HTTP协议
HTTP协议

文章目录
- HTTP协议
-
-
- 应用层协议
- 认识URL
- urlencode和urldecode
- 从应用层协议自顶向下看待通信
- HTTP协议格式
- 简单实现http服务器
-
- (打印请求)
- (打印响应)
- 网页版
- 再谈请求和响应格式内容
- 表单
- 提交方法
-
- GET方法和POST方法
- HTTP状态码
- HTTP长连接
- HTTP周边会话保持
- cookie和session id
-
应用层协议

应用层(Application layer)是OSI模型的第七层。应用层直接和应用程序接口并提供常见的网络应用服务。应用层也向表示层发出请求。应用层是开放系统的最高层,是直接为应用进程提供服务的。其作用是在实现多个系统应用进程相互通信的同时,完成一系列业务处理所需的服务。我们程序员写的一个个解决我们实际问题, 满足我们日常需求的网络程序, 都是在应用层。
而学习应用层协议,绕不开http协议和https协议,本文重点介绍http协议。
认识URL
在WWW(万维网)上,每一个信息资源都有统一的且在网上的地址,该地址就叫URL(Uniform Resource Locator,统一资源定位器),它是WWW的统一资源定位标志,就是指网络地址。
- URL由三部分组成:资源类型、存放资源的主机域名、资源文件名。也可认为由4部分组成:协议、主机、端口、路径。
- url的一般格式为
protocol :// hostname[:port] / path / [:parameters][?query]#fragment
例如:
http://user:[email protected]:80/filder/index.html?uid=1#ch1

| protocol(协议) | 最常用的是HTTP协议 |
|---|---|
| hostname (主机名) | 是指存放资源的服务器的域名系统(DNS) 主机名或 IP 地址 。有时,在主机名前也可以包含连接到服务器所需的用户名和密码(格式:username:password@hostname)。 |
| port(端口号) | 整数,可选,省略时使用方案的默认端口,各种传输协议都有默认的端口号,如http的默认端口为80,https默认端口为443。 |
| parameters(参数) | 这是用于指定特殊参数的可选项,有服务器端程序自行解释。例如带层次的文件路径,标识网络资源(文件、视频、图片) |
| query(查询) | 可选,用于给动态网页(如使用CGI、ISAPI、PHP/JSP/ASP/ASP.NET等技术制作的网页)传递参数,可有多个参数,用“&”符号隔开,每个参数的名和值用“=”符号隔开。 |
| fragment(片断标识符) | 字符串,用于指定网络资源中的片段。例如一个网页中有多个名词解释,可使用fragment直接定位到某一名词解释。 |
- 说明一下:一般格式中带方括号的为可选项
urlencode和urldecode
url中不乏有像/ ? :等这样的字符,而这些字符在url中被解释为特殊含义。例如
| + | 表示空格 |
|---|---|
| / | 分隔目录和子目录 |
| ? | 分隔实际和URL和参数 |
| # | 表示书签 |
| & | URL中指定的参数间的分隔符 |
| = | URL中指定的参数的值 |
那么在参数中若存在这些特殊字符就需要对其转义
转义的规则:
- Url编码默认使用的字符集是US-ASCII。
- urlencode:对字符串中除了 -_. 之外的所有非字母数字字符都将被替换成百分号(%)后跟两位 十六进制数,空格则编码为加号(+),形式为%XY。
- urldecode:对参数值进行编码。即将%XY的形式转换回对应的非字母数字字符。
US-ASCII码表
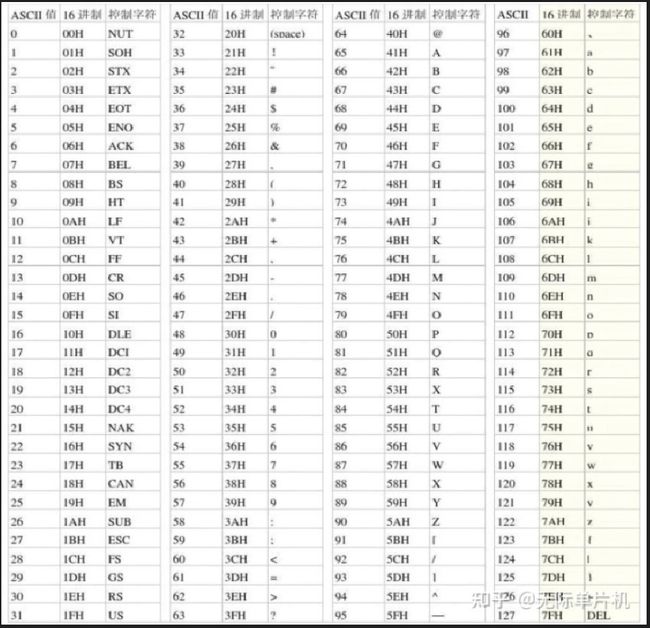
例如:
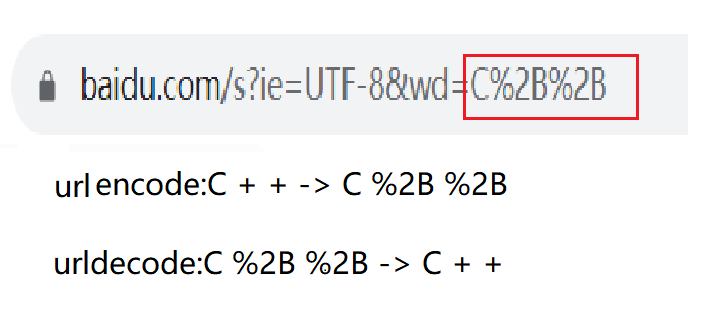
- C++字符串填充到url中,需要对C++中的特殊字符进行urlencode处理。+号对应的US-ASCII码是43,该码为十进制,需要将其转换为形如%XY的16进制。因此C++对应的url为C%2B%2B。
因此,网络上也有很多工具可以将你输入的字符转换为url转换工具
从应用层协议自顶向下看待通信
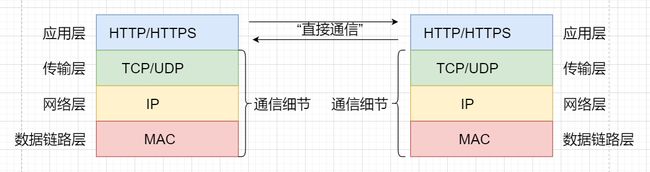
- 常见应用层协议有HTTP/HTTPS,常见传输层协议有TCP/UDP,常见网络层协议有IP,常见数据链路层有MAC。
- 在进行通信时,我们主要在应用层完成HTTP/HTTPS协议的内容传输,而通信那头拿到的也是HTTP/HTTPS的传输内容,因此可以看似在应用层通过HTTP/HTTPS“直接通信”。
- 下三层负责通信细节,而下三层是由操作系统或驱动帮我们完成,因此站在应用层上看,是应用层与对方应用层进行”直接通信“。
- HTTP是基于请求和响应的应用层服务,客户端发送request給服务器,服务器收到后对数据进行处理,然后发送response給客户端,即这种方式就完成了一次HTTP请求。因此学习基于HTTP对应的请求格式和响应格式是学习HTTP的重点。
HTTP协议格式
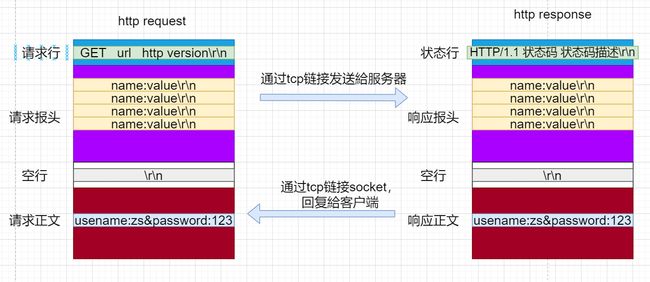
请求格式
- 一个请求中包含请求行、请求报头、空行和请求正文。
- 请求行中通常以
请求方法 url HTTP版本\r\n的形式存在。 - 请求报头中包含了请求的属性。每条属性以
key:value键值对的方式存在,每条属性之间以\r\n分隔。请求报头遇到空行部分结束。 - 请求正文在空行后面,请求正文允许为空字符串,若请求正文存在,那么在请求报头中会有一条请求属性
Context-length来标识请求正文的长度。
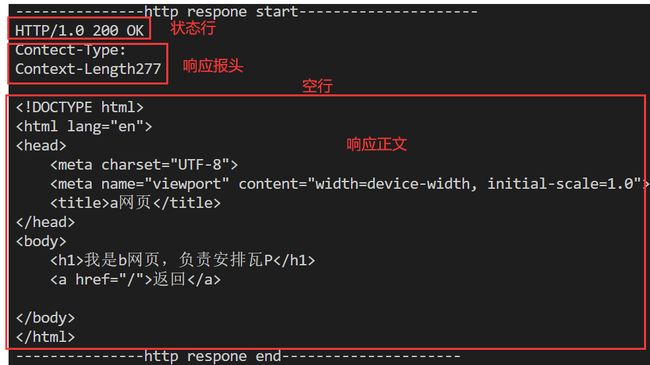
响应格式
- 一个响应包含状态行、响应报头、空行、响应正文。
- **状态码是指用以表示网页服务器超文本传输协议响应状态的3位数字代码。**其中有1XX,2XX,3XX,4XX等等。常见的有200(OK)表示请求已成功,302(Move Temporarily)表示临时重定向,404(not found)表示请求失败,请求所希望得到的资源未被在服务器上发现。
- 状态行中通常以
HTTP版本号 状态码 状态码描述\r\n的形式存在 - 响应报头中包含了响应的属性。每条属性以
key:value键值对的方式存在,每条属性之间以\r\n分隔。响应报头遇到空行部分结束。 - 响应正文在空行后面,响应正文允许为空字符串,若响应正文存在,那么在响应报头中会有一条响应属性
Context-length来标识响应正文的长度。
一个完整的HTTP请求
在应用层中,客户端自上向下交付request給传输层,即通过tcp链接发送給服务器。因为下三层的的通信细节由操作系统完成,因此我们不需要太过关心。在这里需要知道的是客户端将request交付給传输层,传输层通过TCP链接发送給服务器。服务器从传输层中读取request到应用层。对数据做完处理后生成一个response,然后也是以自上向下交付的形式交给传输层。传输层通过TCP链接发送給客户端,客户端将response从传输层读取到应用层。这样就完成了一次HTTP请求。
基于以上的请求格式和响应格式,如何保证能够读到完整的报文?
- 在空行之前,请求行和请求报头的内容都是以
字符串\r\n的结构存在,因此只需要按行读取,直至读到空行,就能将请求行和请求报头读完。 - 若请求正文存在,那么在请求报头中会有一条请求属性
Context-length来标识请求正文的长度。因此按照该属性向空行后读相应大小的正文即可把请求正文读完。
基于以上的请求格式和响应格式,如何实现序列化和反序列化。
再看序列化定义:序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
- 字符串本身就能够充当存储和传输的形式,以
\r\n为间隔标识的字符串,就能够在写入和读取中进行传输。而正文除了有一条属性Context-length标识外,正文通常是文件、图片、视频、音频等二进制的方式存在,因此只需要标定正文长度能够读取完整即可。
简单实现http服务器
(打印请求)
该程序仅仅实现客户端向服务器发送请求,然后再服务器端将该请求进行打印,并没有实现响应功能。
httpserver.cc
#include- 外部传参回调函数Get和端口号給httpserver对象
httpserer.hpp
#pragma once
#include - 创建套接字,绑定端口号和ip,设置套接字为监听模式,获取可以与客户端通信的sockfd。
- 收到请求后,创建子进程,创建孙子进程,回收子进程,孙子进程被OS领养,让孙子进程去调用HandlerHttp函数。这样的好处在于该进程的运行不受命令行解释器的影响(服务器的特点),让孙子进程作为守护进程一直运行,直到进程内部程序结束让OS回收。
- HandlerHttp函数的作用是读取客户端发来的请求,将读到的报文用来设置HttpRequest对象的_inbuffer成员,然后将该对象和HttpResponse对象作为参数发送給外部的回调函数。
- 回调函数Get对HttpRequest对象的_inbuffer成员进行打印。
protocol.hpp
#pragma once
#include- 该文件用来声明和实现HttpRequest类和HttpResponse类,即完成了请求协议的载体和响应协议的载体。
将云服务器的公网ip和端口号在浏览器上以公网ip:端口号的形式进行连接,云服务器就能收到浏览器发来的请求
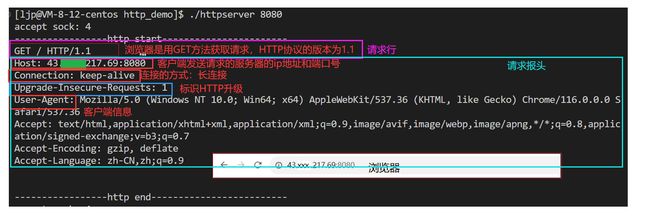
- 可以看到,客户端不只是发送了一次请求給服务器,其原因在于服务器没有发送响应給客户端,浏览器认为服务器没有收到请求而不断的发送HTTP请求。虽然我们使用浏览器只访问了一次服务器,浏览器发送了很多条请求給服务器。
- 收到的请求中可以看到收到了请求行和请求报头。在请求行中,可以看到url是
/。url当中的/不能称之为我们云服务器上根目录,这个/表示的是web根目录,这个web根目录可以是你的机器上的任何一个目录,这个是可以自己指定的,不一定就是Linux的根目录。
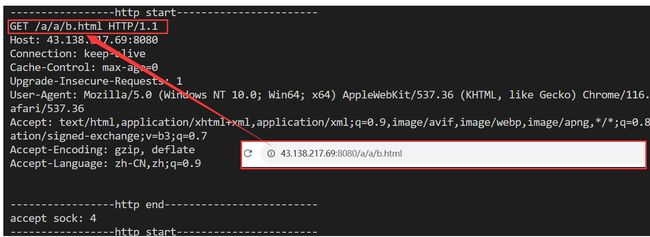
- 当浏览器要访问指定路径底下的文件时,HTTP会将该路径保存在url中,然后会在客户端发送来的请求行中存在。
- HTTP是基于请求和响应的应用层服务,一般情况下是客户端发送请求給服务器,然后服务器才发送响应給客户端。这种基于request&response这样的工作方式,我们称之为cs或bs模式,其中c表示client,s表示server,b表示browser。然而会存在一种版本差问题,客户端此时的版本为1.0,而服务要求的版本为1.2,客户端此时不想升级版本,因此客户端向服务器发送的请求中就需要有对应的属性标识其版本,服务器根据请求报头中的版本属性让不同版本的客户端享受不同的服务。而服务端想要客户端对其版本进行升级,因此服务器也需要对客户端发送版本属性。因此在HTTP请求中,客户端和服务器会互换bs通信双方的协议版本。
(打印响应)
客户端发送请求給服务器,在服务器打印请求的基础上,服务器发送相应的相应給客户端。
httpserver.cc
#include for test hello world
第二把都不起 翻了就被翻了呗 第三把都能拉满,再输连败奖励也能叠满。第二局赢了更是血赚。?
\r\n";//响应正文
//将响应的内容添加到HttpResponse类的对象的成员中
rep._outbuffer+=respline;
rep._outbuffer+=respheader;
rep._outbuffer+=respblank;
rep._outbuffer+=body;
cout<<"---------------http respone start---------------------"<<endl;
cout<<rep._outbuffer<<endl;//打印响应
cout<<"---------------http respone end---------------------"<<endl;
return true;
}
int main(int args, char *argv[])
{
if (args != 2)
{
Usage(argv[0]);
exit(0);
}
uint16_t port = atoi(argv[1]);
unique_ptr<httpserver> hs(new httpserver(Get, port));
hs->inithttpserver();
hs->start();
return 0;
}
- 除了打印请求外,还打印了自定义响应。
httpserver.hpp
#pragma once
#include - HandlerHttp函数中,读取到客户端发送来的请求,将給请求设置进req对象的成员中,然后调用parse函数用req对象去构造rep对象
- 最后将rep对象的成员_outbuffer作为响应发送給客户端。
protocol.hpp
#pragma once
#include- 从_inbuffer中通过分割符
\r\n取到请求的请求行,然后以空格作为分隔符填充 _method(方法) 、 _url(url)、 _httpversion(版本)
Until.hpp
#pragma once
#include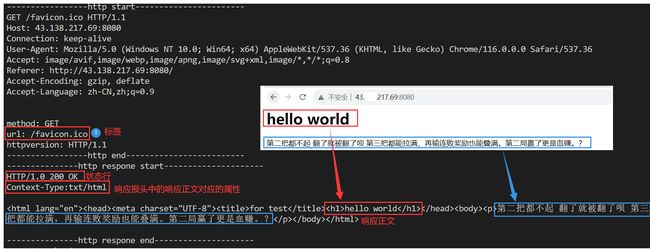
- 通过查知道客户都会向服务器发送多个请求,其中会出现url是/favicon.ico的的情况。该favicon.ico是图标,是互联网产品的标识,类似百度的图标。在打开百度是不止会呈现百度的搜索框等还有图标。

- 按照响应协议格式将响应打印,并且浏览器也能收到服务器发送的响应。该响应是一个html网页,网页的内容是直接存在于响应正文中。
网页版
scc、hpp、p 、u
httpserver.cc
#include - 在Get函数中,不仅打印了客户端发来的请求,还打印了服务器发送回去的响应。
- 发送回去的响应结构服从
响应行,响应报头,响应空行,响应正文形式。在响应报头中,包含了响应正文的类型和长度。注意的是,响应正文的长度定义在protocol.hpp文件的HttpRequest类中,若在响应报头中填充了响应正文的长度,就需要获取实际正文的大小,否则浏览器会做出不一样的行为。例如浏览器会执行默认动作为下载文件。 - suffixtodos函数的作用为,传入在req对象中定义好的文件类型后缀,返回在HTML对应的文件类型后缀,方便客户端做解析。
- 在响应报头中定义了正文的大小,就应该去获取大小并填充进报头中,否则浏览器会对响应做出的默认动作为下载文件。
- referer:客户端发送请求时,客户端所在的页面
protocol.hpp
#pragma once
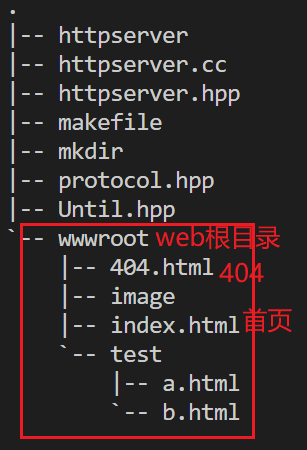
#include- 在当前路径下我创建了一个
wwwroot的目录作为web根目录,由于url自动給web根目录后加\,因此定义该目录时不需要加\。 - 如果客户端发送请求并没有要求请求指定资源,即客户端申请的是web根目录,那么响应会返回一个首页(
home_page),homepage是一个.html文件。 - 另外客户端申请的资源是非法的或服务端所不存在的,那么服务器会返回web根目录底下的404.html文件。即返回状态码404。
- 另外在web根目录底下有一个test目录,里面有一个a.html文件和一个b.html文件,这两个文件充当网页跳转的作用。
- stat函数
stat函数是用于获取文件或目录的元数据信息的系统调用函数。通过提供文件或目录的路径,stat函数将获取到的信息填充到struct stat结构体中。函数原型
#include#include #include int stat(const char *path, struct stat *buf);
-
path:要获取信息的文件或目录的路径字符串。buf:一个指向struct stat结构体的指针,用于存储获取到的元数据信息。- 通常需要先定义一个stat结构体,然后通过stat函数传参要获取信息的文件路径的字符串和指向该结构体的指针,stat函数会将获取到的信息填充到stat指针指向的结构体中。
Until.hpp
#pragma once
#include- readFile函数的作用是:在
httpserver.cc中传入文件所在的路径,以二进制的方式将指定路径的指定文件读取到out参数中。
index.html
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>网站的首页title>
head>
<body>
<h1>我是网站的首页h1>
<img src="https://non1.oss-cn-guangzhou.aliyuncs.com/write1/202309152048396.png" alt="头像">
<a href="https://www.baidu.com/index.htm">百度一下a>
<a href="https://www.bilibili.com/">哔哩哔哩a>
<a href="https://www.csdn.net/">csdna>
<a href="/test/b.html">无畏契约启动a>
<a href="/test/a.html">原神启动a>
<form action="/a/b/c.py" method="GET">
姓名:<br>
<input type="text" name="xname">
<br>
密码:<br>
<input type="password" name="ypwd">
<br><br>
<input type="submit" value="登陆">
form>
body>
html>
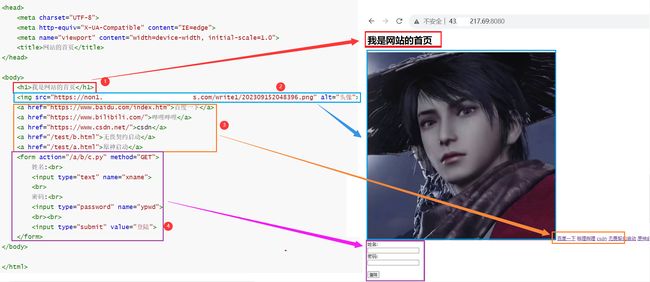
- 第一部分是一级标题,通常显示在网页的最上方。
- 第二部分是显示的图片,这里是以外链的形式存在。
- 第三部分是实现了一个网页跳转的功能,在这里可以跳转到百度,哔哩哔哩、csdn,以及web根目录底下的test目录的b.html和a.html文件。
- 第三部分是表单,表单实现了一个输入账号和密码的功能。注意:网页功能属于HTML知识范畴。
- 因此可以看到一个网页的内容不止有描述性文字,还有图片,文件,表单等。在客户端发送请求給服务器时,往往会发送许多次,其原因在于一个网页由网页本身和所携带的资源构成,客户端需要发送多次请求,来获取到一整个网页。
再谈请求和响应格式内容
请求

User-Agent是客户端的相关信息。Accept是客户端可以接收的响应文件类型。Referer是客户端在发送请求时,所处在的当前网页对应的web端的文件路径。路径前是ip和端口号
响应
表单
HTML 表单用于搜集不同类型的用户输入。
- 表单的格式
<form>
.
form elements
.
form>
- 在两个form之间有表单元素,表单元素指的是不同类型的 input 元素、复选框、单选按钮、提交按钮等等。表单元素通常以键值对
key:value的方式存在。
例如
| 类型 | 描述 |
|---|---|
| text | 定义常规文本输入。 |
| password | 定义密码输入。 |
| submit | 定义提交按钮(提交表单)。 |

-
在网页中打开开发者工具查看,有一个表单用于输入账号和密码。账号的key是text,其对应的值为xname,该值由用户输入。密码的key为password,其对应的值为ypwd,该值由用户输入。登录按钮的key为submit,其对应的值为登陆,用户点击后提交表单。
-
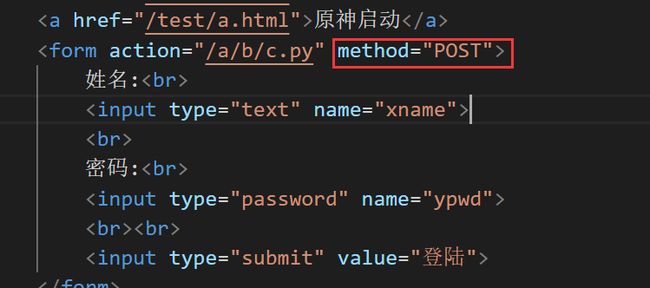
在表单是上面可以看到形如
的代码。其action为该表单提交到对应路径的的文件中,这里是/a/b/c.pymethod为提交的方法,这里用的是GET方法。在后期可以在表单提交对应的文件中取到表单进行操作。 -
我们在提交数据时,本质上前端会以form表单的形式提交,浏览器会将表单的内容转换为POST或GET方法作为请求发送給服务器。
提交方法
HTTP常见的提交方法有:
| 方法 | 说明 | 支持的HTTP协议版本 |
|---|---|---|
| GET | 获取资源 | 1.0、1.1 |
| POST | 传输实体主体 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| HEAD | 获得报文首部 | 1.0、1.1 |
| DELETE | 删除文件 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONNECT | 要求用隧道协议连接代理 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINE | 断开连接关系 | 1.0 |
其中最常用的是GET方法和POST方法
GET方法和POST方法
GET方法
- 当前网页使用的是GET方法,我进行提交表单后可以看到,网页跳转的网址是
服务器ip:端口/提交表单获取的资源?表单提交的内容。一是提交服务器的ip端口与提交表单对应的路径是以\相连,说明网上的资源多数在Linux上部署。二是提交表单对应的路径与表单提交的内容是以?相连。三是表单的内容之间是以&相连。 - url会以
提交表单所获取的资源?表单提交的内容方式存在。
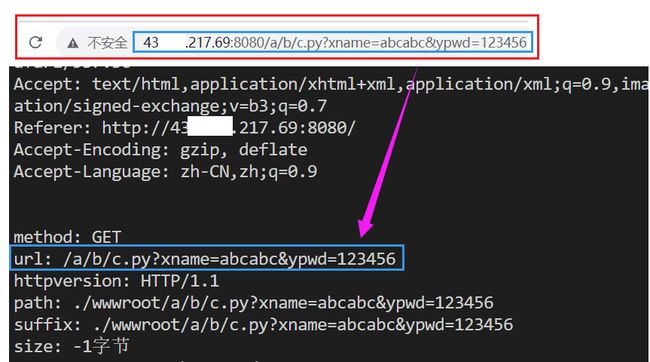
POST方法
现只把index.html中的提交方法改成POST
浏览器连接上后提交表单,可以看到:
- 网页跳转的网址只有获取资源的web地址,后面没有所提交的表单内容。
- url是以
提交表单获取的资源的方式存在。 - 提交表单的内容在方法上单独一行存在。
因此可以知道POST方法并不会呈现表单内容給用户看,相比于GET方法多了一些隐蔽性。

GET方法和POST方法的性质
- GET方法通过url传递参数,POST方法通过请求正文传递参数。
- POST方法通过请求正文提交参数,一般情况下用户看不到,因此POST方法私密性比GET方法更好,但私密性不等同安全性。
- 无论GET方法还是POST方法都是不安全的,HTTP协议是以明文提交,注定协议本身是不安全的,相比之下安全性更高的协议是HTTPS。
- GET方法通过url传递参数,该参数注定不能太大。而POST方法通过请求正文提交,正文可以很大。因此若要上传图片、视频等通常要使用POST方法。
- GET方法的url:
资源路径?提交参数。服务器会以?作为分隔符,拿着?右边的参数传递給?左边的资源路径对应的文件,进行相关操作。而POST方法的提交参数在请求正文中,本身就是于资源路径分离的。
HTTP状态码
HTTP常见的状态码有:
| 类别 | 原因短语 | |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作加以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
最常见的状态码有200(OK),404(Not Found),404(Forbidden),302(Redirect重定向),504(Bad Gateway)。
重定向的基本原理
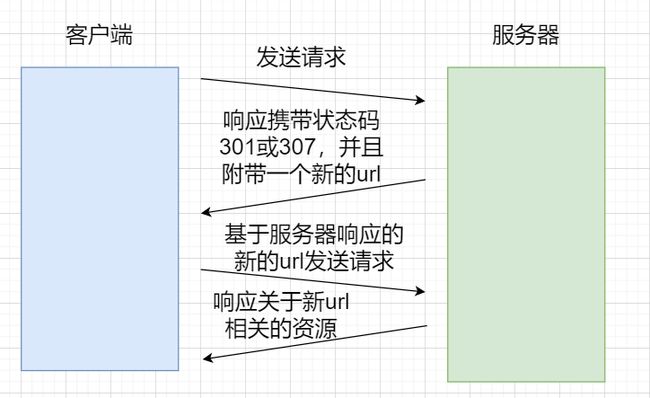
- 客户端对服务器发送请求,获取指定资源。服务器返回相应,相应中有3XX状态码,并携带一个新的url。客户端发送请求,获取新url指定的资源。服务器相应新url下的资源。即客户端获取某个资源,服务器返回了另一个资源,完成了重定向。
重定向有临时重定向和永久重定向。其中状态码301表示的就是永久重定向,而状态码302和307表示的是临时重定向。
临时重定向和永久重定向本质是影响客户端的标签,决定客户端是否需要更新目标地址。如果某个网站是永久重定向,那么第一次访问该网站时由浏览器帮你进行重定向,但后续再访问该网站时就不需要浏览器再进行重定向了,此时你访问的就是重定向后的网站。而如果某个网站是临时重定向,那么每次访问该网站时如果需要进行重定向,都需要浏览器来帮我们完成重定向跳转到目标网站。
重定向演示
httpserver.cc
bool Get(const HttpRequest& req,HttpResponse& rep)
{
cout<<"-----------------http start-----------------------"<<endl;
cout<<req._inbuffer<<endl;
cout<<"method: "<<req._method<<endl;
cout<<"url: "<<req._url<<endl;
cout<<"httpversion: "<<req._httpversion<<endl;
cout<<"path: "<<req._path<<endl;
cout<<"suffix: "<<req._suffix<<endl;
cout<<"size: "<<req._size<<"字节"<<endl;
cout<<"-----------------http end-------------------------"<<endl;
std::string respline = "HTTP/1.0 307 Temporary Redirect\r\n";//临时重定向307
std::string respheader = suffixtodos(req._suffix);
if(req._size>0)
{
respheader +="Context-Length";
respheader +=to_string(req._size);//如果这里給了Context-Length但是没有給实际的size浏览器默认行为是将路径的文件下载下来
//且在响应报头处没有給正文的长度,网页是无法加载的
respheader+="\r\n";
}
respheader += "Location: https://www.bilibili.com/\r\n";//重定向到的网址
std::string respblank = "\r\n";
std::string body;
body.resize(req._size+1);
if(!Until::readFile(req._path,(char*)body.c_str(),req._size))
{
Until::readFile(html_404,(char*)body.c_str(),req._size);
//根据客户端发送来的path字段,对对于的路径读取文件,若所读取的路径不存在文件,那么就将html_404对应的文件填充到body字段中
}
rep._outbuffer+=respline;
rep._outbuffer+=respheader;
rep._outbuffer+=respblank;
rep._outbuffer+=body;
cout<<"---------------http respone start---------------------"<<endl;
cout<<rep._outbuffer<<endl;
cout<<"---------------http respone end---------------------"<<endl;
return true;
}
- 需要更改的地方就只有httpserver.cc中的GET函数,一是将相应的状态码有200(OK)改成307(Temporary Redirect),二是在响应报头中加一条重定向到的网址的属性。
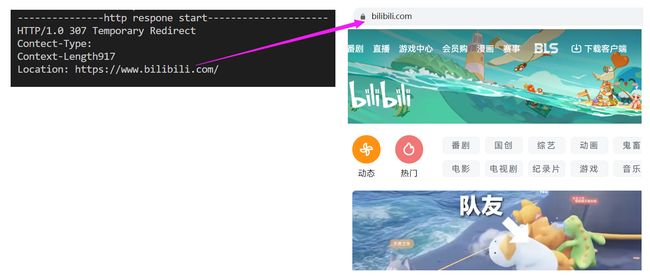
std::string respline = "HTTP/1.0 307 Temporary Redirect\r\n";//临时重定向307
respheader += "Location: https://www.bilibili.com/\r\n";//重定向到的网址
HTTP长连接
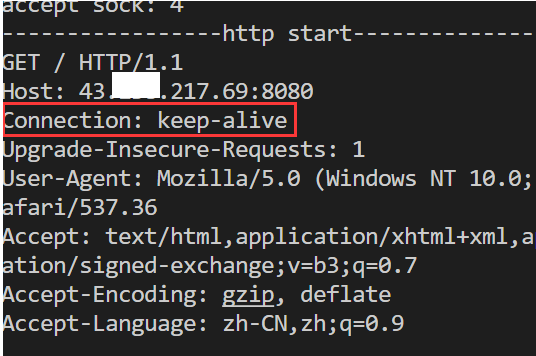
在请求中默认连接方式是keep-alive即默认是长连接。
长连接属性
- http网页有多种元素组成,意味着客户端需要向服务端发送多次请求以获取到足够多的响应,然后浏览器对网页进行组合和渲染才能得到一个完整的网页。而HTTP是基于TCP,那么多次发送HTTP请求就面临着TCP面对连接需要频繁创建连接问题,即需要多次进行三次握手来创建信道,四次挥手断开连接。如果没有长连接,每次请求就需要完成一次三次握手四次挥手。
- 如果有长连接,在一个TCP连接中就可以持续发送多份数据而不会断开连接,即请求可以复用这个信道。
- 但长连接也有缺陷,存在队头阻塞问题。如果仅仅使用一个连接,它需要发送请求,等待响应。之后才能发起下一个请求。在请求应答过程中,若出现状况,剩下的所有工作就会阻塞在这次请求响应中,即所谓的“队头阻塞”问题。它会阻碍网络传输和web页面渲染,直至失去响应。
HTTP周边会话保持
-
HTTP协议本身是无状态的。例如浏览器向服务器发送了三次请求,当前请求无法得知上一次请求了什么,也无法得知下一次会请求到什么,即HTTP协议不做状态记录。若按照HTTP协议的无状态属性,我们在网页上登录账号后,退出当前网页或跳转到其他网页再次点击进入该网页时,浏览器需要向服务器发送请求,那么我们需要再次登录账号。事实是我们在网页登录账号,当退出当前网页后,再次点击该网页也不需要登录了,其原因在于浏览器帮助做了会话保持。
-
浏览器一是会对过去用户查看的视频、图片等做强制缓存处理,下次用户再查看时就从缓存中获取资源,不需要向服务器发送请求。二是浏览器会以某种方式记录用户的账号密码,使得用户再次进入网页时不需要进行登录操作。即HTTP本身是无状态的,但由于用户需要,需要HTTP周边会话保持。
-
而当我们需要访问网址的会员资源时,浏览器会向服务器发送请求,请求中包含用户的信息,服务器会对该信息进行身份认证,若满足会员状态,就将给予当前用户权限去访问会员资源。且用户登录上后,往后用户访问的是同一个网站,浏览器会自动推送历史保留信息。
-
浏览器将用户信息即用户账号和密码保存起来的技术称为cookie。
cookie和session id
浏览器向服务器发送登录请求,服务器响应save文件,浏览器将将用户信息保存到本地形成Cookie文件。往后浏览器向服务器发送请求都需要携带用户信息,每次服务器都需要进行登录操作,才能响应资源。
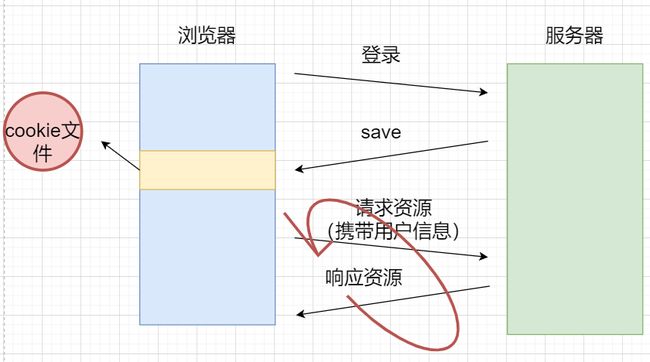
- cookie分为内存级cookie和文件级cookie。浏览器页面本身也是一个进程,在不关闭当前浏览器时,浏览器会记录一些用户信息,该信息属于内存级cookie。而将浏览器关闭后再点开也不会影响的用户信息,该信息属于文件级cookie。
- 若本地的cookie文件内就包含用户的账号和密码,对于非法分子来说是很轻易拿到用户信息然后进行非法操作。只需要拿到浏览器目录下的cookie文件就能拿到用户信息。因此本地的cookie文件不再是用户信息,而是session id。
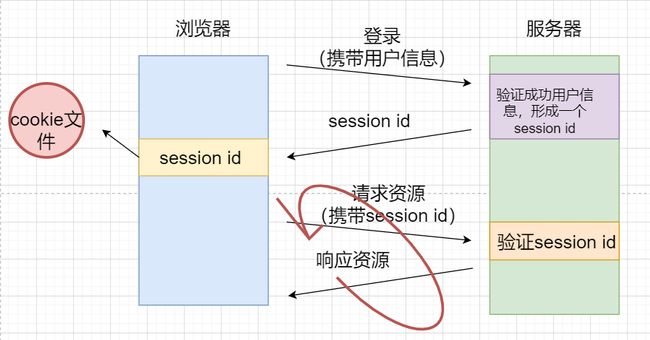
- 浏览器向服务器发送登录请求时,服务器会验证用户信息,然后形成一个session id,该session id全网唯一,服务器响应浏览器session id,浏览器将session id保存到本地形成cookie文件。往后每次向服务器发送请求,都携带session id,服务器拿着session id去验证当前用户信息是否正常,若正常就响应资源。
- cookie文件是session id的优点在于
- 用户信息保存在服务器上而不是本地,用户信息的保存安全问题交给了服务器,即互联网产品厂商,让他们去保护用户信息,用户信息的安全性大大加强了。
- 每次请求资源携带的是session id而不是用户信息,避免被非法分子拦截获取用户信息。
- 非法分子拿到session id,也需要向服务器发送请求才能获取资源,服务器在鉴别session id时会判断当前用户的ip地址等等,若当前账号处于非法状态,服务器立即对用户账号进行封号保护。
当然我们也可以自己设置cookie。在httpserver.cc的Get函数中,在响应报头中携带cookie属性。
httpserver.cc
//......
bool Get(const HttpRequest& req,HttpResponse& rep)
{
//......
respheader+="Set-Cookie: name=1234567abcdefg; Max-Age=120\r\n";
//......
}
