GC 的三种基本实现方式
开发十年,就只剩下这套Java开发体系了 >>> 
参考资料《代码的未来》(作者: [日] 松本行弘)。
由于并非本人原著(我只是个“搬运工“),SO 未经本人允许请尽情转载。
另外个人像说明一下这里所说的GC指泛指垃圾回收机制,而单指Java或其他某种特定语言中的GC——可能具体语言中实现的垃圾回收实现机制会有所不同。下面是具体内容:
将内存管理,尤其是内存空间的释放实现自动化,这就是GC(Garbage Collection)。
GC其实是个古老的技术,从20世纪60年代就开始研究,还发表了不少论文。这项技术在大学实验室级别的地方已经应用了很长时间,但是可以说从20世纪90年代Java出现之后,一般程序员才有缘基础到它,在此之前这项技术还只是少数人的专利。
术语定义
1,垃圾:
所谓垃圾(Garbage),就是需要回收的对象。作为编写程序的人,是可以做出“这个对象已经不需要了“这样的判断,但是计算机是做不到的。因此如果程序(通过某个变量等等)可能会直接或间接的引用一个对象,那么这个对象就被视为“存活“;与之相反,已经引用不到的则被视为“死亡“。将这些死亡对象找出来,然后作为垃圾进行回收,者就是GC的本质。
2,根
所谓的根(Root),就是判断对象是否被引用的起始点。至于哪里的才是根,不通的语言和编译器都有不通的规定,但基本上是将变量和运行栈空间作为根。
主要GC实现方式:
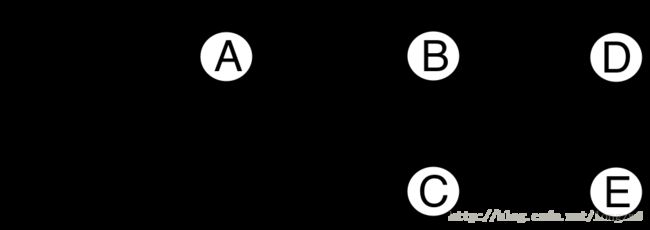
标记清除方式
标记清除(Mark and Sweep)是最早开发出来的GC算法(1960年)。它的原理非常简单:
首先从根开始将可能被引用的对象用递归的方式进行标记,然后将没有标记到的对象作为垃圾进行回收。
初始状态: 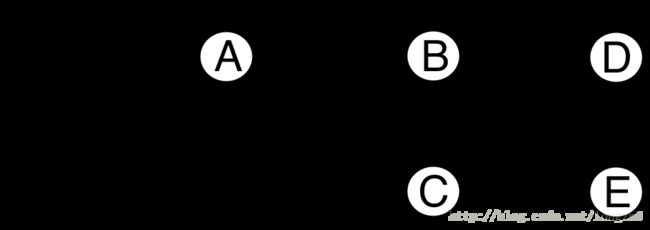
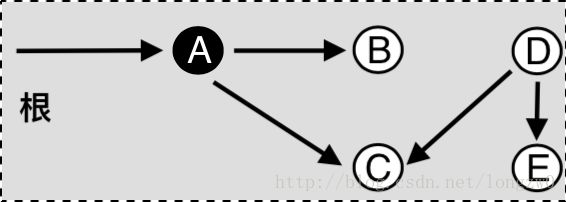
标记阶段:
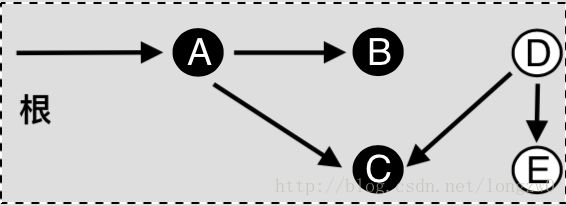
清除阶段:
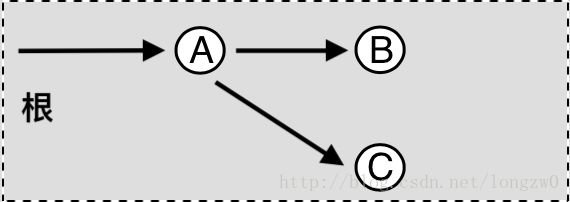
上述图片显示了标记清除算法的大致原理。
“初始状态“图中显示了随着程序的运行而分配出一些对象的状态,一个对象可以对其他的对象进行引用。
“标记阶段“图中显示了GC开始执行,从根开始可以被引用的对象上进行“标记“。大多数情况下,这种标记是通过对象内部的标志(Flag)来实现的。于是,被标记的对象我们将它涂黑。
紧接着被标记的对象所能引用的对象也会被打上标记。重复这一步骤就可以从根开始可能被间接引用到的对象全部打上标记。到此为止的操作即被称为——标记阶段(Mark phase)。标记阶段完成时,被标记的对象就是“存活“对象,反之为“死亡“对象。
标记清除算法的处理时间,是和存活对象数与对象总数的总和相关的。
作为标记清除的变形,还有一种叫做标记压缩(Mark and Compat)的算法,它不是将被标记的对象清除,而是将他们不断压缩。
复制收集方式
标记清除算法有一个缺点,就是在分配了大量对象,并且其中只有一小部分存活的情况下,所消耗的时间会大大超过必要的值,这是应为在清除阶段还需要对大量死亡对象进行扫描。
复制收集(Copy and Collection)则试图克服这一缺点。在这种算法中,会将从根开始被引用的对象复制到另外的空间中,然后,再将复制的对象所能够引用的对象用递归的方式不断复制下去。
初始状态(1)——旧空间:
新空间的开辟(2)——新空间:

复制对象(3)
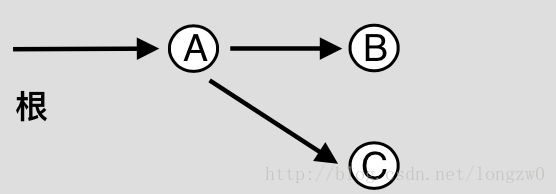
如上图:
(1)部分是GC开始前的内存状态,者也同时代表着对象在内存中所占用的“旧空间“。
图(2)在旧空间以外开辟“新空间“并将可能从根被引用的对象复制到新空间中。
图(3)从已经复制的对象开始再将可以被引用的对象逐个复制到新空间当中……随着复制的进行,直到复制完成——最终“死亡“对象就留在了“旧空间“当中,接着将旧空间废弃掉,这样就可以将“死亡“对象所占用的空间一口气释放出来,而没有必要再次扫描“死亡“对象的必要。而等到下次GC操作是,这次所创建的“新空间“就成为了将来的“旧空间“了。
复制收集方式的过程相当于只存在于标记清除方式中的标记阶段。由于清除阶段中需要对所有对象进行扫描,这样如果在存在大量对象,且其中大量对象已经为“死亡“对象的情况下必然会造成不必要的资源和性能上的开销。
而在复制收集方式中就不存在这样的开销。但是和标记相比,将对象复制一份的开销相对要大,因此在“存活“对象相对比例较高的情况下,反而不利。
复制收集方式的另一个优点是:它具有局部性(Locality)。在复制收集过程中,会按照对象被引用的顺序将对象复制到新空间中。于是,关系较近的对象被放置在距离较近的内存空间中的可能性会提高,这样被称为局部性。局部性高的情况下,内存缓存会更容易有效运作,程序的运行也能够得到提高。
引用计数方式
引用计数方式是GC算法中最简单也最容易实现的一种,它和标记清除方式差不多是同一时间被发明出来的。
它的原理是:在每个对象中保存该对象的引用计数,当引用发生增减时对计数进行更新。
引用计数的增减,一般发生在变量复制,对象内容更新,函数结束(局部变量不在被引用),等时间点。当一个对象的引用计数为0时,则说明它将来不会再被引用,因此可以释放相应的内存空间。
(1) 
(2) 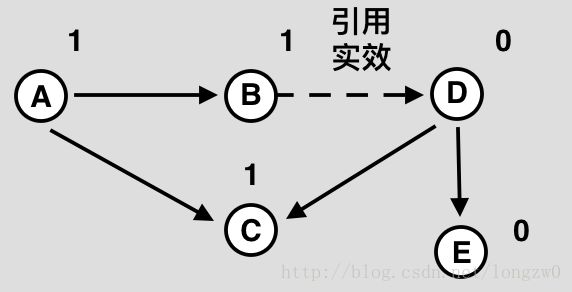
(3) 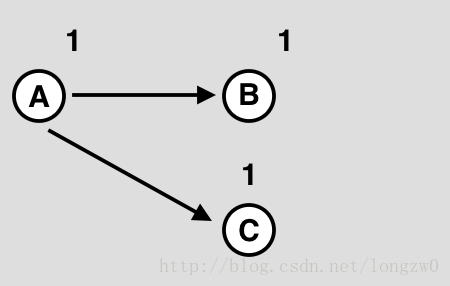
如上图:
(1)中所有对象都保存着自己被多少个对象进行引用的数量(引用计数)——图中右上角的的数字。
(2)当对象引用发生变化时,引用计数也会更者变化。在这里图中的对象B到D的引用实效后,对象D的引用计数变为0,由于对象D的引用计数变为0,因此D到E和C的引用计数也分=别减少。结果E的引用计数也变为0,于是想象E也会被释放。
(3)引用计数为0的对象被释放——“存活”对象被保留下来。而这个GC过程中不需要对所有对象进行扫描。
优点
- 相比标记清除和复制收集方式实现更容易。
- 当对象不再被引用的瞬间就会被释放。
- 其他GC机制中,要预测一个对象何时会被释放是很困难的,而在引用计数方式中则是立即被释放。
- 由于释放操作是针对个别执行的,因此和其他算法相比,由GC而产生的中断时间就比较短。
缺点
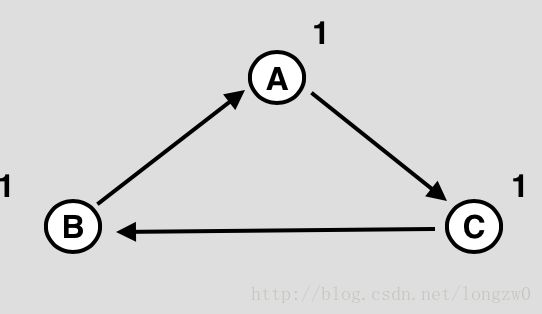
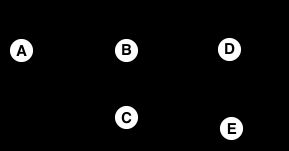
- 无法释放循环引用的对象。如上图A,B,C三个对象没有被其他对象引用,而是互相之间循环引用,因此他们的计数永远不会为0,结果这些对象就永远不会被释放。
- 必须在引用发生增减时对引用计数做出正确的增减,而如果漏掉或者更改了引用计数就会引发很难找到的内存错误。
- 引用计数不适合并行处理。如果多个线程同时对引用计数进行增减的话,引用计数的值就可能会产生不一致的问题(结果就会导致内存错误),为了避免这样的事情发生,对引用计数的操作必须采用独占的方式来进行。如果引用计数操作频繁发生,每次使用都要使用加锁等并发操作其开销也不可小觑。