python量化交易笔记---14.随机变量
随机变量用大写字母来表示,如 X X X,其具体的观测值用小写字母来表示,如 x x x。我们希望通过观测到的结果,来推断出随机变量的真实分布。根据随机变量的取值,分为离散随机变量和连续随机变量,在量化交易中,绝大多数数据都是连续随机变量。
1.概率与概率分布
1.1.离散型随机变量
假设离散型随机变量 X X X,其所有取值的集合为 { a k } , k = 1 , 2 , 3 , . . . \{a_k\}, k=1,2,3,... {ak},k=1,2,3,...,我们定义 X X X的概率质量函数为:
f X ( a k ) = P { X = a k } , k = 1 , 2 , 3 , . . . f_{X}(a_k)=P\{ X=a_k \}, k=1, 2, 3, ... fX(ak)=P{X=ak},k=1,2,3,...
累积概率分布函数定义为:
F X ( a ) = P { X ≤ a } = ∑ i : a i ≤ a f X ( a i ) F_{X}(a)=P\{X \le a\}=\sum_{i:a_{i} \le a}f_{X}(a_{i}) FX(a)=P{X≤a}=i:ai≤a∑fX(ai)
我们假设随机变量 X X X可以取的值为 { 1 , 2 , 3 , 4 , 5 } \{1, 2, 3, 4, 5\} {1,2,3,4,5},对应的概率为: { 0.1 , 0.1 , 0.3 , 0.3 , 0.2 } \{0.1, 0.1, 0.3, 0.3, 0.2\} {0.1,0.1,0.3,0.3,0.2},根据此分布我们生成1000个点,打印出每个数值出现的概率和直方图,代码如下所示:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def startup():
''' 数据位置分析 '''
num = 1000
data = np.random.choice([1, 2, 3, 4, 5], size=num, replace=True, p=[0.1, 0.1, 0.3, 0.3, 0.2])
xs = pd.Series(data)
print(xs.value_counts() / num)
plt.hist(xs)
plt.show()
if '__main__' == __name__:
startup()
运行结果为:

1.2.连续型随机变量
连续型随机变量取某个具体值的概率为0,即: P X ( X = a k ) = 0 P_{X}(X=a_{k})=0 PX(X=ak)=0。
累积分布函数定义:
F X ( a ) = P X { X ≤ a } = ∫ − ∞ a f X ( x ) d x F_{X}(a)=P_{X}\{ X \le a \}=\int_{-\infty}^{a}f_{X}(x)dx FX(a)=PX{X≤a}=∫−∞afX(x)dx
概率密度函数定义:
f X ( x ) = d F X ( x ) d x f_{X}(x)=\frac{dF_{X}(x)}{dx} fX(x)=dxdFX(x)
下面我们以2014年沪深300指数日收益率为例,绘制出其概率密度函数和累积分布函数的曲线,数据格式为:
代码如下所示:
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
def startup():
data = pd.read_csv('../datas/return300.csv')
f_x = stats.kde.gaussian_kde(data.iloc[:, 1])
bins = np.arange(-5, 5, 0.02)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.subplot(211)
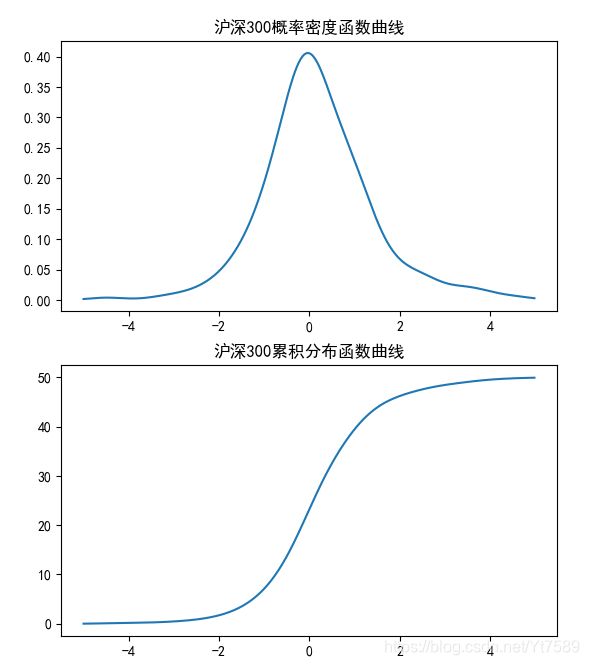
plt.title('沪深300概率密度函数曲线')
plt.plot(bins, f_x(bins))
plt.subplot(212)
plt.title('沪深300累积分布函数曲线')
plt.plot(bins, f_x(bins).cumsum())
plt.show()
if '__main__' == __name__:
startup()
运行结果如下所示:
2.期望与方差
2.1.离散随机变量
期望定义为:
E ( X ) = ∑ k a k f X ( a k ) = ∑ k a k P { X = a k } E(X)=\sum_{k}a_{k}f_{X}(a_{k})=\sum_{k}a_{k}P\{ X=a_{k} \} E(X)=k∑akfX(ak)=k∑akP{X=ak}
方差定义为:
V a r ( X ) = E [ X − E ( X ) ] 2 = ∑ k [ a k − E ( X ) ] 2 P { X = a k } Var(X)=E[X-E(X)]^{2}=\sum_{k}[a_{k}-E(X)]^{2}P\{ X=a_{k} \} Var(X)=E[X−E(X)]2=k∑[ak−E(X)]2P{X=ak}
光讲概念比较抽象,下面以伯努利分布为例。假设随机变量 X X X服从伯努利分布,只能取值0或者1,其概率质量函数定义为:
f X ( x ) = P { X = x } = { p , x = 1 1 − p , x = 0 f_{X}(x)=P\{ X=x \}=\begin{cases} p,\quad x=1\\ 1-p, \quad x=0 \end{cases} fX(x)=P{X=x}={p,x=11−p,x=0
其希望值为:
E ( X ) = ∑ k a k P { X = a k } = 1 ⋅ P { X = 1 } + 0 ⋅ P { X = 0 } = 1 ⋅ p + 0 ⋅ ( 1 − p ) = p E(X)=\sum_{k}a_{k}P\{ X=a_{k} \}=1 \cdot P\{ X=1 \} + 0 \cdot P\{ X=0 \}=1 \cdot p + 0 \cdot (1-p)=p E(X)=k∑akP{X=ak}=1⋅P{X=1}+0⋅P{X=0}=1⋅p+0⋅(1−p)=p
方差为:
V a r ( X ) = ∑ k [ a k − E ( X ) ] 2 P { X = a k } = ( 1 − p ) 2 P { X = 1 } + ( 0 − p ) 2 P { X = 0 } = ( 1 − p ) 2 p + p 2 ( 1 − p ) = ( 1 − p ) p Var(X)=\sum_{k}[a_{k}-E(X)]^{2}P\{ X=a_{k} \}=(1-p)^{2}P\{ X=1 \}+(0-p)^{2}P\{ X=0 \}\\ =(1-p)^{2}p + p^{2}(1-p)=(1-p)p Var(X)=k∑[ak−E(X)]2P{X=ak}=(1−p)2P{X=1}+(0−p)2P{X=0}=(1−p)2p+p2(1−p)=(1−p)p
2.2.连续随机变量
期望定义:
E ( X ) = ∫ − ∞ ∞ x f X ( x ) d x E(X)=\int_{-\infty}^{\infty}x f_X(x)dx E(X)=∫−∞∞xfX(x)dx
方差定义为:
V a r ( X ) = ∫ − ∞ ∞ [ x − E ( X ) ] 2 f X ( x ) d x Var(X)=\int_{-\infty}^{\infty} \big[ x - E(X) \big]^{2} f_{X}(x)dx Var(X)=∫−∞∞[x−E(X)]2fX(x)dx
3.二项分布
我们把伯努利变量多次观察值的过程称之为伯努利过程。假设随机变量 Y i Y_{i} Yi代表第 i i i次观察时 Y Y Y取值为1或0的值,我们进行n次试验,每次实验中 Y i Y_{i} Yi为1的概率为p,将 Y i Y_{i} Yi为1的次数用随机变量 X ∼ b ( n , p ) X \sim b(n, p) X∼b(n,p)表示:
X = ∑ i = 1 n Y i , X ∈ 0 , 1 , 2 , . . . , n X=\sum_{i=1}^{n}Y_{i}, \quad \quad X \in {0, 1, 2, ..., n} X=i=1∑nYi,X∈0,1,2,...,n
3.1.性质
3.1.1.概率密度函数
f X ( k ) = P { X = k } = C n k ⋅ p k ⋅ ( 1 − p ) n − k C n k = n ! k ! ⋅ ( n − k ) ! f_{X}(k)=P\{ X=k \}=C_{n}^{k} \cdot p^{k} \cdot (1-p)^{n-k}\\ C_{n}^{k}=\frac{n!}{k! \cdot (n-k)!} fX(k)=P{X=k}=Cnk⋅pk⋅(1−p)n−kCnk=k!⋅(n−k)!n!
表示在n次试验中,有 k k k次 Y i Y_{i} Yi值为1的概率。
3.1.2.期望
E ( X ) = n p E(X)=np E(X)=np
3.1.3.方差
V a r ( x ) = n p ( 1 − p ) Var(x)=np(1-p) Var(x)=np(1−p)
3.2.Python程序实现
程序如下所示:
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
def startup():
n = 100
p = 0.5
count = 20
datas = np.random.binomial(n, p, count)
print(datas)
k = 20
f_X = stats.binom.pmf(k, n, p)
print('概率质量函数(20次正面概率):{0}'.format(f_X))
F_X = stats.binom.pmf(np.arange(0, 21, 1), n, p).sum()
print('累积分布函数(小于等于20次正面概率)1:{0}'.format(F_X))
F_X2 = stats.binom.cdf(k, n, p)
print('累积分布函数(小于等于20次正面概率)2:{0}'.format(F_X2))
if '__main__' == __name__:
startup()
运行结果如下所示:

3.3.金融应用
在金融分析领域,如果我们设定收益率为正时为1,否则为0,就可以将其视为二项分布。我们还以沪深300在2014年的收益率为例,交易日为245天,相当于做了245次试验,我们可以求出收益率为正(即为1)的概率,我们就可以预测接下来10天收益率为正的概率,程序如下所示:
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
def startup():
data = pd.read_csv('../datas/return300.csv')
ror = data.iloc[:, 1]
p = len(ror[ror>0]) / len(ror)
print('p={0}'.format(p))
n = 10
k = 6
print('10天中6天上涨概率:{0}'.format(stats.binom.pmf(k, n, p)))
if '__main__' == __name__:
startup()
运行结果为:

4.正态分布
4.1.正态分布定义
对于连续型随机变量,正态分布又叫高斯分布,是自然界中广泛存在的一种分布,在金融和社会科学领域,也有很多应用场景。随机变量 X X X服从希望为 μ \mu μ和方差为 σ 2 \sigma ^{2} σ2的正态分布表示为: X ∼ N ( μ , σ 2 ) , X ∈ ( − ∞ , ∞ ) X \sim N(\mu, \sigma ^{2}), X \in (-\infty, \infty) X∼N(μ,σ2),X∈(−∞,∞)。
概率密度函数定义:
f X ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 f_{X}(x)=\frac{1}{\sqrt{2 \pi \sigma}} e^{-\frac{(x-\mu)^{2}}{2\sigma ^{2}}} fX(x)=2πσ1e−2σ2(x−μ)2
下面程序画出三个正态分布的曲线:
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
def gaussian(mu, sigma, x):
sigma2 = sigma ** 2
return 1/np.sqrt(2*np.pi*sigma)*np.exp(-(x-mu)**2 / (2*sigma2))
def startup():
x = np.linspace(-5, 7, 1000)
# mu=0, sigma=1
mu = 0
sigma = 1
y1 = gaussian(mu, sigma, x)
plt.plot(x, y1)
# mu=0, sigma = 2
mu = 0
sigma = 2
y2 = gaussian(mu, sigma, x)
plt.plot(x, y2)
# mu = 1, sigma = 5
mu = 2
sigma = 3
y3 = gaussian(mu, sigma, x)
plt.plot(x, y3)
plt.show()
if '__main__' == __name__:
startup()
运行结果为:

4.2.正态分布规一化
可以将任意的正态分布 X ∼ N ( μ , σ 2 ) X \sim N(\mu, \sigma ^{2}) X∼N(μ,σ2)转化为标准正态分布 Z ∼ N ( 0 , 1 ) Z \sim N(0, 1) Z∼N(0,1),其统计性质不变:
Z = x − μ σ Z=\frac{x-\mu}{\sigma} Z=σx−μ
4.3.正态分布金融上的应用
还以沪深300指数2014年日收益率数据库例,假设我们想要估计在其后的一天(2015-01-05)亏损在95%的情况下不会超过多少?假设我们认为沪深300指数2014年日收益率符合正态分布,我们可以先求出正态分布的参数:均值、方差,然后这个值,代码如下所示:
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
def startup():
data = pd.read_csv('../datas/return300.csv')
ror = data.iloc[:, 1]
mu = ror.mean()
print('均值:{0}'.format(mu))
sigma = ror.var()
stdval = ror.std()
print('方差:{0}; 标准差:{1}'.format(sigma, stdval))
loss = stats.norm.ppf((1-0.95), mu, stdval)
print('95%的情况下亏损不会高于:{0}%'.format(-loss))
if '__main__' == __name__:
startup()
运行结果为:

5.变量的关系
在金融分析中,我们通常需要考察股票对、营收与收益率等之间的关系,我们就需要研究变量间的关系。
5.1.联合概率分布
5.1.1.定义
对于随机变量 X X X和 Y Y Y,其所有可能取值集合分别为 { x i } \{ x_{i} \} {xi}和 { y j } \{y_{j}\} {yj},其中 i , j = 1 , 2 , 3 , . . . i,j=1, 2, 3, ... i,j=1,2,3,...的值,则 X X X和 Y Y Y的联合概率质量函数定义为:
f X , Y ( x i , y j ) = P { X = x i 且 Y = y j } , i , j = 1 , 2 , 3 , . . . f_{X,Y}(x_{i}, y_{j})=P\{ X=x_{i}且Y=y_{j} \}, \quad i,j = 1, 2, 3, ... fX,Y(xi,yj)=P{X=xi且Y=yj},i,j=1,2,3,...
随机变量 X X X和 Y Y Y的联合累积分布函数定义为:
F X , Y ( x , y ) = P { X ≤ x 且 Y ≤ y } F_{X,Y}(x, y)=P\{ X \le x且 Y \le y \} FX,Y(x,y)=P{X≤x且Y≤y}
5.1.2.离散型
F X , Y ( x , y ) = ∑ i : x i ≤ x ∑ j : y j ≤ y P { X = x i 且 Y = y j } = ∑ i : x i ≤ x ∑ j : y j ≤ y f X , Y ( x i , y j ) F_{X,Y}(x,y)=\sum_{i:x_{i} \le x} \sum_{j:y_{j} \le y} P\{ X=x_{i} 且 Y=y_{j} \}\\ =\sum_{i:x_{i} \le x} \sum_{j:y_{j} \le y} f_{X,Y}(x_{i}, y_{j}) FX,Y(x,y)=i:xi≤x∑j:yj≤y∑P{X=xi且Y=yj}=i:xi≤x∑j:yj≤y∑fX,Y(xi,yj)
边际概率函数定义为:
f X ( x i ) = ∑ j f X , Y ( x i , y j ) f_{X}(x_{i})=\sum_{j} f_{X,Y}(x_{i}, y_{j}) fX(xi)=j∑fX,Y(xi,yj)
期望值定义为:
E ( X ) = ∑ i ∑ j x i ⋅ f X , Y ( x i , y j ) = ∑ i x i ∑ j f X , Y ( x i , y j ) = ∑ i x i ⋅ f X ( x i ) E(X)=\sum_{i} \sum_{j}x_{i} \cdot f_{X,Y}(x_{i}, y_{j})=\sum_{i}x_{i}\sum_{j}f_{X,Y}(x_{i}, y_{j})\\ =\sum_{i}x_{i} \cdot f_{X}(x_{i}) E(X)=i∑j∑xi⋅fX,Y(xi,yj)=i∑xij∑fX,Y(xi,yj)=i∑xi⋅fX(xi)
同理可以求出E(Y),这里就不再给出证明了。
5.1.3.连续型
累积分布函数定义为:
F X , Y ( a , b ) = ∫ − ∞ ∞ ∫ − ∞ ∞ f X , Y ( x , y ) d x d y F_{X,Y}(a,b)=\int_{-\infty}^{\infty} \int_{-\infty}^{\infty} f_{X,Y}(x,y)dxdy FX,Y(a,b)=∫−∞∞∫−∞∞fX,Y(x,y)dxdy
概率密度函数比较复杂,这里就不再讲述了。
5.2.变量的独立性
随机变量 X X X和 Y Y Y的联合累积分布函数满足:
F X , Y ( x , y ) = F X ( x ) ⋅ F Y ( y ) F_{X,Y}(x,y)=F_{X}(x) \cdot F_{Y}(y) FX,Y(x,y)=FX(x)⋅FY(y)
则称随机变量 X X X和 Y Y Y相互独立,同时具有:
f X , Y ( x , y ) = f X ( x ) ⋅ f y ( y ) f_{X,Y}(x,y)=f_{X}(x) \cdot f_{y}(y) fX,Y(x,y)=fX(x)⋅fy(y)
对于离散型随机变量有:
P { X = x 且 Y = y } = P { X = x } ⋅ P { Y = y } P\{X=x且Y=y\}=P\{ X=x \} \cdot P\{ Y=y \} P{X=x且Y=y}=P{X=x}⋅P{Y=y}
5.3.变量的相关性
随机变量 X X X和随机变量 Y Y Y的协方差定义为:
C o v ( X , Y ) = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] Cov(X,Y)=E\bigg[ \big( X-E(X) \big) \big( Y-E(Y) \big) \bigg] Cov(X,Y)=E[(X−E(X))(Y−E(Y))]
协方差具有如下性质:
C o v ( X , Y ) = C o v ( Y , X ) C o v ( a X , b Y ) = a b C o v ( X , Y ) a , b 为 常 数 C o v ( X 1 + X 2 , Y ) = C o v ( X 1 , Y ) + C o v ( X 2 , Y ) Cov(X,Y)=Cov(Y,X)\\ Cov(aX,bY)=abCov(X,Y) \quad \quad a,b为常数\\ Cov(X_{1}+X_{2},Y)=Cov(X_{1}, Y)+Cov(X_{2}, Y) Cov(X,Y)=Cov(Y,X)Cov(aX,bY)=abCov(X,Y)a,b为常数Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y)
协方差大小不具有直接可比性,因此我们定义相关系数:
ρ X , Y = C o v ( X , Y ) σ X σ Y \rho _{X,Y}=\frac{Cov(X,Y)}{\sigma _{X} \sigma _{Y}} ρX,Y=σXσYCov(X,Y)
其取值为 [ − 1 , 1 ] [-1,1] [−1,1]。 ρ \rho ρ为正数时值越大,则表明 X X X增大 Y Y Y增大的越明显; ρ \rho ρ为负数时值越小,则表明 X X X增大时 Y Y Y减小越明显。
5.4.相关性分析举例
我们以上证综指和深证综指日收益率数据为例,来分这两个指数的相关性。程序如下所示:
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
def startup():
data = pd.read_table('../datas/TRD_Index.txt')
shIndex = data[data.Indexcd==1] # 上证综指编号为1
szIndex = data[data.Indexcd==399106] # 深证综指编号为399106
# 计算相关系数
szIndex.index = shIndex.index
rho = szIndex.Retindex.corr(shIndex.Retindex)
# 绘制相关性图形
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title('上证综指与深证综指相关性(rho={0})'.format(rho))
plt.xlabel('上证综指')
plt.ylabel('深证综指')
plt.scatter(shIndex.Retindex, szIndex.Retindex)
plt.show()
if '__main__' == __name__:
startup()
运行结果为:

由上图可以看出,深证综指和上证综指从图形上看几乎形成一个直线,而相关系数为0.9,证明这二者之间存在非常强的正相关性。