4.19 python 网络编程和操作系统部分(TCP/UDP/操作系统概念/进程/线程/协程) 学习笔记
文章目录
- 1 网络编程概念
-
- 1)基本概念
- 2)应用-最简单的网络通信
- 2 TCP协议和UDP协议进阶(网络编程)
-
- 1)TCP协议和UDP协议基于socket模块实现
- 2)粘包现象
- 3)文件上传和下载代码
- 4)验证客户端合法性
- 5)socketserver模块 -- 并发的tcp协议server端
- 3 操作系统基础
-
- 1)操作系统历史
- 2)基础并发概念
- 4 进程
-
- 1)进程的三状态图
- 2)进程的调用算法
- 3)进程的开启和关闭
- 4)multiprocessing模块
- 5)进程同步 —— Lock 锁
- 6)进程之间通信 —— 队列
- 7)进程之间的数据共享 —— Manager类
- 5 线程
-
- 1)基本概念
- 2)threading模块开启线程
- 3)线程之间的数据共享
- 4)守护线程
- 5)线程锁
- 6)线程队列
- 7)线程池与进程池
- 6 协程
1 网络编程概念
1)基本概念
-
机器的地址
- mac地址:能够唯一标示你这台机器的
- arp协议(通过ip找mac):地址解析协议,通过一台机器的ip地址获取到他的mac地址,用到了交换机的 广播和单播
- ip地址:能够更好的更方便的找到你的机器
- mac地址:能够唯一标示你这台机器的
-
局域网
- 单个局域网内的机器通信
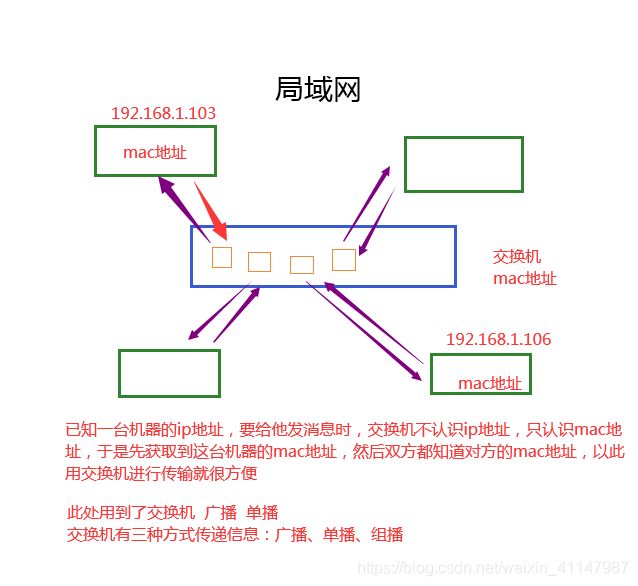
- 网段
- 交换机:只认识mac地址
- 不能理解ip地址,只能理解mac地址
- 多个局域网通信
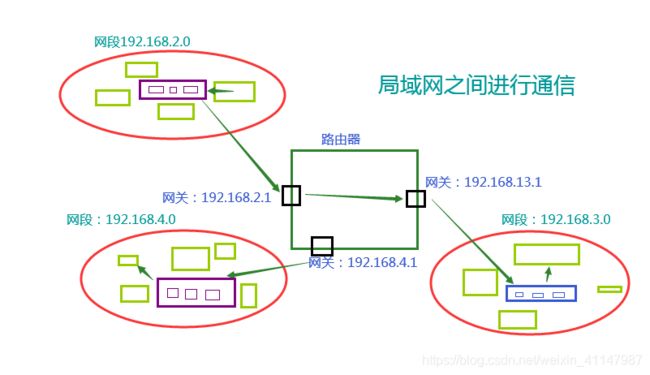
- 网关
- 路由器
- 可以理解ip地址
- 单个局域网内的机器通信
-
ip地址
-
一台机器的临时地址,能够更好更方便的找到你的机器地址
-
ipv4协议:四位点分十进制
- 0.0.0.0-255.255.255.255
-
ipv6协议
- 0:0:0:0:0:0 - FFFFFF:FFFFFF:FFFFFF:FFFFFF:FFFFFF:FFFFFF
-
公网地址:需要我们自己申请购买的地址
-
内网地址:保留字段,下面都是内网地址
- 192.168.0.0-192.168.255.255 学校
- 172.16.0.0-172.31.255.255 学校
- 10.0.0.0-10.255.255.255 公司
-
特殊的ip地址
- 127.0.0.1 本地回环地址(本机地址,不需要过交换机),测试时候用
-
查看自己ip地址指令 ipconfig/ifconfig
-
-
子网掩码
-
也是一个ip地址,用来判断两台机器在不在一个局域网内
-
IP : 192.168.12.1 11000000.00011100.00001111.00000001 子网掩码:255.255.255.0 11111111.11111111.11111111.00000000 进行和运算 11000000.00011100.00001111.00000000 192.168.12.0
-
-
端口 port
- 用来确定一台机器的具体应用
- 虚拟单位,不是实际存在
- 0-65535
- 个人电脑发送请求时操作系统随机分配,服务器端有固定端口
-
osi 7层协议(osi 五层协议是将前三层合并)
- 协议:
- 内容(osi五层协议)
- 应用层(5层)
- python代码
- 传输层
- 预备如何传输,使用的端口port(tcp、udp协议) b’端口+内容’
- 机器:四层路由器–>四层交换机
- 网络层
- 使用的ip(ivp4 ivp6) b’ip+端口+内容’
- 机器:路由器–>三层交换机
- 数据链路层
- 使用的mac地址(arp协议) b’mac地址+ip+端口+内容’
- 机器:网卡–>二层交换机
- 物理层(1层)
- 物理线路
- 接收时刚好相反
- 应用层(5层)
-
tcp 和 udp 协议
-
tcp协议(打电话) - 线下缓存高清电影/qq远程控制/发邮件
-
先建立连接,才能通信
-
占用连接/可靠(消息不丢失)/实时性高/慢
-
建立连接:三次握手
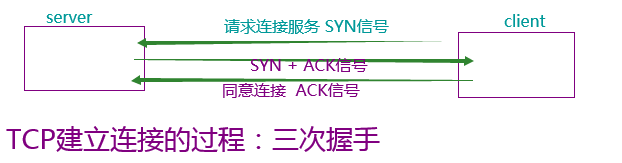
-
连接过程中:收发消息,两次握手

-
断开连接:四次挥手
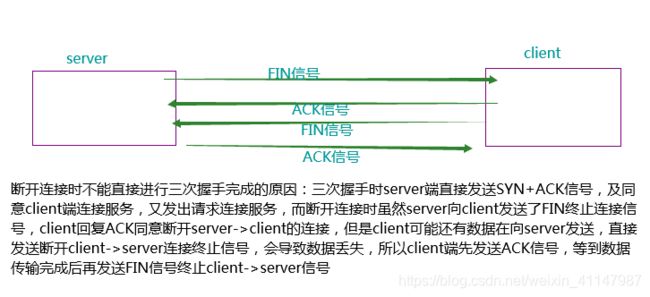
-
-
udp协议(发短信) - 在线播放视频/qq微信消息
- 不需要建立连接,就可以通信
- 不占用连接/不可靠(网络不稳定时会丢失)/实时性底/快
-
2)应用-最简单的网络通信
-
B/S 架构和 C/S 架构
- C/S架构(需要安装)
- client 客户端
- server 服务端
- B/S架构
- browser 浏览器
- server 服务端
- C/S 和 B/S 的关系
- B/S 架构也是 C/S 架构的一种
- C/S 架构的优点
- 可以离线使用
- 功能更完善
- 安全性更高
- B/S 架构的优点
- 不用安装
- 统一PC端用户的入口
- C/S架构(需要安装)
-
socket模块实现简单网络通信测试
# server.py-->服务器端 import socket sk = socket.socket() # 创建一个server端对象 sk.bind(('127.0.0.1', 9000)) # 给server端绑定一个地址 sk.listen() # 开始监听(可以接收)客户端给我的连接了 conn, addr = sk.accept() # 建立连接 conn.send(b'hello') msg = conn.recv(1024) print(msg) conn.close() # 关闭连接 sk.close()
# client.py-->客户端
import socket
sk = socket.socket()
sk.connect(('127.0.0.1', 9000)) # 建立连接
msg = sk.recv(1024) # 接收消息
print(msg)
sk.send(b'byebye') # 传输消息
sk.close() # 断开连接
'''
测试时先打开服务器端,再打开客户端进行连接
'''
2 TCP协议和UDP协议进阶(网络编程)
1)TCP协议和UDP协议基于socket模块实现
-
TCP协议
- 语法:
- socket(type=socket.SOCK_STRAM) tcp协议的server,默认参数可以不用传
- bind() 绑定一个ip和端口
- listen() 监听,代表socket服务的开启
- accept() 等到有客户端来访问和客户端建立连接
- send() 直接通过连接发送消息,不需要写地址
- recv() 只接收消息
- connect() 客户端/tcp协议的方法,和server端建立连接
- close() 关闭服务/连接
- 服务端和多个客户端进行通信
- 服务器端和客户端进行多次通话
- 实例代码如下:
# server.py 服务器端 import socket sk = socket.socket() sk.bind(('127.0.0.1',9001)) # 申请操作系统的资源 sk.listen() while True: # 为了和多个客户端进行握手 conn,addr = sk.accept() # 能够和多个客户端进行握手了 print('conn : ',conn) while True: send_msg = input('>>>') conn.send(send_msg.encode('utf-8')) if send_msg.upper() == 'Q': break msg = conn.recv(1024).decode('utf-8') if msg.upper() == 'Q': break print(msg) conn.close() # 挥手 断开连接 sk.close() # 归还申请的操作系统的资源# client.py 客户端 import socket sk = socket.socket(type = socket.SOCK_STREAM) # stream 数据流 sk.connect(('127.0.0.1',9001)) while True: msg = sk.recv(1024) msg2 = msg.decode('utf-8') if msg2.upper() == 'Q':break print(msg,msg2) send_msg = input('>>>') sk.send(send_msg.encode('utf-8')) if send_msg.upper() == 'Q': break sk.close() - 语法:
-
UDP协议
- 语法:
- socket.socket(type=socket.SOCK_DGRAM) dgram->datagram 数据包
- sendto() 需要写一个对方的地址
- recvfrom() 接收消息和地址
- close() 关闭服务/连接
- 服务器端和客户端进行通信
# server.py 服务器端 import socket sk = socket.socket(type = socket.SOCK_DGRAM) sk.bind(('127.0.0.1',9001)) while True: msg,addr= sk.recvfrom(1024) print(msg.decode('utf-8')) msg = input('>>>') sk.sendto(msg.encode('utf-8'),addr)# client.py 客户端 import socket sk = socket.socket(type=socket.SOCK_DGRAM) server = ('127.0.0.1',9001) while True: msg = input('>>>') if msg.upper() == 'Q':break sk.sendto(msg.encode('utf-8'),server) msg = sk.recv(1024).decode('utf-8') if msg.upper() == 'Q':break print(msg)- 识别不同客户端
- 语法:
2)粘包现象
- 现象:两条或更多条连续发送的消息粘在一起
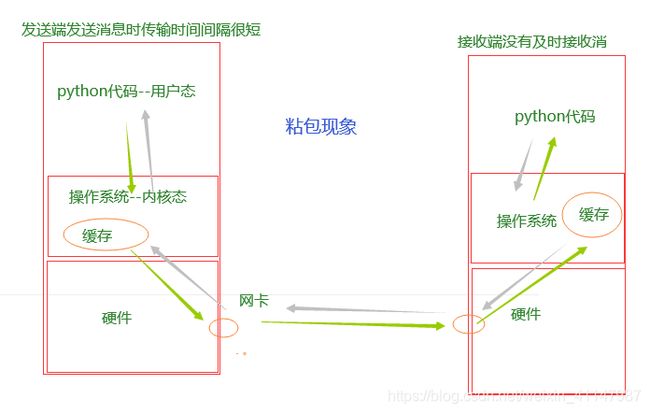
-
粘包发生特点
- 只出现在tcp协议中,因为tcp协议多条消息之间没有边界,并且还有一大堆优化算法
- tcp协议多条消息之间没有边界:因为tcp协议和udp协议传输数据时会有最大带宽限制MKT(一般MKT=1500字节),但是tcp协议可以通过Python更改最大带宽限制,从而一次传输大量数据,但是传输数据时没有边界,导致接收后出现粘包现象
-
原因:
- 发送端发送消息时传输时间间隔很短
- 接收端没有及时接收消息,而在对方的缓存中堆积在一起造成的
-
粘包发生的本质:tcp协议是流式传输,数据与数据之间没有边界
-
解决方法
-
自定义协议:利用设置边界解决粘包现象
-
规定最大传输长度为n字节,每次接收时都接受n字节的数据作为一个数据
-
发送端:
- 第一种:计算将要发送的数据长度,通过struct模块将长度转换为固定的n字节,发送n个字节的长度
- 第二种:发送的数据相关的内容组成json:先发json的长度,再发json,json中存了接下来要发送的数据长度,再发数据(文件传输代码中实现了)
-
接收端:接收n字节,再使用struct.unpack将n字节转换为数字,这个数字就是将要接受的数据的长度,再根据长度接收数据,两条数据就不会粘在一起了
-
-
struct模块
- struct.pack(‘i’, 字符串)
- struct.unpack(‘i’, 字符串)
-
实例代码
# server.py 服务器端 import struct import socket sk = socket.socket() sk.bind(('127.0.0.1',9001)) sk.listen() conn,addr = sk.accept() msg1 = input('>>>').encode() msg2 = input('>>>').encode() # num = str() # '10001' # ret = num.zfill(4) # '0006' # conn.send(ret.encode('utf-8')) blen = struct.pack('i',len(msg1)) conn.send(blen) conn.send(msg1) conn.send(msg2) conn.close() sk.close()# client.py 客户端 import time import struct import socket sk = socket.socket() sk.connect(('127.0.0.1',9001)) # length = int(sk.recv(4).decode('utf-8')) length = sk.recv(4) length = struct.unpack('i',length)[0] msg1 = sk.recv(length) msg2 = sk.recv(1024) print(msg1.decode('utf-8')) print(msg2.decode('utf-8')) sk.close() -
3)文件上传和下载代码
# server端
import socket
import struct
import time
login_state = {
'name' : None,
'state': False
}
sk = socket.socket()
sk.bind(('127.0.0.1', 9006))
sk.listen()
conn, addr = sk.accept()
msg = conn.recv(1024).decode('utf-8')
with open('register.txt', encoding='utf-8', mode='r') as f:
for i in f:
if msg == i.strip():
conn.send('登陆成功'.encode('utf-8'))
login_state['name'] = msg.split('|')[0]
login_state['state'] = True
if login_state['state'] == False:
conn.send('q'.encode('utf-8'))
while True:
if login_state['state'] == True:
conn.send('1上传/2下载:'.encode('utf-8'))
opt = conn.recv(1024).decode('utf-8')
if opt == '1':
dir_test = conn.recv(1024).decode('utf-8').strip().split('/')[-1]
print(dir_test)
while True:
with open('../updateTest/' + dir_test, encoding='utf-8', mode='a') as f:
msg = conn.recv(1024).decode('utf-8')
if msg.upper() == 'Q':
break
f.write(msg)
break
elif opt == '2':
file_dir = conn.recv(1024).decode('utf-8')
with open(file_dir, encoding='utf-8', mode='r') as f:
for i in f:
i = i.strip()
print('传输中')
# length = struct.pack('i', len(i))
# conn.send(length)
conn.send(i.encode('utf-8'))
time.sleep(1)
print('传输完成')
time.sleep(2)
conn.send('q'.encode('utf-8'))
break
else:
login_state['name'] = None
login_state['state'] = False
break
else:
break
conn.close()
sk.close()
# client端
import socket
import struct
import time
sk = socket.socket()
sk.connect(('127.0.0.1', 9006))
msg1 = input('name>>>')
msg2 = input('pwd>>>')
msg = msg1.strip() + '|' + msg2.strip()
sk.send(msg.encode('utf-8'))
recv_msg = sk.recv(1024).decode('utf-8')
if recv_msg.upper() == 'Q':
sk.close()
msg = sk.recv(1024).decode('utf-8')
opt = input(msg).strip()
sk.send(opt.encode('utf-8'))
if opt == 'q':
sk.close()
elif opt == '1':
file_dir = input('上传文件路径>>>')
sk.send(file_dir.encode('utf-8'))
with open(file_dir, encoding='utf-8', mode='r') as f:
for i in f:
sk.send(i.encode('utf-8'))
time.sleep(2)
sk.send('q'.encode('utf-8'))
sk.close()
else:
file_dir = input('下载文件路径>>>')
sk.send(file_dir.encode('utf-8'))
while True:
# file_len = struct.unpack('i', sk.recv(4))[0]
# print(file_len)
file_msg = sk.recv(1024).decode('utf-8')
print(file_msg)
if file_msg.strip().upper() == 'Q':
print('下载完成!')
break
else:
print('正在下载中')
with open(('../download/' + file_dir.strip().split('/')[-1]), mode='a') as f:
f.write(file_msg + '\n')
sk.close()
4)验证客户端合法性
-
客户端合法性问题场景
每台服务器有多个客户端连接,可能有外来非法客户端连接服务器传输病毒
-
验证客户端合法性
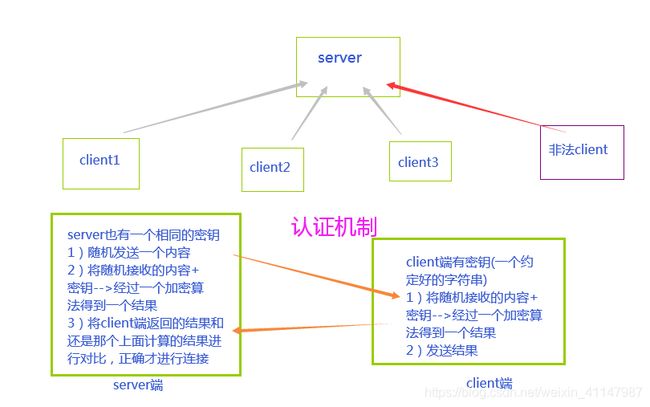
-
代码实现客户端合法性
-
hashlib模块加密
import os import socket import hashlib import hmac # server.py 服务器端 secret_key = b'alex_sb' sk = socket.socket() sk.bind(('127.0.0.1',9001)) sk.listen() conn,addr = sk.accept() # 创建一个随机的字符串 rand = os.urandom(32) # 发送随机字符串 conn.send(rand) # 根据发送的字符串 + secrete key 进行摘要 sha = hashlib.sha1(secret_key) sha.update(rand) res = sha.hexdigest() # res = hmac.new(secret_key, rand).digest() # hmac模块进行加密 # 等待接收客户端的摘要结果 res_client = conn.recv(1024).decode('utf-8') # 做比对 if res_client == res: print('是合法的客户端') # 如果一致,就显示是合法的客户端 # 并可以继续操作 conn.send(b'hello') else: conn.close() # 如果不一致,应立即关闭连接import hashlib import hmac # client.py 客户端 secret_key = b'alex_sb979' sk = socket.socket() sk.connect(('127.0.0.1',9001)) # 接收客户端发送的随机字符串 rand = sk.recv(32) # 根据发送的字符串 + secret key 进行摘要 sha = hashlib.sha1(secret_key) sha.update(rand) res = sha.hexdigest() # res = hmac.new(secret_key, rand).digest() # hmac模块进行加密 # 摘要结果发送回server端 sk.send(res.encode('utf-8')) # 继续和server端进行通信 msg = sk.recv(1024) print(msg) -
hmac模块加密(专门用于网络传输的加密模块)
在上述代码中
-
5)socketserver模块 – 并发的tcp协议server端
基于socket模块完成,tcp协议的server端处理并发的客户端请求
# server.py 服务器端
import time
import socketserver
class Myserver(socketserver.BaseRequestHandler):
def handle(self):
conn = self.request
while True:
try:
content = conn.recv(1024).decode('utf-8')
conn.send(content.upper().encode('utf-8'))
time.sleep(0.5)
except ConnectionResetError:
break
server = socketserver.ThreadingTCPServer(('127.0.0.1',9001),Myserver) # 实例化一个server
server.serve_forever() # 服务不停止
import socket
# client.py 客户端
sk = socket.socket()
sk.connect(('127.0.0.1',9001))
while True:
sk.send(b'hello')
content = sk.recv(1024).decode('utf-8')
print(content)
socketserver模块详解博客
3 操作系统基础
1)操作系统历史
- I/O操作
- 都是相对内存来说的
- I – input,O – output
- 计算机工作的两个阶段
- CPU工作:做计算(对内存中的数据进行操作)时工作
- CPU不工作:IO操作的时候(但是时间极短)
- 多道批处理系统:
- 遇到IO操作进行切换,执行完IO操作后再切换回来
- 节省时间、提高CPU利用率
- 进程之间数据隔离
- 时空复用:在同一个时间点上,多个程序同时执行着,一条内存条上存储了多个进程的数据
- 分时操作系统(单CPU):
- 每个程序执行一个时间片–时间片轮转
- 没有提高CPU利用率,提高了用户体验
- 实时操作系统
- 实时控制系统
- 实时信息处理系统
- 特点:及时响应、可靠性高
- 分布式操作系统
- 讲一个大任务分给多个操作系统/程序/插件程序来共同完成,提升效率
- celery python分布式框架
- 操作系统功能
- 有序划分硬件资源,使应用程序对硬件资源的竞争请求变的有序化
- 隐藏了硬件调用接口,为应用程序员提供了更方便的系统调用接口
2)基础并发概念
- 进程:进行中的程序就是一个进程
- 占用资源,需要操作系统调度分配资源
- pid(进程ID):唯一标识一个进程
- 是计算机中的最小资源分配单位
- 线程:
- 是进程中的一个单位,不能脱离进程存在
- 是计算机中能够被CPU调度的最小单位:实际执行具体编译解释之后的代码是线程,所以cpu执行的是解释之后的线程中的代码
- 并发:多个程序同时执行
- 只有一个CPU,多个程序轮流在一个CPU上执行
- 宏观上:多个程序同时执行
- 微观上:多个程序轮流在一个CPU上执行,本质上还是串行
- 并行:多个程序同时执行,并且在多个CPU上执行
- 同步:在做A事件的时候发起B事件,必须等B事件结束之后才能继续做A事件
- 异步:在做A事件的时候发起B事件,不用等B事件结束就可以继续做A事件
- 阻塞:程序执行时,如果CPU不工作 input accept recv recvfrom sleep connect
- 非阻塞:程序执行时,如果CPU工作
- 同步阻塞
- 调用函数必须等待结果
- CPU不工作
- join() input() sleep() recv() accept() connect() get()
- 同步非阻塞
- 调用函数必须等待结果
- CPU工作——调用了一个高计算的函数
- strip() eval() sum() max() min() sorted()
- 异步非阻塞
- 调用函数时不需要立即获取结果,也不需要等
- start() terminate()
- 异步阻塞
- 调用函数时不需要立即获取结果,而是继续做其他的事情,在获取结果的时候也不知道先获取谁的,但是总之需要等(阻塞)
4 进程
1)进程的三状态图
-
就绪、运行、阻塞
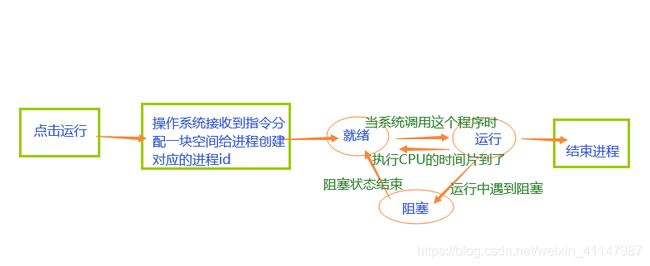
-
代码分析图

2)进程的调用算法
-
给所有的进程分配资源或者分配CPU使用权的一种方法
-
短作业优先
-
先来先服务 FCFS
-
多级反馈算法

- 多个任务队列,优先级从高到低
- 新来的任务加入第一优先队列
- 执行完一个时间片之后就会降级到下一级队列队尾
- 总是优先级高的队列中的任务都执行完才会执行优先级低的队列
- 优先级越高,时间片越短
3)进程的开启和关闭
-
父进程与子进程
- 父进程开启了子进程
- 父进程要负责给子进程回收子进程结束之后的资源
-
进程开启方法
-
通过外部函数开启
- 先定义外部函数,然后在主函数中对Process类进行实例化将函数名作为target参数的值,然后调用start()方法开启子进程
- 这个子进程就是执行对应target参数传进去的函数
import os from multiprocessing import Process def func(): print(os.getpid(),os.getppid()) # pid process id 进程id # ppid parent process id 父进程id if __name__ == '__main__': # 只会在主进程中执行的所有的代码你写在name = main下 print('main :',os.getpid(),os.getppid()) p = Process(target=func) p.start() -
通过面向对象开启
-
建立一个继承Process的子类,添加run()方法,在主函数中对子类实例化并调用start方法,即可创建子进程
-
要传参要通过
__init__方法进行传参,而且__init__方法要继承Process类super().__init__()import os import time from multiprocessing import Process class MyProcess(Process): def __init__(self,a,b,c): self.a = a self.b = b self.c = c super().__init__() def run(self): time.sleep(1) print(os.getppid(),os.getpid(),self.a,self.b,self.c) if __name__ == '__main__': print('-->',os.getpid()) for i in range(10): p = MyProcess(1,2,3) p.start()
-
-
4)multiprocessing模块
多元的进程处理模块,此处主要使用Process类
-
代码
import os from multiprocessing import Process def func(): print(os.getpid(),os.getppid()) # pid process id 进程id # ppid parent process id 父进程id if __name__ == '__main__': # 只会在主进程中执行的所有的代码你写在name = main下 print('main :',os.getpid(),os.getppid()) p = Process(target=func) p.start() -
windows用
if __name__ == '__main__':的原因(linux和mac都可以不用)- windows系统直接引入父进程模块,如果不引入
if __name__ == '__main__':直接会和父进程一样,循环产生子进程,而不会执行想要的操作,linux和mac系统则不存在这个问题


- windows系统直接引入父进程模块,如果不引入
-
给子进程传递参数
import os from multiprocessing import Process def func(name,age): print(os.getpid(),os.getppid(),name,age) if __name__ == '__main__': # 只会在主进程中执行的所有的代码你写在name = main下 print('main :',os.getpid(),os.getppid()) p = Process(target=func,args=('alex',84)) p.start() -
不能获取子进程的返回值
-
开启多个子进程
import os import time from multiprocessing import Process def func(name,age): print('%s start'%name) time.sleep(1) print(os.getpid(),os.getppid(),name,age) if __name__ == '__main__': # 只会在主进程中执行的所有的代码你写在name = main下 print('main :',os.getpid(),os.getppid()) arg_lst = [('alex',84),('太白', 40),('wusir', 48)] for arg in arg_lst: p = Process(target=func,args=arg) p.start() # 异步非阻塞 -
join的用法
import os import time import random from multiprocessing import Process def func(name,age): print('发送一封邮件给%s岁的%s'%(age,name)) time.sleep(random.random()) print('发送完毕') if __name__ == '__main__': arg_lst = [('大壮',40),('alex', 84), ('太白', 40), ('wusir', 48)] p_lst = [] for arg in arg_lst: p = Process(target=func,args=arg) p.start() p_lst.append(p) for p in p_lst:p.join() # p_l = [] # p = Process(target=func, args=('大壮',40)) # p.start() # p_l.append(p) # p = Process(target=func, args=('alex', 84)) # p.start() # p_l.append(p) # p = Process(target=func, args=('太白', 40)) # p.start() # p_l.append(p) # p = Process(target=func, args=('wusir', 48)) # p.start() # p_l.append(p) for p in p_l:p.join() print('所有的邮件已发送完毕') -
进程之间的数据是隔离的
from multiprocessing import Process n = 0 def func(): global n n += 1 if __name__ == '__main__': p_l = [] for i in range(100): p = Process(target=func) p.start() p_l.append(p) for p in p_l:p.join() print(n) -
多进程实现一个并发的socket的server
# server端 import socket from multiprocessing import Process def talk(conn): while True: msg = conn.recv(1024).decode('utf-8') ret = msg.upper().encode('utf-8') conn.send(ret) conn.close() if __name__ == '__main__': sk = socket.socket() sk.bind(('127.0.0.1',9001)) sk.listen() while True: conn, addr = sk.accept() Process(target = talk,args=(conn,)).start() sk.close()# client端 import time import socket sk = socket.socket() sk.connect(('127.0.0.1',9001)) while True: sk.send(b'hello') msg =sk.recv(1024).decode('utf-8') print(msg) time.sleep(0.5) sk.close() -
Process类的一些其他方法/属性
-
p.pid、p.ident # 子进程ID
-
p.name # 子进程名
-
p.terminate() # 强制结束子进程 ,异步非阻塞
-
p.is_alive() # 查看子进程是否存在
import os import time from multiprocessing import Process class MyProcess(Process): def __init__(self,a,b,c): self.a = a self.b = b self.c = c super().__init__() def run(self): time.sleep(3) print(os.getppid(),os.getpid(),self.a,self.b,self.c) if __name__ == '__main__': p = MyProcess(1,2,3) p.start() print(p.pid,p.ident) print(p.name) print(p.is_alive()) p.terminate() # 强制结束一个子进程 同步 异步非阻塞 print(p.is_alive()) time.sleep(0.01) print(p.is_alive())
-
-
守护进程(现在基本直接zabbix框架进行监控)
-
p.daemon = True # 表示P1是一个守护进程,再start()之前设置
-
主进程会等待所有的子进程结束,是为了回收子进程的资源
-
守护进程会等待主进程的代码执行结束之后再结束,而不是等待整个主进程结束
import time from multiprocessing import Process def son1(): while True: print('--> in son1') time.sleep(1) def son2(): # 执行10s for i in range(10): print('in son2') time.sleep(1) if __name__ == '__main__': # 3s p1 = Process(target=son1) p1.daemon = True # 表示设置p1是一个守护进程 p1.start() p2 = Process(target=son2,) p2.start() time.sleep(3) print('in main') # p2.join() # 等待p2结束后守护进程才会结束,因为此处p1要等待主进程代码执行完成,然后主进程代码执行完成加入p2.join()就相当于等p2执行结束,所以如上效果
-
5)进程同步 —— Lock 锁
涉及进程之间数据安全的问题,虽然锁可以保证数据安全,但是会降低程序的运行效率
-
语法
- lock = Lock() # 设置锁
- 第一种拿取钥匙方法:
- lock.acquire() # 拿钥匙
- 代码 # 进门关门
- lock.release() # 放钥匙
- 第二种拿取钥匙方法
- with lock:
- 代码
- 这种方法代替了第一种方法,而且在此基础上作了一些异常处理,保证第一个进程的代码出错退出之后,也会归还钥匙
- with lock:
-
理解:对门加锁(互斥锁),多进程一起拿钥匙进门,第一个拿到钥匙的进程占用房间,其他进程不能进入,只有等这个进程占用结束才能再次竞争拿钥匙
# 加锁实例:抢票 import json import time from multiprocessing import Process,Lock def search(i): with open('ticket',encoding='utf-8') as f: ticket = json.load(f) print('%s :当前的余票是%s张'%(i,ticket['count'])) def buy_ticket(i): with open('ticket',encoding='utf-8') as f: ticket = json.load(f) if ticket['count']>0: ticket['count'] -= 1 print('%s买到票了'%i) time.sleep(0.1) with open('ticket', mode='w',encoding='utf-8') as f: json.dump(ticket,f) def get_ticket(i,lock): search(i) # lock.acquire() # 拿钥匙,关门 # buy_ticket(i) # 执行 # lock.release() # 开门放钥匙 with lock: # 代替acquire和release 并且在此基础上做一些异常处理,保证即便一个进程的代码出错退出了,也会归还钥匙 buy_ticket(i) if __name__ == '__main__': lock = Lock() # 互斥锁 for i in range(10): Process(target=get_ticket,args=(i,lock)).start()
6)进程之间通信 —— 队列
进程之间通信 IPC(Inter Process communication)
-
基于文件的IPC:
-
适用于同一个机器上的多个进程通信
-
基于socket\pickle/Lock实现的文件级别的通信来完成数据传递的
-
使用Queue实现(IPC还可以通过pipe实现,pipe管道基于socket/pickle实现的,但是没有锁不安全)
-
from multiprocessing import Queue
from multiprocessing import Queue,Process def pro(q): for i in range(10): print(q.get()) # 收,收>发进行发次通信后进入阻塞队列等待再一次发 def son(q): for i in range(10): q.put('hello%s'%i) # 发,发>收只进行收次通信 if __name__ == '__main__': q = Queue() p = Process(target=son,args=(q,)) p.start() p = Process(target=pro, args=(q,)) p.start()
-
-
-
基于网络的IPC:
- 同一台机器或者多台机器上的多进程通信
- 使用第三方工具实现(消息中间件)
- memcache
- redis
- rabbitmq
- kafka
-
生产者消费者模型
-
把原本获取数据处理数据的完整过程进行了解耦(低耦合、高内聚)
-
基础实现代码
import time import random from multiprocessing import Queue,Process def consumer(q,name): # 消费者:通常取到数据之后还要进行某些操作 while True: food = q.get() if food: print('%s吃了%s'%(name,food)) else:break def producer(q,name,food): # 生产者:通常在放数据之前需要先通过某些代码来获取数据 for i in range(10): foodi = '%s%s'%(food,i) print('%s生产了%s'%(name,foodi)) time.sleep(random.random()) q.put(foodi) if __name__ == '__main__': q = Queue() c1 = Process(target=consumer,args=(q,'alex')) c2 = Process(target=consumer,args=(q,'alex')) p1 = Process(target=producer,args=(q,'大壮','泔水')) p2 = Process(target=producer,args=(q,'b哥','香蕉')) c1.start() c2.start() p1.start() p2.start() p1.join() p2.join() q.put(None) q.put(None) -
应用:
-
爬虫
-
分布式操作:celery

-
-
本质:就是让生产数据和消费数据的效率达到平衡并且最大化的效率
-
异步阻塞爬虫代码实例
# 进程的生产者消费者模型 # 多个进程访问页面 # 一个进程负责把网页源码写到文件里 import requests from multiprocessing import Process,Queue url_dic = { 'cnblogs':'https://www.cnblogs.com/Eva-J/articles/8253549.html', 'douban':'https://www.douban.com/doulist/1596699/', 'baidu':'https://www.baidu.com', 'gitee':'https://gitee.com/old_boy_python_stack__22/teaching_plan/issues/IXSRZ', } def producer(name,url,q): ret = requests.get(url) q.put((name,ret.text)) def consumer(q): while True: tup = q.get() if tup is None:break with open('%s.html'%tup[0],encoding='utf-8',mode='w') as f: f.write(tup[1]) if __name__ == '__main__': q = Queue() pl = [] for key in url_dic: p = Process(target=producer,args=(key,url_dic[key],q)) p.start() pl.append(p) Process(target=consumer,args=(q,)).start() for p in pl:p.join() q.put(None)
-
7)进程之间的数据共享 —— Manager类
Manage类里面有一些可以进行进程共享的数据类型,但是数据共享时不安全,可能会丢失,所以要对共享的数据进行加锁
from multiprocessing import Process,Manager,Lock
def change_dic(dic,lock):
with lock:
dic['count'] -= 1
if __name__ == '__main__':
m = Manager()
# with Manager() as m:
lock = Lock()
dic = m.dict({'count': 100})
# dic = {'count': 100}
p_l = []
for i in range(20):
p = Process(target=change_dic,args=(dic,lock))
p.start()
p_l.append(p)
for p in p_l : p.join()
print(dic)
5 线程
1)基本概念
-
线程:能被操作系统调度(给CPU执行)的最小单位
-
线程特点:
- 数据共享
- 操作系统调度的最小单位
- 可以利用多核:同一进程的多个线程可以同时被一个或者多个CPU执行
- 数据不安全
- 开启关闭切换时间开销小
-
在CPython解释器中的多线程 —— 节省IO操作时间
-
gc 垃圾回收机制 线程
-
gc 解释博客
-
引用计数 + 分代回收
-
当值引用计数为0时回收值
-
引用计数:
a = 1 # 当一个线程执行上面代码时,gc会对数值1的引用计数+1 -
全局解释器锁 GIL(global interpreter lock)
-
GIL解释博客
-
它的出现主要是为了完成gc的回收机制,对不同线程的引用计数的变化记录的更加精准
-
导致了同一个进程中的多个线程只能有一个线程真正的被CPU调度,即不能利用多核
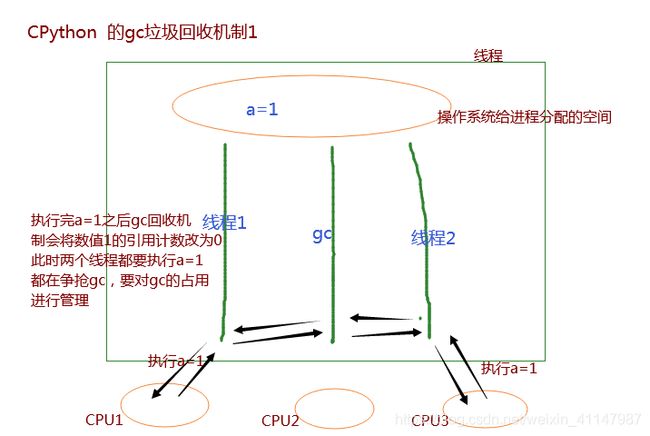
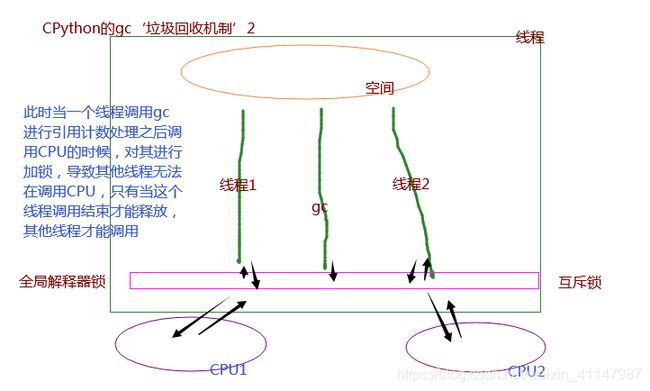
-
-
-
节省的是io操作的时间,而不是cpu计算的时间,因为cpu的计算速度特别快,大部分情况下,没有办法把一条进程中的所有io操作都规避掉,所以节省io操作的时间已经大大超过多线程同时利用cpu带来的节省的时间,即提升的效率>>降低的效率
-
pypy解释器 不能利用多核(因为gc)
-
jpython 可能利用多核
-
2)threading模块开启线程
-
函数方式开启线程
-
线程执行效率高
-
线程也有join()进行主动等待线程结束
-
线程不能在外部关闭
-
current_thread() 获取当前所在的线程对象
- current_thread().ideal # 当前线程对象的id
-
enumerate() 列表 存储了所有活着的线程,包括主线程
-
active_count() 数字 存储了活着的线程的数量
import os import time from threading import Thread,current_thread,enumerate,active_count # from multiprocessing import Process as Thread def func(i): print('start%s'%i,current_thread().ident) time.sleep(1) print('end%s'%i) if __name__ == '__main__': tl = [] for i in range(10): t = Thread(target=func,args=(i,)) t.start() print(t.ident,os.getpid()) tl.append(t) print(enumerate(),active_count()) for t in tl:t.join() print('所有的线程都执行完了')
-
-
面向对象开启线程(与面向对象开启进程方式相同)
# 面向对象的方式起线程 from threading import Thread class MyThread(Thread): def __init__(self,a,b): self.a = a self.b = b super().__init__() def run(self): print(self.ident) t = MyThread(1,2) t.start() # 开启线程 才在线程中执行run方法 print(t.ident)
3)线程之间的数据共享
可以数据共享
from threading import Thread
n = 100
def func():
global n
n -= 1
t_l = []
for i in range(100):
t = Thread(target=func)
t.start()
t_l.append(t)
for t in t_l:
t.join()
print(n)
4)守护线程
-
守护线程、主线程、子线程
- 主线程会等待子线程结束之后才结束,因为主线程结束进程就结束
- 守护线程随着主线程的结束而结束
- 守护线程会在主线程的代码执行结束后继续守护其他子线程
-
守护进程和守护线程的结束原理不同
- 守护进程需要主进程来回收资源
- 守护线程是随着进程的结束而结束,所有的线程都会随着进程的结束而被回收
import time from threading import Thread def son(): while True: print('in son') time.sleep(1) def son2(): for i in range(3): print('in son2 ****') time.sleep(1) # flag a 0s t = Thread(target=son) t.daemon = True # 设置守护线程 t.start() Thread(target=son2).start() # flag b a-b段代码执行需要的时间接近0s
5)线程锁
多线程同时操作全局变量/静态变量,会产生数据不安全现象
-
互斥锁(Lock)
-
产生:
- += -= *= /= while if 等操作全局变量时会导致数据不安全
- 带返回值的都是先计算再赋值,数据都是不安全的 a = b.strip()
- append pop queue logging 等列表中的方法或者字典的方法去操作全局变量的时候,数据是安全的
-
通过dis模块理解线程的数据安全问题
-
dis.dis(函数名) 查看执行函数时操作系统的调用cpu指令

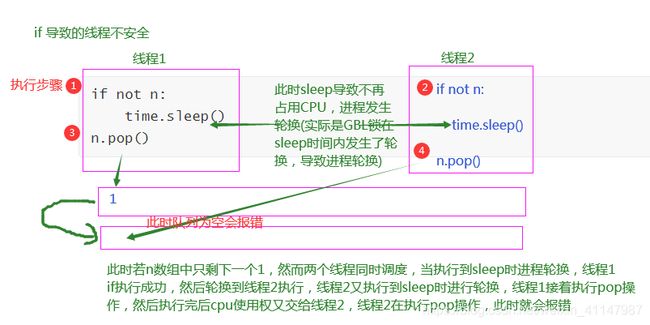

-
-
线程安全的单例模式
import time class A: from threading import Lock __instance = None lock = Lock() def __new__(cls, *args, **kwargs): with cls.lock: # 加锁 if not cls.__instance: time.sleep(0.000001) # cpu轮转 cls.__instance = super().__new__(cls) return cls.__instance -
解决:不要操作全局变量,不要再类里操作全局变量

代码方案:
from threading import Thread,Lock n = 0 def add(lock): for i in range(500000): global n with lock: n += 1 def sub(lock): for i in range(500000): global n with lock: # 加锁 n -= 1 t_l = [] lock = Lock() for i in range(2): t1 = Thread(target=add,args=(lock,)) t1.start() t2 = Thread(target=sub,args=(lock,)) t2.start() t_l.append(t1) t_l.append(t2) for t in t_l: t.join() print(n) -
应用场景:平常使用,但是多把锁会出现死锁现象
-
-
递归锁(R(Recursion)Lock)
-
理解:一把钥匙开多个门
-
语法:
- rlock = RLock() # 设置锁
- 第一种拿取钥匙方法:
- rlock.acquire() # 拿钥匙
- 代码 # 进门关门
- rlock.release() # 放钥匙
- 第二种拿取钥匙方法
- with rlock:
- 代码
- with rlock:
-
递归锁实例:(在同一个线程中可以被acquire多次)
from threading import Thread,RLock def func(i,lock): rlock.acquire() rlock.acquire() print(i,': start') rlock.release() rlock.release() print(i, ': end') rlock = RLock() # 在同一个线程中可以被acquire多次 for i in range(5): Thread(target=func,args=(i,rlock)).start() -
效率比较低
-
应用场景:能够快速解决死锁现象
-
-
死锁现象
-
产生原因:有多把(互斥/递归)锁,并且在多个线程中交叉使用
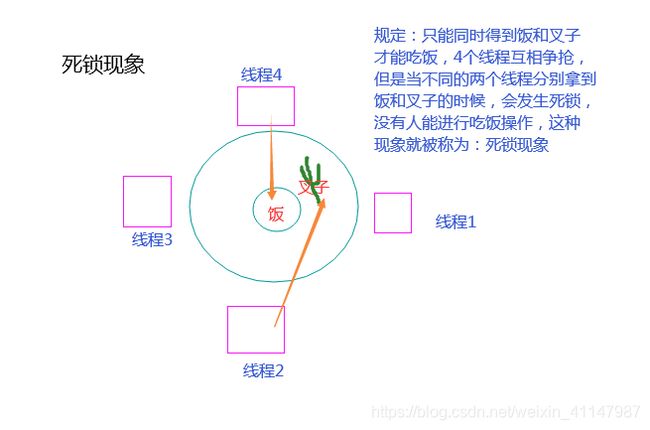
import time from threading import Thread,Lock,RLock noodle_lock = Lock() fork_lock = Lock() # 解决方法:fork_lock = noodle_lock = RLock() def eat(name): noodle_lock.acquire() print(name,'抢到面了') fork_lock.acquire() print(name, '抢到叉子了') print(name,'吃面') time.sleep(0.1) fork_lock.release() print(name, '放下叉子了') noodle_lock.release() print(name, '放下面了') def eat2(name): fork_lock.acquire() print(name, '抢到叉子了') noodle_lock.acquire() print(name,'抢到面了') print(name,'吃面') noodle_lock.release() print(name, '放下面了') fork_lock.release() print(name, '放下叉子了') Thread(target=eat,args=('线程1',)).start() Thread(target=eat2,args=('线程2',)).start() Thread(target=eat,args=('线程3',)).start() Thread(target=eat2,args=('线程4',)).start() -
解决方法:
- 如果是互斥锁,出现了死锁现象,最快速的解决方案是可以把所有的互斥锁改为一把递归锁,就可以解决,但是效率会降低(代码如上)
-
6)线程队列
-
queue模块——>线程之间数据安全的容器队列
-
语法:
-
q = queue.Queue(大小) # FIFO 先进先出的队列,最常用
import queue # 线程之间数据安全的容器队列 from queue import Empty # 不是内置的错误类型,而是queue模块中的错误 q = queue.Queue(4) # fifo 先进先出的队列 q.get() q.put(1) q.put(2) q.put(3) q.put(4) print('4 done') q.put_nowait(5) print('5 done') try: q.get_nowait() except Empty: pass print('队列为空,继续其他内容') -
q = queue.LifoQueue() # LIFO 后进后出的栈 ,常用于算法
from queue import LifoQueue # last in first out 后进先出 栈 lq = LifoQueue() lq.put(1) lq.put(2) lq.put(3) print(lq.get()) print(lq.get()) print(lq.get()) -
q = queue.PriorityQueue() # 优先级队列(put时要传入优先数),常用于常用web、运维服务
from queue import PriorityQueue # 优先级队列 priq = PriorityQueue() priq.put((2,'线程1')) priq.put((1,'线程2')) priq.put((0,'线程3')) print(priq.get()) print(priq.get()) print(priq.get()) -
q.get()
-
q.put()
-
q.get_nowait() # 队列中为空,拿不到数据了,返回queue.Empty错误
-
q.put_nowait() # 队列满了,放不进去数据了,返回queue.Full错误
-
queue.Empty queue.Full # 不是内置的错误类型,而是queue模块中的错误
-
7)线程池与进程池
-
池
- 在此程序开始的时候,还没提交任务先创建几个进程或者线程,放在池子里。这就是池。
- 使用原因:如果先开好进程/线程,那么有任务之后就可以直接使用这个池中的数据了
- 优点:
- 避免的线程/进程的多次开启和回收,极大减少了时间开销
- 减轻CPU的压力,规定了池中的进程/线程数控制了操作系统需要调度的任务个数,控制池中的单位,有利于提高操作系统效率,减轻操作系统负担
-
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExcutor-
线程池
-
实例化创建线程池
-
向线程池中提交任务,submit传参数(按照位置传,按照关键字传)
-
线程池 import time import random from threading import current_thread from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor def func(a,b): print(current_thread().ident,'start',a,b) time.sleep(random.randint(1,4)) print(current_thread().ident,'end') if __name__ == '__main__': tp = ThreadPoolExecutor(4) for i in range(20): tp.submit(func,i,b=i+1)
-
-
进程池
-
进程池 import os import time,random from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor def func(a,b): print(os.getpid(),'start',a,b) time.sleep(random.randint(1,4)) print(os.getpid(),'end') if __name__ == '__main__': tp = ProcessPoolExecutor(4) for i in range(20): tp.submit(func,i,b=i+1)
-
-
获取任务结果
-
获取任务结果 import os import time,random from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor def func(a,b): print(os.getpid(),'start',a,b) time.sleep(random.randint(1,4)) print(os.getpid(),'end') return a*b if __name__ == '__main__': tp = ProcessPoolExecutor(4) futrue_l = {} for i in range(20): # 异步非阻塞的 ret = tp.submit(func,i,b=i+1) futrue_l[i] = ret # print(ret.result()) # Future未来对象 for key in futrue_l: # 同步阻塞的 print(key,futrue_l[key].result())
-
-
map
-
import os import time,random from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor def func(a): print(os.getpid(),'start',a[0],a[1]) time.sleep(random.randint(1,4)) print(os.getpid(),'end') return a[0]*a[1] if __name__ == '__main__': tp = ProcessPoolExecutor(4) ret = tp.map(func,((i,i+1) for i in range(20))) for key in ret: # 同步阻塞的 print(key)
-
-
回调函数
-
简单用法
-
# 回调函数 : 效率最高的 import time,random from threading import current_thread from concurrent.futures import ThreadPoolExecutor def func(a,b): print(current_thread().ident,'start',a,b) time.sleep(random.randint(1,4)) print(current_thread().ident,'end',a) return (a,a*b) def print_func(ret): # 异步阻塞 print(ret.result()) if __name__ == '__main__': tp = ThreadPoolExecutor(4) futrue_l = {} for i in range(20): # 异步非阻塞的 ret = tp.submit(func,i,b=i+1) ret.add_done_callback(print_func) # ret这个任务会在执行完毕的瞬间立即触发print_func函数,并且把任务的返回值对象传递到print_func做参数 # 异步阻塞 回调函数 给ret对象绑定一个回调函数,等待ret对应的任务有了结果之后立即调用print_func这个函数 # 就可以对结果立即进行处理,而不用按照顺序接收结果处理结果
-
-
实例
-
from concurrent.futures import ThreadPoolExecutor import requests import os def get_page(url): # 访问网页,获取网页源代码 线程池中的线程来操作 print('<进程%s> get %s' %(os.getpid(),url)) respone=requests.get(url) if respone.status_code == 200: return {'url':url,'text':respone.text} def parse_page(res): # 获取到字典结果之后,计算网页源码的长度,把https://www.baidu.com : 1929749729写到文件里 线程任务执行完毕之后绑定回调函数 res=res.result() print('<进程%s> parse %s' %(os.getpid(),res['url'])) parse_res='url:<%s> size:[%s]\n' %(res['url'],len(res['text'])) with open('db.txt','a') as f: f.write(parse_res) if __name__ == '__main__': urls=[ 'https://www.baidu.com', 'https://www.python.org', 'https://www.openstack.org', 'https://help.github.com/', 'http://www.sina.com.cn/' ] # 获得一个线程池对象 = 开启线程池 tp = ThreadPoolExecutor(4) # 循环urls列表 for url in urls: # 得到一个futrue对象 = 把每一个url提交一个get_page任务 ret = tp.submit(get_page,url) # 给futrue对象绑定一个parse_page回调函数 ret.add_done_callback(parse_page) # 谁先回来谁就先写结果进文件 -
不用回调函数
- 按照顺序获取网页 百度 python openstack git sina
- 也只能按照顺序写
-
用上了回调函数
- 按照顺序获取网页 百度 python openstack git sina
- 哪一个网页先返回结果,就先执行那个网页对应的parserpage(回调函数)
-
-
-
6 协程
-
生成器及send方法参考博客
-
协程理解参考博客
-
【PEP 342】
-
操作系统不可见的
-
本质就是一条线程,多个任务在一条线程上来回切换
-
利用协程这个概念实现的内容:来规避IO操作,达到我们将一条线程中的io操作降到最低的目的
-
切换并规避io的两个模块
- gevent
- 利用了greenlet(c语言底层实现) 底层模块完成的切换 + 自动规避的功能
- asyncio
- 利用了yield 底层模块完成的切换 + 自动规避的功能
- 发展历程:
- 出现tornado 一步的web框架
- 出现yield from,更好的实现协程
- 出现send,更好地实现协程
- 出现asyncio模块,基于python原生的协程的概念正式的成立
- 出现特殊的在python中提供协程功能的关键字:async、await
- gevent
-
协程存在数据共享,但是数据安全
-
进程、线程与协程的区别
- 进程,数据隔离,数据不安全,操作系统级别,开销特别大,能利用多核
- 线程,数据共享,数据不安全,操作系统级别,开销小,不能利用多核,一些文件相关的io只有操作系统能感知到
- 协程,数据共享,数据安全,用户级别,开销更小,不能利用多核,协程的所有切换都基于用户,那么只有在用户级别能够感知到的io操作才会用协程模块做切换来规避(如:socket,请求网页)
-
用户级别的协程的好处
- 减轻了操作系统的负担
- 一条线程如果开了多条协程,那么会让操作系统感知到线程很忙,这样能多争取到一些时间片时间来被CPU执行,提高了程序效率
-
gevent模块实例
-
import time print(time.sleep) from gevent import monkey monkey.patch_all() import time import gevent def func(): # 带有io操作的内容写在函数里,然后提交func给gevent print('start func') time.sleep(1) print('end func') g1 = gevent.spawn(func) g2 = gevent.spawn(func) g3 = gevent.spawn(func) gevent.joinall([g1,g2,g3]) -
处理一些基础的网络操作
-
基于gevent协程实现socket并发
-
# server端 import socket print(socket.socket) # 在patch all之前打印一次 from gevent import monkey # gevent 如何检测是否能规避某个模块的io操作呢? monkey.patch_all() import socket import gevent print(socket.socket) # 在patch all之后打印一次,如果两次的结果不一样,那么就说明能够规避io操作 def func(conn): while True: msg = conn.recv(1024).decode('utf-8') MSG = msg.upper() conn.send(MSG.encode('utf-8')) sk = socket.socket() sk.bind(('127.0.0.1',9001)) sk.listen() while True: conn,_ = sk.accept() gevent.spawn(func,conn) -
# client端 import time import socket from threading import Thread def client(): sk = socket.socket() sk.connect(('127.0.0.1',9001)) while True: sk.send(b'hello') msg = sk.recv(1024) print(msg) time.sleep(0.5) for i in range(500): Thread(target=client).start()
-
-
gevent检测能规避某个模块的io操作的方法:
import socket print(socket.socket) # 在patch all之前打印一次 from gevent import monkey # gevent 如何检测是否能规避某个模块的io操作呢? monkey.patch_all() import socket import gevent print(socket.socket) # 在patch all之后打印一次,如果两次的结果不一样,那么就说明能够规避io操作
-
-
asyncio模块
-
实例
import asyncio async def func(name): print('start',name) # await 可能会发生阻塞的方法 # await 关键字必须写在一个async函数里 await asyncio.sleep(1) print('end') loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait([func('alex'),func('太白')]))
-
-
协程的原理
-
# 协程的原理 import time def sleep(n): print('start sleep') yield time.time() + n print('end sleep') def func(n): print(123) yield from sleep(n) # 睡1s print(456) def run_until_complete(g1,g2): ret1 = next(g1) ret2 = next(g2) time_dic = {ret1: g1, ret2: g2} while time_dic: min_time = min(time_dic) time.sleep(min_time - time.time()) try: next(time_dic[min_time]) except StopIteration: pass del time_dic[min_time] n = 1 g1 = func(1) g2 = func(1.1) run_until_complete(g1,g2)
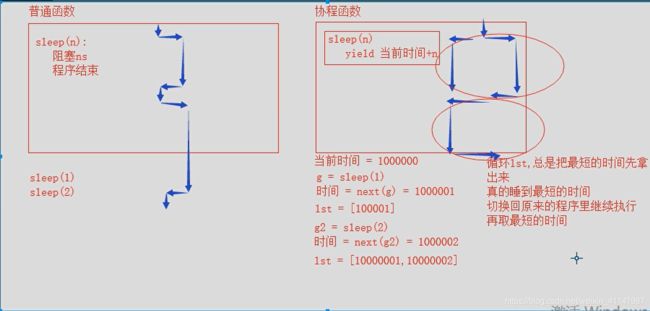
-
此文为个人学习old_boy系列课程笔记
参考博客链接