牛客 - Java专项练习题知识点整理(三)
目录
Java 8内存结构
GC垃圾回收机制
堆内存设置(JDK7)
Java包命名规范
Integer对象方法
会话跟踪
运算符
面向对象五大基本原则
序列化
try-catch-finally 规则 - 异常处理语句的语法规则
Java*.exe
接口实现原则
int和Integer的比较
内联函数
new String(str.getBytes(“gbk”),“UTF-8”)
Java 8内存结构
以前一直认为 内存结构 = 内存模型,直到看到了这篇文章 求你了,再问你Java内存模型的时候别再给我讲堆栈方法区了… ,现纠正一下。
Java内存模型(Java Memory Model ,JMM)就是一种符合内存模型规范的,屏蔽了各种硬件和操作系统的访问差异的,保证了Java程序在各种平台下对内存的访问都能得到一致效果的机制及规范。目的是解决由于多线程通过共享内存进行通信时,存在的原子性、可见性(缓存一致性)以及有序性问题。
下面正式介绍一下Java 8的内存结构。
1.8同1.7比,最大的差别就是:元数据区取代了永久代。
包括:堆、虚拟机栈、本地方法栈、程序计数器、元数据区
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元数据空间并不在虚拟机中,而是使用本地内存。
1.8后,字符串常量池从永久代中剥离出来,存放在堆中。

1. 程序计数器
每个线程一块,指向当前线程正在执行的字节码代码的行号。如果当前线程执行的是native方法,则其值为null。
2. 虚拟机栈

线程私有,生命周期与线程同进同退。每个Java方法在被调用的时候都会创建一个栈帧,并入栈。一旦完成调用,则出栈。所有的的栈帧都出栈后,线程也就完成了使命。
每个栈帧存储局部变量表、操作数栈、动态链接、方法出口信息。其中局部变量表包括八大基本类型、对象引用、returnAddress
3. 本地方法栈
功能与Java虚拟机栈十分相同。区别在于,本地方法栈为虚拟机使用到的native方法服务。
4. 堆

堆是JVM内存占用最大,管理最复杂的一个区域。其唯一的用途就是存放对象实例:所有的对象实例及数组都在堆上进行分配。1.8后,字符串常量池从永久代中剥离出来,存放在堆中。
5. 元数据区
元数据区取代了1.7版本及以前的永久代。元数据区和永久代本质上都是方法区的实现。方法区存放虚拟机加载的类信息,静态变量,常量等数据。
GC垃圾回收机制
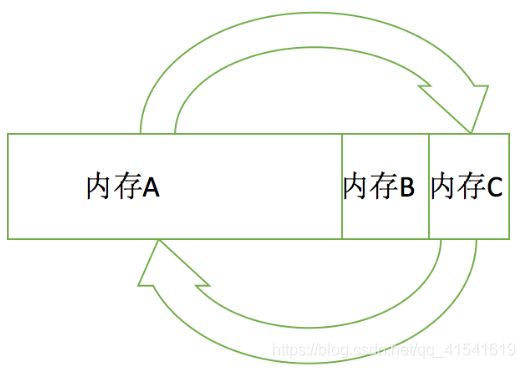
工作原理如下:
1. 首先,Eden区最大,对外提供堆内存。当 Eden 区快要满了,则进行 Minor GC,把存活对象放入From Survivor 区,清空 Eden 区;
2. Eden区被清空后,继续对外提供堆内存;
3. 当 Eden 区再次被填满,此时对 Eden 区和 From Survivor 区同时进行 Minor GC,把存活对象放入 To Survivor 区,同时清空 Eden 区和From Survivor区;
4. Eden区继续对外提供堆内存,并重复上述过程,即在 Eden 区填满后,把 Eden 区和某个 Survivor 区的存活对象放到另一个 Survivor 区;
5. 当某个 Survivor 区被填满,且仍有对象未被复制完毕时,或者某些对象在反复 Survive 15 次左右时,则把这部分剩余对象放到Old 区;
6. 当 Old 区也被填满时,进行 Major GC)(Full GC),对 Old 区进行垃圾回收。
老年代和持久代都是Full GC
[ 注意,在真实的 JVM 环境里,可以通过参数 SurvivorRatio 手动配置 Eden 区和单个 Survivor 区的比例,默认为 8:1:1 ]
堆内存设置(JDK7)
1. 原理
JVM堆内存分为2块:Permanent Space 和 Heap Space。
Permanent 即 持久代(Permanent Generation),主要存放的是Java类定义信息,与垃圾收集器要收集的Java对象关系不大。如:存放虚拟机加载的类信息,静态变量,常量等数据。
(1)类的方法(字节码...)
(2)类名(Sring对象)
(3).class文件读到的常量信息
(4)class对象相关的对象列表和类型列表 (e.g., 方法对象的array).
(5)JVM创建的内部对象
(6)JIT编译器优化用的信息
Heap = { Old + NEW = {Eden, from, to} },Old 即 年老代(Old Generation),New 即 年轻代(Young Generation)。年老代和年轻代的划分对垃圾收集影响比较大。
2. 年轻代Eden
所有新生成的对象首先都是放在年轻代。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。年轻代一般分3个区,1个Eden区,2个Survivor区(from 和 to)。
大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当一个Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当另一个Survivor区也满了的时候,从前一个Survivor区复制过来的并且此时还存活的对象,将可能被复制到年老代。
2个Survivor区是对称的,没有先后关系,所以同一个Survivor区中可能同时存在从Eden区复制过来对象,和从另一个Survivor区复制过来的对象;而复制到年老区的只有从另一个Survivor区过来的对象。而且,因为需要交换的原因,Survivor区至少有一个是空的。特殊的情况下,根据程序需要,Survivor区是可以配置为多个的(多于2个),这样可以增加对象在年轻代中的存在时间,减少被放到年老代的可能。
针对年轻代的垃圾回收即 Young GC(Minor GC)。
3. 年老代
在年轻代中经历了N次(可配置)垃圾回收后仍然存活的对象,就会被复制到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
针对年老代的垃圾回收即 Full GC。
4. 持久代(JDK8 被替换为元数据区)
用于存放静态类型数据,如 Java Class, Method 等。持久代对垃圾回收没有显著影响。但是有些应用可能动态生成或调用一些Class,例如 Hibernate CGLib 等,在这种时候往往需要设置一个比较大的持久代空间来存放这些运行过程中动态增加的类型。
5. 所以,当一组对象生成时,内存申请过程如下:
(1)JVM会试图为相关Java对象在年轻代的Eden区中初始化一块内存区域。当Eden区空间足够时,内存申请结束。否则执行下一步。
(2)JVM试图释放在Eden区中所有不活跃的对象(Young GC | Minor GC)。释放后若Eden空间仍然不足以放入新对象,JVM则试图将部分Eden区中活跃对象放入Survivor区。
(3)Survivor区被用来作为Eden区及年老代的中间交换区域。
(4)当年老代空间足够时,Survivor区中存活了一定次数的对象会被移到年老代。当年老代空间不够时,JVM会在年老代进行完全的垃圾回收(Full GC)。
(5)Full GC后,若Survivor区及年老代仍然无法存放从Eden区复制过来的对象,则会导致JVM无法在Eden区为新生成的对象申请内存,即出现“Out of Memory”。
6. OOM(“Out of Memory”)异常一般主要有如下2种原因:
(1)年老代溢出,表现为:java.lang.OutOfMemoryError:Javaheapspace
这是最常见的情况,产生的原因可能是:设置的内存参数Xmx过小或程序的内存泄露及使用不当问题。
例如:循环上万次的字符串处理、创建上千万个对象、在一段代码内申请上百M甚至上G的内存。还有的时候虽然不会报内存溢出,却会使系统不间断的垃圾回收,也无法处理其它请求。这种情况下除了检查程序、打印堆内存等方法排查,还可以借助一些内存分析工具,比如MAT就很不错。
(2)持久代溢出,表现为:java.lang.OutOfMemoryError:PermGenspace
通常由于持久代设置过小,动态加载了大量Java类而导致溢出 ,解决办法唯有将参数 -XX:MaxPermSize 调大(一般256m能满足绝大多数应用程序需求)。将部分Java类放到容器共享区(例如Tomcat share lib)去加载的办法也是一个思路,但前提是容器里部署了多个应用,且这些应用有大量的共享类库
Java包命名规范
java规范中包名一般是小写的;
类名一般是大写的;
System是类名 java.lang.System,out是System的成员,println是方法名
Integer对象方法
| Integer.parseInt("") |
将字符串类型转换为int的基础数据类型 |
| Integer.valueOf("") |
将字符串类型数据转换为Integer对象 |
| Integer.intValue() |
将Integer对象中的数据取出,返回一个基础数据类型int |
会话跟踪
会话跟踪是一种灵活、轻便的机制,它使Web上的状态编程变为可能。
HTTP是一种无状态协议,每当用户发出请求时,服务器就会做出响应,客户端与服务器之间的联系是离散的、非连续的。当用户在同一网站的多个页面之间转换时,根本无法确定是否是同一个客户,会话跟踪技术就可以解决这个问题。当一个客户在多个页面间切换时,服务器会保存该用户的信息。
有四种方法可以实现会话跟踪技术:URL重写、隐藏表单域、Cookie、Session。
1. 隐藏表单域
,非常适合不需要大量数据存储的会话应用。
2. URL 重写
URL 可以在后面附加参数,和服务器的请求一起发送,这些参数为名字/值对。
3. Cookie
一个 Cookie 是一个小的,已命名数据元素。服务器使用 SET-Cookie 头标将它作为 HTTP
响应的一部分传送到客户端,客户端被请求保存 Cookie 值,在对同一服务器的后续请求使用一个Cookie 头标将之返回到服务器。与其它技术比较,Cookie 的一个优点是在浏览器会话结束后,甚至在客户端计算机重启后它仍可以保留其值。
4. Session
使用 setAttribute(String str,Object obj)方法将对象捆绑到一个会话
运算符
1. <<,有符号左移位,将运算数的二进制整体左移指定位数,低位用0补齐。
2. >>,有符号右移位,将运算数的二进制整体右移指定位数,整数高位用0补齐,负数高位用1补齐(保持负数符号不变)。
3. >>>,无符号右移位,不管正数还是负数,高位都用0补齐(忽略符号位)
面向对象五大基本原则
1. 单一职责原则(Single-Resposibility Principle)
一个类,最好只做一件事,只有一个引起它的变化。单一职责原则可以看做是低耦合、高内聚在面向对象原则上的引申,将职责定义为引起变化的原因,以提高内聚性来减少引起变化的原因。
2. 开放封闭原则(Open-Closed principle)
软件实体应该是可扩展的,而不可修改的。也就是,对扩展开放,对修改封闭的。
3. Liskov替换原则(Liskov-Substituion Principle)
子类必须能够替换其基类。这一思想体现为对继承机制的约束规范,只有子类能够替换基类时,才能保证系统在运行期内识别子类,这是保证继承复用的基础。
4. 依赖倒置原则(Dependecy-Inversion Principle)
依赖于抽象。具体而言就是高层模块不依赖于底层模块,二者都同依赖于抽象;抽象不依赖于具体,具体依赖于抽象。
5. 接口隔离原则(Interface-Segregation Principle)
使用多个小的专门的接口,而不要使用一个大的总接口
序列化
在序列化的时候,被transient或者static修饰的属性,不可以被序列化。
一个类可以被序列化,那么它的子类也可以被序列化。
序列化可以实现深复制,而Object中的clone实现的就只是浅复制。
try-catch-finally 规则 - 异常处理语句的语法规则
1. 必须在 try 之后添加 catch 或 finally 块。try 块后可同时接 catch 和 finally 块,但至少有一个块。
2. 必须遵循块顺序:若代码同时使用 catch 和 finally 块,则必须将 catch 块放在 try 块之后。
3. catch 块与相应的异常类的类型相关。
4. 一个 try 块可能有多个 catch 块。若如此,则执行第一个匹配块。即Java虚拟机会把实际抛出的异常对象依次和各个catch代码块声明的异常类型匹配,如果异常对象为某个异常类型或其子类的实例,就执行这个catch代码块,不会再执行其他的 catch代码块
5. 可嵌套 try-catch-finally 结构。
6. 在 try-catch-finally 结构中,可重新抛出异常。
7. 除了下列情况,总将执行 finally 做为结束: JVM 过早终止(调用 System.exit(int));在 finally 块中抛出一个未处理的异常;计算机断电、失火、或遭遇病毒攻击
由此可以看出,catch只会匹配一个,因为只要匹配了一个,虚拟机就会使整个语句退出。
Java*.exe
| java.exe |
java虚拟机 |
| javadoc.exe |
java document(文档) |
| jdb.exe |
java debug调试 |
| javaprof.exe |
java profile【描述什么的轮廓--》引申】剖析,解释 |
javaprof 资源分析工具,用于分析Java程序在运行过程中调用了哪些资源,包括类和方法的调用次数和时间,以及各数据类型的内存使用情况等.
接口实现原则
两同两小一大
1. 名称相同,参数类型相同
2. 抛出的异常范围 小于 接口定义的范围
3. 返回值类型范围 小于或等于 接口范围
4. 访问权限 大于或等于 接口定义范围
int和Integer的比较
1. 无论如何,Integer与new Integer不会相等。
2. 两个都是非new出来的Integer,如果数在-128到127之间,则是true,否则为false
java在编译Integer i2 = 128的时候,被翻译成-> Integer i2 = Integer.valueOf(128);而valueOf()函数会对-128到127之间的数进行缓存
3. 两个都是new出来的,都为false
4. int和Integer(无论new否)比,都为true,因为会把Integer自动拆箱为int再去比
内联函数
public final void method() {
//TODO something
}1. 在java中使用final关键字来指示一个函数为内联函数;
2. final关键字只是告诉编译器,在编译的时候考虑性能的提升,可以将final函数视为内联函数。 但最后编译器会怎么处理,编译器会分析将final函数处理为内联和不处理为内联的性能比较了;
3. 内联在被调用时,会在调用处直接展开使用,从而提高程序执行速度;
4. 内联不一定好,当被指定为内联的方法体很大时,展开的开销可能就已经超过了普通函数调用的时间,引入了内联反而降低了性能,因为在选择这个关键字应该慎重些,不过,在以后高版本的JVM中,在处理内联时做出了优化,它会根据方法的规模来确定是否展开调用。
new String(str.getBytes(“gbk”),“UTF-8”)
第一步:byte[] bytes= str .getBytes(“gbk”)
告诉java虚拟机将中文以“gbk”的方式转换为字节数组。一个汉字对应2个字节。
第二步:String s=new String(bytes,“utf-8”)
将每2字节组装成一个汉字。此汉字就是第一步 str 代表的汉字。