北京小程序开发-微信小程序开发时间总结
一、双线程模型
渲染线程和逻辑线程
小程序的双线程指的就是渲染线程和逻辑线程,这两个线程分别承担UI的渲染和执行 JavaScript 代码的工作
渲染线程使用 Webview 进行 UI 的渲染呈现。Webview 是一个完整的类浏览器运行环境,本身具备运行 JavaScript 的能力,但是小程序并不是将逻辑脚本放到 Webview 中运行,而是将逻辑层独立为一个与 Webview 平行的线程,使用客户端提供的 JavaScript 引擎运行代码,iOS 的JavaScriptCore、安卓是腾讯 X5 内核提供的 JsCore 环境以及 IDE 工具的 nwjs
并且逻辑线程是一个只能够运行 JavaScript 的沙箱环境,不提供 DOM 操作相关的 API,所以不能直接操作 UI,只能够通过 setData 更新数据的方式异步更新 UI
事件驱动的通信方式
你要注意上图渲染线程和逻辑线程之间的通信方式,与 Vue/React 不同的是,小程序的渲染层与逻辑层之间的通信并不是在两者之间直接传递数据或事件,而是由 Native 作为中间媒介进行转发。
整个过程是典型的事件驱动模式:
-
渲染层(也可以称为视图层)通过与用户的交互触发特定的事件 event;
-
然后 event 被传递给逻辑层;
-
逻辑层继而通过一系列的逻辑处理、数据请求、接口调用等行为将加工好的数据 data 传递给渲染层;
-
最后渲染层将 data 渲染为可视化的 UI。
总的来说,跟浏览器的线程模型相比,小程序的双线程模型解决了或者说规避了 Web Worker 堪忧的性能同时又实现了与 Web Worker 相同的线程安全,从性能和安全两个角度实现了提升。可以概括地说,双线程模式是受限于浏览器现有的进程和线程管理模式之下,在小程序这一具体场景之内的一种改进的架构方案。
注意:浏览器中Worker 内的 JavaScript 代码不能操作 DOM,可以将其理解为线程安全的
性能方面
-
在保证功能的前提下尽量使用结构简单的 UI;
-
尽量降低 JavaScript 逻辑的复杂度;
-
尽量减少 setData 的调用频次和携带的数据体量。
二、 小程序的用户体系与 OAuth 规范
微信小程序完整的登录流程
整个登录流程中描述了三种角色和六个术语,了解它们的定位和作用,是理解小程序登录流程的基础。
登录流程里的三个角色
客户端在整个登录流程中主要承担两种行为:
-
作为整个流程的发起者,获取临时登录凭证 code;
-
作为整个流程的终结者,存储登录态令牌 token。
不过客户端的所有信息和网络请求几乎都是可以被破解或拦截的,所以出于安全的考虑,小程序登录流程中的一些接口被限制不能在客户端中直接调用,而是需要在服务端发起,开发者服务的工作便是处理这些安全敏感的网络请求,体现为上图中使用code 获取 openid 和 session_key的请求,这个请求使用了微信提供的 auth.code2Session 接口。
而微信接口服务的工作对于开发者来说是不透明的,你需要做的仅仅是根据接口的规范,组装网络请求发送给它,然后根据返回的接口执行分发逻辑。微信服务器会验证网络请求的合法性,对于合法请求下发密钥 session_key 和用户 openid
登录流程的六个术语
-
code
-
它是在客户端(即小程序)内通过 wx.login API 获取的,然后通过 HTTP 请求发送给开发者服务器。code 的作用体现在“临时”两字上,它的有效期限仅有 5 分钟,并且仅能够使用一次(即请求一次 auth.code2Session 接口)。
-
-
appid
-
每个微信小程序在创建之后(即在微信公众平台注册并初始化完成)便同时生成了一appid,这个 ID 标记了小程序的唯一性,等同于网站的URL(经过备案的)、App 的包名等标记应用唯一性的信息
-
-
appsecret
-
它是小程序的密钥,可以在微信公众平台的后台管理系统中获取。appsecret 是非常私密的信息,所以微信在制定小程序登录的流程时,将携带此信息的网络请求限制在只能通过开发者服务器发送给微信接口服务,这样对于客户端来说是不可见的,进而降低了被泄露的可能性。与appid 不同的是,appsecret 可以被重置,但每次重置之后,历史的 appsecret 便会失效,所以请谨慎操作。
-
-
openid
-
这里你要注意,很多开发者容易走入一个误区: 误将 openid 理解为用户的唯一 ID。这句话如果放在某个小程序的特定语境下是没有问题的,但是如果放在微信生态的全局角度上是错误的。为什么呢?
-
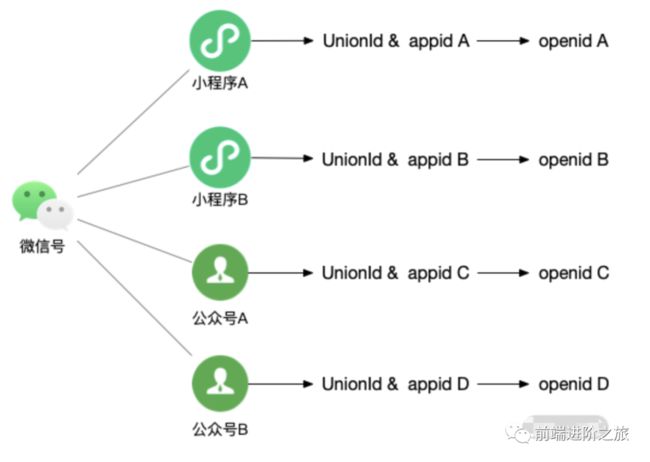
微信对于用户 openid 的定义是:微信号在某个应用程序中的唯一 ID。这里的“某个应用程序”指的是小程序、公众号、接入开放平台的应用。微信生态中目前有公众平台和开放平台两种,其中公众平台又细分为小程序和公众号,开放平台可以接入网站、移动应用等。同一个微信号在不同的应用程序中有不同的 openid。
-
在微信生态下另外有一个标记微信号的唯一 ID:UnionId。这个 ID 跟应用程序无关。所以,可以简单地理解为 UnionId 与 appid 综合加密后的结果,见下图:
-
UnionId 通常用来关联在不同应用程序中各个 openid,比如同一个微信号在小程序和公众号内需要配置同样的权限,仅通过 openid 无法实现,便需要获取此微信号的 UnionId。虽然获取 UnionId 的流程并不在这节课的讨论范围之内,但我相信你在后续工作中一定会遇到处理 UnionId 和 openid 的场景,所以先了解一下没啥坏处
-
-
session_key
-
session_key 是对用户数据进行加密签名的密钥,微信服务器使用它将用户的数据进行加密和解密。你可以简单地将 session_key 理解为获取用户数据的“绿卡”,登录之后所有涉及访问微信服务器的请求一般都需要带上它,微信服务器会校验 session_key 的合法性。
-
其实到这一步(即拿到了 openid 和 session_key)已经完成了小程序的登录流程,但对于一个应用程序来说,用户进行登录操作应该是“一劳永逸”的,即登录过一次之后在一定时间之内的后续操作都不需要再次登录,用技术语言描述就是应该保存用户的登录态。这个时候就需要用到接下来的一个术语:token。
-
- token
{ "token_1": { "openid": "获取到的openid 1", "session_key": "获取到的session_key 1" }, "token_2": { "openid": "获取到的openid 2", "session_key": "获取到的session_key 2" }, }-
关联完成之后开发者服务器将 token下发到客户端,客户端保存在本地,后续的所有请求均需要携带此 token,携带的方法并没有既定的规范,可以通过 URL Query、HTTP Body、Header 等,但通常建议通过 Header 传递,这样相对来说更安全一些。
-
登录态是个逻辑词汇,token 可以理解为登录态的具象化、数据化。在小程序的登录流程图中,你可以看出,token是由开发者服务器创建的一个字符串,而且需要跟 openid 和 session_key 相关联。其实这里并不是强制关联 openid,因为 openid 并不算是私密信息,可以放心地下发到客户端(即小程序)。但是 session_key 是非常私密的信息,一旦泄露有很大的安全隐患,所以强烈建议不要把它下发到客户端。
-
在获取到 openid 和 session_key 之后,开发者服务器创建一个 token,然后与 openid 和session_key 进行关联,具体的方法根据服务器编程语言的不同有多种实现方案。咱们以JavaScript 语言作为示例,可以创建一个对象,对象的 key 是 token 的值,value 是一个包含 openid 和 session_key 的对象,如下:
-
OAuth 2.0 规范中的角色划分
咱们先思考一个问题:小程序登录之后如果需要访问用户的数据(比如昵称、地域、性别等)需要得到谁的授权?是微信?还是用户?
答案是用户。用户的数据虽然存放在微信的服务器之上,但是这些数据的所有权属于用户自己,而不是微信。这里其实引出了 OAuth 2.0 规范中的两个基本概念。
-
Resource Owner:资源所有者,即用户; -
Resource Server:资源服务器,即微信。
而小程序在获取用户数据中的角色是作为微信平台的第三方应用程序,在 OAuth 2.0 规范中的术语为 Third-party application。
三、自定义组件
自定义组件的资源管理
创建微信小程序自定义组件需要使用 Component 构造器,这是微信小程序结构体系内最小粒度的构造器,外层是 Page 构造器,最外层的是 App 构造器,三者的关系如下图:
Component({
behaviors:[],
properties:{},
data: {},
lifetimes: {},
pageLifetimes: {},
methods: {}
});
我们可以对照 Vue 和 React 讲解 Component 构造器的几个属性,这样更容易理解:
-
behaviors类似于 Vue 和 React 中的mixins,用于定义多个组件之间的共享逻辑,可以包含一组 properties、data、lifetimes 和 methods 的定义; -
properties类似于 Vue 和 React 中的 props ,用于接收外层(父组件)传入的数据; -
data 类似于 Vue 中的 data 以及 React 中的 state ,用于描述组件的私用数据(状态);
-
lifetimes 用于定义组件自身的生命周期函数,这种写法是从小程序基础库 2.2.3 版本引入的,原本的写法与 Vue 和 React 类似,都是直接挂载到组件的一级属性上
-
pageLifetimes 是微信小程序自定义组件独创的一套逻辑,用于监听此组件所在页面的生命周期。一般用于在页面特定生命周期时改变组件的状态,比如在页面展示时(show)把组件的状态设置为 A,在页面隐藏时(hide)设置为 B;
-
methods 与 Vue 的 methods 类似,用于定义组件内部的函数
自定义组件的生命周期
组件间的通信流程
与 Vue/React 不同,小程序没有类似 Vuex 或 Redux 数据流管理模块,所以小程序的自定义组件之间的通信流程采用的是比较原始的事件驱动模式,即子组件通过抛出事件将数据传递给父组件,父组件通过 properties 将数据传递给子组件
假设小程序的某个页面中存在两个组件,两个组件均依赖父组件(Page)的部分属性,这部分属性通过 properties 传递给子组件
当组件 A 需要与组件 B 进行通信时,会抛出一个事件通知父组件 Page,父组件接收到事件之后提取事件携带的信息,然后通过 properties 传递给组件 B。这样便完成了子组件之间的消息传递。
除了事件驱动的通信方式以外,小程序还提供了一种更加简单粗暴的方法:父组件通过selectComponent 方法直接获取某个子组件的实例对象,然后就可以访问这个子组件的任何属性和方法了。随后将这个子组件的某个属性通过 properties传递个另外一个子组件。相较而言,事件驱动的方法更加优雅,在流程上也更加可控,所以通常建议使用事件驱动的通信方式。
四、性能优化
微信 IDE 的小程序评分功能位于
调试器-> Audits 面板中
点击“运行”之后,微信 IDE 会对当前的小程序项目进行评测(包括代码层面的检测、通过记录用户交互行为的体验检测)。最终从性能、体验和最佳实践三个维度分别打分以及综合分:
-
性能评分是通过对页面渲染、网络、JS 脚本等方面的评估综合得来的;
-
体验评分是从设计和交互等方面的评估而来,由于设计和交互存在一定的主观因素,所以体验的评分权当建议;
-
最佳实践涉及的方面更宽泛,除了代码编写方面的建议
小程序性能优化的具体维度
微信 IDE 对小程序性能进行评分有以下几个维度
-
避免过大的 WXML 节点数目
-
避免执行脚本的耗时过长的情况
-
避免首屏时间太长的情况
-
避免渲染界面的耗时过长的情况
-
对网络请求做必要的缓存以避免多余的请求
-
所有请求的耗时不应太久
-
避免 setData 的调用过于频繁
-
避免 setData 的数据过大
-
避免短时间内发起太多的图片请求
-
避免短时间内发起太多的请求
1. 避免过大的 WXML 节点数目
WXML 是基于 HTML 的一种 DSL(Domain Specific Language,领域专属语言),除了原生组件(比如 Camera 相机组件)以外,常规组件最终会被小程序的渲染线程通过 WebView 渲染为 HTML ,所以
从性能优化的角度上,HTML 的大部分性能优化方案均适用于 WXML,尽量减少节点数目就是方案之一
节点数目会影响渲染性能,要理解这句话,你要对浏览器的渲染流程有大概了解,来看下面这张图:
HTML 是 XML 的变体,在渲染的时候首先会被浏览器内核解析为 DOM 树,这是一种树形结构,然后会解析每个节点标签的类型、属性等要素,最后与 JavaScript 脚本和 CSS 结合起来进而在经过布局和绘制完成整个渲染流程
理论上 HTML 的节点数目和深度是没有限制的,但是从浏览器的渲染流程中不难看出,DOM 树的结构越复杂,渲染的管线就会越慢
降低节点数目对于性能优化的另外一个原因,是与小程序 /Vue/React 这种 MVVM 框架的 DOM更新机制有关。这类框架在更新 UI 时不直接操作 DOM ,而是使用 VDOM( Virtual DOM,虚拟 DOM )技术来实现,VDOM 的高性能来源于高效的 Diff 算法,在内存中对 VDOM 树结构进行对比后提取差异点再映射到真实 DOM 中。
2. 避免执行脚本的耗时过长
执行脚本的耗时过长对于性能的不良影响主要体现在两个时期:
-
第一是在小程序加载完成后的首次渲染期间;
-
第二是小程序运行过程中的处理用户交互时期。
JavaScript 脚本对小程序首次渲染的影响与浏览器环境下