据的访问。
- 虚拟内存/硬盘:当主存不足时,操作系统会使用硬盘空间作为虚拟内存。
缓存层次依次是:寄存器 -> CPU高速缓存 -> 主存(RAM) -> 磁盘缓存 -> 虚拟内存/硬盘。
每一层都具有不同的速度和容量,更接近CPU的存储设备速度会更快,但容量相对较小。操作系统的任务就是尽可能有效地管理这些层次,以保证最佳性能。
我们可以借鉴这种多级缓存的思想。先来看下多级缓存的架构图:
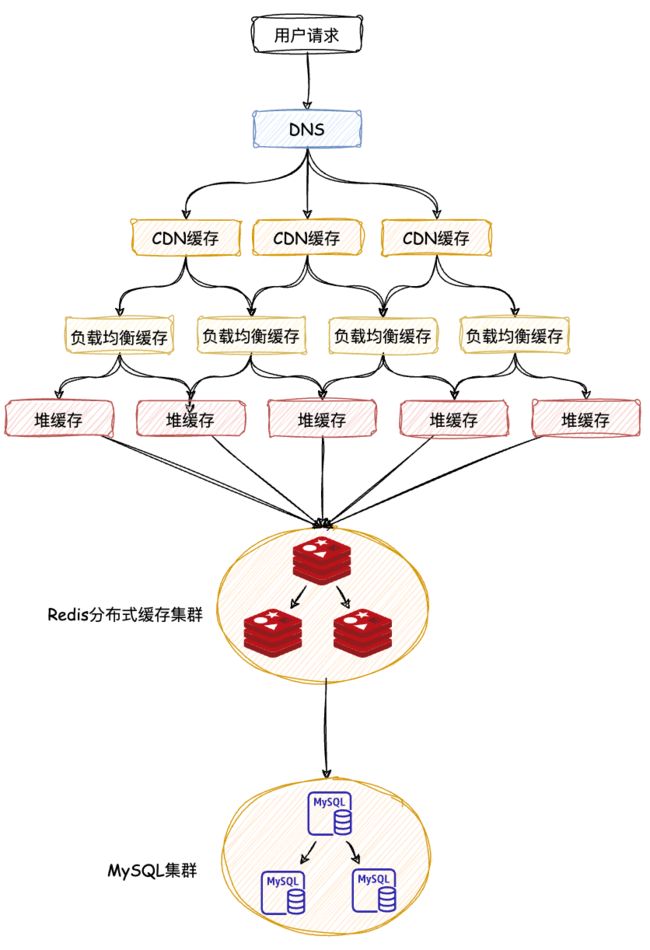
在多级缓存架构中,常见的执行顺序是 CDN 缓存 -> Nginx 缓存 -> Tomcat 堆内缓存 -> Redis 分布式缓存 -> 数据库。
每一层都试图解决来自上一层的负载。如果某一层未能找到请求的数据(缓存未命中),则会将请求传递给下一层。
- CDN 缓存:这是最接近用户的缓存层次,通常用于分发静态资源,如图片、CSS、JavaScript 等。当用户请求这类资源时,首先检查 CDN 是否有缓存。如果 CDN 有,则直接返回;否则,请求传递给下一层。
- Nginx 缓存:Nginx 是反向代理服务器,也可以配置为缓存服务器。如果 CDN 没有命中,请求就到了这里。如果 Nginx 能找到请求的资源,它会发送给用户,并可能更新 CDN。如果 Nginx 也没有,则请求传递给应用服务器。
- Tomcat 堆缓存:Tomcat 可以配置堆内缓存,主要用于频繁访问的动态生成的数据。如果此层缓存没有命中,那么请求将转发到后端的数据服务层。
- Redis 分布式缓存:Redis 是一个高速的键-值数据库,常用作分布式缓存。如果 Tomcat 堆内缓存未命中,请求就会查询 Redis。如果 Redis 有数据,则返回给 Tomcat,并可能将数据载入堆内缓存以备后用。如果 Redis 还是没有找到数据,那么只好访问最后一层——数据库。
- 数据库:数据库是数据的落地存储,也是最可靠的数据源。如果前面所有的缓存层都未能命中,那么请求将直接访问数据库获取数据。然后,这个数据可能会被载入 Redis、Tomcat 堆内缓存,甚至更新 Nginx 和 CDN 缓存,以便下次请求更快地获取数据。
以上就是这种多级缓存架构的执行顺序。要注意的是,每一个缓存层都是为了减少对下一层的负载和提高数据访问速度。但是,为了维持数据的一致性,也需要适当的过期策略和缓存刷新机制。
热点Key自动探测
缓存最重要的指标就是命中率,甚至都没有之一。
而「热点数据」会频繁被访问或使用,是最适合被缓存的数据。
所以,如果说我们能「预测热点数据」,就能最大程度有效地发挥缓存的作用。这在技术层面上也确实是可行的。
我们先来说说热点数据,热点数据其实可以分为:「静态热点数据」 和 「动态热点数据」。
所谓静态热点数据,就是能够提前预测的热点数据。
例如,我们可以通过一次活动卖家报名的方式提前筛选出来,通过报名系统对这些热点商品进行打标。
另外,我们还可以通过大数据提前分析,比如我们可以通过Flink或者离线任务去分析用户历史成交记录、用户的购物车记录,来发现哪些商品可能更热门、更好卖。
这些都是可以提前分析出来的热点,分析出来之后,我们可以提前放入缓存中保护起来,这在技术上是可以实现的。
而所谓动态热点数据,就是不能被提前预测到的,系统在运行过程中临时产生的热点。
例如,抖音的一个热搜,可能导致某个周边相关产品被疯狂抢购,这是人为无法预测的。
所以如何动态预测热点数据就成了我们缓存系统的关键。
这里介绍一种名为「动态热点key探测」的技术,给出其技术架构,希望能给大家提供思路:
- 首先构建一个异步系统,此系统可以异步收集链路上各个环节的应用和中间件的热点Key。如Nginx、Redis、RPC服务框架等这些中间件。可以使用Nginx 的UDP直接上报请求,或者将请求写到本地Kafka,或者使用Flume订阅本地 Nginx日志等方式进行上报。
建立一个热点上报和可以按照需求订阅的热点服务的下发规范。
主要目的是通过链路上各个系统(包括详情、购物车、交易、优惠、库存、物流等)访问的时间差把上游已经发现的热点透传给下游系统,提前做好保护。
比如,对于大促高峰期,详情系统是最早知道的,我们可以通过部署在每台机器上的Agent把日志汇总到聚合和分析集群中,然后把符合一定规则的热点数据进行上报,或者是在统一接入层上使用 Nginx模块统计热点URL。
- 将上游系统和中间件收集的热点数据发送到「实时热点发现系统」,对于热点的统计可以很简单的对访问的商品进行访问计数,然后排序还有就是用通常的队列的淘汰算法如LRU等都可以实现。
实时热点发现系统可以主动推送热点数据到中间件,或者下游系统(如交易系统)按需订阅实时热点发现系统。
你可以是把热点数据填充到Cache中,或者直接推送到应用服务器的内存中,还可以对这些数据进行拦截,总之下游系统可以订阅这些数据,然后根据自己的需求决定如何处理这些数据。
整体架构图大致如下所示:
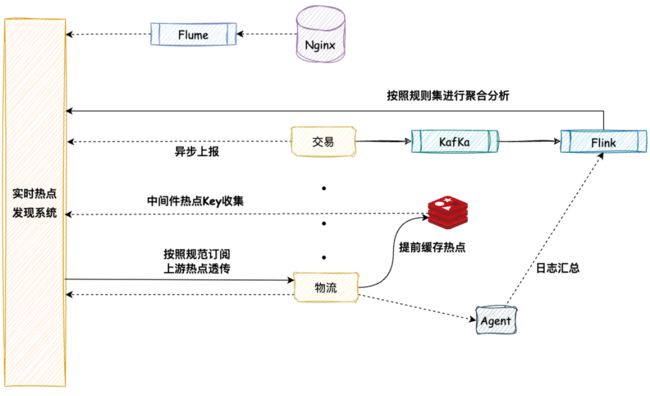
注意:所提供的架构图仅供参考,实现方法多种多样,无需局限于特定的架构设计。
这个系统能够实现的技术前提是「时间差」!。主要依赖前面的导购页面(包括首页、搜索页面、商品详情、购物车等)提前识别哪些商品的访问量高,通过这些系统中的中间件或应用来收集热点数据,并进行记录。
举个例子,按照用户购买行为来说,我们一般网购商品的时候,会打开商品详细页,或者商品评价来看看。这中间就存在时间差,这个时间差实时热点发现系统一直在工作,能够预测用户「接下来可能的行为」,从而预测热点对应用进行保护。
热点发现要做到接近实时(3s内完成热点数据的发现),因为只有做到接近实时,动态发现才有意义,才能实时地对下游系统提供保护。若热点信息在10秒后才发送,其实已失去了意义。因为在这10秒内,用户可以执行多项操作。时间越长,不可控因素增多,导致热点缓存命中率下降。
京东在网上开源了一个热点key探测的具体实现:https://gitee.com/jd-platform-opensource/hotkey,大伙有兴趣可以参考下。
本篇文章,我们讨论了高并发系统设计中缓存的重要性。适当使用缓存可以显著提高系统性能,并且可以抵消由于大量请求造成的负载。
总体来说,缓存是一个强大的工具,但要充分利用它,你需要详细地理解你的应用程序,包括哪些信息被频繁地读取,哪些信息更新的频率较高,以及在特定情况下可能会出现的问题。
同时,记住缓存并不能解决所有问题。在设计高并发系统时,我们还需要考虑数据库优化、负载均衡、分布式系统设计等其他方面。通过全方位地理解和应用这些原则,我们才能创建出稳定、可扩展和高效的高并发系统。
希望这篇文章能为你在处理高并发系统设计问题时提供有价值的参考和启示。当然,每个项目和场景都有其特定的需求和挑战,所以请持续学习和实践,不断改进你的设计策略。
感谢阅读,如果本篇文章有任何错误和建议,欢迎给我留言指正。
老铁们,关注我的微信公众号「Java 随想录」,专注分享Java技术干货,文章持续更新,可以关注公众号第一时间阅读。
一起交流学习,期待与你共同进步!