C#算法、排序以及数据结构
C#算法
什么是算法?
算法可以理解为有基本运算及规定的运算顺序所构成的完整的解题步骤,或者看成按照要求设计好的有限的确切的计算序列,并且这样的步骤和序列可以解决一类问题
算法分类:
分治法
堆排序
二叉树
动态规划
贪心算法
图
算法解决了哪些问题?
互联网信息的访问检测,海量数据的管理
在一个交通图中,寻找最近的路
人类基因工程,dna有10万个基因,处理这些基因序列需要复杂的算法支持
上面的算法是我们没有接触到,或者是封装到底层的东西,那么作为程序员,在日常编码过程中会在什么地方使用算法呢?
在你利用代码去编写程序,去解决问题的时候,其实这些编码过程都可以总结成一个算法,只是有些算法看起来比较普遍比较一般,偶尔
我们也会涉及一些复杂的算法比如一些Al
大多数我们都会利用已有的思路(算法)去开发程序!
学习算法的作用:
学习算法就像是去理解编程,可以让我们平时的编码过程变得更加通畅;并且会提高我们解决程序问题的能力
一、分治算法
分治策略是:对于一个规模为n的问题,若该问题可以容易的解决(比如说规模n较小)则直接解决,否则将其分解成k个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解决这些子问题,然后将各子问题的解合并得到原问题的解。这种算法设计策略叫做分治法。
可使用分治法求解的一些经典问题:
(1)二分搜索
(2)大整数乘法
( 3 ) Strassen矩阵乘法
( 4)相盘覆盖
(5)合并排序
(6)快速排序
(7)线性时间选择
(8)最接近点对问题
(9)循环赛日程表
(10)汉诺塔
1.1 最大子数组问题

1.1.1 暴力求解
找出最大子数组:
//创建一个价格数组
int[] priceArray = { 50, 57, 65, 75, 67, 60, 54, 51, 48, 44, 47, 43, 56, 64, 71, 65, 61, 73, 70 };
//创建一个价格波动的数组(比价格数组少一个元素)
int[] priceFluctuations = new int[priceArray.Length-1];
//给价格波动的数组赋值
for (int i = 1; i < priceArray.Length; i++)
{
priceFluctuations[i-1] = priceArray[i] - priceArray[i-1];
}
//默认priceFluctuations数组中的第一个元素是最大的子数组
int total = priceFluctuations[0];
//初始化开始索引和结束索引都是0
int startIndex = 0;
int endIndex = 0;
//遍历priceFluctuations的每一个元素
for (int i = 0; i < priceFluctuations.Length; i++)
{
//取得以i为子数组起点的所有子数组
for(var j=i;jtotal)
{
total = totalTemp;
startIndex = i;
endIndex = j;
}
}
}
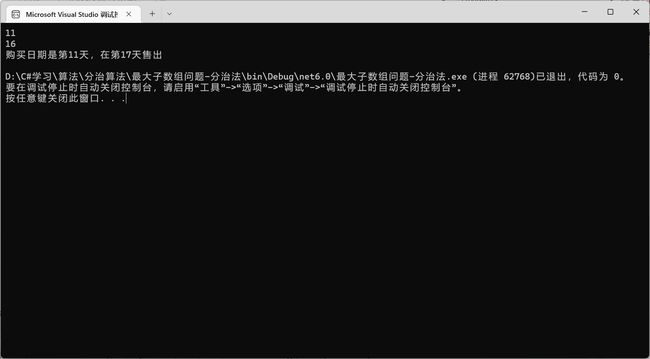
Console.WriteLine("startIndex:"+startIndex);
Console.WriteLine("endIndex:"+endIndex);
//索引相差一:因为价格波动的数组第一位是没有的,所以就产生了错位现象
Console.WriteLine("购买日期是第"+startIndex+"天\t出售是第"+(endIndex+1)+"天");

1.1.2 分治法
分析:mid是low,high的中间值;[low,mid]属于低区间,[mid+1,high]属于高区间

代码实现:
class Program
{
//定义一个子数组结构体,来保存最大子数组里面的一些东西
struct SubArray
{
public int startIndex; //开始索引
public int endIndex;//结束索引
public int total;//最大子数组的和
}
static void Main(string[] args)
{
//创建一个价格数组
int[] priceArray = { 50, 57, 65, 75, 67, 60, 54, 51, 48, 44, 47, 43, 56, 64, 71, 65, 61, 73, 70 };
//int[] priceArray = { 100,113,110,85,105,102,86,63,81,101,94,106,107,79,94,90,97 };
//创建一个价格波动的数组(比价格数组少一个元素)
int[] priceFluctuations = new int[priceArray.Length - 1];
//给价格波动的数组赋值
for (int i = 1; i < priceArray.Length; i++)
{
priceFluctuations[i - 1] = priceArray[i] - priceArray[i - 1];
}
var subArray = GetMaxSubArray(0,priceFluctuations.Length-1,priceFluctuations);
Console.WriteLine(subArray.startIndex);
Console.WriteLine(subArray.endIndex);
Console.WriteLine("购买日期是第"+subArray.startIndex+"天,在第"+(subArray.endIndex+1)+"天售出");
}
//定义一个取得最大子数组的方法
static SubArray GetMaxSubArray(int low, int high, int[] array)//这个方法是用来取得array这个数组从low到high之间的最大子数组
{
int mid = (low + high) / 2;//得到中值mid,低区间:[low,mid],高区间:[mid+1,high]
//递归结束条件
if (low == high)
{
SubArray subArray; //结构体不需要new
subArray.startIndex = low;
subArray.endIndex = high;
subArray.total = array[low];
return subArray;
}
//1、得到低区间的最大子数组:递归调用(递归结束条件:low == mid)
var subarray1 = GetMaxSubArray(low,mid,array);
//2、得到高区间的最大子数组:递归调用(递归结束条件:mid+1 == high)
var subArray2 = GetMaxSubArray(mid+1, high, array);
//3、i位于低区间,j位于高区间
//(1)从[low,mid]中找到最大子数组[i,mid]
int total1 = array[mid];//默认最大子数组的和为array[mid]
int startIndex = mid; //默认开始索引为mid
int totalTemp = 0; //临时的和
//从mid开始遍历,向下遍历低区间
for (int i = mid; i>=low; i--)
{
totalTemp += array[i];
if (totalTemp>total1)
{
total1 = totalTemp;
startIndex = i;
}
}
//(2)从[mid+1,high]找到最大子数组[mid+1,j]
int total2 = array[mid+1];//默认最大子数组的和为array[mid+1],将array[mid+1]的值重新赋值给total
int endIndex = mid+1; //默认开始索引为mid
totalTemp = 0;//上面的循环遍历结束,将临时的和归零
//从mid+1开始遍历,向上遍历高区间
for (int j = mid+1; j <= high; j++)
{
totalTemp += array[j];
if (totalTemp > total2)
{
total2 = totalTemp;
endIndex = j;
}
}
SubArray subArray3;
subArray3.startIndex = startIndex;
subArray3.endIndex = endIndex;
subArray3.total = total1 + total2;
//判断哪一个最大子数组比较大;因为可能出现三个值一样,所以加上了=
if (subarray1.total>=subArray2.total && subarray1.total>=subArray3.total)
{
return subarray1;
}else if(subArray2.total>=subarray1.total && subArray2.total>=subArray3.total)
{
return subArray2;
}
else
{
return subArray3;
}
}
}
二、动态规划算法
什么是动态规划,我们要如何描述它?
动态规划算法通常基于一个递推公式及一个或多个初始状态。当前子问题的解将由上一次子问题的解推出。
动态规划和分治法相似,都是通过组合子问题的解来求解原问题。分治法将问题划分成互不相交的子问题,递归求解子问题,再将他们的解组合起来,求出原问题的解。与之相反,动态规划应用于子问题重叠的情况,即不同的子问题具有公共的子子问题。在这种情况下,分治算法会做出许多不必要的工作,它会反复的求解那些公共子问题。而动态规划算法对每个子子问题只求解一次,将结果保存到表格(程序中保存在数组)中,从而无需每次求解一个子子问题都要重新计算。
2.1 背包问题
问题描述:
假设现有容量m kg的背包,另外有i个物品,重量分别为w[1] w[2] … w[i] (kg),价值分别为p[1]p[2] … p[i](元) ,将哪些物品放入背包可以
使得背包的总价值最大?最大价值是多少?
(示例一:m=10 i=3 重量和价值分别为 3kg-4元 4kg-5元 5kg-6元)
1、穷举法(把所有情况列出来,比较得到总价值最大的情况)
如果容量增大,物品增多,这个方法的运行时间将成指数增长(如示例,当i=3时,便有2^3中情况)
2、动态规划算法
我们要求得i个物体放入容量为m(kg)的背包的最大价值(记为c[i,m])。在选择物品的时候,对于每种物品i只有两种选择,即装入背包或不
装入背包。某种物品不能装入多次(可以认为每种物品只有一个),因此该问题被称为0-1背包问题
对于c[i,m]有下面几种情况:
a、c[i,0]=c[0,m]=0
b、c[i,m]=c[i-1,m] w[i]>m (最后一个物品的重量大于容量,直接舍弃不用)
w[i]<=m的时候有两种情况,一种是放入i,一种是不放入i
不放入i c[i,m]=c[i-1,m]
放入i c[i,m]=c[i-1,m-w[i]]+p[i]
c[i,m]=max(不放入i,放入i)
2.1.1 穷举法(暴力求解)
假设有4个物品,分别编号为1,2,3,4;每个物品有两种选择0(不选)/1(选)
物品: 4 3 2 1
选择: 2 2 2 2 总的选择情况:2的4次方(种)
01 01 01 01
都不选:0 0 0 0 二进制数:0 2的0次方
都选: 1 1 1 1 二进制数:15 2的4次方-1
8 4 2 1
取出5: 0 1 0 1
位运算:
位左移运算:<< 位右移运算:>>
例如:
5的二进制:0101
5<<2 运算:010100 解释:5代表的二进制数左移两位,相当整体与2的2次方相乘
5>>2 运算:01.01——>01 解释:5代表的二进制数右移两位,相当将小数点左移两位;将小数点后面的省略即得01
如何取得,5的二进制:0101 最右边的1?
方法一:
1、先让5>>1=010 = 2d
2、再让2<<1=0100=4d
2、再让5-4= 0101 - 0100 = 0001 = 1d
完整的表达式:5-(5>>1)<<1 得到二进制的第一位上的数字(右起)
方法二:取一个数中指定位(按位与运算)
找一个数,对应X要取的位,该数的对应位为1,其余位为零,此数与X进行“与运算”可以得到X中的指定位。
例:设X=10101110, 取X的低4位,用 X & 0000 1111 = 0000 1110 即可得到
取X的第二位,用 X & 0000 0010 = 0000 0010 即可得到
还可用来取X的2、4、6位
利用如上方法:
5=0101,用0101 & 0001 = 0001 = 1d
可证n个物品,总的选择方案共有:2的4次方-1(种)
代码实现:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace 动态规划算法
{
internal class Program
{
static void Main(string[] args)
{
int m; //定义背包重量
int[] w = { 0, 3, 4, 5 }; //定义物品重量;w[0] = 0,表示没有那个物品
int[] p = { 0, 4, 5, 6 }; //定义物品价值
Console.WriteLine("背包是10kg时,总价值最大为:"+Exhaustivity(10,w,p));
Console.WriteLine("背包是3kg时,总价值最大为:"+Exhaustivity(3,w,p));
Console.WriteLine("背包是4kg时,总价值最大为:"+Exhaustivity(4,w,p));
Console.WriteLine("背包是5kg时,总价值最大为:"+Exhaustivity(5,w,p));
Console.WriteLine("背包是7kg时,总价值最大为:"+Exhaustivity(7,w,p));
Console.ReadLine();
}
//穷举法
public static int Exhaustivity(int m, int[] w, int[] p)
{
//获取物品的个数,只有三个,0只是作为标志位(表示没有那个物品)
int i = w.Length-1;
//定义一个最大价值
int maxPrice = 0;
//遍历所有解决方案,从0开始到2的m次方
for (int j =0;j< System.Math.Pow(2,m);j++)
{
//定义一个物品重量的和,默认等于0
int weightTotal = 0;
//定义一个物品价值的和,默认等于0
int priceTotal = 0;
//将i转化为二进制数,有几个物品就转化为几位二进制数
//取得j上某一个位的二进制值
for (int number = 1;number<=i;number++)
{
int result = Get2(j,number);
//如果result == 1,表示第number位上是1,则它要被选中
if (result == 1)
{
weightTotal += w[number];
priceTotal+=p[number];
}
if (weightTotal<=m && priceTotal>maxPrice)
{
maxPrice = priceTotal;
}
}
}
return maxPrice;
}
//取得二进制数上某一位的二进制值:例如,0101,取出右起第三位的二进制的值1
///
/// 取得j上第number位上的二进制值,是0还是1
///
///
///
/// 2.1.2 递归实现(不带备忘的自顶向下法)
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace _0_1背包问题_递归实现_不带备忘的自顶向下法_
{
internal class Program
{
static void Main(string[] args)
{
int m; //定义背包重量
int[] w = { 0, 3, 4, 5 }; //定义物品重量;w[0] = 0,表示没有那个物品
int[] p = { 0, 4, 5, 6 }; //定义物品价值
Console.WriteLine("背包是10kg时,总价值最大为:" + UpDown(10,3, w, p));
Console.WriteLine("背包是3kg时,总价值最大为:" + UpDown(3, 3, w, p));
Console.WriteLine("背包是4kg时,总价值最大为:" + UpDown(4, 3, w, p));
Console.WriteLine("背包是5kg时,总价值最大为:" + UpDown(5, 3, w, p));
Console.WriteLine("背包是7kg时,总价值最大为:" + UpDown(7, 3, w, p));
Console.ReadLine();
}
///
///
///
///
/// i个物品
///
///
/// 缺点:递归实现不带备忘的自顶向下法会重复解决子问题,会造成大量的时间的消耗,性能的浪费
2.1.3递归实现(带备忘的自顶向下法)
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace _0_1背包问题_递归实现_带备忘的自顶向下法_
{
internal class Program
{
//声明一个备忘数组
public static int[,] result = new int[11, 4]; //11:代表m,0-10 4:代表i,0-3
static void Main(string[] args)
{
int m; //定义背包重量
int[] w = { 0, 3, 4, 5 }; //定义物品重量;w[0] = 0,表示没有那个物品
int[] p = { 0, 4, 5, 6 }; //定义物品价值
Console.WriteLine("背包是10kg时,总价值最大为:" + UpDown(10, 3, w, p));
Console.WriteLine("背包是3kg时,总价值最大为:" + UpDown(3, 3, w, p));
Console.WriteLine("背包是4kg时,总价值最大为:" + UpDown(4, 3, w, p));
Console.WriteLine("背包是5kg时,总价值最大为:" + UpDown(5, 3, w, p));
Console.WriteLine("背包是7kg时,总价值最大为:" + UpDown(7, 3, w, p));
Console.ReadLine();
}
///
///
///
///
/// i个物品
///
///
/// 2.1.4 动态规划(自底向上法)
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace _0_1背包问题_动态规划_自底向上法_
{
internal class Program
{
static void Main(string[] args)
{
int m; //定义背包重量
int[] w = { 0, 3, 4, 5 }; //定义物品重量;w[0] = 0,表示没有那个物品
int[] p = { 0, 4, 5, 6 }; //定义物品价值
Console.WriteLine("背包是10kg时,总价值最大为:" + BottomUp(10, 3, w, p));
Console.WriteLine("背包是3kg时,总价值最大为:" + BottomUp(3, 3, w, p));
Console.WriteLine("背包是4kg时,总价值最大为:" + BottomUp(4, 3, w, p));
Console.WriteLine("背包是5kg时,总价值最大为:" + BottomUp(5, 3, w, p));
Console.WriteLine("背包是7kg时,总价值最大为:" + BottomUp(7, 3, w, p));
Console.ReadLine();
}
//需要一个二维数组存储结果
public static int[,] result = new int[11, 4];
public static int BottomUp(int m, int i, int[] w, int[] p)
{
//性能节约:w, p相同的情况下
if (result[m,i]!=0)
{
return result[m,i];
}
for (int tempM = 1;tempM m(最后一个物品的重量大于容量,直接舍弃不用)
if (w[tempI]>tempM)
{
result[tempM, tempI] = result[tempM,tempI-1];
}
else//w[i] <= m的时候有两种情况
{
//1、放入i c[i, m] = c[i - 1, m - w[i]] + p[i]
int maxValue1 = result[tempM - w[tempI], tempI - 1] + p[tempI];
//2、不放入i c[i, m] = c[i - 1, m]
int maxValue2 = result[tempM, tempI - 1];
if (maxValue1>maxValue2)
{
result[tempM, tempI] = maxValue1;
}
else
{
result[tempM, tempI] = maxValue2;
}
}
}
}
return result[m, i];
}
}
}
三、贪心算法
对于许多最优化问题,使用动态规划算法来求最优解有些杀鸡用牛刀了,可以使用更加简单、更加高效的算法。贪心算法就是这样的算法,它在每一步做出当时看起来最佳的选择。也就是说它总是做出局部最优的选择,从而得到全局最优解。
对于某些问题并不保证得到最优解,但对很多问题确实可以求得最优解。
3.1 活动选择问题
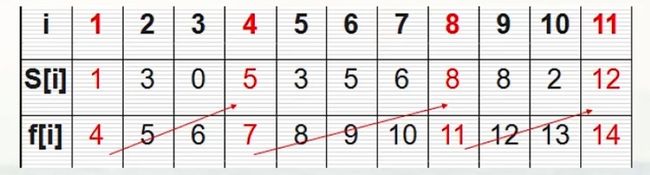
有n个需要在同一天使用同一个教室的活动a1 , a2 , … , an,教室同一时刻只能由一个活动使用。每个活动ai都有一个开始时间si和结束时间fi。一旦被选择后,活动ai就占据半开时间区间[si,fi)。如果[si,fi]和[sj,fj]互不重叠,ai和aj两个活动就可以被安排在这一天。该问题就是要安排这些活动使得尽量多的活动能不冲突的举行(最大兼容活动子集)。例如下图所示的活动集合S,其中各项活动按照结束时间单调递增排序。
{a3,a9,a11]}是一个兼容的活动子集,但它不是最大子集,因为子集{al,a4,a8,a11}更大,实际上它是我们这个问题的最大兼容子集,但它不是唯一的一个{a2,a4 , a9,a11}
1、动态规划算法解决思路
我们使用Sij代表在活动ai结束之后,且在aj开始之前的那些活动的集合,我们使用c[i,j]代表Sij的最大兼容活动子集的大小,对于上述问题就是求c[0,12](a0=0,0;a1=1,4;…;a11=12,14;a12=24,24)的解
a,当i>=j-1或者Sij中没有任何活动(子集)的时候,c[i,j] = 0(等于0表示是一个空集) 1、Sij不存在活动,c[i,j] = 0 2、Sij存在子集的时候,c[i,j]= max {c[i,k]+c[k,j]+1](+1:表示k活动本身) ak属于Sij,这里是遍历Sij的集合,然后求得最大兼容子集 注:ai、aj、Sij:i、j是下标,ak:k是下标,代表ij中的活动 2、贪心算法解决思路 注:am:m是下标 树是一种数据结构,它是由n(n≥0)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点: 树的种类: 简单分类: 空树 只有一个节点的树 有多个节点的树,如下图 按学名分类: 无序树:树中任意节点的子结点之间没有顺序关系,这种树称为无序树,也称为自由树; 有序树:树中任意节点的子结点之间有顺序关系,这种树称为有序树; 二叉树:每个节点最多含有两个子树的树称为二叉树; 满二叉树:叶节点除外的所有节点均含有两个子树的树被称为满二叉树; 完全二叉树:一棵深度为k的有n个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点 与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。 简单来说,就是除最后一层外,所有层都是满节点,且最后一层缺右边连续节点的二叉树称为完全二叉树; 顺序存储一般只用于完全二叉树,否则会造成内存空间的浪费 哈夫曼树(最优二叉树):带权路径最短的二叉树称为哈夫曼树或最优二叉树。 树的遍历 遍历表达法有4种方法:先序遍历、中序遍历、后序遍历、层次遍历 例如上图: 其先序遍历又称先根遍历)为ABDECF(根-左-右) 其中序遍历(又称中根遍历)为DBEAFC(左-根-右)(仅二叉树有中序遍历) 其后序遍历(又称后根遍历)为DEBFCA(左-右-根) 其层次遍历为ABCDEF(同广度优先搜索) 二叉树(Binary tree)是树形结构的一个重要类型。许多实际问题抽象出来的数据结构往往是二叉树形式,即使是一般的树也能简单地转换为二叉树,而且二叉树的存储结构及其算法都较为简单,因此二叉树显得特别重要。二叉树特点是每个节点最多只能有两棵子树,且有左右之分。 二叉树是n个有限元素的集合,该集合或者为空、或者由一个称为根(root)的元素及两个不相交的、被分别称为左子树和右子树的二叉树组成,是有序树。当集合为空时,称该二叉树为空二叉树。在二叉树中,一个元素也称作一个节点 。 定义 二叉树(binary tree)是指树中节点的度不大于2的有序树,它是一种最简单且最重要的树。二叉树的递归定义为:二叉树是一棵空树,或者是一棵由一个根节点和两棵互不相交的,分别称作根的左子树和右子树组成的非空树;左子树和右子树又同样都是二叉树 [2] 。 基本形态 二叉树是递归定义的,其节点有左右子树之分,逻辑上二叉树有五种基本形态: 1、空二叉树——如图(a); 2、只有一个根节点的二叉树——如图(b); 3、只有左子树——如图(c); 4、只有右子树——如图(d); 5、完全二叉树——如图(e) 二叉树的性质 在二叉树的第i层上最多有2^(i-1)个节点(i>=1) 2^(i-1):表示2的i-1次方 深度为k的二叉树,至多有2^k-1个节点 2^k-1:表示2的k次方减一 对于一个完全二叉树,假设它有n个节点,对节点进行从1开始编号,对任一节点i满足下面 a. 它的双亲是节点i/2(除了i=1的情况) b. 左孩子是2i,右孩子是2i+1 c. 如果2i>n 说明无左孩子,2i+1>n说明无右孩子 数据结构的分类: 线性表是最简单、最基本、最常用的数据结构。线性表是线性结构的抽象(Abstract),线性结构的特点是结构中的数据元素之间存在一对一的线性关系。这种一对一的关系指的是数据元素之间的位置关系,即:(1)除第一个位置的数据元素外,其它数据元素位置的前面都只有一个数据元素;(2)除最后一个位置的数据元素外,其它数据元素位置的后面都只有一个元素。也就是说,数据元素是一个接一个的排列。因此,可以把线性表想象为一种数据元素序列的数据结构。 线性表主要由顺序表示或链式表示。在实际应用中,常以栈、队列、字符串等特殊形式使用。 顺序表示指的是用一组地址连续的存储单元依次存储线性表的数据元素,称为线性表的顺序存储结构或顺序映像*(sequential mapping)*。它以“物理位置相邻”来表示线性表中数据元素间的逻辑关系,可随机存取表中任一元素。 链式表示指的是用一组任意的存储单元存储线性表中的数据元素,称为线性表的链式存储结构。它的存储单元可以是连续的,也可以是不连续的。在表示数据元素之间的逻辑关系时,除了存储其本身的信息之外,还需存储一个指示其直接后继的信息*(即直接后继的存储位置),这两部分信息组成数据元素的存储映像,称为结点(node)*。它包括两个域;存储数据元素信息的域称为数据域;存储直接后继存储位置的域称为指针域。指针域中存储的信息称为指针或链 。 数据结构和算法动态可视化:https://visualgo.net/zh/ 排序( Sort)是计算机程序设计中的一种重要操作,也是日常生活中经常遇到的问题。例如,字典中的单词是以字母的顺序排列,否则,使用起来非常困难。同样,存储在计算机中的数据的次序,对于处理这些数据的算法的速度和简便性而言,也具有非常深远的意义。 排序是把一个记录(在排序中把数据元素称为记录)集合或序列重新排列成按记录的某个数据项值递增(或递减)的序列。 作为排序依据的数据项称为“排序项",也称为记录的关键码(Keyword)。关键码分为主关键码(Primary Keyword)和次关键码(Secondary Keyword)。一般地,若关键码是主关键码,则对于任意待排序的序列,经排序后得到的结果是唯一的;若关键码是次关键码排序的结果不一定唯一,这是因为待排序的序列中可能存在具有相同关键码值的记录。此时,这些记录在排序结果中,它们之间的位置关系与排序前不一定保持一致。 如果使用某个排序方法对任意的记录序列按关键码进行排序,相同关键码值的记录之间的位置关系与排序前一致,则称此排序方法是稳定的;如果不一致,则称此排序方法是不稳定的。 由于待排序的记录的数量不同,使得排序过程中涉及的存储器不同,可将排序方法分为内部排序( Internal Sorting )和外部排序(External Sorting )两大类。 外部排序指的是在排序过程中,记录的主要部分存放在外存中,借助于内存逐步调整记录之间的相对位置。在这个过程中,需要不断地在内、外存之间交换数据。 插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为O(n^2)。是稳定的排序方法。插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插入的位置),而第二部分就只包含这一个元素(即待插入元素)。在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中。插入排序的基本思想是:每步将一个待排序的纪录,按其关键码值的大小插入前面已经排序 冒泡排序(Bubble Sort)的基本思想是:将相邻的记录的关键码进行比较,若前面记录的关键码大于后面记录的关键码,则将它们交换,否则不交换 是稳定的排序算法 简单选择排序(Simple Select Sort)算法的基本思想是:从待排序的记录序列中选择关键码最小(或最大)的记录并将它与序列中的第一个记录交换位置;然后从不包括第一个位置上的记录序列中选择关键码最小(或最大)的记录并将它与序列中的第二个记录交换位置;如此重复,直到序列中只剩下一个记录为止。 快速排序由于排序效率综合来说是几种排序方法中效率较高,因此经常被采用,再加上快速排序思想----分治法也确实实用,因此很多软件公司的笔试面试,包括像腾讯,微软等知名IT公司都喜欢考这个,还有大大小的程序方面的考试如软考,考研中也常常出现快速排序的身影。 快速排序详细步骤 以一个数组作为示例,取区间第一个数为基准数。 初始时,i = 0; j = 9; X = a[i]=72 由于已经将a[0]中的数保存到X中,可以理解成在数组a[0]上挖了个坑,可以将其它数据填充到这来。从j(j=9:从后往前遍历,找一个比它小的数字放在0号位置)开始向前找一个比X小或等于X的数。当j=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8];i++;这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从i(i=0:从前往后遍历,找一个比它大的数字放在后面)开始向后找一个大于X的数,当i=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3];j–; 数组变为: i = 3; j=7; X=72 数组变为: 可以看出a[5]前面的数字都小于它,a[5]后面的数字都大于它。因此再对a[0…4]和a[6…9]这二两个子区间查复上述步骤就可以了。 快排总结 什么是堆? 堆是具有下列性质的完全二叉树:(堆其实也是一种二叉树) 每个节点的值都大于或者等于其左右孩子节点的值,称为大顶堆;或者每个节点的值都小于或者等于其左右孩子节点的值,称为小顶堆。 堆排序 堆排序算法就是利用堆(小顶堆或者大顶堆)进行排序的方法。 使用代码把下图中的二叉树构造成大顶堆 提取相同的部分封装成方法:HeapAjust
b,当i
想要使用贪心算法的话,得先找到适合贪心算法的规律(局部最优选择)
对于任何非空的活动集合S,假如am是S中结束时间最早的活动,则am一定在S的某个最大兼容活动子集中。
(如何证明上面的结论?反证法)
递归解决
迭代解决3.1.1 动态规划算法
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace 贪心算法
{
internal class Program
{
static void Main(string[] args)
{
//开始时间数组
int[] s = { 0, 1, 3, 0, 5, 3, 5, 6, 8, 8, 2, 12 ,24 }; //0,24是补充上去的第1号,第12号活动
//结束时间数组
int[] f = { 0, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 24 };//0,24是补充上去的第1号,第12号活动
//定义一个list类型的二维数组集合,大小初始为13,13
List
3.1.2 贪心算法(递归实现)
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace 贪心算法_递归实现__活动选择问题
{
internal class Program
{
//开始时间数组
static int[] s = { 0, 1, 3, 0, 5, 3, 5, 6, 8, 8, 2, 12 }; //添加0号活动可以保证编号和索引对应,24号是动态规划才用得到
//结束时间数组
static int[] f = { 0, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 };//添加0号活动可以保证编号和索引对应
static void Main(string[] args)
{
List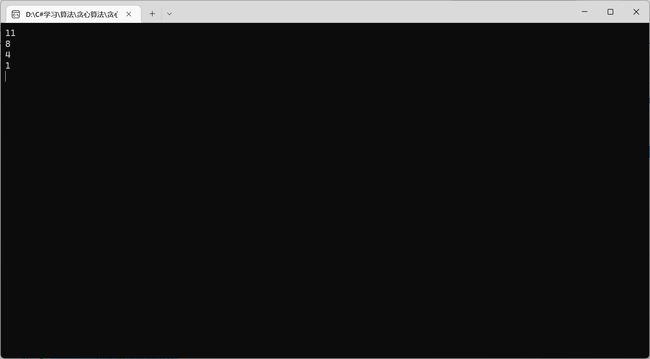
3.1.3 贪心算法(迭代实现)
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace 贪心算法_迭代实现__活动选择问题
{
internal class Program
{
static void Main(string[] args)
{
//开始时间数组
int[] s = { 0, 1, 3, 0, 5, 3, 5, 6, 8, 8, 2, 12 }; //添加0号活动可以保证编号和索引对应,24号是动态规划才用得到
//结束时间数组
int[] f = { 0, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 };//添加0号活动可以保证编号和索引对应
int startTime = 0;
int endTime = 24;
List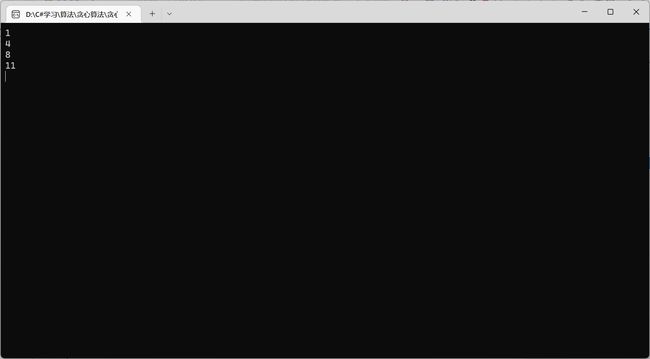
四、树
4.1 树的介绍

4.1.2 二叉树的介绍

C#数据结构
一、线性表
线性表就是位置有先后关系,一个接着一个排列的数据结构。1.1存储结构
1.2 线性表使用及自定义线性表步骤
using System;
using System.Collections.Generic;
using System.Linq;
using System.Security.Cryptography.X509Certificates;
using System.Text;
using System.Threading.Tasks;
namespace ListDS_Study
{
public class Program
{
static void Main(string[] args)
{
//使用官方封装的List线性表
ListC#排序
1.1 排序基本概念
例如一个学生成绩表,其中某个学生记录包括学号、姓名及计算机文化基础、C语言、数据结构等课程的成绩和总成绩等数据项。在排序时,如果用总成绩来排序,则会得到一个有序序列;如果以数据结构成绩进行排序,则会得到另一个有序序列。
内部排序指的是在排序的整个过程中,记录全部存放在计算机的内存中,并且在内存中调整记录之间的相对位置,在此期间没有进行内、外存的数据交换。1.2 排序算法的稳定性

1.3 插入排序(稳定)
的文件中适当位置上(当前元素比已经排好序的元素进行比较,如果已经排好序的元素中存在比当前元素大的数,则将其向后移动;待依次移动完成之后将其直接插入该位置),直到所有元素全部插完为止。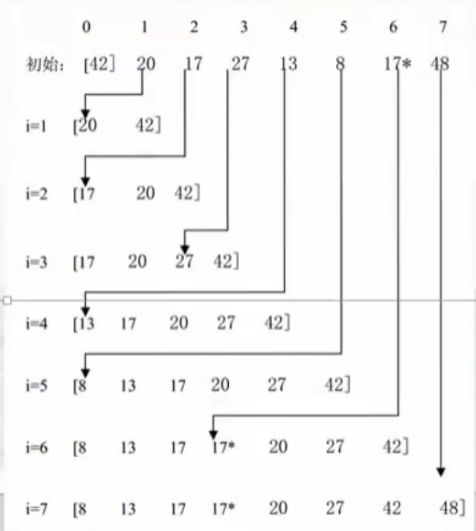
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace InsertSort
{
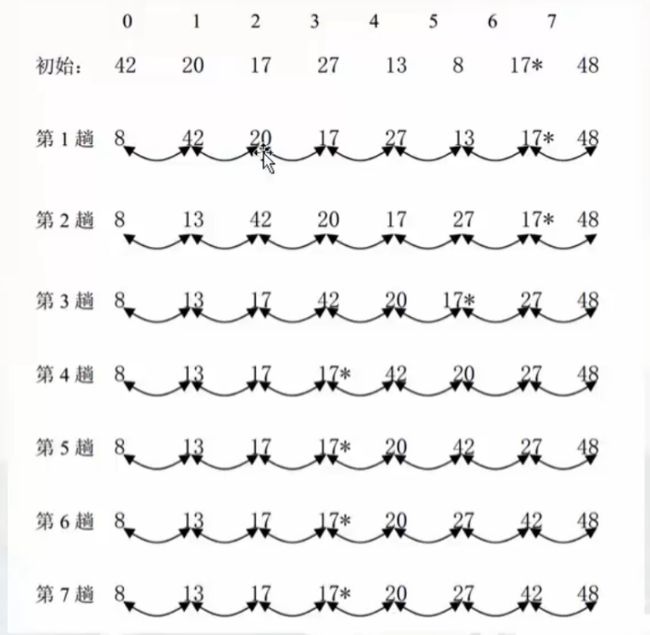
/// 1.4 冒泡排序(稳定)
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace BubbleSort
{
internal class Program
{
static void Main(string[] args)
{
//获得一组数字
//string str = Console.ReadLine();
//string[] strArray = str.Split();
//int[] intArray = new int[strArray.Length];
//for (int i = 0; i < strArray.Length; i++)
//{
// int number = Convert.ToInt32(strArray[i]);
// intArray[i] = number;
//}
//输入一组数据
int[] intArray = new int[] {19,50,19,16};
for (int j = 0; j < intArray.Length - 1; j++) //进行Length - 1轮比较
{
//进行比较 j=0 Length-1
//j=1 Length - 1 - 1
//j=2 Length - 1 - 2
//需要一个变量标志,记录当前轮次比较是否有发生交换
bool isChange = false;
for(int i = 0; i < intArray.Length - 1 - j; i++)
{
//如果左边大于右边,就交换
if (intArray[i]>intArray[i+1])
{
int temp = intArray[i];
intArray[i] = intArray[i+1];
intArray[i+1] = temp;
isChange = true;
}
}
if (isChange = false)
{
break;
}
}
foreach (int i in intArray)
{
Console.Write(i+" ");
}
Console.ReadLine();
}
}
}
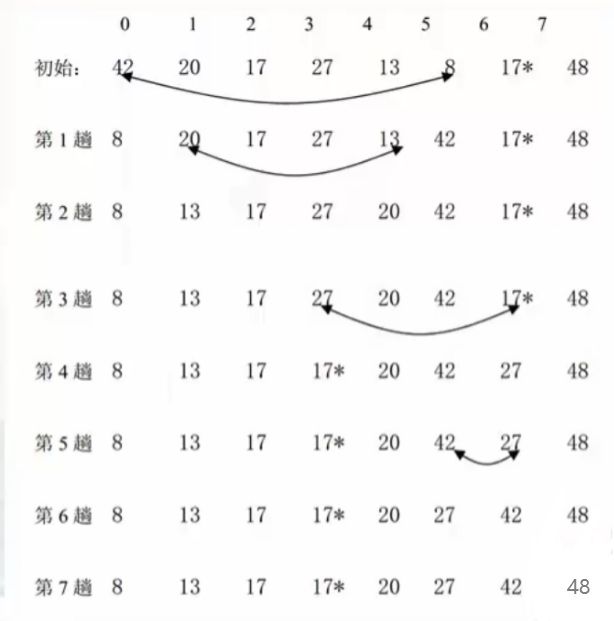
1.5 简单选择排序(不稳定)
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace SimpleSelectSort
{
internal class Program
{
static void Main(string[] args)
{
int[] data = new int[] { 42, 20, 17, 27, 13, 8, 17, 48 };
SimpleSelectSort(data);
foreach (int i in data)
{
Console.Write(i + " ");
}
Console.ReadLine();
}
static void SimpleSelectSort(int[] dataArray)
{
//只需要遍历到倒数第二个元素就行了,因为它后面只有一个元素不需要遍历了
for (int i = 0; i 1.6 *快速排序(面试经常被问到)(不稳定)
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
该方法的基本思想是:
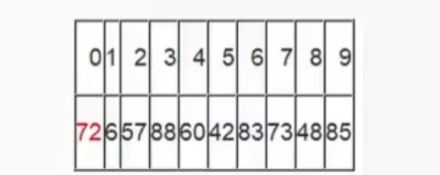
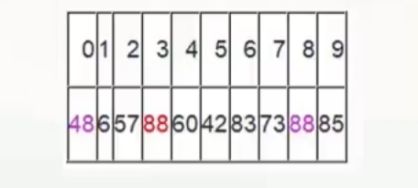
再重复上面的步骤,先从后向前找,再从前向后找。
从j开始向前找,当j=5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; i++从i开始向后找,当i=5时,由于i==j退出。
此时,i= j =5,而a[5]刚好又是上次挖的坑,因此将X填入a[5]。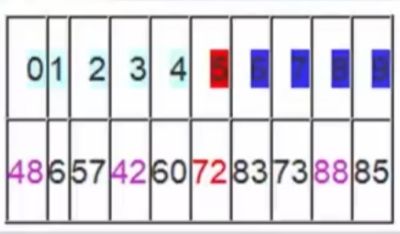
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace QuickSort
{
/// 1.7 堆排序(顺序存储)(不稳定)
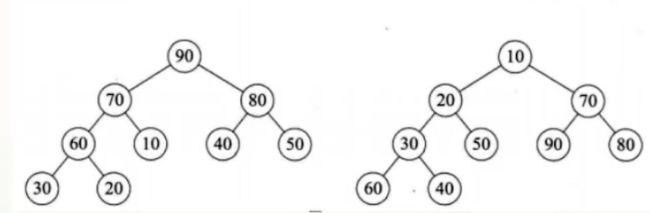
将待排序的序列构造成一个大顶堆,此时整个序列的最大值就是根节点。将它移走〈跟堆的最后一个元素交换,此时末尾元素就是最大值),然后将剩余的n-1个序列重新构造成一个堆,这样就会得到n个元素中的次小值。如此反复执行,便能得到一个有序序列了。

using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace 堆排序_顺序存储
{
/// using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace 堆排序_顺序存储
{
///