MySQL、HQL、impala、presto 的语法常见区别(持续更新中)
MySQL、Hive SQL、 presto 语法常见区别
立一个FLAG:等到我有空了再写案例。(20220327)
1、hive 不支持 join的on中用 or连接多个条件,但MySQL和presto支持
hive 联结中on的或条件改写
上面链接给出了hive中怎么用on or,即用union all 或者union来改写语句
2、hive目前,in、not in 是不支持子查询的,MySQL和presto支持
hive in子句中的子查询改写
3、hive不支持limit
在hive中,不支持limit m-1,n的方式,只能用row_number() over(distribute by … sort by … ) rank where rank< (m+n+1) and rank > (m-1)实现。
Mysql中可以用limit m-1, n的限制语法;表中下标从0开始,从第m条记录开始取,一共取n条记录。
hive限制取数数量
4、nullif函数
hive 较低的版本暂时不支持这个函数不支持nullif函数
MySQL和presto支持
NULLIF(exp1,expr2)函数的作用是如果exp1和exp2相等则返回空(NULL),否则返回第一个值。
5、分母为0的问题
hive中分母为0和null均不报错,算出来结果为null
但presto中分母为0报错,为null不报错,用case when判断
6、计算四分位数
hive具有percentile(col,num)函数,presto不支持
hive SQL–hive计算中位数及分位数
7、group by中字段别名
因为MySQL对查询做了增强没有严格遵循SQL的执行顺序,where后面不能用select中的别名,但是group by ,order by都可以
# 牛客网:SQL26 计算25岁以上和以下的用户数量
MySQL:
select case when coalesce(age,20) < 25
then '25岁以下'
else '25岁及以上' end as age_cut
,count(distinct device_id) as number
from user_profile
group by age_cut
hive则遵循SQL执行顺序,select中的别名不能用在group by等之后。上题中,应在group by后重复加上case when语句
hive:
select case when coalesce(age,20) < 25
then '25岁以下'
else '25岁及以上' end as age_cut
,count(distinct device_id) as number
from user_profile
group by case when coalesce(age,20) < 25
then '25岁以下'
else '25岁及以上' end
8、分组连接函数
MySQL的group_concat()函数使用如下:
Select
fid,
group_concat(name order by name desc)
from test
group by fid
hive可以用concat_ws函数和collect_list、collect_set 函数来实现该功能
select
id,
concat_ws(',',collect_set(content)) as con_con,
concat_ws(',',collect_set(comment)) as con_com
from db_name.test_tb
group by id
hive函数concat用法
在presto中无collect_set,可用array_join函数实现该功能
select
id,
array_join(array_agg(content), ',') as con_con
from db_name.test_tb
group by id
hive函数array_join用法
9、hive中count开窗函数与distinct不能共用
count(distinct user_id) over(partition by )
在hive中报错,但我记得MySQL不会,记不清楚了需要再验证一下
10、hive和presto的grouping sets函数区别
一致点:
(1)grouping sets中不能有表别名,如果有多个表join,应该在join的结果外加一层后再去使用grouping sets,不然会报错
(2)grouping sets中有几个聚合语句,就生成几个维度
(3)grouping sets的聚合语句中,如果user_id在,而user_name不在里面,那么运行结果里面,user_name列会是空值
group by
user_id
,user_name
grouping sets
(
,(user_id)
,(user_id,user_name)
)
不同点:
(1)hive中select子句中要有grouping__ID,为具体的数值,用于后面的维度测试,但presto的select子句中grouping作为一个函数,要grouping(column_1,column_2,…)
(2)hive的group by子句中要列出所有要用的字段,然后加上grouping sets,presto的group by子句中仅有grouping sets
Hive/Presto中函数grouping sets用法详解
11、聚合函数用法不同
hive和MySQL中用with rollup、with cube
presto中用rollup()和cube()
12、列转行
hive:lateral view explode
presto:cross json unnest
参考
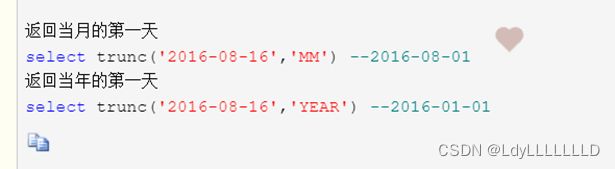
13、时间处理函数
(1)格式yyyy/MM/dd与yyyy-MM-dd与yyyyMMdd转换
hive: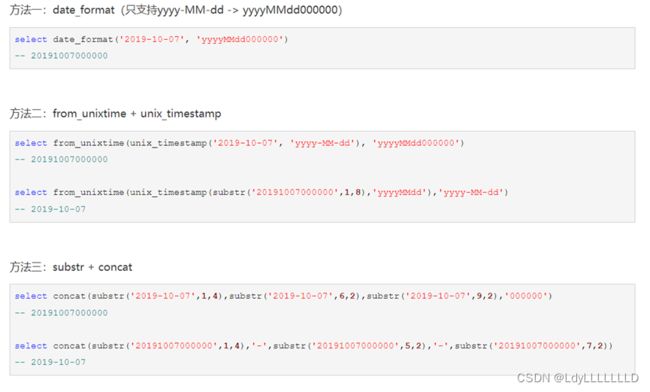
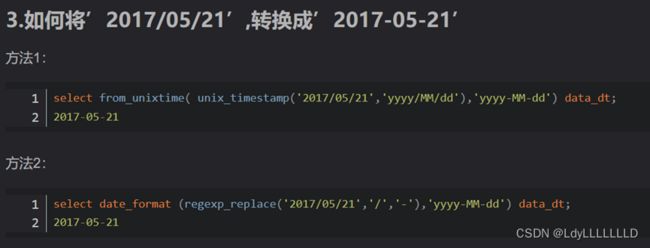
presto
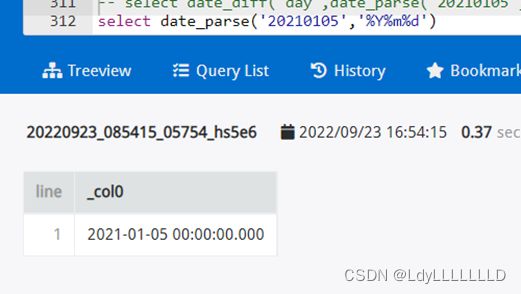
(2)返回当前时间
hive

impala/presto都有函数now()
Presto: current_date 不加括号,current_timestamp同理
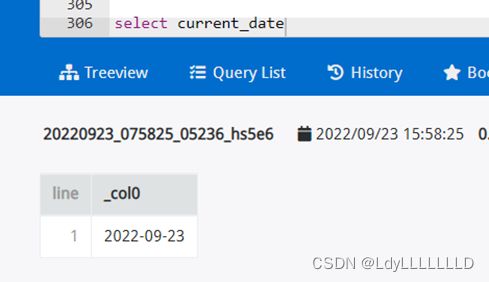
Impala: current_date() 加括号,current_timestamp同理
(3)计算时间差

也常用函数date_sub/date_add
月份差,有函数months_between()以及下面的用法
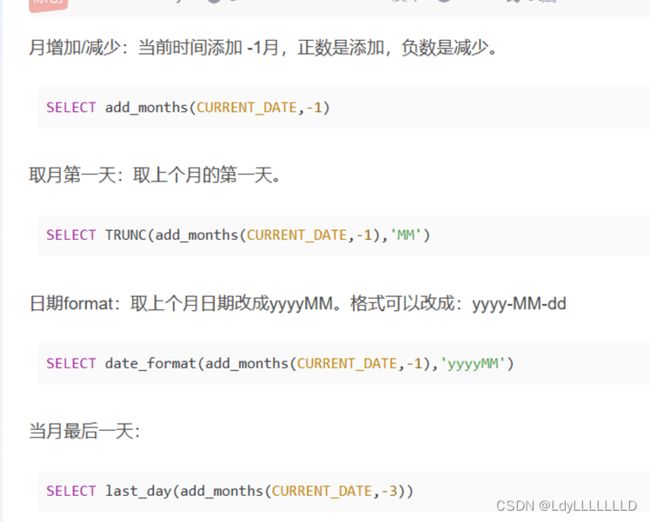
impala
![]()
(4)其他不常用时间函数
hive函数last_day/next_day
next_day求 当前日期的 下一个指定的周几。
last_day求 当前日期所在月的最后一天
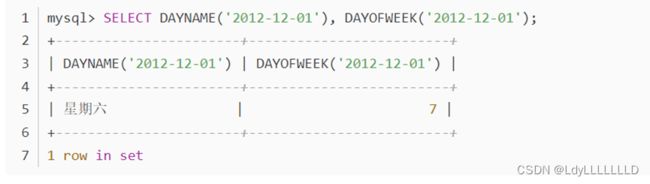
hive根据日期获取星期几
使用函数dayofweek()或者用求余函数pmod计算
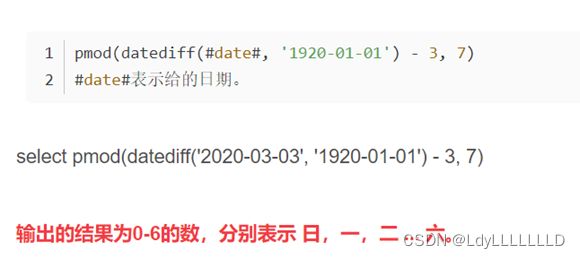
MySQL
DAYNAME函数返回日期名称,而DAYOFWEEK函数返回日期的索引