Python - 数据类型
字符串
去掉空格的方法:a="adsfvfv",使用a.strip()
input函数
a = input()
a为字符串类型,input函数输入的为字符串类型
列表
作用&定义
1、用来存储做个数据
2、列表的元素可以是任意类型
3、列表当中可以嵌套,可以一直嵌套列表、字典等,但是不建议
4、列表中的数据,几乎包含所有数据类型
5、列表的切片还是列表
一般定义
list = [1,2,3,4,4,3,2]
length = list.len
# 其他定义.里表中可以存放不同类型的元素
list = ['111',2,'d',[[1,3,],2,3,1,{'name':'lilei'}]重要功能:索引和切片
列表的增删改查与查询、切片、索引。例如:
items = [1,2,3,4,'苹果','火龙果']
items[5] # 火龙果
items[-1] # 火龙果
[100] # 应该为空
# 列表的切片得到的是一个列表
items[2:5] # [3,4,'苹果']
[1:1000000] # 结果是,现将现有的数据都取出,不会报错,
# 切片超出范围不报错,索引会报错
items[::-1] # 反转
列表的增删改查
club = ["喜洋洋","美羊羊","懒洋洋","沸羊羊","暖洋洋"]
# 增加
club.append("灰太狼") # 在末尾增加
b = club.append("惠洋洋")
print(b) # 输出None
# 在指定位置增加
club.insert(0,"小灰灰")
# 删除2种方式
club.remove("美羊羊") # 根据值删除
club.pop(3) # 根据索引删除
# 修改
club[-2] = "小白狼"
print(club) # 沸羊羊修改为 小白狼
列表 VS 字符串
列表是可变数据类型,字符串是不可变数据类型
元组
定义:a = (1,2,3,4) 或者 a = 2,3
1、元组切片切出来还是元组
2、元组不能增加、修改、删除
3、括号有时可以去掉,不建议不加括号
4、
注意:如果元祖只有1个数据,那么后面需要加逗号
a = (1)不是元组类型,是int类型
a = (1,)是元组
列表 VS 元组
1、作用不同
2、列表对数据的操作更多一些,元组少一些,例如:增删改
3、
字典
定义:favor = {"tv":"小猪佩奇","work":"字符串","food":"鱼香肉丝"}
属性
1、字典的丛:用来存储多份数据
2、以键值对形式存在
3、字典的key:必须是不可变类型,不能重复,所以key不能是字典或者列表
4、实际上字典的值一般都是字符串
5、具备增删改查操作
合法但是有点奇怪的写法:
favor = {1:“哈哈哈”,“2”:“好好好”}
favor = {(1,):“斤斤计较”,None:没有}不合法的写法
favor = {[1,2,]:"jjjjj",{1:"a"}:"ooo"}增删改查
favor = {"tv":"小猪佩奇","food":"米饭","fruit":"葡萄"}
# 增加元素
favor["color"] = green
# 修改
favor["tv"] = "葫芦娃"
# 删除
favor.pop("tv")
# 查询
favor["food"]
# 查询全部key和value的方法
favor.keys()
favor.values()
# 重点掌握
favor.items() # 以元组的形式输出每一个键值对
([('tv','小猪'),('food','米饭'),('fruit','葡萄')])
集合
定义:a = {1,2,4}
属性:
1、空集合: set()
2、不能有重复元素
3、没有顺序
数据类型的相互转换
方式:类型的名称加上括号,就是转换函数
list ——> tuple
a = [1,2,3,4]
tuple(a)
list ——> str
a = ['1','2','3','4']
str(a)
list ——> set
set(a)m使用场景:在自动化中去重
数据类型之间的运算
1、比较运算符:等于、不等于、大于、小于、大于等于、小于等于
比较运算得到的结果是布尔值 True/ False
2、成员运算: in not in 一个数据是不是包含另一个数据
主要用在有多个成员的额数据类型中,比如字符串、列表、元组、字典
成员运算得到的结果是布尔类型 True / False
3、逻辑运算 and or not
4、赋值运算:+=、-=、*=、/=
可变类型和不可变类型
可变(可以增删改查):列表、字典,集合
不可变(不能增删改查):True、None、1
有序 VS 无序(通过索引区分)
有序:有索引的,如:字符串、列表、元组
无序:没有索引,如:集合、字典
关于文件操作的2道题
'''
person_info = [
{
"name": "明鹏程",
"age": 22,
"gender": "男",
"hobby": "学习",
"motto": "学习使我快乐"
},
{
"name": "萌笑天",
"age": 20,
"gender": "女",
"hobby": "拿30K offer",
"motto": "下次拿个40K 的"
}
]
'''
person_info = [
{
"name": "明鹏程",
"age": 22,
"gender": "男",
"hobby": "学习",
"motto": "学习使我快乐"
},
{
"name": "萌笑天",
"age": 20,
"gender": "女",
"hobby": "拿30K offer",
"motto": "下次拿个40K 的"
}
]
with open("dict.txt", encoding="utf8", mode="x") as f:
List1 = []
keyLine = (",").join(person_info[0].keys()) + "\n"
List1.append(keyLine)
for ele in person_info:
ele["age"] = str(ele["age"])
ele1 = ",".join(ele.values()) + "\n"
List1.append(ele1)
f.writelines(List1)
'''
题目2:
手工准备cases.txt 文件,文件中手工复制 2 行数据:
url:/futureloan/mvc/api/member/register@mobile:18866668888@pwd:123456
url:/futureloan/mvc/api/member/recharge@mobile:18866668888@pwd:1000
请利用上课所学知识,把txt里面的两行内容取出然后保存到一个列表和字典当中:(可定义函数)
列表当中,有2个字典
每一行的数据,就是一个字典。
字典的key分别是:url,mobile,pwd
[
{'url': '/futureloan/mvc/api/member/register', 'mobile': '18866668888', 'pwd': '123456'},
{'url': '/futureloan/mvc/api/member/recharge', 'mobile': '18866668888', 'pwd': '1000'}
]
'''
'''
思路:
1、先逐行读取
2、根据@去切割
3、切割后,将字符链接起来
'''
with open("cases.txt", encoding="utf8") as f:
read_list = f.readlines()
res_list = []
# print(read_list)
# 切割
# tmp_map = {} # 位置1
for item in read_list:
tmp_map = {} # 位置2
# print(item)
item_list = item.strip("\n").split("@")
# print("item_list: ", item_list)
res_list.append(tmp_map)
for ele in item_list:
temp_list = ele.split(":")
tmp_map[temp_list[0]] = temp_list[1]
print("res_list", res_list)
题目2因为字典定义位置问题,引起了我的思考,如果放在位置1,那么结果不符合预期,如果放在位置2是符合预期的,因此,有了以下思考:
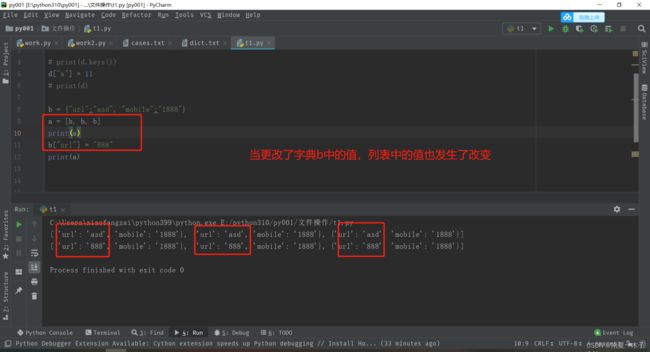
特别注意:列表里面存放字典,如果字典的值修改了,那么列表中这个值也是修改了的,看如下例子:
- 这是因为:数组列表里的三个元素,均为同一字典的内存地址,所以当该字典发生更新时,引用该字典的元素也就都会同步更新。

l