关于nn.Embedding的解释,以及它是如何将一句话变成vector的
首先我们来看Embedding的参数。
nn.Embedding((num_embeddings,embedding_dim)
其中,num_embeddings代表词典大小尺寸,比如训练时所可能出现的词语一共5000个词,那么就有num_embedding=5000,而embedding_dim表示嵌入向量的维度,即用多少来表示一个符号。提到embedding_dim,就不得先从one_hot向量说起。
最初的时候,人们将word转换位vector是利用one_hot向量来实现的。简单来讲,现在词典里一共5个字,[‘我’,‘是’,‘中’,‘国’,‘人’],即num_embedding=5,而现在有一句话‘我是人’,one_hot则利用一个长度为5的01向量来代表这句话中的每个字(假设词典按顺序编码),有
- 我:[1 0 0 0 0 ]
- 是:[0 1 0 0 0 ]
- 人:[0 0 0 0 1 ]
显然,这种方法简单快捷,但是当词典的字很多,比如50000个字的时候,这种方法会造成极大的稀疏性,不便于计算。而且one_hot方法无法处理原来标签的序列信息,比如“我是人”这句话中,“我”和“人”的距离与“我”和“是”的距离一样,这显然是不合理的。
因此,为了改进这些缺点,embedding算是它的一个升级版(没有说谁好和谁不好的意思,现在one hot向量也依旧在很多地方运用,选择特征时要选择自己合适的才行。)
embedding翻译word是这样操作的,首先,先准备一本词典,这个词典将原来句子中的每个字映射到更低的维度上去。比如,字典中有50000个字,那按照One-hot方法,我们要为每个字建立一个50000长度的vector,对于embedding来说,我们只需要指定一个embedding_dim,这个embedding_dim<50000即可。

见上图,也就是说,原来one-hot处理一句话(这句话有length个字),那我们需要一个(length,50000)的矩阵代表这句话,现在只需要(length,embedding_dim)的矩阵就可以代表这句话。
从数学的角度出发就是(length,50000)*(50000,embedding),做了个矩阵运算。
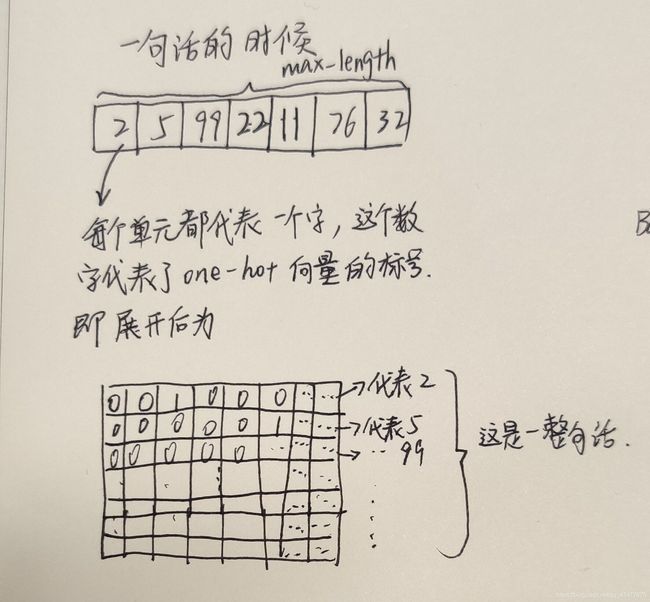
上面这张图是计算示意图,为了方便计算,我们将句子的最大长度设置为max_length,也就是说,输入模型的所有语句不可能超过这个长度。原来用one_hot向量表示的话,如果浓缩起来就是上面的那个长条,如果展开则是下方的那个矩阵。
也就是说,当整个输入数据X只有一句话时
X(1, max_length, num_embeddings)
字典为(num_embeddings, embedding_dim)
则经过翻译之后,这句话变成(1,max_length,embedding_dim)
当输入数据X有多句话时,即Batch_size不等于1,有
X(batch_size, max_length, num_embeddings)
字典为(num_embeddings, embedding_dim)
则经过翻译之后,输入数据X变成(batch_size,max_length,embedding_dim)

因此,nn.embedding(num_embeddings,embedding_dim)的作用就是将输入数据降维到embedding_dim的表示层上,得到了输入数据的另一种表现形式。
代码应用如下
import torch
import numpy as np
batch_size=3
seq_length=4
input_data=np.random.uniform(0,19,size=(batch_size,seq_length))#shape(3,4)
input_data=torch.from_numpy(input_data).long()
embedding_layer=torch.nn.Embedding(vocab_size,embedding_dim)
lstm_input=embedding_layer(input_data)#shape(3,4,6)
注意,输入进embedding层的数据并不是经过词典映射的,而是原始数据,因此张量内部有超出embedding层合法范围的数,这会导致embedding层报错,所以一开始input_data要约束在0,19之间。
且在输入数据的时候,不需要自己手动的将vocab_num给设置出来,这个embedding会自己完成映射。