数据挖掘:概念与技术(第三版)之第十章的学习记录
本章主要讲解聚类的基本概念和方法
对聚类的浅要分析
聚类是什么意思,很好理解,这里不说了。
需要注意的是一下这几点
1、在相同的数据集上,不同的聚类方法可能产生不同的聚类 。
2、聚类可以作为其他算法的预处理步骤。书P289页最上方给出了一个识别手写数字的例子。
3、聚类在搜索中也有广泛的应用。
4、聚类可以应用与离群点检测。
5、聚类被称为无监督学习。
KDD对聚类分析的要求是P289,10.1.2。
基本的聚类方法有哪些?
一般来说,基本聚类方法可以划分为如下4类:
1、划分方法
2、层次方法
3、基于密度的方法
4、基于网格的方法
需要注意的是,某一个具体的方法可能属于多个层次,这里对聚类方法进行一个划分主要对其提供一个相对有组织的描述。
接下来,我们依次探讨这4类方法。
划分方法
聚类分析最简单、最基本的版本是划分,它把对象组织成多个互斥的簇。这一方法,要求每个对象必须/恰好属于每一个簇。(事实上,我们应该知道,这个要求是很不合理的,因为它忽略了离群点,假若把噪声数据强行划分在簇里,那势必会降低聚类的准确率,所以为了改进这一点,在模糊划分中适当放宽了这一要求。但本书并没有讲到模糊划分,有兴趣的同学可以进行查阅一下文献。)
大部分的划分算法都是基于距离的。(这个应该也很好理解吧,我们在前面应该提到过不止一次,这里说的距离实际上是用来度量相似性的)。他们的操作步骤通常是这样的:
1、首先给定要构建的分区数K,然后直接创建一个初始划分;
2、然后,使用一种称之为迭代的重定位技术来不断的调整,改进划分。(它的改进准则是:同一个簇中的对象要尽可能接近,不同簇中的对象要尽可能的远离)
从上面我们可以看到,这种传统的操作方法,为了达到全局最优,算法很有可能要穷举所有可能的划分,这显示不是不可接受的。因此实际上,目前的划分算法一般都采用启发式的方法,即渐进的提高聚类质量,以逼近局部最优解。
下面,我们就来讲解目前流行的划分算法:K-均值算法和K-中心点算法。这类算法非常适合发现中小规模的数据库中的球状簇(实际上是近似于球)
K-均值算法:一种基于形心的技术
首先我们来讲解传统的/基于形心的技术
假设数据集D中包含n个欧式空间中的对象,划分方法就是把D中的对象分配到k个簇中,其中各个簇之间互斥。然后通过目标函数来评估划分簇的质量,然后不断调整。
其实我们可以看到,这里叙述的划分方法和上面的传统方法基本一样。但是还没有完!!!
我们知道,划分方法一般聚类的都是球状簇。那么既然是球,就自然有球心。因此,这里说的基于形心的/形心实质上就可以理解为球心。
我们一般用簇Ci的形心来代表该簇。从概念上来讲,簇的形心就是它的中心点。而这个中心点可以用多种方法定义(为什么呢?因为,这个球状只是我们看起来是球的形状而已,他并不是几何意义上的球,所以,要找出这个“球”的中心,自然不像几何那么严谨),例如可以取该簇中所有对象的均值或中心点
上面我们提到了目标函数,它的值被称为簇内变差它的作用就是用来评估簇划分的质量的。它的目的就是要让簇内高相似性和簇间低相似性。
书P293,公式(10.1)给出了一个目标函数。实际上该函数就是求簇内每个对象到簇中心点(K-均值算法的话均值就是中心点)的距离平方,然后求和这里不再多说。
总的来说,我们要提高聚类质量,那么就要不断的去优化簇内变差。但是传统划分算法开销巨大,所以这里我们引出了k-均值算法。
这个算法就是把簇的形心定义为簇内点的均值。它的处理流程如下
1、在数据集中,随机地选择k个对象,每个对象代表一个簇的初始均值(中心);
2、对剩下的每个对象,分别计算其与各个簇中心的欧式距离(事实上就是计算相似性),将它分配到最相似的簇;
3、更新簇中心。对于每个簇来说,就是根据簇中的当前对象,来重新计算每个簇的均值,然后把该均值作为新的簇的中心。
4、然后重复第2,3步直至分配稳定。
P294,例10.1给出了相似的例子,简单明了。
K-均值算法的特点是:不能保证该算法收敛域全局最优解,并且它常常终止于一个局部最优解。结果可能依赖于初始簇中心的随机选择,所以为了尽可能的得到好的结果,我们通常会选择不同的初始簇中心,来多疑运行K-均值算法。
k-均值算法的优缺点
优点:
1、对于处理大数据集,该算法是相对可伸缩的和有效的;
缺点:
1、仅当簇的均值有定义时才能使用K-均值定义。例如,处理标称数据就不能使用K-均值算法。因为它无法计算簇内均值呀(映射???我想应该不可以吧=。=),所以针对这种情况,可以使用k-众数算法来处理标称数据
2、对噪声和离群点敏感。上面已经提到了,因为它的划分是互斥的,所以必然会出现这种情况。所以针对这种情况,出现了模糊划分技术。上面已经提到过。
3、必须用户自己指定要生成的簇数K。阅读过10.1.2节的同学知道,要求用户自己指定参数一般都是不靠谱的,所以这里给出了一种解决方法,那就是提供一个k的取值范围然后去试,然后取一个相对较好的。实际上,我们也能想象到这种方法其实也不好。
如何提高K-均值算法的性能
因为这个算法实在太简单了,所以它的性能能够提升的方面也就是伸缩性了。
在面对大数据集时,通过使用这三种方法来提高K-均值的伸缩性
1、使用样本;
2、过滤方法;
3、微聚类方案。
K-中心点:一种基于代表对象的技术
K-中心点算法是针对K-均值算法对离群点和噪声敏感的缺点提出的一种改进算法。
P295,例10.2给出了K-均值算法的对离群点和噪声敏感的一个例子。
类比于K-均值算法,K-中心点聚类算法的变动主要有两点
1、中心点不是均值,而是用一个实际的对象(称作“代表对象”)来表示中心点;
2、目标函数不是距离的平方和了(公式10.1,P293)而是绝对距离和了(公式10.2,P296)
关于这个公式需要好好理解下, 它的值表示的是数据集中所有对象P与Ci的代表对象Oi的绝对误差之和。
下面我们是否要更新代表对象,就靠这个目标函数的值来决定了。
PAM算法是K-中心点聚类的一种流行的实现。它的主要流程如下
1、随机选择K个对象,每个对象代表一个簇的中心点;
2、对剩下的每个对象,分别计算其与各个簇中心(代表对象)的欧式距离,将它分配到最相似的簇;
3、更新代表对象了。这一步稍微有点复杂,我拆开来说。
3.1:为了决定一个非代表对象是否是当前的一个代表对象更好的替代,我们需要来计算一下。
3.2:首先计算所有点(除开该候选对象)到当前代表对象集合的绝对误差之和(实际上就是计算公式10.2)
3.3:然后计算所有点(除开待替换对象)到当前代表对象集合(该集合目前是少了待替换对象,多了该候选对象)的绝对误差之和(公式10.2)
3.4:接着,比较这两次计算的值,如果3.3的值比3.2的值小,那么说明如果我们使用该候选点替换该中心点之后,聚类的效果会更好。所以我们进行中心点的替换(代表对象)。
4、重复第2,3步直至聚类稳定。
从算法我们可以看出,使用了新的目标函数之后,K-中心点算法(具体来书是PAM算法)相对与K-均值算法来说,它对于离群点和噪声数据不那么敏感了。但同时,我们也能看到,该算法的计算量是相当巨大的。
所以,一般来说,PAM算法一般都应用与小型的数据集上。
那么面对大型数据集时该使用什么呢?
CLARA算法是使用了抽样数据集来处理。具体的在P297页有详细论述。
层次方法
由于实际的需求,我们在某些时刻希望对数据进行分层次的聚类。对于数据汇总或者可视化来说,用层级结构的形式来表示数据对象是有用的。
存在多种层次聚类方法,一般来说可以分为这三种:
1、算法方法(凝聚,分裂、BIRCH,Chameleon),这类方法将数据对象看作确定性的,并且根据对象之间的确定性的距离计算簇。
2、概率方法,这类方法使用概率模型捕获簇,并且根据模型的拟合度/度量/簇的质量
3、贝叶斯方法,这类方法计算可能的聚类的分布,即他们返回给定数据上的一组聚类结构和他们的概率、条件,而不是输出数据集上单个确定性的聚类。
层次方法中的算法方法
凝聚的层次聚类
凝聚的层次聚类使用自底向上的策略。典型地,它从令每个对象形成自己的簇开始,并且迭代的把簇合并成越来越大的簇,直到所有的对象都在一个簇中,或者满足某个终止条件。
在合并簇时,它根据某种相似性度量(实际上就是距离)找出两个最接近的簇,并且合并它们,形成一个簇。
分裂的层次聚类
分裂的层次聚类使用自顶向下的策略,它从把所有对象置于一个簇中开始,递归地把簇划分成更小的簇,直至满足某一个终止条件或者仅包含一个对象。
P299,例10.3介绍了一种凝聚的层次聚类算法AGNES和一种分裂的层次聚类算法DIANA。具体可以看一看示例。
对于分裂和凝聚来说,可能会遇到的最大问题是在合并或分裂点的选择方法上遇到困难,这种决定是至关重要的,引文一旦对象的组群被合并或被分裂,则下一步处理将在新产生的簇上进行。它既不会撤销先前所在工作,也不会在簇之间进行对象交换。因此,如果合并和分裂点选择不当的话,那么很有可能会产生低质量的聚类。
其实,就这种操作方法,我们应该很容易想到。相对于凝聚来说,分裂产生低质量聚类的概率要大得多。
因此在实际中,也是凝聚比分裂用得多得多。
凝聚和分裂算法的距离度量
不管是凝聚还是分裂,一个核心问题是度量两个簇之间的距离,其中每个簇是一般是一个对象集。
4个最常用的聚类度量在P300中部给出了,其中值得特别关注的是最小距离和最大距离。
当算法使用最小距离时,被称为单连接算法;当算法使用最大距离时,被称为全连接算法。
单连接和全连接的构造在P300中下部做了论述,看下,应该不难理解。
根据这两种构造过程,我们可以发现,单连接趋向于发现由局部邻近性定义的分层的簇,而全连接则趋向发现由全局邻近性选择的簇。
提高层次方法的聚类质量
前面说到,在凝聚和分裂时,合并点和分裂点的选择是至关重要的。因此,如果合并和分裂选择不当,则很有可能会产生低质量的簇,而一种提高层次方法聚类质量的方向是集成层次聚类与其他聚类技术,这种聚类方法被称为多阶段聚类。
这里介绍两种多阶段聚类算法:BIRCH和Chameleon。
BIRCH
我认为书上写得不是很好理解,建议同志们参看这篇文章,写的非常好。
BIRCH聚类算法原理
Chameleon
这个算法比较好理解,性能也是比较强大,相比BIRCH只适用于球形或类球形来说,Chameleon能发现各种各样形状的,高质量的簇。这得益于它对簇的两个考察指标:相对互联度RI和相对接近的RC。
书上写的也很清楚,参考下这篇文章认识会深一些。
Chameleon两阶段聚类算法
层次方法中的概率方法
纵观层次方法中的算法方法,凝聚和分裂是使用连接度量(距离??)BIRCH也是连接度量(回想一下CF树),Chameleon同样是连接度量(相对互连度和相对接近度),这些方法往往使得聚类容易理解并且也特别有效,因为它能够反映在具体的数字上。
但是,他同样存在一些缺点。例如
1、到底哪种距离度量合适呢??
2、假如有缺失的属性值,那么距离度量要如何计算??
3、一定采用启发式的局部逼近,得到的符合全局最优吗?
所以,因为有这么多种不确定的因素存在,我们需要一些新的思路。
大家注意到我特别强调了不确定这个词,那么这种处理“不确定”或者说“可能”最直接的方法当然就是用概率了。
这里提出一种用概率来看待聚类问题的方法是:把待聚集的数据看作是一个样本,通过聚类样本来尽可能准确的估计总体。
这里有一个很重要的度量指标是:聚类质量。
而聚类质量体现在总体的分布函数上。
具体来说就是,如果样本的聚类质量越高,则总体的生成模型就越接近某种分布函数(高斯分布,伯努利分布)
具体做法是这样的

这里出现的log指的就是聚类质量。对这个公式不太理解的,看看书。
P306,提到了该方法处理属性缺失值的方法
层次方法之贝叶斯方法
P306。
学习了解了这一块儿之后,目前我对使用概率来进行层次聚类没看出有什么很不一样的地方。对于之前提到的诸如属性值缺失这些问题,我认为完全可以在数据预处理阶段进行处理呀,这样在聚类阶段就可以使用距离来度量了嘛。毕竟距离度量很灵活,即便使用最基础的欧式距离,也很准确。目前,我看不出概率的独到性所在。
密度方法
回顾划分和层次方法,对于发现非球状类型的簇,我们貌似只看到Chameleon有这个强大的功能。
这里引入基于密度的聚类方法,这类方法不仅能发现任意形状的簇,而且先天的对噪声和离群点不敏感。
这里介绍三种代表性方法,DBSCAN,OPTICS,DENCLUE。
DBSCAN
DBSCAN的思路其实挺简单的,书上用了核心对象,密度可达和密度相连这几个概念来阐述。这几个概念平常没有接触过,可能有点陌生。但是其很也很好理解。理清了这几个概念之后,看书上P309,10.4.2也就容易了。
这篇文章补缺了书上很多没提到的知识点。
DBSCAN聚类原理
值得注意的是,大家在看到书P308图10.14的时候,容易过分具象化簇了。为什么这么说呢?因为一般的讲义都是把簇画成圆形,并且给出了核心点和半径。这样便于大家理解算法的思想。但实际上,大家要注意。DBSCAN是可以发现任意形状的簇的,因此这个簇基本上都不是圆形了,而且这个半径实际上是一个阀值。判断一个点是否在它的半径内,实际上还是通过计算距离来判断的。
上面给出的参考文章就明确的提到了这一点。
DBSCAN算法需要选择一种距离度量,对于待聚类的数据集中,任意两个点之间的距离,反映了点之间的密度,说明了点与点是否能够聚到同一类中。由于DBSCAN算法对高维数据定义密度很困难,所以对于二维空间中的点,可以使用欧几里德距离来进行度量。
此外,DBSCAN算法需要用户输入半径和阀值。前面也提到过,要求用户输入参数基本上都是不靠谱的,这里DBSCAN算法经过反复的实验,给出了一般的标准化参数,即半径=4,阀值=4。
具体,参数值是如何确定的,DBSCAN也是采用了一般的处理方法。而具体是什么,因为该处理方法是比较通用的,所以放到本章最后再来说。
OPTICS算法
在DBSCAN算法中,我们知道该算法需要用户输入半径和阀值。这显然是不靠谱的,虽然我们可以通过其他方法来优化参数的选择,但这其实不是最好的做法。
这里为了克服在聚类分析中使用一组全局参数的缺点,这里提出了OPTICS算法。
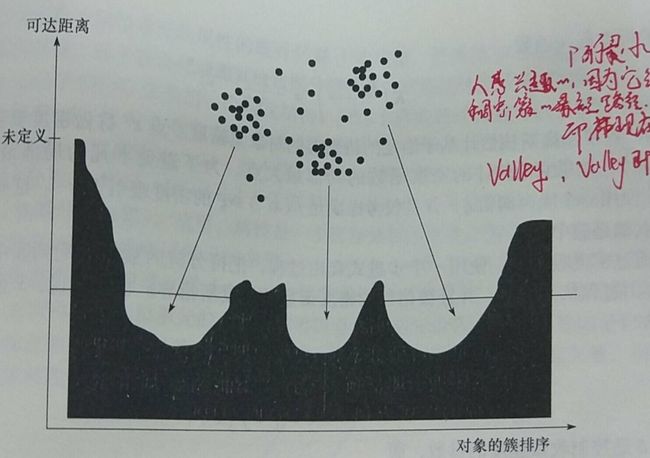
该算法的牛逼之处在于:它并不显示地产生数据集聚类,而是为聚类分析生成一个增广的簇排序(如以样本点输出次序为横轴,以可达距离为纵轴的坐标图)。那么这个排序就厉害了,它代表了各样本点基于密度的聚类结构,它包含的信息等价于从一个广泛的参数设置所获得的基于密度的聚类。换句话说,从这个排序中可以得到基于任何半径和任何阀值的聚类。
回头看看上面那句话,我“使用”一个广泛的参数来克服你使用一组全局参数带来的缺点。OPTICS算法有点儿上帝视角的味道了。
OK,现在我们来看到底什么是OPTICS算法。
要搞清楚OPTICS算法,同DBSCAN算法一样,需要搞清楚这么几个概念的定义,即:半径、阀值,核心点,核心距离,可达距离,最小可达距离等。
这里的大部分概念在DBSCAN中都已经解释清楚了。这里着重理解下核心距离和可达距离。P310,例10.8对这两个概念做了详细的解释。
搞清楚概念之后,其实就很简单了。
我认为,OPTICS的核心思想无外乎这两句话
1、较稠密簇中的对象在簇排序中相互靠近;
2、一个对象的最小可达距离给出了一个对象连接到一个稠密簇的最短路径。
这两句话,可能一时半会儿体会不到它的意义。
那我们先来看看具体咋做
算法:OPTICS
输入:样本集D, 邻域半径E, 给定点在E领域内成为核心对象的最小领域点数MinPts
输出:具有可达距离信息的样本点输出排序
方法:
1、创建两个队列,有序队列和结果队列。(有序队列用来存储核心对象及其该核心对象的直接可达对象,并按可达距离升序排列;结果队列用来存储样本点的输出次序。你可以把有序队列里面放的理解为待处理的数据,而结果队列里放的是已经处理完的数据);
2、如果所有样本集D中所有点都处理完毕,则算法结束。否则,选择一个未处理(即不在结果队列中)且为核心对象的样本点,找到其所有直接密度可达样本点,如过该样本点不存在于结果队列中,则将其放入有序队列中,并按可达距离排序;
3、如果有序队列为空,则跳至步骤2(重新选取处理数据)。否则,从有序队列中取出第一个样本点(即可达距离最小的样本点)进行拓展,并将取出的样本点保存至结果队列中(如果它不存在结果队列当中的话)。然后进行下面的处理。
3.1.判断该拓展点是否是核心对象,如果不是,回到步骤3(因为它不是核心对象,所以无法进行扩展了。那么就回到步骤3里面,取最小的。这里要注意,第二次取不是取第二小的,因为第一小的已经放到了结果队列中了,所以第二小的就变成第一小的了。)。如果该点是核心对象,则找到该拓展点所有的直接密度可达点;
3.2.判断该直接密度可达样本点是否已经存在结果队列,是则不处理,否则下一步;
3.3.如果有序队列中已经存在该直接密度可达点,如果此时新的可达距离小于旧的可达距离,则用新可达距离取代旧可达距离,有序队列重新排序(因为一个对象可能直接由多个核心对象可达,因此,可达距离近的肯定是更好的选择);
3.4.如果有序队列中不存在该直接密度可达样本点,则插入该点,并对有序队列重新排序;
4、迭代2,3。
5、算法结束,输出结果队列中的有序样本点。
认真学了了DBSCAN算法,肯定会对OPTICS算法感到熟悉。因为这两个算法的推进过程基本上是完全一样的。
OK,对照算法,再回想一下我说的那两句话。
1、较稠密簇中的对象在簇排序中相互靠近;
2、一个对象的最小可达距离给出了一个对象连接到一个稠密簇的最短路径。
是不是体会更深刻了一些?
OPTICS全称是Ordering points to identify the clustering structure 。翻译过来就是,对点排序以此来确定簇结构。实际上,我觉得这个名字就点出了这个算法很多东西了。
最后,参考Wiki上的图,来具体感受下OPTICS最后跑出来的结果。

多的不说,直说下面几点
1、X轴代表OPTICS算法处理点的顺序,y轴代表可达距离。
2、簇在坐标轴中表述为凹陷(山谷??Valley),并且凹陷越深,簇越紧密
3、黄色代表的是噪声,它们不形成任何凹陷。
在最开始就已经说了,OPTICS是用的广泛的参数。
当你需要提取聚集的时候,参考Y轴和图像,自己设定一个阀值就可以提取聚集了。这里将阀值设为0.1就挺合适的。
再来一张凹陷明显的
DENCLUE
目前不是太理解
基于网格的方法
参考这篇文章吧
聚类评估
书上写得就挺简单的