时序数据库 TimescaleDB 安装与使用

TimescaleDB 是一个时间序列数据库,建立在 PostgreSQL 之上。然而,不仅如此,它还是时间序列的关系数据库。使用 TimescaleDB 的开发人员将受益于专门构建的时间序列数据库以及经典的关系数据库 (PostgreSQL),所有这些都具有完整的 SQL 支持。本文介绍 TimescaleDB 的 CentOS 7 环境源码编译安装与使用。
01 源码安装
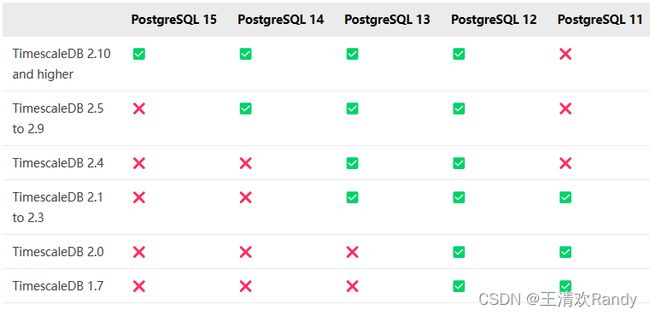
安装 TimescaleDB 之前确保你的机器上已经安装好了 PostgreSQL,并且检查安装的 PG 版本与 TimescaleDB 版本兼容情况:https://docs.timescale.com/self-hosted/latest/upgrades/upgrade-pg/
源码安装需要使用到 CMake 和 GUN 编译器 gcc 等工具,确保机器已经安装了这些工具
1.1 源码安装 TimescaleDB
- 拉取 TimescaleDB 源码
git clone https://github.com/timescale/timescaledb
- 进入源码目录并切换分支到指定版本
cd timescaledb
git checkout 2.11.1
- 执行 bootstrap 引导构建系统
./bootstrap
遇到报错:PostgreSQL was built without OpenSSL support, which TimescaleDB needs for full compatibility
解决方法:重新编译安装 postgresql,增加 --with-openssl 选项
./configure --prefix=/home/randy/soft/postgresql --with-openssl
或者执行 ./bootstrap -DUSE_OPENSSL=0 不使用 openssl

- 进入上一步生成的 build 目录,编译安装 timescaledb
cd build
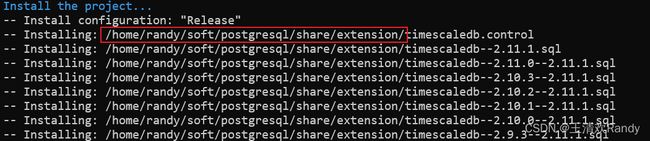
make && make install
安装完成之后,就可以在 postgresql 插件目录下看到 timescaledb 了
1.2 修改 PG 配置
完成 TimescaleDB 安装之后,需要修改 postgresql 配置文件增加 timescaledb 预加载库
- 找到 pg 配置文件
$ psql -Upostgres -dpostgres -c "SHOW config_file;"
Password for user postgres:
config_file
--------------------------------------------------
/home/randy/soft/postgresql/data/postgresql.conf
(1 row)
- 修改 pg 配置文件
vim /home/randy/soft/postgresql/data/postgresql.conf
# 做如下修改
shared_preload_libraries = 'timescaledb'
修改完成之后重启 pg
1.3 安装 TimescaleDB 插件
- 执行如下命令创建 timescaledb 插件
CREATE EXTENSION IF NOT EXISTS timescaledb;
- 完成插件创建之后可以使用 \dx 命令查看插件是否成功安装
testdb=# \dx
List of installed extensions
Name | Version | Schema | Description
-------------+---------+------------+---------------------------------------------------------------------------------------
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
timescaledb | 2.11.1 | public | Enables scalable inserts and complex queries for time-series data (Community Edition)
(2 rows)
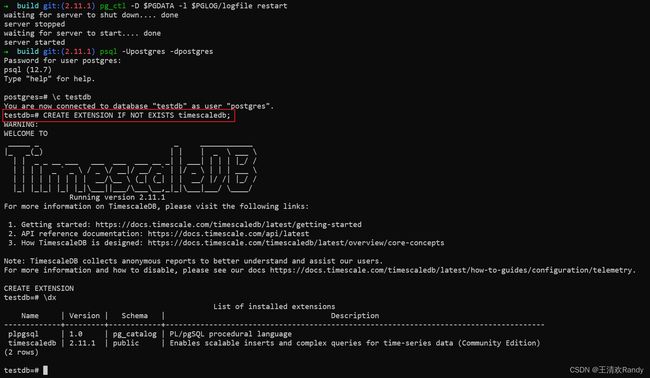
至此,postgresql + timescaledb 时序数据库就安装完成了
- 不想再用这个插件的话,使用如下命令删除插件
DROP EXTENSION IF EXISTS timescaledb;
02 Timescale 基础使用
2.1 创建超表 hypertables
- CREATE 创建一个 pg 普通表
testdb=# CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
device TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);
CREATE TABLE
然后使用 create_hypertable 函数将普通表转化成 hypertable
testdb=# SELECT create_hypertable('conditions', 'time');
create_hypertable
-------------------------
(1,public,conditions,t)
(1 row)
- INSERT 向 hypertable 中插入数据
testdb=# INSERT INTO conditions(time, location, device, temperature, humidity)
SELECT now(), to_char(i, 'FM0000'), to_char(i, 'FM00000'), random()*i, random()*i FROM generate_series(1,10000) i;
INSERT 0 10000
- SELECT 查询 hypertable 数据
testdb=# SELECT * FROM conditions ORDER BY time DESC LIMIT 10;
time | location | device | temperature | humidity
-------------------------------+----------+--------+---------------------+----------------------
2023-08-03 12:37:00.345665+08 | 0001 | 00001 | 0.24349980974765373 | 0.5948687729797264
2023-08-03 12:37:00.345665+08 | 0002 | 00002 | 1.8149739913052656 | 0.616265502369167
2023-08-03 12:37:00.345665+08 | 0003 | 00003 | 2.400422475569293 | 0.6870057094407791
2023-08-03 12:37:00.345665+08 | 0004 | 00004 | 2.639553072461581 | 1.9409034849705193
2023-08-03 12:37:00.345665+08 | 0005 | 00005 | 2.127623537273031 | 3.8871503537982655
2023-08-03 12:37:00.345665+08 | 0006 | 00006 | 2.3469833801156312 | 4.411529933527426
2023-08-03 12:37:00.345665+08 | 0007 | 00007 | 1.0073460031664823 | 0.016827997740616496
2023-08-03 12:37:00.345665+08 | 0008 | 00008 | 7.023014897212306 | 0.8679293544022073
2023-08-03 12:37:00.345665+08 | 0009 | 00009 | 6.744935559863428 | 6.312948981297968
2023-08-03 12:37:00.345665+08 | 0010 | 00010 | 9.279208258323166 | 9.451548543523778
(10 rows)
- UPDATE 更新 hypertable 数据
更新数据的语句与标准 SQL 一致,如下示例修改指定记录的值
testdb=# SELECT * FROM conditions
WHERE time = '2023-08-03 12:37:00.345665+08' AND location = '0001';
time | location | device | temperature | humidity
-------------------------------+----------+--------+---------------------+--------------------
2023-08-03 12:37:00.345665+08 | 0001 | 00001 | 0.24349980974765373 | 0.5948687729797264
(1 row)
testdb=# UPDATE conditions SET temperature = 70.2, humidity = 50.0
WHERE time = '2023-08-03 12:37:00.345665+08' AND location = '0001';
UPDATE 1
testdb=# SELECT * FROM conditions
WHERE time = '2023-08-03 12:37:00.345665+08' AND location = '0001';
time | location | device | temperature | humidity
-------------------------------+----------+--------+-------------+----------
2023-08-03 12:37:00.345665+08 | 0001 | 00001 | 70.2 | 50
(1 row)
也可以修改该指定范围内的多行记录,如下例子中修改时间 2023-08-03 12:37:00 到 2023-08-03 12:37:05 这 5 秒内的数据如下
testdb=# SELECT * FROM conditions ORDER BY time DESC LIMIT 10;
time | location | device | temperature | humidity
-------------------------------+----------+--------+--------------------+----------------------
2023-08-03 12:37:00.345665+08 | 0002 | 00002 | 1.8149739913052656 | 0.616265502369167
2023-08-03 12:37:00.345665+08 | 0003 | 00003 | 2.400422475569293 | 0.6870057094407791
2023-08-03 12:37:00.345665+08 | 0004 | 00004 | 2.639553072461581 | 1.9409034849705193
2023-08-03 12:37:00.345665+08 | 0005 | 00005 | 2.127623537273031 | 3.8871503537982655
2023-08-03 12:37:00.345665+08 | 0006 | 00006 | 2.3469833801156312 | 4.411529933527426
2023-08-03 12:37:00.345665+08 | 0007 | 00007 | 1.0073460031664823 | 0.016827997740616496
2023-08-03 12:37:00.345665+08 | 0008 | 00008 | 7.023014897212306 | 0.8679293544022073
2023-08-03 12:37:00.345665+08 | 0009 | 00009 | 6.744935559863428 | 6.312948981297968
2023-08-03 12:37:00.345665+08 | 0010 | 00010 | 9.279208258323166 | 9.451548543523778
2023-08-03 12:37:00.345665+08 | 0011 | 00011 | 1.994685462372594 | 7.361677356344085
(10 rows)
testdb=# UPDATE conditions SET temperature = temperature + 0.1
WHERE time >= '2023-08-03 12:37:00' AND time < '2023-08-03 12:37:05';
UPDATE 10000
testdb=# SELECT * FROM conditions ORDER BY time DESC LIMIT 10;
time | location | device | temperature | humidity
-------------------------------+----------+--------+--------------------+----------------------
2023-08-03 12:37:00.345665+08 | 0002 | 00002 | 1.9149739913052657 | 0.616265502369167
2023-08-03 12:37:00.345665+08 | 0003 | 00003 | 2.500422475569293 | 0.6870057094407791
2023-08-03 12:37:00.345665+08 | 0004 | 00004 | 2.739553072461581 | 1.9409034849705193
2023-08-03 12:37:00.345665+08 | 0005 | 00005 | 2.2276235372730313 | 3.8871503537982655
2023-08-03 12:37:00.345665+08 | 0006 | 00006 | 2.4469833801156313 | 4.411529933527426
2023-08-03 12:37:00.345665+08 | 0007 | 00007 | 1.1073460031664824 | 0.016827997740616496
2023-08-03 12:37:00.345665+08 | 0008 | 00008 | 7.123014897212306 | 0.8679293544022073
2023-08-03 12:37:00.345665+08 | 0009 | 00009 | 6.844935559863428 | 6.312948981297968
2023-08-03 12:37:00.345665+08 | 0010 | 00010 | 9.379208258323166 | 9.451548543523778
2023-08-03 12:37:00.345665+08 | 0011 | 00011 | 2.094685462372594 | 7.361677356344085
(10 rows)
- Upsert 插入新数据或更新已存在的数据
Upsert 只能在存在唯一索引或唯一约束的表中生效,可以使用 ALTER TABLE … ADD CONSTRAINT … UNIQUE 语句为已经存在的 hypertable 创建唯一约束
testdb=# ALTER TABLE conditions
ADD CONSTRAINT conditions_time_location
UNIQUE (time, location);
ALTER TABLE
testdb=# \d conditions
Table "public.conditions"
Column | Type | Collation | Nullable | Default
-------------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | not null |
location | text | | not null |
device | text | | not null |
temperature | double precision | | |
humidity | double precision | | |
Indexes:
"conditions_time_location" UNIQUE CONSTRAINT, btree ("time", location)
"conditions_time_idx" btree ("time")
Triggers:
ts_insert_blocker BEFORE INSERT ON conditions FOR EACH ROW EXECUTE FUNCTION _timescaledb_internal.insert_blocker()
Number of child tables: 1 (Use \d+ to list them.)
插入新数据或更新已存在的数据使用 INSERT INTO … VALUES … ON CONFLICT … DO UPDATE 语句实现
testdb=# SELECT * FROM conditions
WHERE time = '2023-08-03 12:37:00.345665+08' AND location = '0001';
time | location | device | temperature | humidity
-------------------------------+----------+--------+-------------+----------
2023-08-03 12:37:00.345665+08 | 0001 | 00001 | 70.3 | 50
(1 row)
testdb=# INSERT INTO conditions
VALUES ('2023-08-03 12:37:00.345665+08', '0001', '00001', 70.2, 50.1)
ON CONFLICT (time, location) DO UPDATE
SET temperature = excluded.temperature,
humidity = excluded.humidity;
INSERT 0 1
testdb=# SELECT * FROM conditions
WHERE time = '2023-08-03 12:37:00.345665+08' AND location = '0001';
time | location | device | temperature | humidity
-------------------------------+----------+--------+-------------+----------
2023-08-03 12:37:00.345665+08 | 0001 | 00001 | 70.2 | 50.1
(1 row)
也可以只执行插入操作,如果记录已存在则直接跳过,该操作使用 INSERT INTO … VALUES … ON CONFLICT DO NOTHING 语句实现
testdb=# INSERT INTO conditions
VALUES (NOW(), 'new', '00001', 70.1, 50.0)
ON CONFLICT DO NOTHING;
INSERT 0 1
testdb=# SELECT * FROM conditions WHERE location = 'new';
time | location | device | temperature | humidity
-------------------------------+----------+--------+-------------+----------
2023-08-04 10:33:16.698018+08 | new | 00001 | 70.1 | 50
(1 row)
testdb=# INSERT INTO conditions
VALUES ('2023-08-04 10:33:16.698018+08', '0001', '00001', 71, 50.1)
ON CONFLICT DO NOTHING;
INSERT 0 1
testdb=# SELECT * FROM conditions WHERE location = 'new';
time | location | device | temperature | humidity
-------------------------------+----------+--------+-------------+----------
2023-08-04 10:33:16.698018+08 | new | 00001 | 70.1 | 50
(1 row)
- DELETE 删除数据
删除数据的语句与标准 SQL 一致 DELETE FROM …
testdb=# SELECT * FROM conditions WHERE location = 'new';
time | location | device | temperature | humidity
-------------------------------+----------+--------+-------------+----------
2023-08-04 10:33:16.698018+08 | new | 00001 | 70.1 | 50
(1 row)
testdb=# DELETE FROM conditions WHERE location = 'new';
DELETE 1
testdb=# SELECT * FROM conditions WHERE location = 'new';
time | location | device | temperature | humidity
------+----------+--------+-------------+----------
(0 rows)
- DROP 删除 hypertable 只需要使用 PG 命令删除基表(普通表)即可
testdb=# DROP TABLE conditions;
DROP TABLE
2.2 编辑超表 hypertable
hypertable 的修改和标准 SQL 一致,可以使用 ALTER TABLE 相关语句实现:http://www.postgres.cn/docs/12/ddl-alter.html
- 增删列
增加列 column 时,如果没有默认值即 NULL 时,新增操作可以很快完成;但是默认值为非空的时候,就需要花大量时间填充所有分区中每条记录新增列的值。
另外,无法对已经被压缩的 hypertable 进行增删列操作,如果要进行该操作需要先解压
testdb=# \d conditions
Table "public.conditions"
Column | Type | Collation | Nullable | Default
-------------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | not null |
location | text | | not null |
device | text | | not null |
temperature | double precision | | |
humidity | double precision | | |
Indexes:
"conditions_time_idx" btree ("time" DESC)
Triggers:
ts_insert_blocker BEFORE INSERT ON conditions FOR EACH ROW EXECUTE FUNCTION _timescaledb_internal.insert_blocker()
Number of child tables: 1 (Use \d+ to list them.)
testdb=# ALTER TABLE conditions
ADD COLUMN test_column DOUBLE PRECISION NULL;
ALTER TABLE
testdb=# \d conditions
Table "public.conditions"
Column | Type | Collation | Nullable | Default
-------------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | not null |
location | text | | not null |
device | text | | not null |
temperature | double precision | | |
humidity | double precision | | |
test_column | double precision | | |
Indexes:
"conditions_time_idx" btree ("time" DESC)
Triggers:
ts_insert_blocker BEFORE INSERT ON conditions FOR EACH ROW EXECUTE FUNCTION _timescaledb_internal.insert_blocker()
Number of child tables: 1 (Use \d+ to list them.)
testdb=# ALTER TABLE conditions
DROP COLUMN test_column;
ALTER TABLE
testdb=# \d conditions
Table "public.conditions"
Column | Type | Collation | Nullable | Default
-------------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | not null |
location | text | | not null |
device | text | | not null |
temperature | double precision | | |
humidity | double precision | | |
Indexes:
"conditions_time_idx" btree ("time" DESC)
Triggers:
ts_insert_blocker BEFORE INSERT ON conditions FOR EACH ROW EXECUTE FUNCTION _timescaledb_internal.insert_blocker()
Number of child tables: 1 (Use \d+ to list them.)
- 重命名列或表
testdb=# \d conditions
Table "public.conditions"
Column | Type | Collation | Nullable | Default
-------------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | not null |
location | text | | not null |
device | text | | not null |
temperature | double precision | | |
humidity | double precision | | |
test_column | double precision | | |
Indexes:
"conditions_time_idx" btree ("time" DESC)
Triggers:
ts_insert_blocker BEFORE INSERT ON conditions FOR EACH ROW EXECUTE FUNCTION _timescaledb_internal.insert_blocker()
Number of child tables: 1 (Use \d+ to list them.)
testdb=# ALTER TABLE conditions RENAME COLUMN test_column TO ts_column;
ALTER TABLE
testdb=# ALTER TABLE conditions RENAME TO weather;
ALTER TABLE
testdb=# \d conditions
Did not find any relation named "conditions".
testdb=# \d weather
Table "public.weather"
Column | Type | Collation | Nullable | Default
-------------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | not null |
location | text | | not null |
device | text | | not null |
temperature | double precision | | |
humidity | double precision | | |
ts_column | double precision | | |
Indexes:
"conditions_time_idx" btree ("time" DESC)
Triggers:
ts_insert_blocker BEFORE INSERT ON weather FOR EACH ROW EXECUTE FUNCTION _timescaledb_internal.insert_blocker()
Number of child tables: 1 (Use \d+ to list them.)
2.3 修改 hypertable 分区间隔
- 普通表转化成 hypertable 时指定分区时间间隔 chunk_time_interval
如果创建 hypertable 是没有指定分区间隔,默认值是 7 天;可以通过查询 _timescaledb.catalog 查看分区间隔的当前设置
testdb=# CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
device TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);
CREATE TABLE
testdb=# SELECT create_hypertable('conditions', 'time');
create_hypertable
-------------------------
(2,public,conditions,t)
(1 row)
testdb=# SELECT h.table_name, c.interval_length
FROM _timescaledb_catalog.dimension c
JOIN _timescaledb_catalog.hypertable h
ON h.id = c.hypertable_id;
table_name | interval_length
------------+-----------------
conditions | 604800000000
(1 row)
可以看到没有指定 chunk_time_interval 的 hypertable 分区间隔为 604800000000 / 1000 / 1000 / 60 / 60 / 24 = 7,interval_length 的单位为微秒(microsecond)
创建 hypertable 时我们通过 chunk_time_interval 指定分区间隔为 1 天
testdb=# DROP TABLE conditions;
DROP TABLE
testdb=# CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
device TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);
CREATE TABLE
testdb=# SELECT create_hypertable(
'conditions',
'time',
chunk_time_interval => INTERVAL '1 day'
);
create_hypertable
-------------------------
(3,public,conditions,t)
(1 row)
testdb=# SELECT h.table_name, c.interval_length
FROM _timescaledb_catalog.dimension c
JOIN _timescaledb_catalog.hypertable h
ON h.id = c.hypertable_id;
table_name | interval_length
------------+-----------------
conditions | 86400000000
(1 row)
- 通过 set_chunk_time_interval 函数修改 hypertable 分区间隔
需要注意的是修改分区时间间隔只会再新建的分区中生效,已经创建的分区不会受到影响。所以如果创建了一个很长时间的分区间隔例如 1 年,然后你想修改成一个更小的分区间隔,那这个更小间隔只会在一年后生效了,这时候只能新建一个表设置分区间隔,然后迁移数据了。
testdb=# SELECT set_chunk_time_interval('conditions', INTERVAL '12 hours');
set_chunk_time_interval
-------------------------
(1 row)
testdb=# SELECT h.table_name, c.interval_length
FROM _timescaledb_catalog.dimension c
JOIN _timescaledb_catalog.hypertable h
ON h.id = c.hypertable_id;
table_name | interval_length
------------+-----------------
conditions | 43200000000
(1 row)
2.4 hypertable 创建索引
在一个 hypertable 中创建索引分为两步:
- 确定该超表的分区列有哪些,其中 time 列是所有 hypertable 表的分区列,所以创建索引必须包含该列;另外,在创建 hypertable 表时可以通过 partitioning_column 字段指定空间分区列。
- 创建的索引组合必须包括所有分区列,在此基础上增加其他列
- 创建索引
hypertable 中索引的创建仍是使用标准的 SQL 语句 CREATE INDEX / CREATE UNIQUE INDEX,例如,如下例子中在 conditions 超表的 time 和 device 列上建立索引 idx_device_time
testdb=# \d conditions
Table "public.conditions"
Column | Type | Collation | Nullable | Default
-------------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | not null |
location | text | | not null |
device | text | | not null |
temperature | double precision | | |
humidity | double precision | | |
Indexes:
"conditions_time_idx" btree ("time" DESC)
Triggers:
ts_insert_blocker BEFORE INSERT ON conditions FOR EACH ROW EXECUTE FUNCTION _timescaledb_internal.insert_blocker()
Number of child tables: 1 (Use \d+ to list them.)
testdb=# CREATE UNIQUE INDEX idx_device_time
ON conditions(device, time);
CREATE INDEX
testdb=# \d conditions
Table "public.conditions"
Column | Type | Collation | Nullable | Default
-------------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | not null |
location | text | | not null |
device | text | | not null |
temperature | double precision | | |
humidity | double precision | | |
Indexes:
"idx_device_time" UNIQUE, btree (device, "time")
"conditions_time_idx" btree ("time" DESC)
Triggers:
ts_insert_blocker BEFORE INSERT ON conditions FOR EACH ROW EXECUTE FUNCTION _timescaledb_internal.insert_blocker()
Number of child tables: 1 (Use \d+ to list them.)
idx_device_time 索引中包含了所有分区列 time,而 device 不是分区列,如果创建的索引组合不包含分区列,会抛出错误,如下 idx_device 索引仅建立在 device 列上
testdb=# CREATE UNIQUE INDEX idx_device
ON conditions(device);
ERROR: cannot create a unique index without the column "time" (used in partitioning)
testdb=#
- 删除索引
hypertable 中删除索引仍是使用标准的 SQL 语句 DROP INDEX,删除 conditions 超表中的索引 idx_device_time
需要注意的是DBMS为主键约束和唯一约束自动创建的索引是无法删除的
testdb=# \d conditions
Table "public.conditions"
Column | Type | Collation | Nullable | Default
-------------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | not null |
location | text | | not null |
device | text | | not null |
temperature | double precision | | |
humidity | double precision | | |
Indexes:
"idx_device_time" UNIQUE, btree (device, "time")
"conditions_time_idx" btree ("time" DESC)
Triggers:
ts_insert_blocker BEFORE INSERT ON conditions FOR EACH ROW EXECUTE FUNCTION _timescaledb_internal.insert_blocker()
Number of child tables: 1 (Use \d+ to list them.)
testdb=# DROP INDEX idx_device_time;
DROP INDEX
testdb=# \d conditions
Table "public.conditions"
Column | Type | Collation | Nullable | Default
-------------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | not null |
location | text | | not null |
device | text | | not null |
temperature | double precision | | |
humidity | double precision | | |
Indexes:
"conditions_time_idx" btree ("time" DESC)
Triggers:
ts_insert_blocker BEFORE INSERT ON conditions FOR EACH ROW EXECUTE FUNCTION _timescaledb_internal.insert_blocker()
Number of child tables: 1 (Use \d+ to list them.)
- 已建索引的普通表转化为 hypertable,空间分区列 partitioning_column 必须包含在已建的索引中
例如,我们在普通表 basic_table 中已经在 device_id 和 time 列上建立了索引 idx_deviceid_time,那么创建以该表为基表的 hypertable 的分区列需要包含在索引列中,即分区列仅能为 time 与 device_id 的组合。
下例中,将已经创建好索引的 basic_table 表转化为仅以 time 为分区列的 hypertable
testdb=# CREATE TABLE basic_table(
time TIMESTAMPTZ,
user_id BIGINT,
device_id BIGINT,
value FLOAT
);
CREATE TABLE
testdb=# CREATE UNIQUE INDEX idx_deviceid_time
ON basic_table(device_id, time);
CREATE INDEX
testdb=# \d basic_table
Table "public.basic_table"
Column | Type | Collation | Nullable | Default
-----------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | |
user_id | bigint | | |
device_id | bigint | | |
value | double precision | | |
Indexes:
"idx_deviceid_time" UNIQUE, btree (device_id, "time")
testdb=# SELECT * from create_hypertable('basic_table', 'time');
NOTICE: adding not-null constraint to column "time"
DETAIL: Time dimensions cannot have NULL values.
hypertable_id | schema_name | table_name | created
---------------+-------------+-------------+---------
4 | public | basic_table | t
(1 row)
testdb=# \d basic_table
Table "public.basic_table"
Column | Type | Collation | Nullable | Default
-----------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | not null |
user_id | bigint | | |
device_id | bigint | | |
value | double precision | | |
Indexes:
"idx_deviceid_time" UNIQUE, btree (device_id, "time")
"basic_table_time_idx" btree ("time" DESC)
Triggers:
ts_insert_blocker BEFORE INSERT ON basic_table FOR EACH ROW EXECUTE FUNCTION _timescaledb_internal.insert_blocker()
也可以将已经创建好索引的 basic_table 表转化为以 time 和 device_id 为分区列的 hypertable
testdb=# SELECT * FROM create_hypertable(
'basic_table',
'time',
partitioning_column => 'device_id',
number_partitions => 4
);
NOTICE: adding not-null constraint to column "time"
DETAIL: Time dimensions cannot have NULL values.
hypertable_id | schema_name | table_name | created
---------------+-------------+-------------+---------
5 | public | basic_table | t
(1 row)
testdb=# \d basic_table
Table "public.basic_table"
Column | Type | Collation | Nullable | Default
-----------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | not null |
user_id | bigint | | |
device_id | bigint | | |
value | double precision | | |
Indexes:
"idx_deviceid_time" UNIQUE, btree (device_id, "time")
"basic_table_time_idx" btree ("time" DESC)
Triggers:
ts_insert_blocker BEFORE INSERT ON basic_table FOR EACH ROW EXECUTE FUNCTION _timescaledb_internal.insert_blocker()
但是,我们无法将不在索引组合中的 user_id 作为创建 hypertable 时的分区列
要解决这个问题,要确保在转化为超表之前建立的所有索引都要包含 hypertable 的分区列,所以将已存在的索引中加入 user_id 即可(重建索引可以重建一个索引,然后删除老的索引,避免使用 reindex 重建索引,因为该过程是阻塞的,一般大表不建议使用这个命令 )
testdb=# \d basic_table
Table "public.basic_table"
Column | Type | Collation | Nullable | Default
-----------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | |
user_id | bigint | | |
device_id | bigint | | |
value | double precision | | |
Indexes:
"idx_deviceid_time" UNIQUE, btree (device_id, "time")
testdb=# SELECT * FROM create_hypertable(
'basic_table',
'time',
partitioning_column => 'user_id',
number_partitions => 4
);
NOTICE: adding not-null constraint to column "time"
DETAIL: Time dimensions cannot have NULL values.
ERROR: cannot create a unique index without the column "user_id" (used in partitioning)
testdb=# DROP INDEX idx_deviceid_time;
DROP INDEX
testdb=# CREATE UNIQUE INDEX idx_userid_deviceid_time
ON basic_table(user_id, device_id, time);
CREATE INDEX
testdb=# \d basic_table
Table "public.basic_table"
Column | Type | Collation | Nullable | Default
-----------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | |
user_id | bigint | | |
device_id | bigint | | |
value | double precision | | |
Indexes:
"idx_userid_deviceid_time" UNIQUE, btree (user_id, device_id, "time")
testdb=# SELECT * FROM create_hypertable(
'basic_table',
'time',
partitioning_column => 'user_id',
number_partitions => 4
);
NOTICE: adding not-null constraint to column "time"
DETAIL: Time dimensions cannot have NULL values.
hypertable_id | schema_name | table_name | created
---------------+-------------+-------------+---------
12 | public | basic_table | t
(1 row)
如果文章对你有帮助,欢迎一键三连 ⭐️ 。如果还能够点击关注,那真的是对我最大的鼓励 。
参考资料
https://docs.timescale.com/self-hosted/latest/install/installation-source/
https://docs.timescale.com/use-timescale/latest/hypertables/create/
PolarDB 开源版 使用TimescaleDB 实现时序数据高速写入、压缩、实时聚合计算、自动老化等-阿里云开发者社区
https://zhuanlan.zhihu.com/p/57120174